| variable | description |
|---|---|
| perc_recall | Percentage Recall - the percentage of correctly recalled items |
| group | Group - whether the individual was assigned to the roller-coaster (group = 0) or the meditation (group = 1) intervention condition |
| age | Age - individual's age (in years) |
Sample Size and Power Analysis
Learning Objectives
At the end of this lab, you will:
- Understand how varying factors can influence power
- Be able to conduct power analyses using the
pwrpackage
What You Need
Required R Packages
Remember to load all packages within a code chunk at the start of your RMarkdown file using library(). If you do not have a package and need to install, do so within the console using install.packages(" "). For further guidance on installing/updating packages, see Section C here.
For this lab, you will need to load the following package(s):
- tidyverse
- kableExtra
- pwr
Lab Data
You can download the data required for this lab here or read it in via this link https://uoepsy.github.io/data/recall_med_coast.csv.
Study Overview
Research Question
Do age and intervention type influence recall?
Setup
Setup
- Create a new RMarkdown file
- Load the required package(s)
- Read in the recall_med_coast dataset into R, assigning it to an object named
recdata
Question 1
Examine the dataset, and perform any necessary and appropriate data management steps.
Question 2
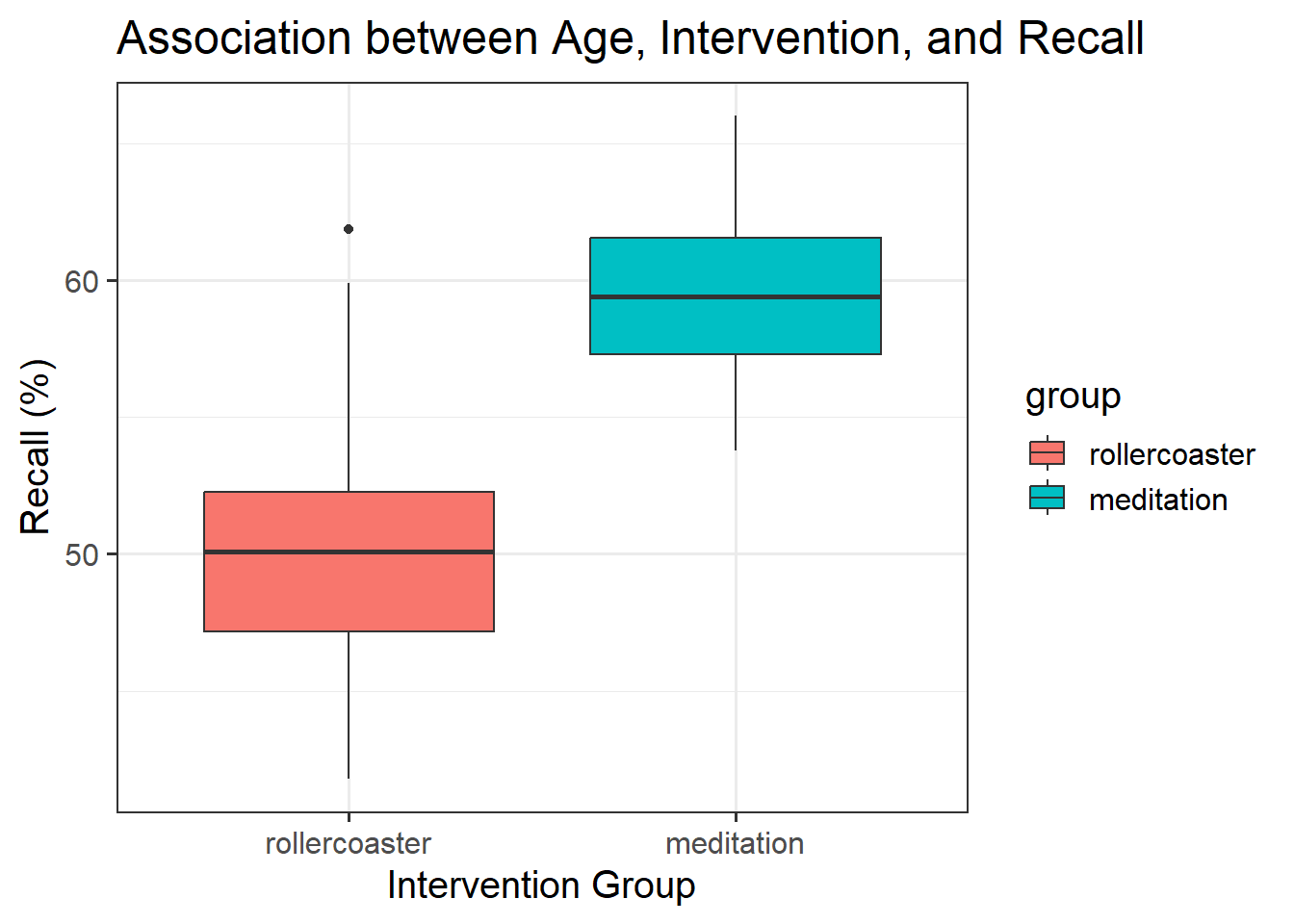
Provide a table of descriptive statistics and visualise your data.
