Contrasts, Study Design, & Factorial ANOVA
LEARNING OBJECTIVES
- Understand how to specify contracts to test specific effects.
- Understand different types of study design.
- Interpret interactions with effects coding.
Case Study - Contrasts
In the first section of this lab, you will be presented with a research question, and will need to go through the steps of describing, visualising, modelling, and interpreting the results.
Research Question: Does WPM differ by caffeine treatment condition?
To investigate if the number of words typed per minute (WPM) differs among caffeine treatment conditions, the researchers conducted an experiment where participants were randomly allocated to one of four treatment conditions. Two of these conditions included non-caffeinated drinks - control (water) and mint tea, and the other two caffeinated drinks - coffee and red bull.
| Drink | Caffeine | Temp |
|---|---|---|
| Control (Water) | No | Cold |
| Red Bull | Yes | Cold |
| Coffee | Yes | Hot |
| Mint Tea | No | Hot |
The researchers were specifically interested in the following comparisons:
- Whether having some kind of caffeine (i.e., red bull / coffee), rather than no caffeine (i.e., control - water / mint tea), resulted in a difference in average WPM
- Whether there was a difference in average WPM between those with hot drinks (i.e., mint tea / coffee) in comparison to those with cold drinks (control - water / red bull)
- Load the
tidyversepackage. - Read the data into R using the function
read_csv()and name the datacaffeine. - Check for the correct coding of all variables (i.e., categorical variables should be factors and numeric variables should be numeric).
Numerically and visually summarise the caffeine dataset. Comment on any observed differences among treatment groups.

Set an appropriate reference group based on the research question.
Fit the following model, and assign it the name “caf_mdl1.”
Examine and describe the coefficients in the output of summary() before interpreting the F-test results from anova() in the context of the ANOVA null hypothesis.
\(\text{WPM} = \beta_0 + \beta_1 \cdot \text{Treatment (Category)} + \epsilon\)
The two planned comparisons that the researchers were interested in can be translated into the following research hypotheses:
\[\begin{aligned} 1. \quad H_0 &: \mu_\text{No Caffeine} = \mu_\text{Caffeine} \\ \quad H_0 &: \frac{1}{2} (\mu_\text{Control} + \mu_\text{Mint Tea}) = \frac{1}{2} (\mu_\text{Coffee} + \mu_\text{Red Bull}) \\ 2. \quad H_0 &: \mu_\text{Hot Drink} = \mu_\text{Cold Drink} \\ \quad H_0 &: \frac{1}{2} (\mu_\text{Coffee} + \mu_\text{Mint Tea}) = \frac{1}{2} (\mu_\text{Control} + \mu_\text{Red Bull}) \end{aligned}\]After checking the levels of the factor treatment, use emmeans to obtain the estimated treatment means and uncertainties for your factor. Hint use plot() to visualise this.
