| zo | zc | ze | za | zn | scs | dass |
|---|---|---|---|---|---|---|
| 0.76 | 1.58 | -0.79 | -0.09 | 1.32 | 30 | 56 |
| 0.30 | -0.27 | -0.09 | 0.09 | -0.40 | 30 | 48 |
| -0.13 | 0.66 | -0.80 | -0.95 | 0.93 | 35 | 48 |
| 1.06 | -1.02 | -0.16 | -0.50 | -0.02 | 29 | 48 |
| 1.74 | -0.78 | -1.55 | -2.86 | -1.14 | 41 | 43 |
| 0.22 | -0.41 | 0.78 | 0.90 | -0.25 | 37 | 60 |
Write Up Example & Block 2 Recap
Learning Objectives
At the end of this lab, you will:
- Understand how to write-up and provide interpretation of a linear model with multiple predictors.
What You Need
- Be up to date with lectures
- Have completed Labs 7-10
Required R Packages
Remember to load all packages within a code chunk at the start of your RMarkdown file using library(). If you do not have a package and need to install, do so within the console using install.packages(" "). For further guidance on installing/updating packages, see Section C here.
For this lab, you will need to load the following package(s):
- tidyverse
- patchwork
- sjPlot
- sandwich
- interactions
Lab Data
You can download the data required for this lab here or read it in via this link https://uoepsy.github.io/data/scs_study.csv.
Note: This is the same data as Lab 8.
Section A: Write-Up
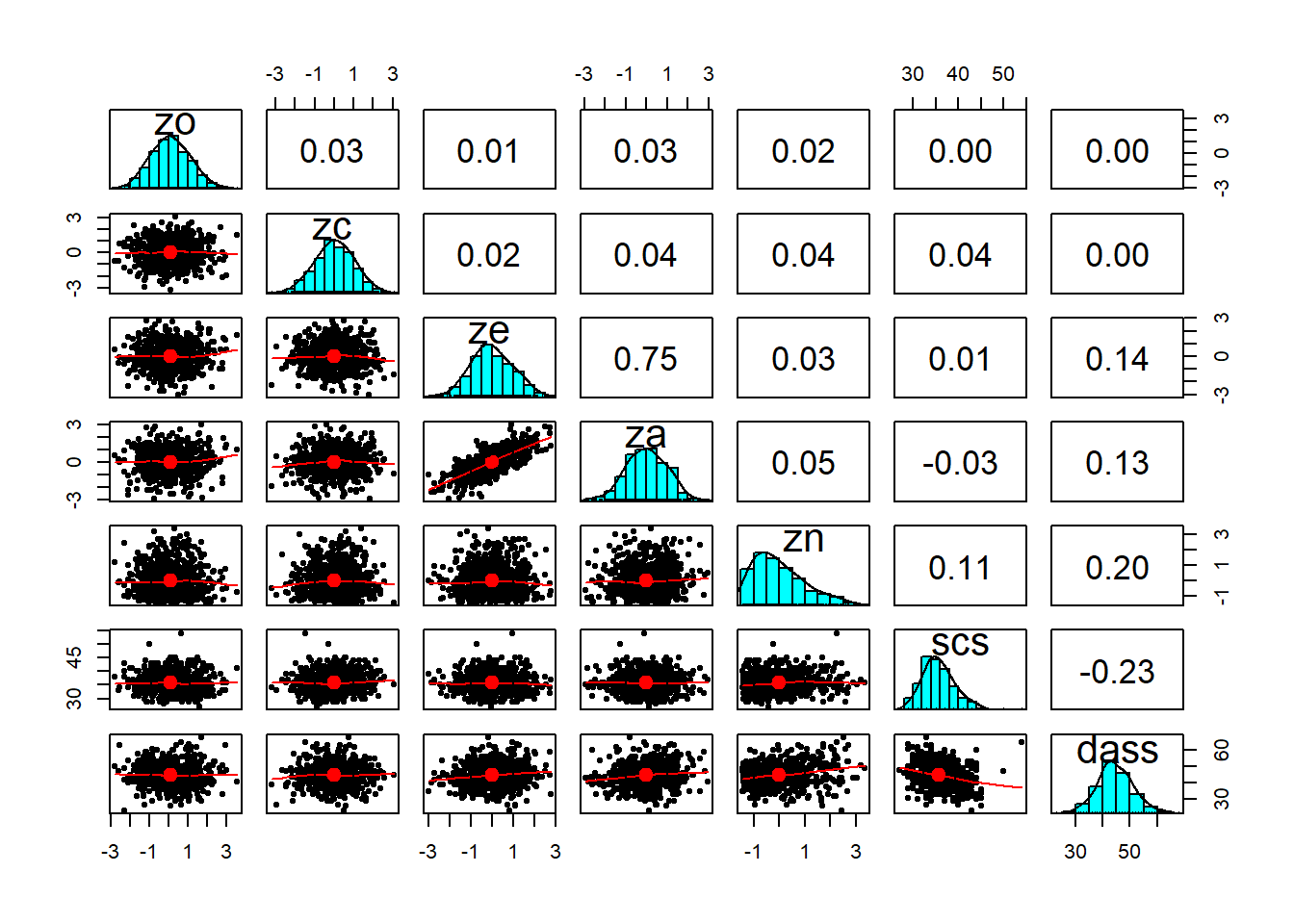
In this lab you will be presented with the output from a statistical analysis, and your job will be to write-up and present the results. We’re going to use an example analysis using one of the datasets we have worked with on a number of exercises in previous labs concerning personality traits, social comparison, depression, and anxiety.
The aim in writing should be that a reader is able to more or less replicate your analyses without referring to your R code. This requires detailing all of the steps you took in conducting the analysis.
The point of using RMarkdown is that you can pull your results directly from the code. If your analysis changes, so does your report!
Make sure that your final report doesn’t show any R functions or code. Remember you are interpreting and reporting your results in text, tables, or plots, targeting a generic reader who may use different software or may not know R at all. If you need a reminder on how to hide code, format tables, etc., make sure to review the rmd bootcamp.
