| wellbeing | outdoor_time | social_int | location | routine |
|---|---|---|---|---|
| 30 | 7 | 8 | Suburb | Routine |
| 21 | 9 | 8 | City | No Routine |
| 38 | 14 | 10 | Suburb | Routine |
| 27 | 16 | 10 | City | No Routine |
| 20 | 1 | 10 | Rural | No Routine |
| 37 | 11 | 12 | Suburb | No Routine |
Model Fit and Standardization
Learning Objectives
At the end of this lab, you will:
- Understand how to interpret significance tests for \(\beta\) coefficients
- Understand how to calculate the interpret \(R^2\) and adjusted-\(R^2\) as a measure of model quality.
- Understand the calculation and interpretation of the \(F\)-test of model utility.
- Understand how to standardize model coefficients and when this is appropriate to do.
What You Need
Required R Packages
Remember to load all packages within a code chunk at the start of your RMarkdown file using library(). If you do not have a package and need to install, do so within the console using install.packages(" "). For further guidance on installing/updating packages, see Section C here.
For this lab, you will need to load the following package(s):
- tidyverse
- patchwork
- sjPlot
Lab Data
You can download the data required for this lab here or read it in via this link https://uoepsy.github.io/data/wellbeing.csv.
Note: this is the same data as Lab 3.
Study Overview
Research Question
Is there an association between well-being and time spent outdoors after taking into account the association between well-being and social interactions?
Setup
Setup
- Create a new RMarkdown file
- Load the required package(s)
- Read the wellbeing dataset into R, assigning it to an object named
mwdata
Exercises
Question 1
Specify and fit a linear model to investigate how wellbeing (WEMWBS scores) are associated with time spent outdoors after controlling for the number of social interactions.
Next, check the summary() output from the model.
Question 2
Formally state:
- your chosen significance level
- the null and alternative hypotheses
Lab Purpose
In this lab (Lab 4), you will focus on the statistics contained within the highlighted sections of the summary() output below. You will be both calculating these by hand and deriving via R code before interpreting these values in the context of the research question following APA guidelines.
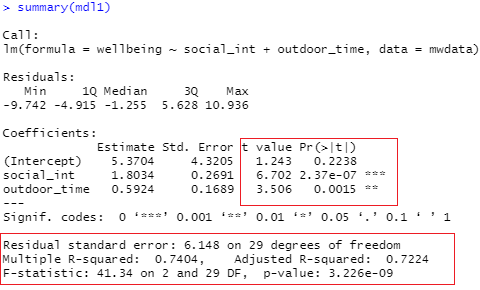
Question 3
Test the hypothesis that the population slope for outdoor time is zero — that is, that there is no linear association between wellbeing and outdoor time (after controlling for the number of social interactions) in the population.
Hint
Recall the formula for obtaining a test statistic:
A test statistic for the null hypothesis \(H_0: \beta_j = 0\) is \[ t = \frac{\hat \beta_j - 0}{SE(\hat \beta_j)} \] which follows a \(t\)-distribution with \(n-k-1 = n - 2 - 1 = n - 3\) degrees of freedom.
Question 4
Obtain 95% confidence intervals for the regression coefficients, and write a sentence about each one.
Hint
Recall the formula for obtaining a confidence interval:
A confidence interval for the population slope is \[ \hat \beta_j \pm t^* \cdot SE(\hat \beta_j) \] where \(t^*\) denotes the critical value chosen from t-distribution with \(n-k-1 = n - 2 - 1 = n - 3\) degrees of freedom for a desired \(\alpha\) level of confidence.
Question 5
What is the proportion of the total variability in wellbeing scores explained by the model?
Hint
The question asks to compute the value of \(R^2\). Since the model includes 2 predictors, you should report the Adjusted \(R^2\).
Question 6
Perform a model utility test at the 5% significance level and report your results.
In other words, conduct an \(F\)-test against the null hypothesis that the model is ineffective at predicting wellbeing scores using social interactions and outdoor time by computing the \(F\)-statistic using its definition.
Hint
The F-ratio is used to test the null hypothesis that all regression slopes are zero.