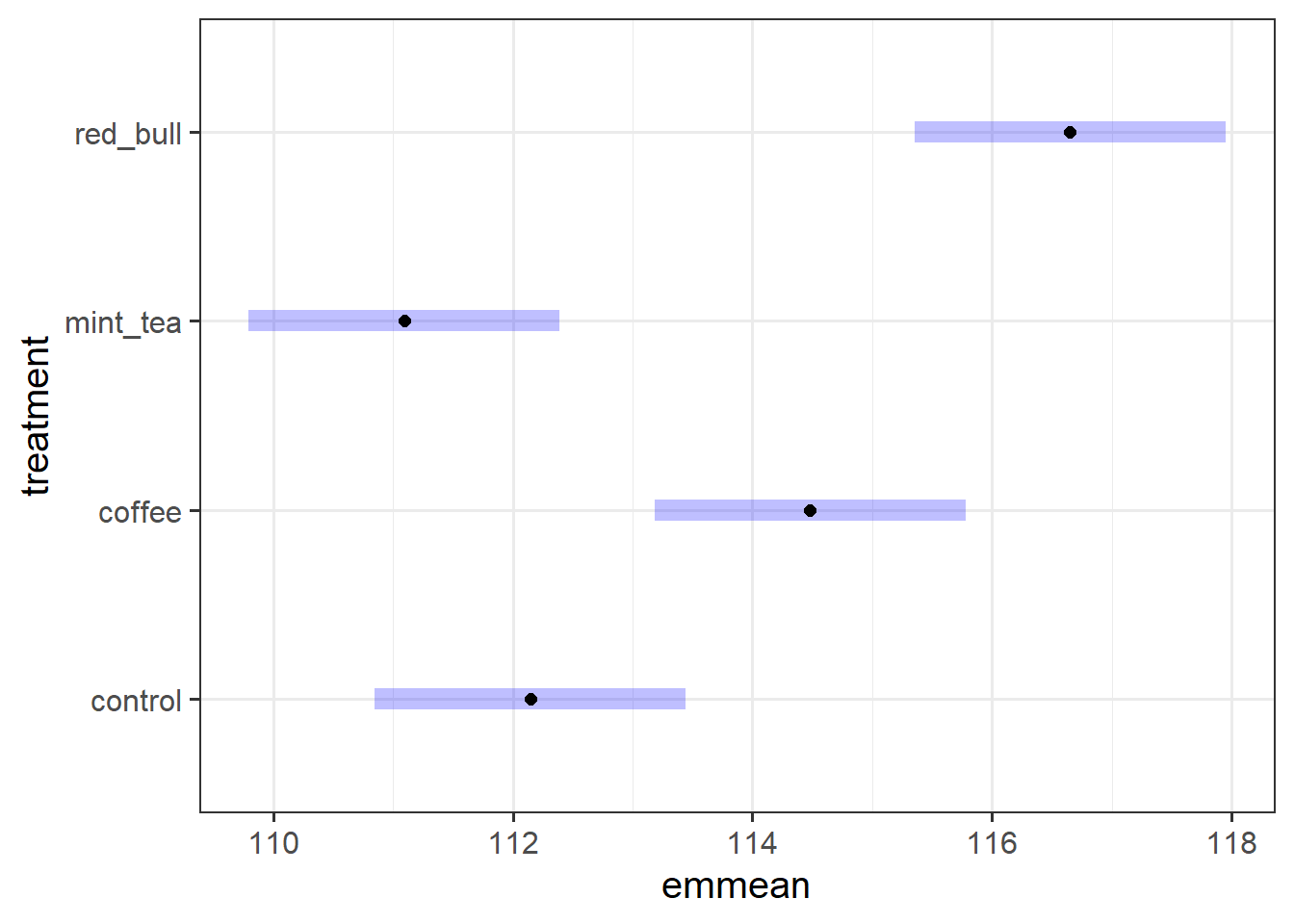
Specify the coefficients of the comparisons and run the contrast analysis. Obtain 95% confidence intervals, and then interpret your results in relation to the researchers hypotheses.
Study Design
For each of the below experiment descriptions, note (1) the design, (2) number of variables of interest, (3) levels of categorical variables, (4) what you think the reference group should be and why.
A group of researchers were interested in whether sleep deprivation influenced reaction time. They hypothesised that sleep deprived individuals would have slower reaction times than non-sleep deprived individuals.
To test this, they recruited 60 participants who were matched on a number of demographic variables including age and sex. One member of each pair (e.g., female aged 18) was placed into a different sleep condition - ‘Sleep Deprived’ (4 hours per night) or ‘Non-Sleep Deprived’ (8 hours per night).
A group of researchers were interested in replicating an experiment testing the Stroop Effect.
They recruited 50 participants who took part in Task A (word colour and meaning are congruent) and Task B (word colour and meaning are incongruent) where they were asked to name the color of the ink instead of reading the word. The order of presentation was counterbalanced across participants. The researchers hypothesised that participants would take significantly more time (‘response time’ measured in seconds) to complete Task B than Task A.