Important - Write-Up Examples & Plagiarism
The example write-up sections included below are not perfect - they instead should give you a good example of what information you should include within each section, and how to structure this. For example, some information is missing (e.g., interpretation of descriptive statistics, what type of interaction is present), some information could be presented more clearly (e.g., variable names in tables, table/figure titles/captions, and rationales for choices), and writing could be more concise in places (e.g., discussion section is quite long).
Further, you must not copy any of the write-up included below for future reports - if you do, you will be committing plagiarism, and this type of academic misconduct is taken very seriously by the University. You can find out more here.
Study Overview
Research Question
Controlling for other personality traits, does neuroticism moderate effects of social comparison on symptoms of depression, anxiety and stress?
Previous research has identified an association between an individual’s perception of their social rank and symptoms of depression, anxiety and stress. We are interested in the individual differences in this association.
To investigate whether the effect of social comparison on symptoms of depression, anxiety and stress varies depending on level of Neuroticism, we will need to fit a multiple regression model with an interaction term and control for other personality traits.
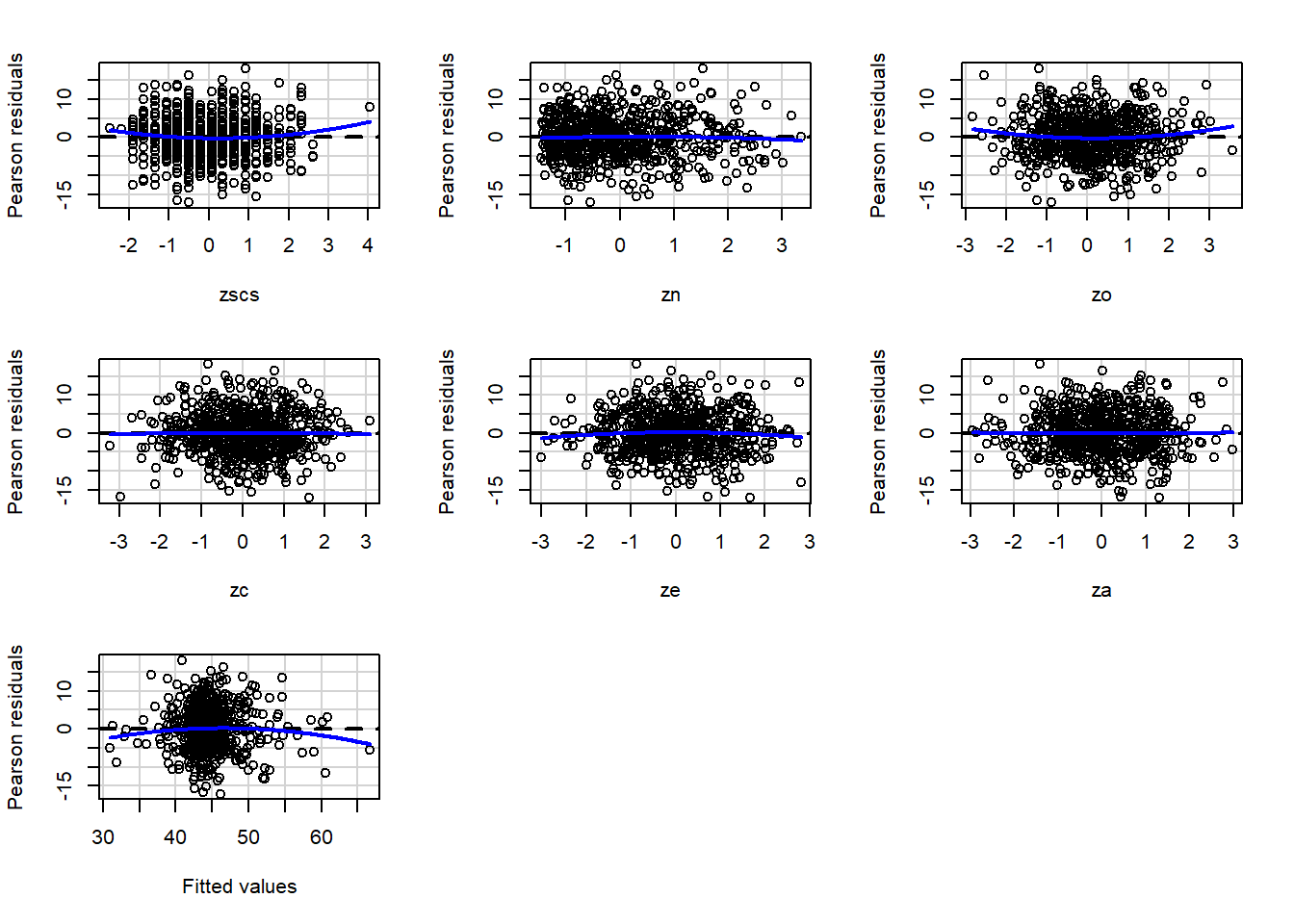
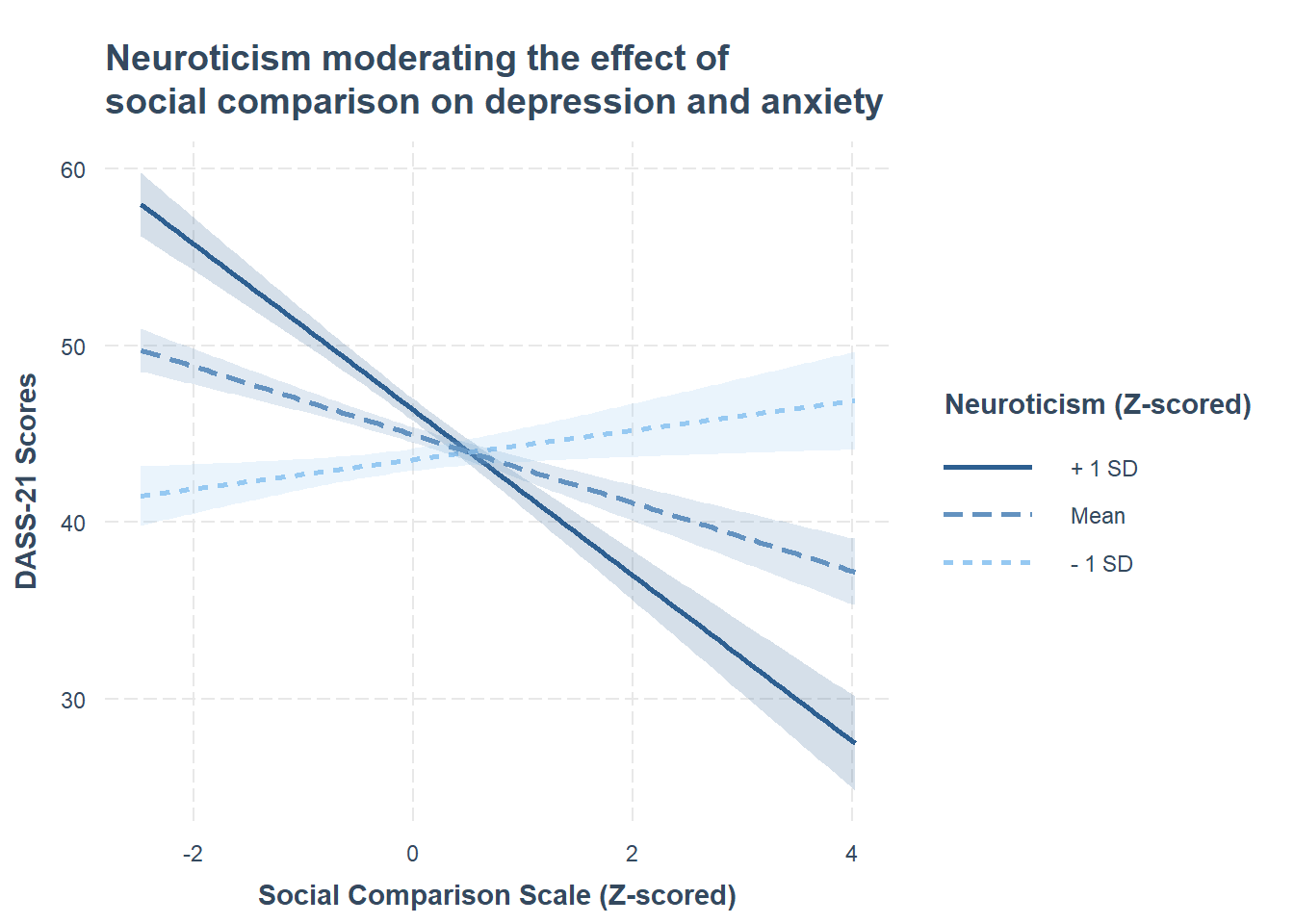
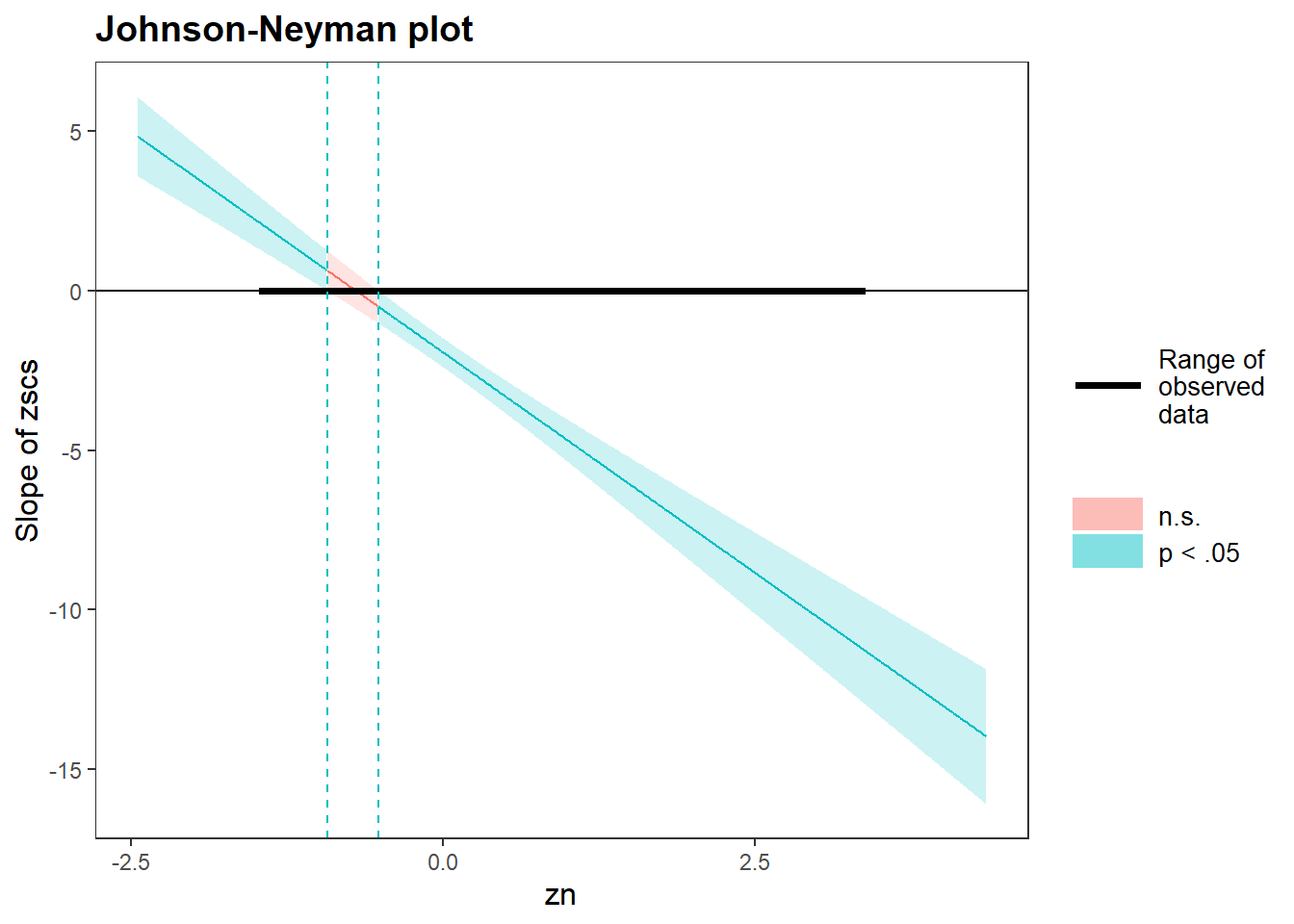
Setup
Setup
- Create a new RMarkdown file
- Load the required package(s)
- Read the scs dataset into R, assigning it to an object named
scs
The 3-Act Structure
We need to present our report in three clear sections - think of your sections like the 3 key parts of a play or story - we need to (1) provide some background and scene setting for the reader, (2) present our results in the context of the research question, and (3) present a resolution to our story - relate our findings back to the question we were asked and provide our answer.