Remember to interpret your plot in the context of the study.
Hint
- For your table of descriptive statistics, both the
group_by()andsummarise()functions will come in handy here. - Recall that when visualising a continuous outcome across groups,
geom_boxplot()may be most appropriate to use. - Make sure to comment on any observed differences among the sample means of the four treatment conditions.
Question 3
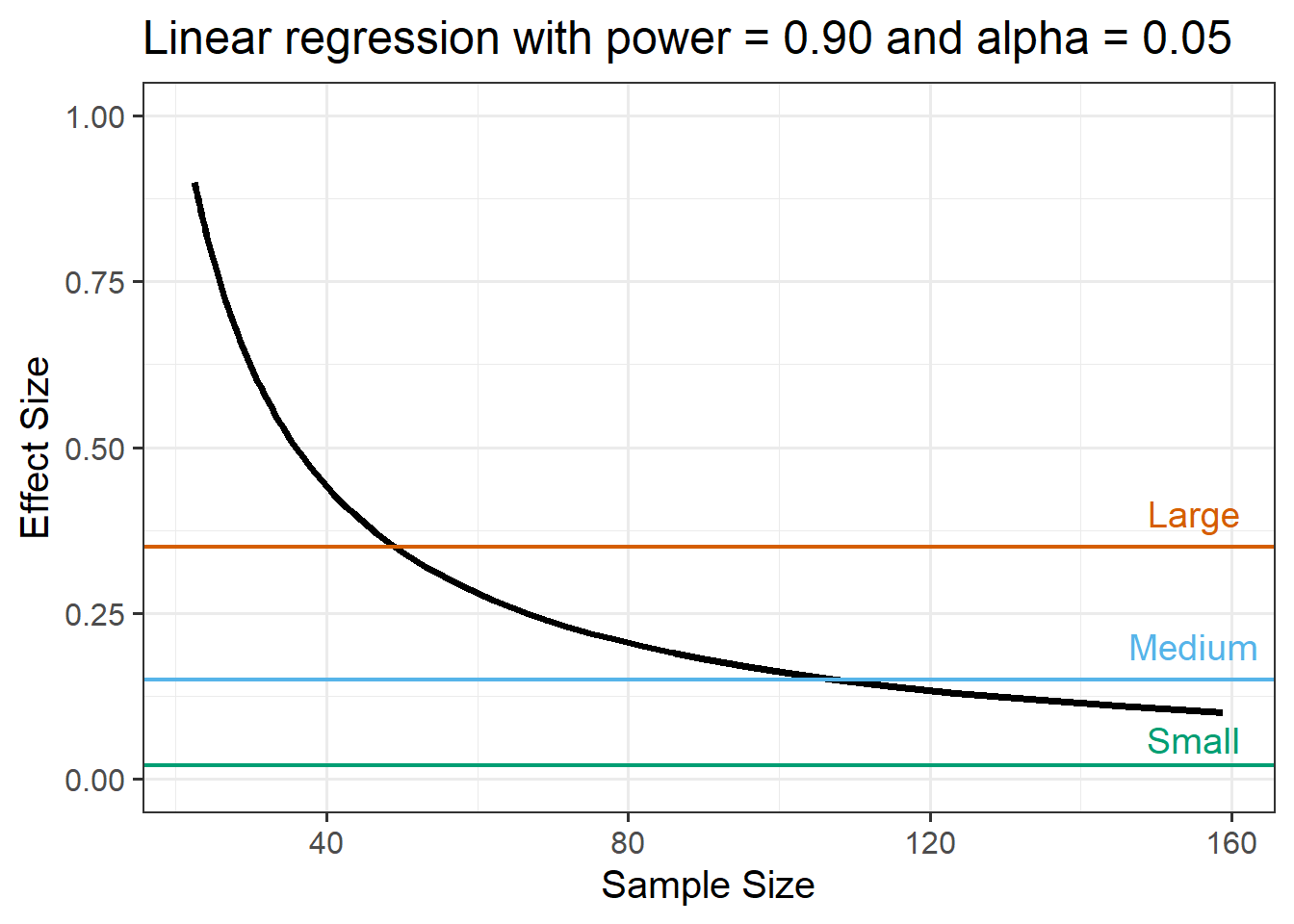
Using a significance level (\(\alpha\)) of .05, what sample size (\(n\)) would you require to check whether any of the predictors (and interaction) influenced recall scores with a 90% chance?
Because you do not know the effect size, assume Cohen’s guideline for linear regression and, to be on the safe side, consider the ‘small’ value.
Hint
In linear regression, the relevant function in R is:
pwr.f2.test(u = , v = , f2 = , sig.level = , power = )Where:
-
u= numerator degrees of freedom = number predictors in the model (\(k\)) -
v= denominator degrees of freedom = \(v = n-k-1\) -
f2= effect size. Cohen suggests effect size cut-off values of \(.02\) (small), \(.15\) (moderate), and \(.35\) (large) -
sig.level= significance level -
power= level of power
Question 4
