| id | type | amount |
|---|---|---|
| 1 | No Music | 23.14891 |
| 2 | Pop Music | 20.59492 |
| 3 | Pop Music | 19.18172 |
| 4 | Pop Music | 16.70237 |
| 5 | Classical Music | 25.91041 |
| 6 | Pop Music | 19.27888 |
Effects Coding
Learning Objectives
At the end of this lab, you will:
- Understand how to specify dummy and sum-to-zero coding
- Interpret the output from a model using dummy coding
- Interpret the output from a model using sum-to-zero coding
What You Need
- Be up to date with lectures
- Have completed previous lab exercises from Week 1
Required R Packages
Remember to load all packages within a code chunk at the start of your RMarkdown file using library(). If you do not have a package and need to install, do so within the console using install.packages(" "). For further guidance on installing/updating packages, see Section C here.
For this lab, you will need to load the following package(s):
- tidyverse
- psych
- kableExtra
Lab Data
You can download the data required for this lab here or read it in via this link https://uoepsy.github.io/data/RestaurantSpending.csv
Study Overview
Research Question
Does the type of background music playing in a restaurant influence the amount of money that diners spend on their meal?
A group of researchers wanted to test the claims reported in (North, Shilcock, and Hargreaves 2003) on whether the type of background music playing in a restaurant influences the average amount of money spent by diners on their meal.
The group researchers got in touch with a restaurant and asked to alternate silence, popular music, and classical music on successive nights over 18 days. On those nights they recorded the mean spend per head for each table.
Setup
Setup
- Create a new RMarkdown file
- Load the required package(s)
- Read the Restaurant Spending dataset into R, assigning it to an object named
rest_spend
Exercises
Question 1
Examine the dataset, and perform any necessary and appropriate data management steps.
Question 2
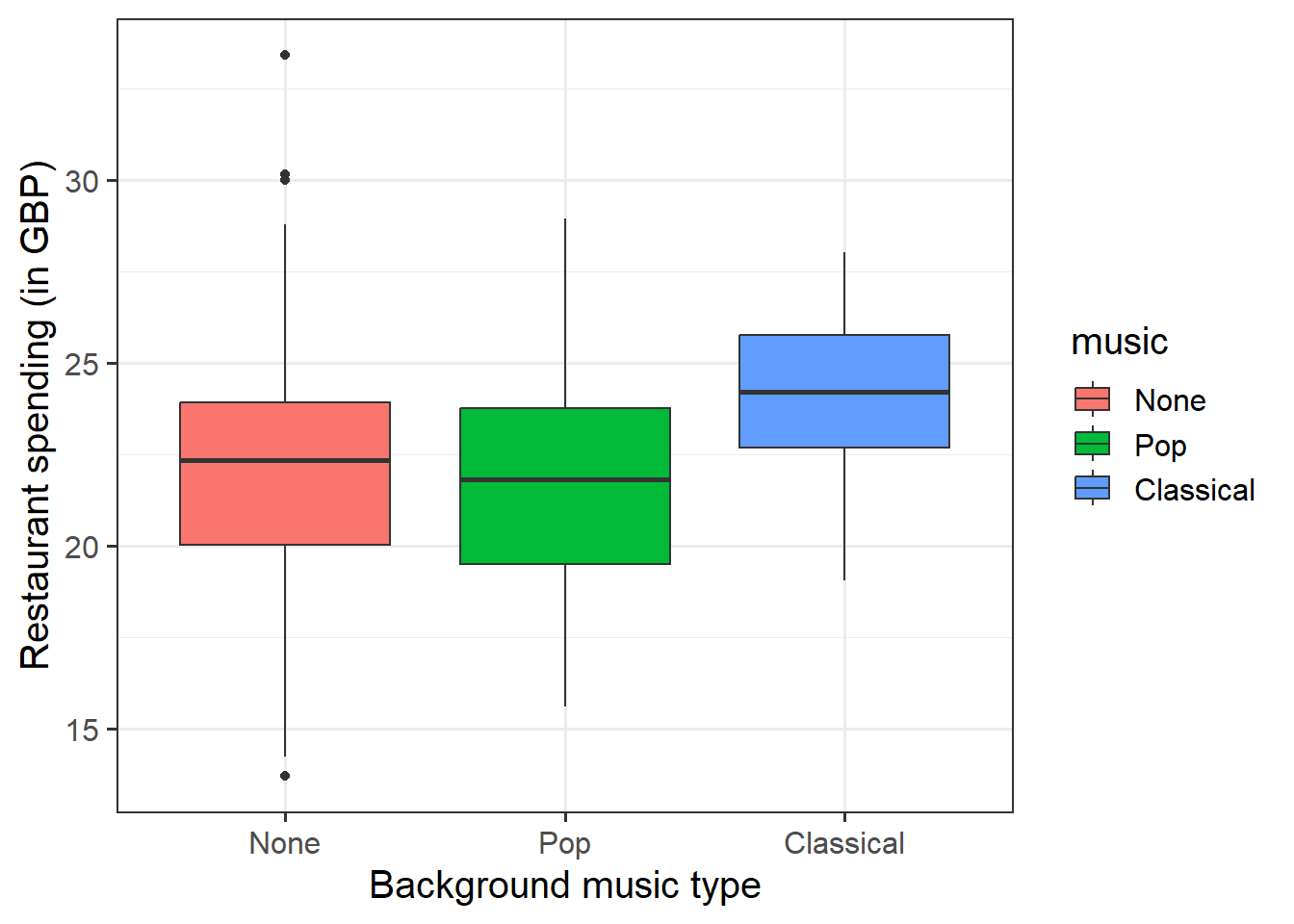
Provide a table of descriptive statistics and visualise your data (remember to interpret your plot in the context of the research question).
