Functions and models
Information about solutions
Solutions for these exercises are available immediately below each question.
We would like to emphasise that much evidence suggests that testing enhances learning, and we strongly encourage you to make a concerted attempt at answering each question before looking at the solutions. Immediately looking at the solutions and then copying the code into your work will lead to poorer learning.
We would also like to note that there are always many different ways to achieve the same thing in R, and the solutions provided are simply one approach.
LEARNING OBJECTIVES
- Review the main concepts from introductory statistics.
- Understand the concept of a function.
- Be able to discuss what a statistical model is.
- Understand the link between models and functions.
Refresher of basic terminology
Provide a short definition for each of these terms:
- (Observational) unit
- Variable
- Categorical variable
- Numeric variable
- Response/dependent variable
- Explanatory/independent variable
- Observational study
- Experiment
Functions and mathematical models
Consider the function \(y = 2 + 5 \ x\).
- Identify the independent variable
- Identify the dependent variable
- Describe in words what the function does, and compute the output for the following input: \[ x = \begin{bmatrix} 2 \\ 6 \end{bmatrix} \]
Write down in words and in symbols the function summarising the relationship between the side of a square and its perimeter.
Hint: We are interested in how the perimeter varies as a function of its side. Hence, the perimeter is the dependent variable, and the side is the independent variable.
In today’s lab you will compute the output of functions and plot them. To do so, you will need functionality from the tidyverse package such as tibble(), mutate(), and ggplot(). If you don’t have the package installed, go to the RStudio menu, select Tools, click Install Packages, type tidyverse and click install.
Load the tidyverse package.
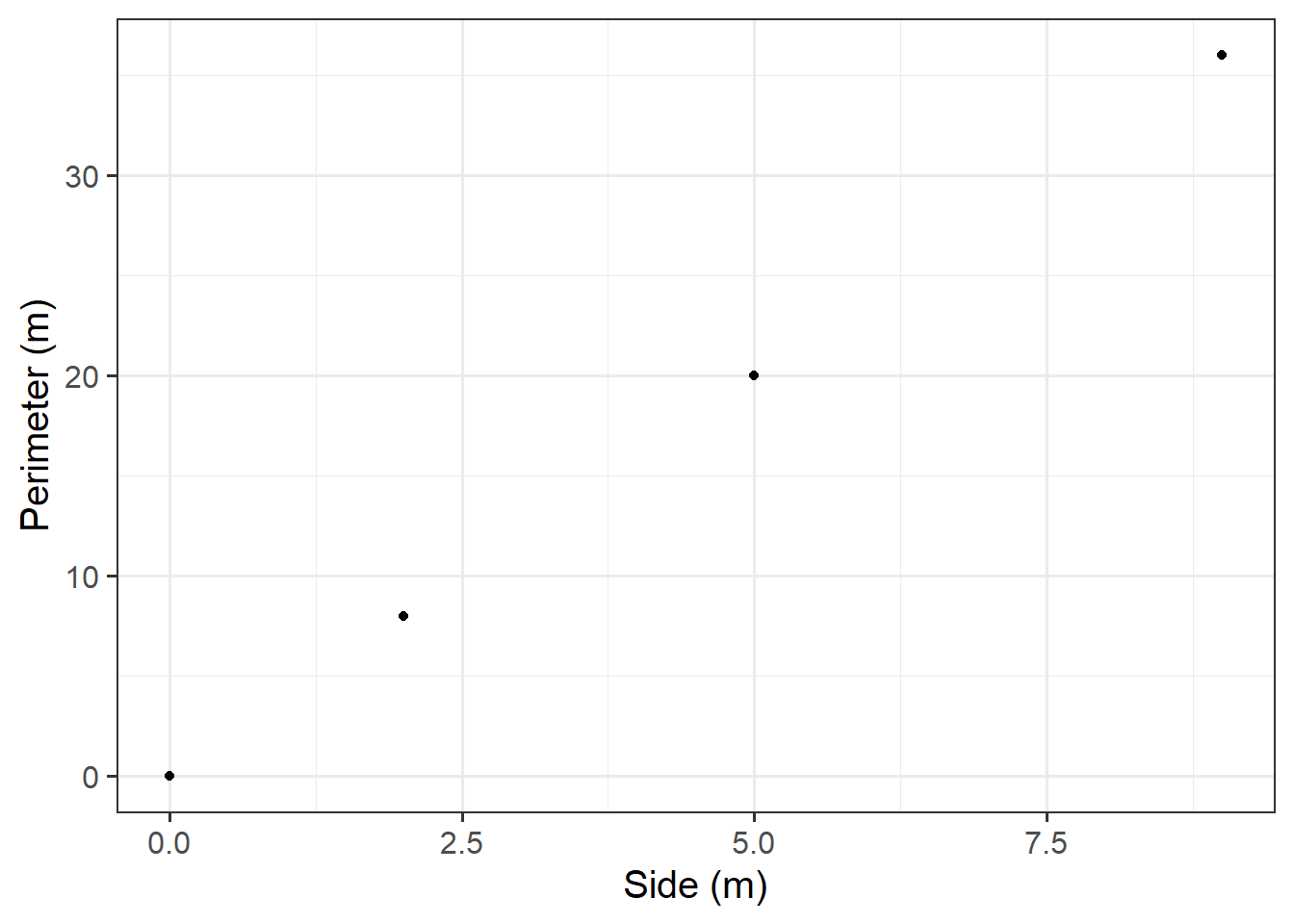
Create a data set called squares containing the perimeter of squares having sides of length \(0, 2, 5, 9\) metres.