Act I: Analysis Strategy
Question 1
Attempt to draft a discussion section based on the above research question and analysis provided.
Analysis Strategy - What to Include
Your analysis strategy will contain a number of different elements detailing plans and changes to your plan. Remember, your analysis strategy should not contain any results. You may wish to include the following sections:
- Very brief data and design description:
- Give the reader some background on the context of your write-up. For example, you may wish to describe the data source, data collection strategy, study design, number of observational units.
- Specify the variables of interest in relation to the research question, including their unit of measurement, the allowed range (for Likert scales), how they are scored, and if they are factors make sure to list the order of the levels.
- Data management:
- Describe any data cleaning and/or recoding.
- Are there any observations that have been excluded based on pre-defined criteria? How/why, and how many?
- * Describe any transformations performed to aid your interpretation (i.e., log transformation, mean centering, standardisation, etc.)
- Model specification:
- Clearly state your hypotheses and specify your chosen significance level.
- What type of statistical analysis do you plan to use to answer the research question? (e.g., t-test, simple linear regression, multiple linear regression, etc.)
- In some cases, you may wish to include some visualisations and descriptive tables to motivate your model specification.
- Specify the model(s) to be fitted to answer your given research question and analysis structure. Clearly specify the response and explanatory variables included in your model(s) and remember to describe the coding of categorical variables (i.e., factors) so the reader is aware of any reference levels.
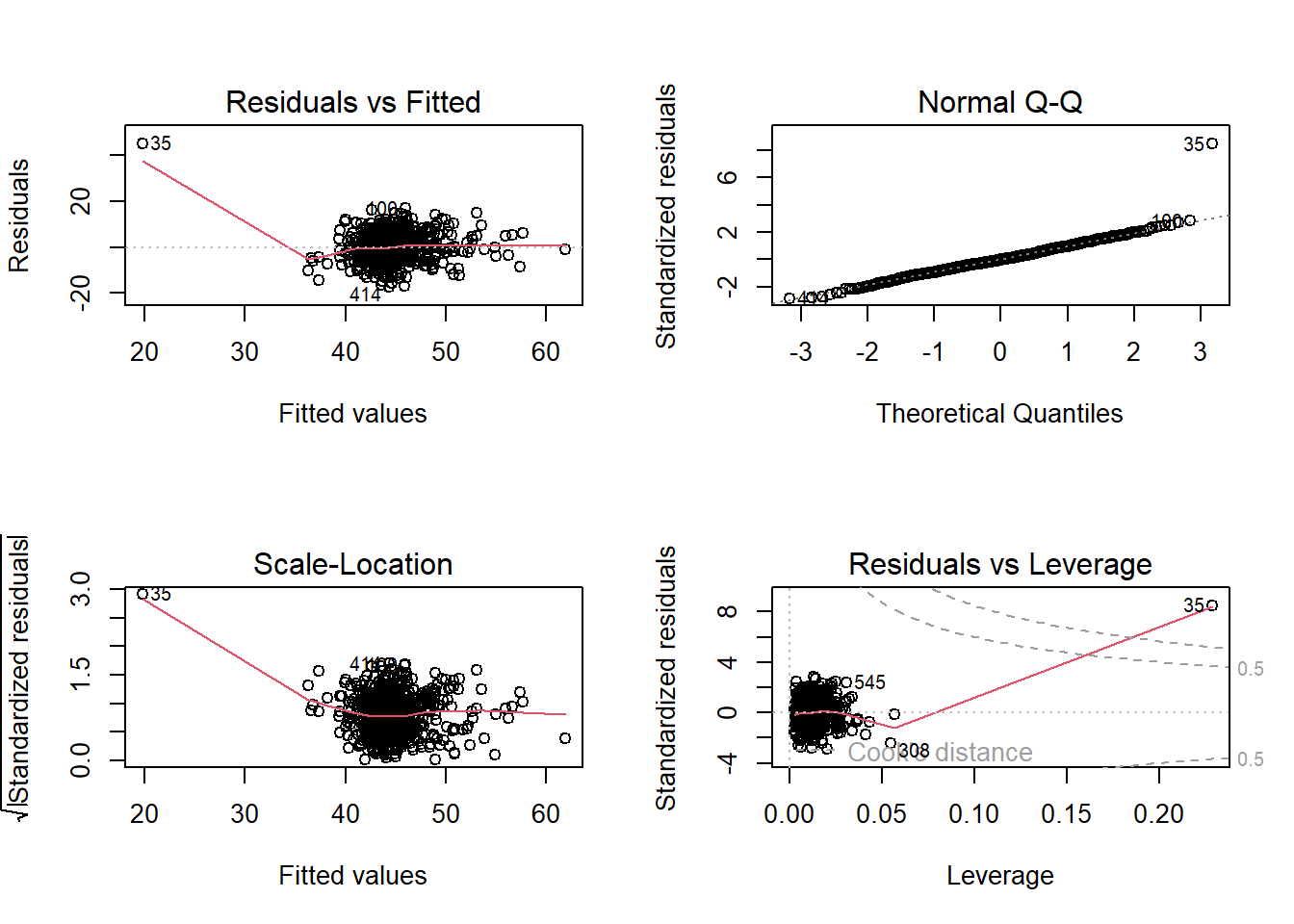