Hint
For your table of descriptive statistics, both the
group_by()andsummarise()functions will come in handy here.When visualising the data, consider using
geom_boxplot()to visually explore the association between restaurant spending and music type.Make sure to comment on any observed differences among the sample means of the three background music types.
Dummy Coding
Question 3
Using dummy coding, choose an appropriate reference level to address the research question, and then formally state a linear model to investigate whether there are differences in restaurant spending based on background music conditions.
Describe and schematically represent the coding matrix used in the above model.
Hint
When you reorder the levels, you should end up with the following coding of group means if you choose ‘none’ as your reference group:
- \(\mu_1\) = mean of no music group
- \(\mu_2\) = mean of pop music group
- \(\mu_3\) = mean of classical music group
When schematically representing the coding scheme, you should produce a matrix/table of 0s and 1s.
Question 4
Fit the specified model, and assign it the name “mdl_rg” (for reference group constraint).
Interpret your coefficients in the context of the study.
Hint
Under the constraint \(\beta_1 = 0\), meaning that the first factor level is the reference group,
- \(\beta_0\) is interpreted as \(\mu_1\), the mean response for the reference group (group 1);
- \(\beta_i\) is interpreted as the difference between the mean response for group \(i\) and the reference group.
Question 5
Identify the relevant pieces of information from the commands anova(mdl_rg) and summary(mdl_rg) that can be used to conduct an ANOVA \(F\)-test against the null hypothesis that all population means are equal.
Interpret the \(F\)-test results in the context of the ANOVA null hypothesis, and present this output in an APA formatted table.
Hint
To create a table, you can use the kable() function from the kableExtra package here, just like you do for tables of descriptive statistics. Note that we need to list how many digits we want our values to be rounded to in our table: + Degrees of freedom are whole numbers, so 1 will suffice + for all others, we want 2 (in line with APA, but to avoid a \(p\)-value of zero, specify 10
Question 6
Obtain the estimated (or predicted) group means for the “None,” “Pop,” and “Classical” background music conditions by using the predict() function.
Hint
Step 1: Define a data frame with a column having the same name as the factor in the fitted model (i.e., music). Then, specify all the groups (= levels) for which you would like the predicted mean.
Step 2: Pass the data frame to the predict function using the newdata = argument. The predict() function will match the column named type with the predictor called type in the fitted model ‘mdl_rg’.
See Semester 1 Lab 3 Q8 for a worked example.
Sum to Zero Coding
Question 7
Using sum-to-zero coding, formally state a linear model to investigate whether there are differences in restaurant spending based on background music conditions.
Describe and schematically represent the coding matrix used in the above model.
Hint
When schematically representing the coding scheme, you should produce a matrix/table of 0s and 1s.
Question 8
Set the sum to zero constraint for the factor of background music.
Fit again the linear model, and assign the model the name ‘mdl_stz’.
Question 9
Interpret your coefficients in the context of the study.
Hint
Recall that under this constraint the interpretation of the coefficients becomes:
- \(\beta_0\) represents the grand mean
- \(\beta_i\) the effect due to group \(i\) — that is, the mean response in group \(i\) minus the grand mean
Comparing Approaches
Question 10
Compare the the predicted group means across both contrast approaches - do they match?
Is the model utility \(F\)-test still the same across both approaches? Why do you think it’s the case?
References
North, A., A. Shilcock, and D. Hargreaves. 2003. “The Effect of Musical Style on Restaurant Customers’ Spending.” Environment and Behavior 35: 712–18.