Using the same \(\alpha\) (.05) and power, what would be the sample size if you assumed effect size to be ‘medium’?
Hint
In linear regression, the relevant function in R is:
pwr.f2.test(u = , v = , f2 = , sig.level = , power = )Where:
-
u= numerator degrees of freedom = number predictors in the model (\(k\)) -
v= denominator degrees of freedom = \(v = n-k-1\) -
f2= effect size. Cohen suggests effect size cut-off values of \(.02\) (small), \(.15\) (moderate), and \(.35\) (large) -
sig.level= significance level -
power= level of power
Question 5
Using the same \(\alpha\) and power, what would be the sample size if you assumed effect size to be ‘large’?
Hint
In linear regression, the relevant function in R is:
pwr.f2.test(u = , v = , f2 = , sig.level = , power = )Where:
-
u= numerator degrees of freedom = number predictors in the model (\(k\)) -
v= denominator degrees of freedom = \(v = n-k-1\) -
f2= effect size. Cohen suggests effect size cut-off values of \(.02\) (small), \(.15\) (moderate), and \(.35\) (large) -
sig.level= significance level -
power= level of power
Question 6
Fit the following model using lm(), and assign it as an object with the name “recall_mdl1”.
\[ \text{Recall} = \beta_0 + \beta_1 \cdot Age + \epsilon \\ \] How much variance in recall scores does the model explain?