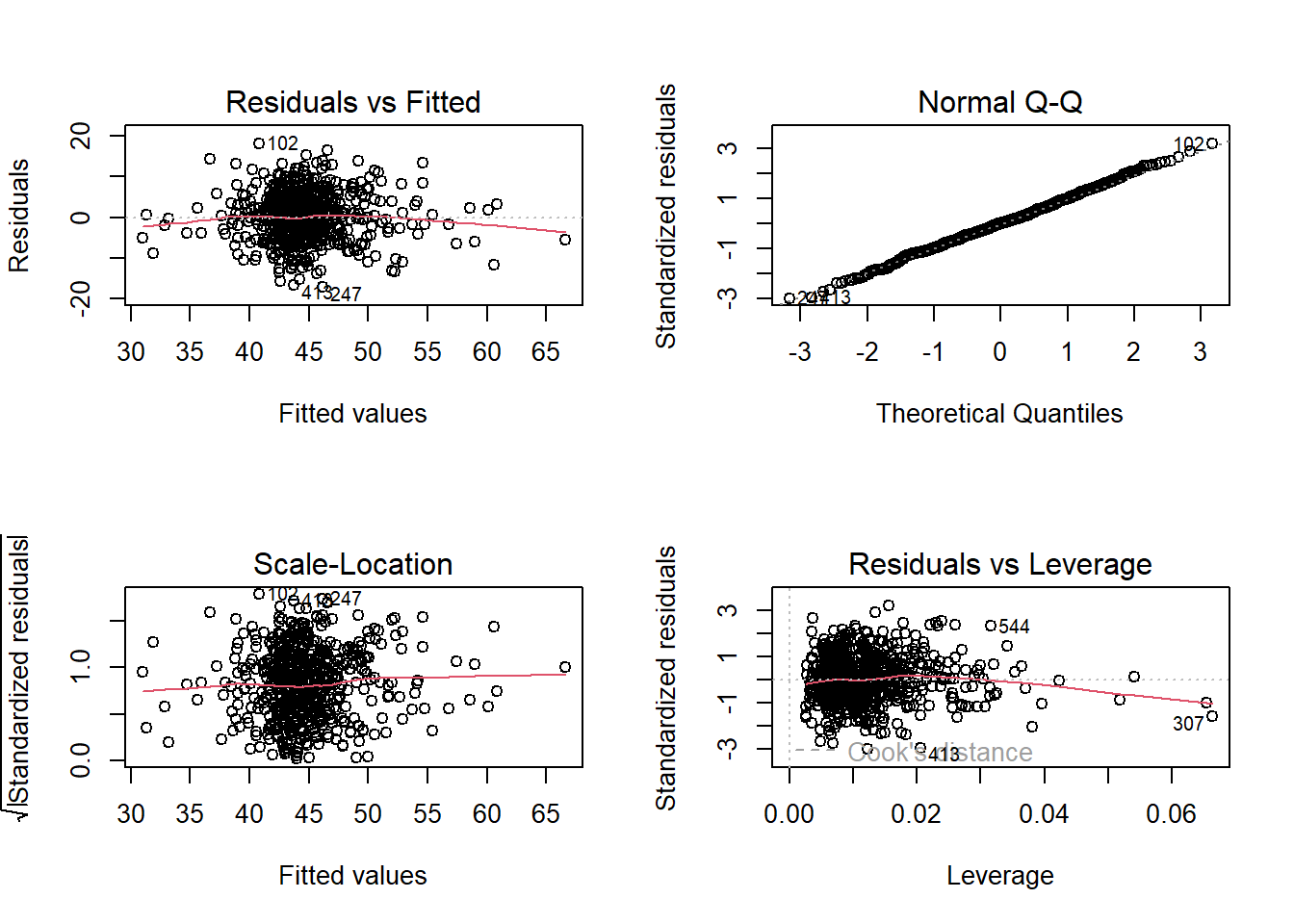
- Detail the steps that you will undertake to ensure that your model(s) do not violate the appropriate assumptions.
- If applicable, detail any required changes/modifications to the model specification to satisfy assumptions. Consider the following: Was there anything you had to do differently than planned during the analysis? Did the modelling highlight issues in your data? Did you have to do anything (e.g., transform any variables, exclude any observations) in order to meet assumptions?
Note that the * used on occasion in the above indicates that you may/should in some cases repeat these steps if you decide to make any modifications to your data (e.g., removing outliers, etc.).
As noted and encouraged throughout the course, one of the main benefits of using RMarkdown is the ability to include inline R code in your document. Try to incorporate this in your write up so you can automatically pull the specified values from your code. If you need a reminder on how to do this, see Lesson 4 of the Rmd Bootcamp.
Act II: Results
Question 2
Attempt to draft a results section based on your detailed analysis strategy and the analysis provided.
Results - What To Include
The results section should follow from your analysis strategy. This is where you would present the evidence and results that will be used to answer the research questions and can support your conclusions. Make sure that you address all aspects of the approach you outlined in the analysis strategy.
In this section, it is useful to include tables and plots to clearly present your findings to your reader. It is important, however, to carefully select what is the key information that should be presented. You don’t want to overload the reader with unnecessary information, and you also want to save space in case there is a page limit. Make use of figures with multiple panels where you can.