You can test yourself here for fun: Stroop Task
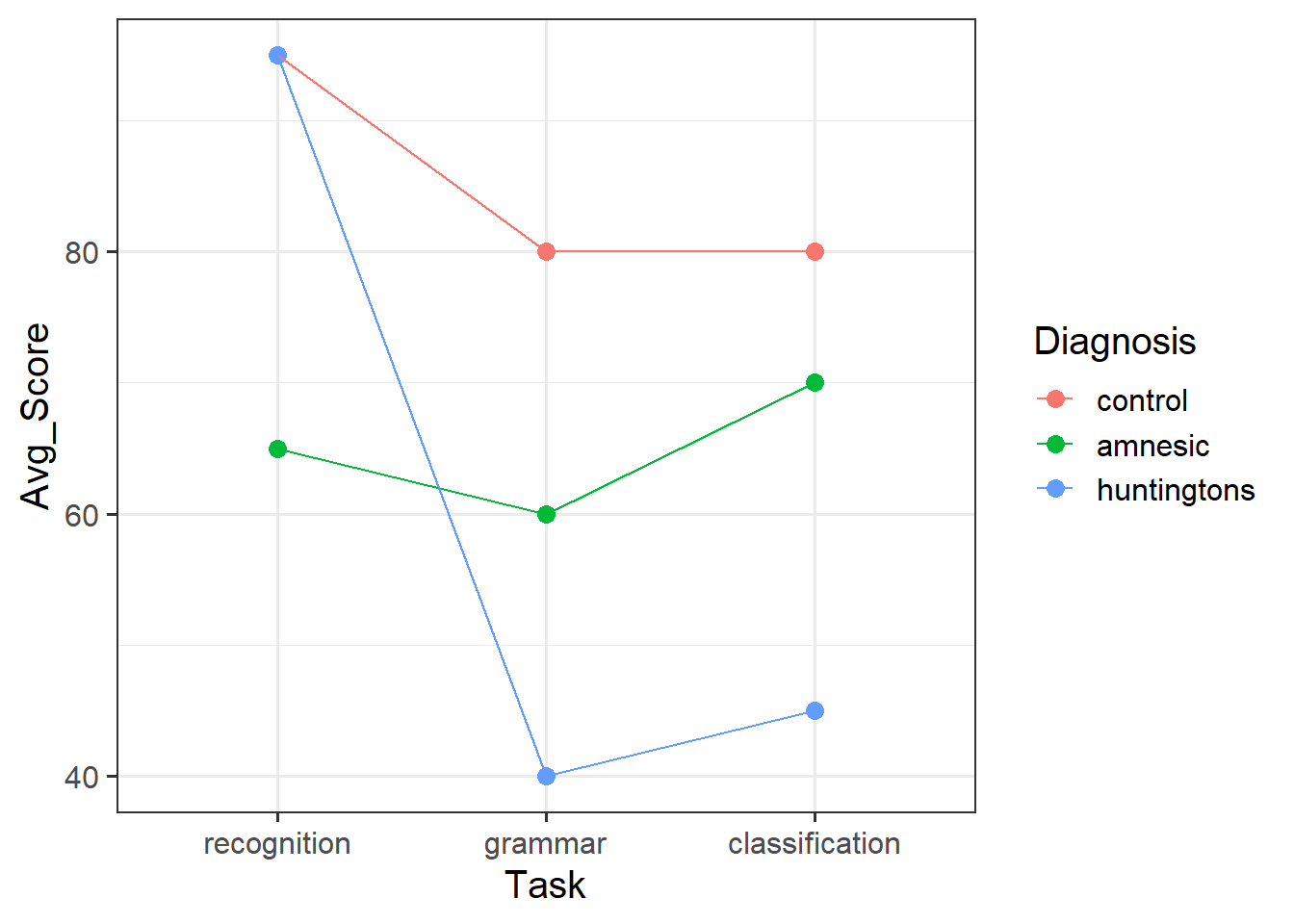
A group of researchers wanted to test a hypothesised theory according to which patients with amnesia will have a deficit in explicit memory but not implicit memory. Huntingtons patients, on the other hand, will display the opposite: they will have no deficit in explicit memory, but will have a deficit in implicit memory.