Question 7
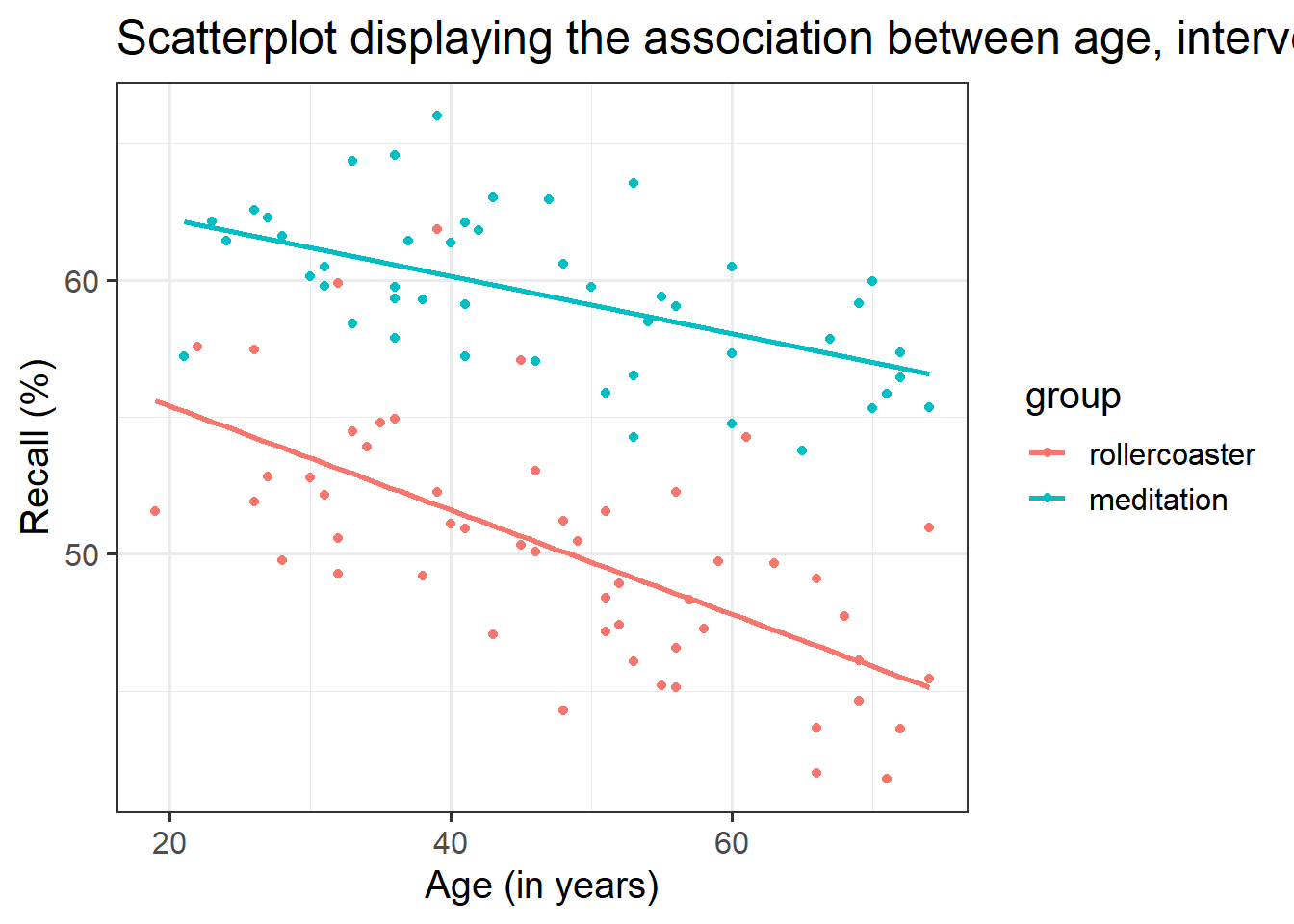
Use a scatterplot to visualise the association between recall and age by group.
Is there any evidence of an interaction between age and group?
Hint
- It might be useful to specify the
color =argument for your grouping variable - Consider using
geom_smooth()to superimpose the best-fitting line describing the association of interest for each intervention group.
Question 8
Imagine you found the R-squared that you computed above (Q6) in a paper, and you are using that to base your next study.
A researcher believes that the inclusion of intervention group and its interaction with age should explain an extra 50% of the variation in recall scores.
Using a significance level of 5%, what sample size should you use for your next data collection in order to discover that effect with a power of 0.9?
Question 9
Suppose that the aforementioned researcher made a mistake, and issues a corrected statement in which they state that the inclusion of intervention group and its interaction with age should explain an extra 5% of the variation in recall scores.
Using a significance level of 5%, what sample size should you use for your next data collection in order to discover that effect with a power of 0.9?
Question 10
A colleague produces a visualisation of the joint relationship between sample size and effect size via a power curve (with coloured lines representing large, medium, and small effect sizes).
Based on this, what feedback/comments might you share with them regarding sample size for their prospective study, and its relation to effect size?