As a broad guideline, you want to start with the results of an exploratory data analysis, presenting tables of summary statistics and exploratory plots. You may also want to visualise relationships between variables and report covariances or correlations. Then, you should move on to the results from your model. Remember that in the main part of the report you should only interpret and report for models that do not violate the assumptions. You should also interpret all of the results presented, and remember to make reference to and comment on your assumption and diagnostic checks for key models.
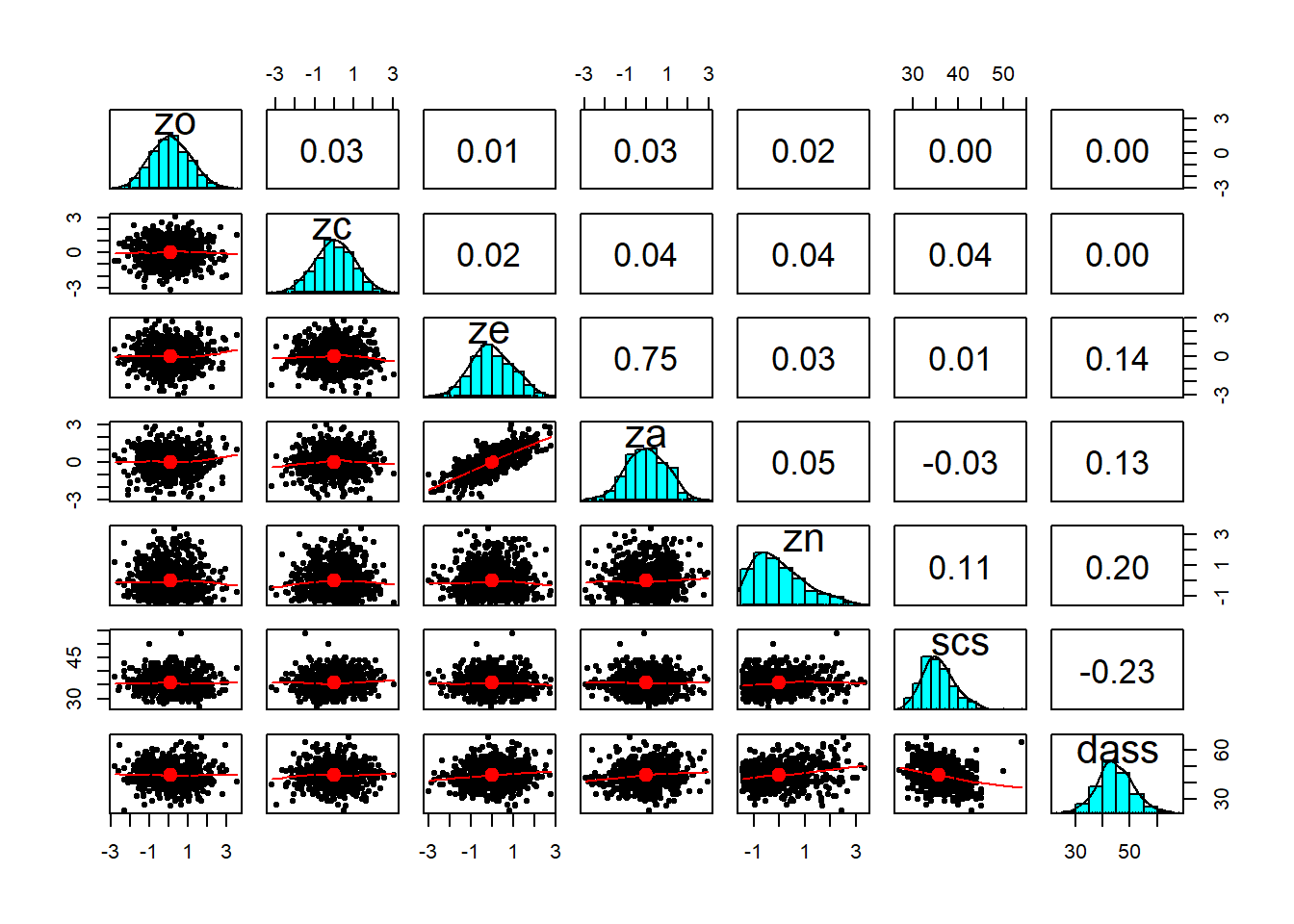
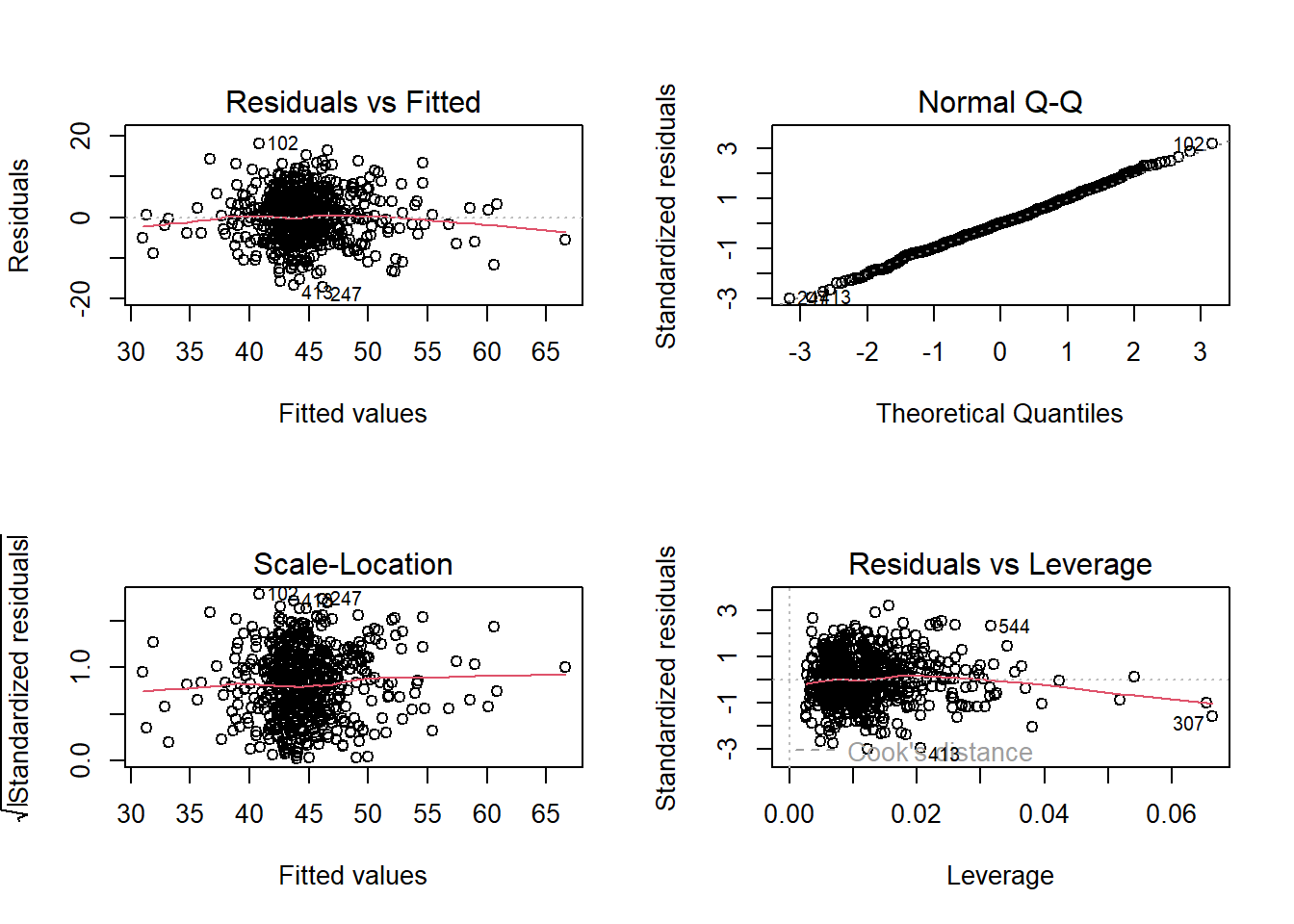
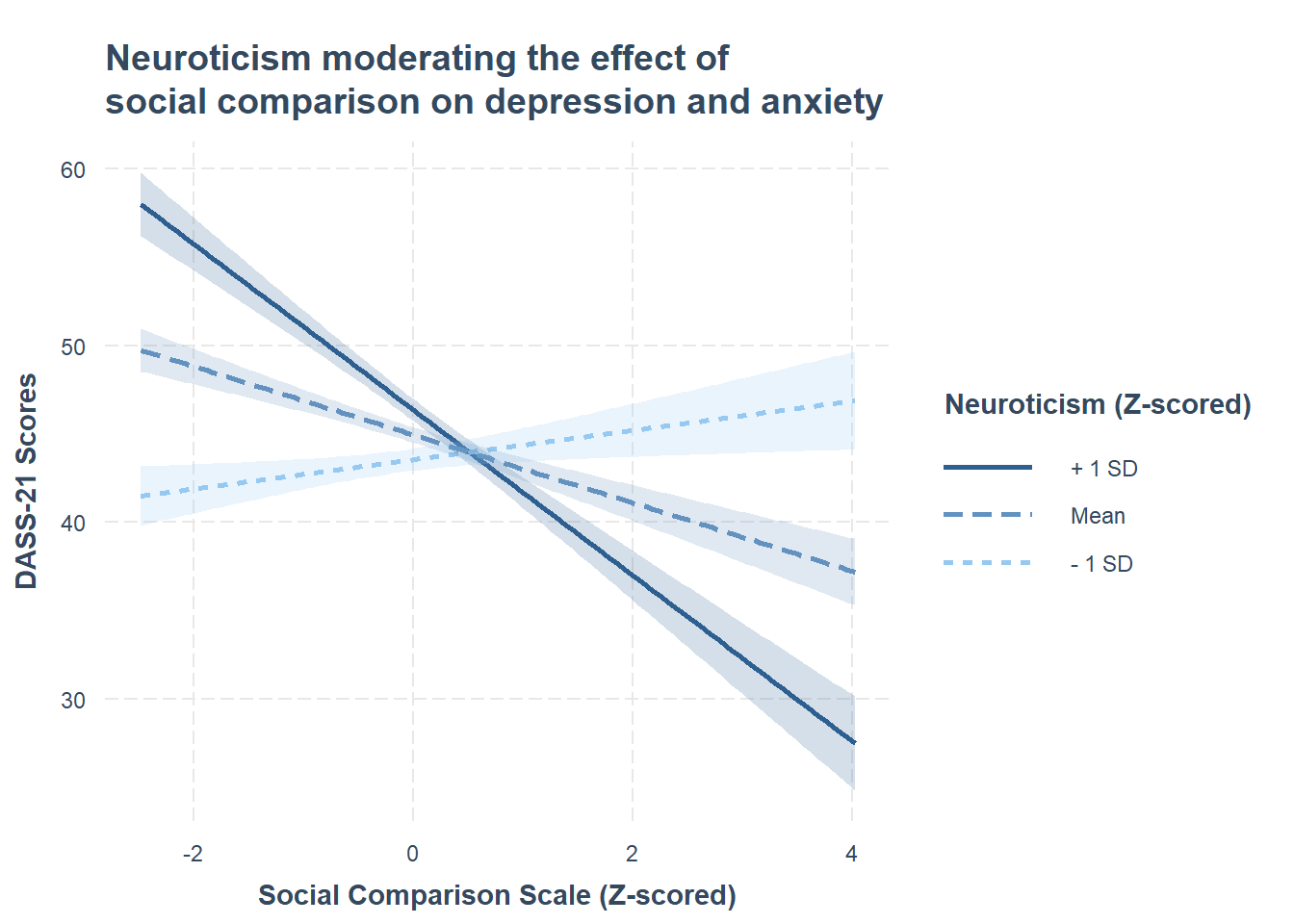
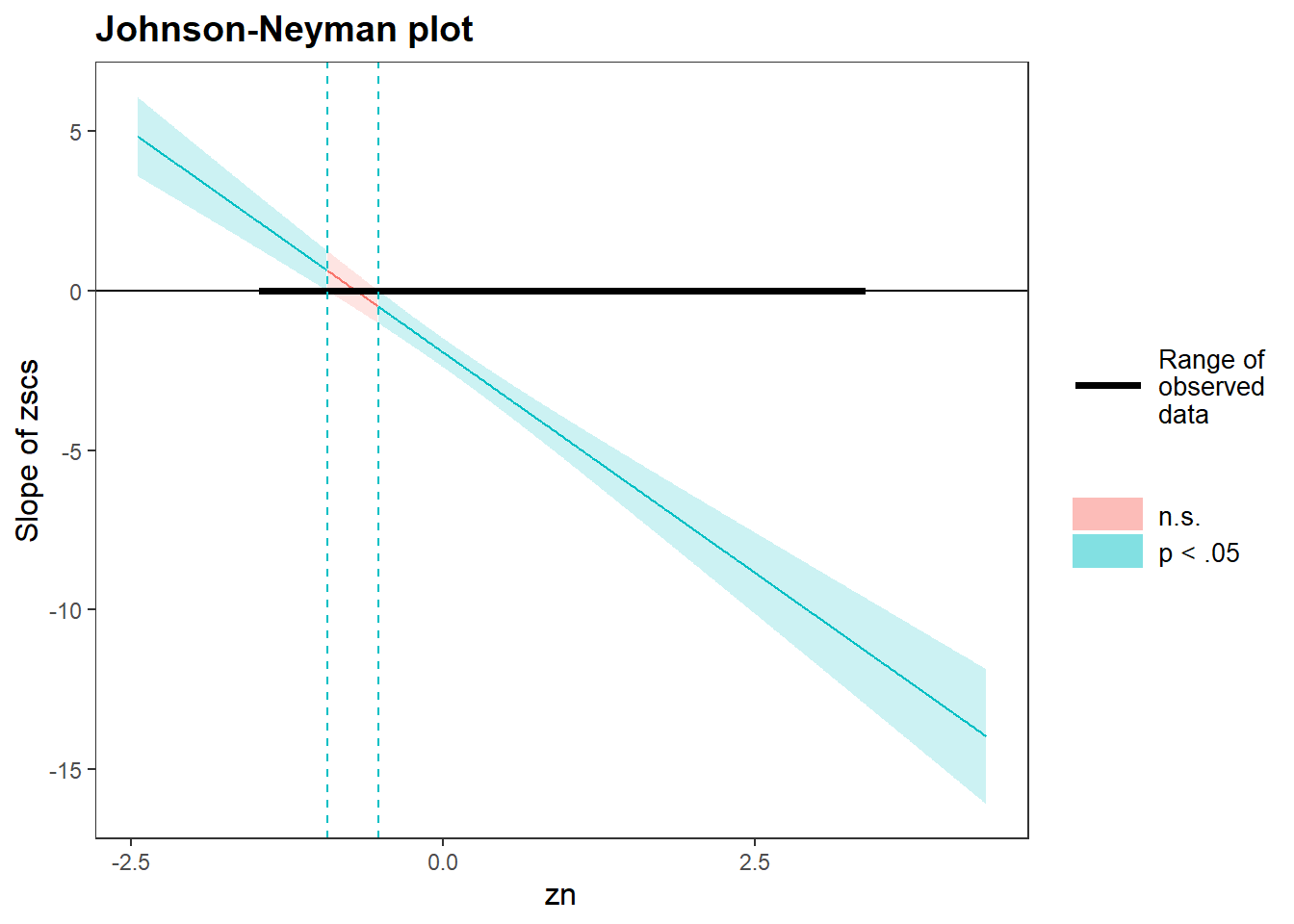
Act III: Discussion
Question 3
Attempt to draft a discussion section based on your results and the analysis provided.
Discussion - What To Include
In the discussion section, you should summarise the key findings from the results section and provide the reader with take-home sentences drawing the analysis together and relating it back to the original question.