To test this, researchers designed a study that included two variables: ‘Diagnosis’ (Amnesic, Huntingtons, Control) and ‘Task’ (Grammar, Classification, Recognition) where participants were randomly assigned to a Task condition. The first two tasks (Grammar and Classification) are known to reflect implicit memory processes, whereas the Recognition task is known to reflect explicit memory processes.
Factorial ANOVA
Next week, the lab will focus on Experiment 3 described above. You have already worked with some of this data before - see semester 1 week 8 lab, but we now have a third task condition - Classification.
Data download link: https://uoepsy.github.io/data/cognitive_experiment.csv
We have data from the 45 participants (15 amnesiacs, 15 Huntington individuals, and 15 controls). Recall that study involves two factors, now with three levels each. For each combination of factor levels we have 5 observations:
| Diagnosis | grammar | classification | recognition |
|---|---|---|---|
| amnesic | 44, 63, 76, 72, 45 | 72, 66, 55, 82, 75 | 70, 51, 82, 66, 56 |
| huntingtons | 24, 30, 51, 55, 40 | 53, 59, 33, 37, 43 | 107, 80, 98, 82, 108 |
| control | 76, 98, 71, 70, 85 | 92, 65, 86, 67, 90 | 107, 80, 101, 82, 105 |
The five observations are assumed to come from a population having a specific mean. The population means corresponding to each combination of factor levels can be schematically written as:
\[ \begin{matrix} & & & \textbf{Task} & \\ & & (j=1)\text{ grammar} & (j=2)\text{ classification} & (j=3)\text{ recognition} \\ & (i=1)\text{ control} & \mu_{1,1} & \mu_{1,2} & \mu_{1,3} \\ \textbf{Diagnosis} & (i=2)\text{ amnesic} & \mu_{2,1} & \mu_{2,2} & \mu_{2,3} \\ & (i=3)\text{ huntingtons} & \mu_{3,1} & \mu_{3,2} & \mu_{3,3} \end{matrix} \]
Repeat the steps outlined in the Semester 1 Week 8 lab, but using the new dataset.
- Read the cognitive experiment data into R.
- Convert categorical variables into factors, and assign more informative labels to the factor levels according to the data description provided above.
- Relevel the
Diagnosisfactor to have ‘Control’ as the reference group. - Relevel the
Taskfactor to have ‘Recognition’ as the reference group. - Rename the response variable from
YtoScore. - Describe the data.
- Visualise the interaction between Diagnosis and Task.
The model with interaction is:
\[\begin{aligned} Score &= \beta_0 \\ &+ \beta_1 D_\text{Control} + \beta_2 D_\text{Amnesic} \\ &+ \beta_3 T_\text{Recognition} + \beta_4 D_\text{Grammar} \\ &+ \beta_5 (D_\text{Control} * T_\text{Recognition}) + \beta_6 (D_\text{Amnesic} * T_\text{Recognition}) \\ &+ \beta_7 (D_\text{Control} * T_\text{Grammar}) + \beta_8 (D_\text{Amnesic} * T_\text{Grammar}) \\ &+ \epsilon \end{aligned}\]Fit the above model, and set the the sum to zero constraint for Diagnosis of ‘Control’ and Task of ‘Recognition.’
Applying the sum to zero constraint, we would have:
\[\begin{aligned} \text{Intercept (global mean)} &= \beta_0 \frac{\mu_{1,1} + \mu_{1,2} + \cdots + \mu_{3,3}}{9} \\ \beta_{Huntingtons} &= -(\beta_1 + \beta_2) \\ \beta_{Classification} &= -(\beta_3 + \beta_4) \\ \beta_{Huntingtons:Classification} &= -(\beta_5 + \beta_6 + \beta_7 + \beta_8) \end{aligned}\]