It is called the F-ratio because it is the ratio of the how much of the variation is explained by the model (per paramater) versus how much of the variation is left unexplained in the residuals (per remaining degrees of freedom).
\[ F_{df_{model},df_{residual}} = \frac{MS_{Model}}{MS_{Residual}} = \frac{SS_{Model}/df_{Model}}{SS_{Residual}/df_{Residual}} \\ \quad \\ \begin{align} & \text{Where:} \\ & df_{model} = k \\ & df_{residual} = n-k-1 \\ & n = \text{sample size} \\ & k = \text{number of explanatory variables} \\ \end{align} \]
Question 7
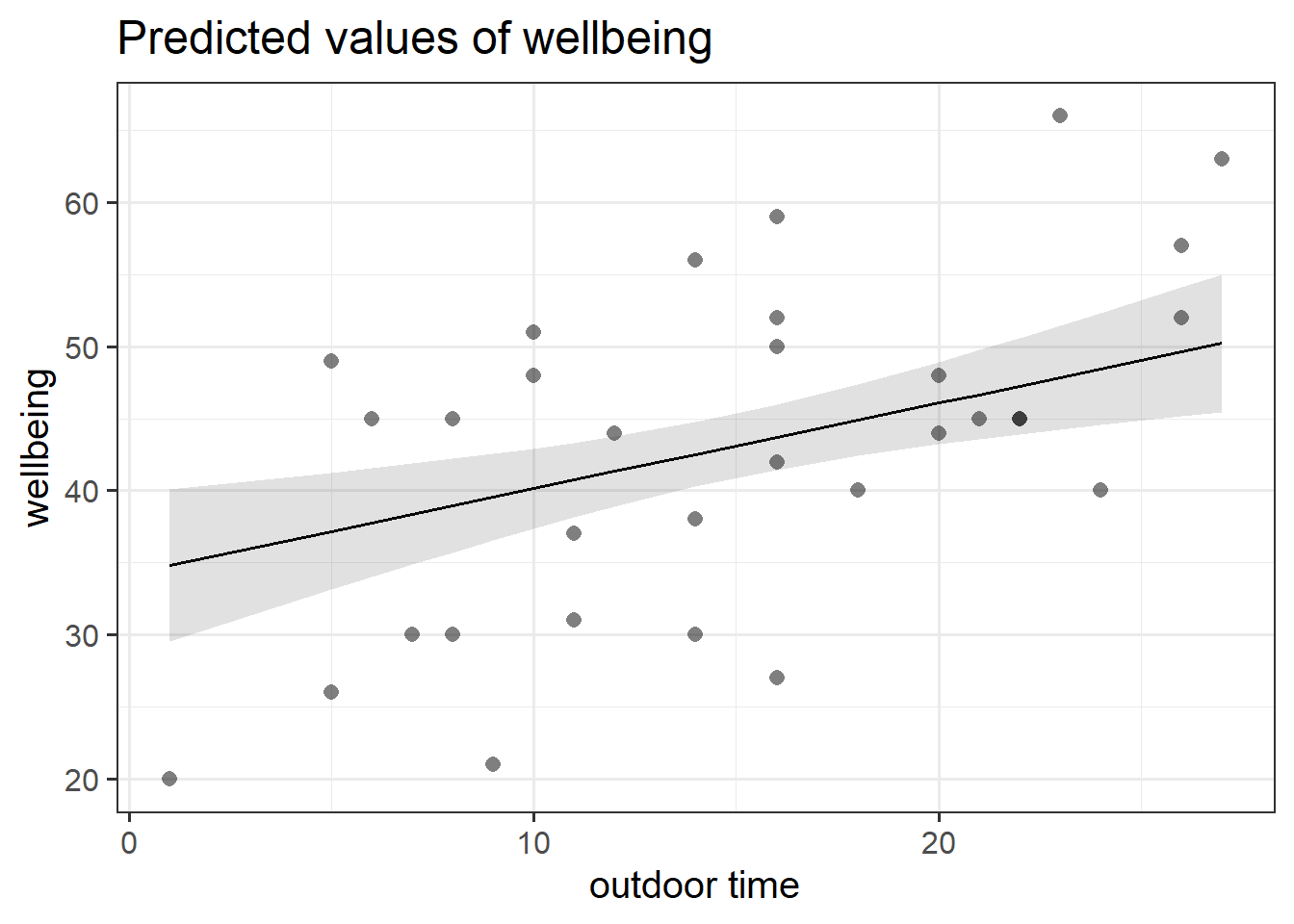
Produce a visualisation of the association between wellbeing and outdoor time, after accounting for social interactions.
Hint
To visualise just one association, you might need to specify the terms argument in plot_model(). Don’t forget you can look up the documentation by typing ?plot_model in the console.
Standardization
Question 8
Fit the regression model using the standardized response and explanatory variables.
Hint
You can either:
- Add to the “mwdata” dataset three variables called
z_wellbeing,z_social_int, andz_outdoor_timerepresenting the standardized welllbeing, social interactions and outdoor time variables, respectively.
Recall the formula for the \(z\)-score: \[ z_x = \frac{x - \bar{x}}{s_x}, \qquad z_y = \frac{y - \bar{y}}{s_y} \]
OR
Question 9
Create a table to present your results from the standardized model.
Hint
Use tab_model() from the sjPlot package.
Remember that you can rename your DV and IV labels by specifying dv.labels and pred.labels.
Question 10
Interpret the standardized variables presented in the above table.