The discussion should be relatively brief, and should not include any statistical analysis - instead think of the discussion as a conclusion, providing an answer to the research question(s).
Section B: Weeks 6 - 11 Recap
In the second part of the lab, there is no new content - the purpose of the recap section is for you to revisit and revise the concepts you have learned over the last 4/5 weeks.
Before you expand each of the boxes below, think about how comfortable you feel with each concept.
Section C: Mock Exam Questions
In the exam, there will be 3 sections containing different types of questions, as outlined below:
- Section A: You will answer multiple choice questions (see Question 1 for an example)
- Section B: You will solve by-hand calculation problems (see Question 2 for an example)
- Section C: You will be asked questions about basic
R-code and to interpret results of analyses (see Question 3 for an example)
Below there is a mock question from each section described above - note that solutions are not provided. These are just to give you an example of the types of questions you will be presented with. If you have questions about these, ask your tutor or come to office hours to discuss.
Question 1
Which assumption is being checked in the following line of code:
residualPlots(model1)
- A: Linearity
- B: Normality
- C: Independence
- D: Equal variances / Homoscedasticity
Question 2
Using the values below, calculate \(R^2\).
- SSModel = 70
- SSResidual = 56
- SSTotal = 126
Question 3
Researchers have a sample of 100 people, and they have measured their resting heart rate (rhr) and their caffeine consumption (caffeine). They were interested in estimating how caffeine consumption was associated with differences in resting heart rate, after controlling for age (age; since heart rate increases with advancing age and because they thought that older people tend to drink less caffeine).
From the following output (see Figure 7), write out and interpret the regression equation for the model following APA guidelines.