Hint: Remember that to combine multiple numbers together we use the function c().
Plot the squares data as points.
Now, instead of just 4 points, we will obtain many more, one hundred, and use them to visualise the relationship between side and perimeter of squares.
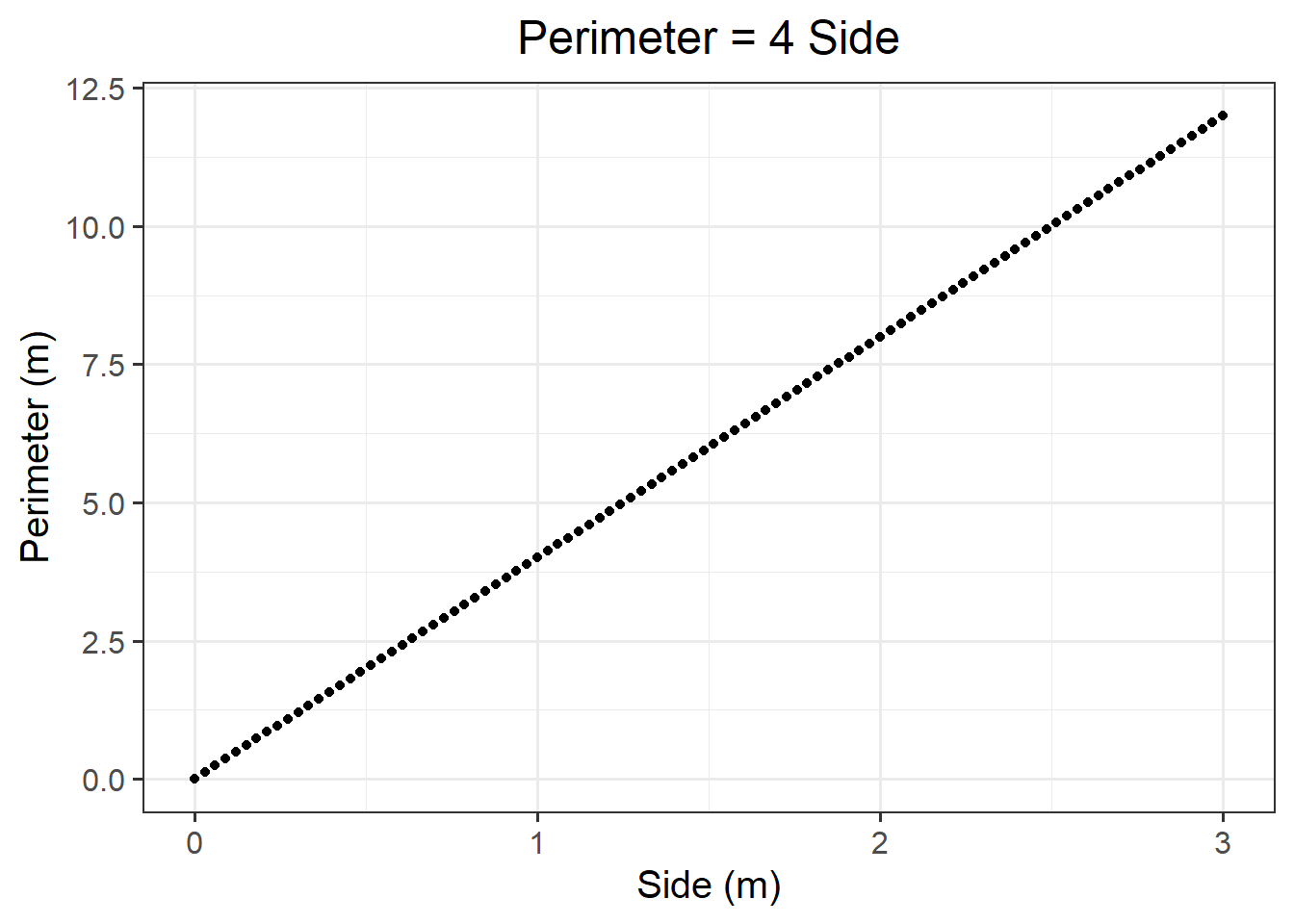
Create a sequence of one hundred side lengths (x) going from 0 to 3 metres.
Compute the corresponding perimeters (y).
Plot the side and perimeter data as points on a graph.
Visualise the functional relationship between side and perimeter of squares. To do so, use the function geom_line() to connect the computed points with lines.
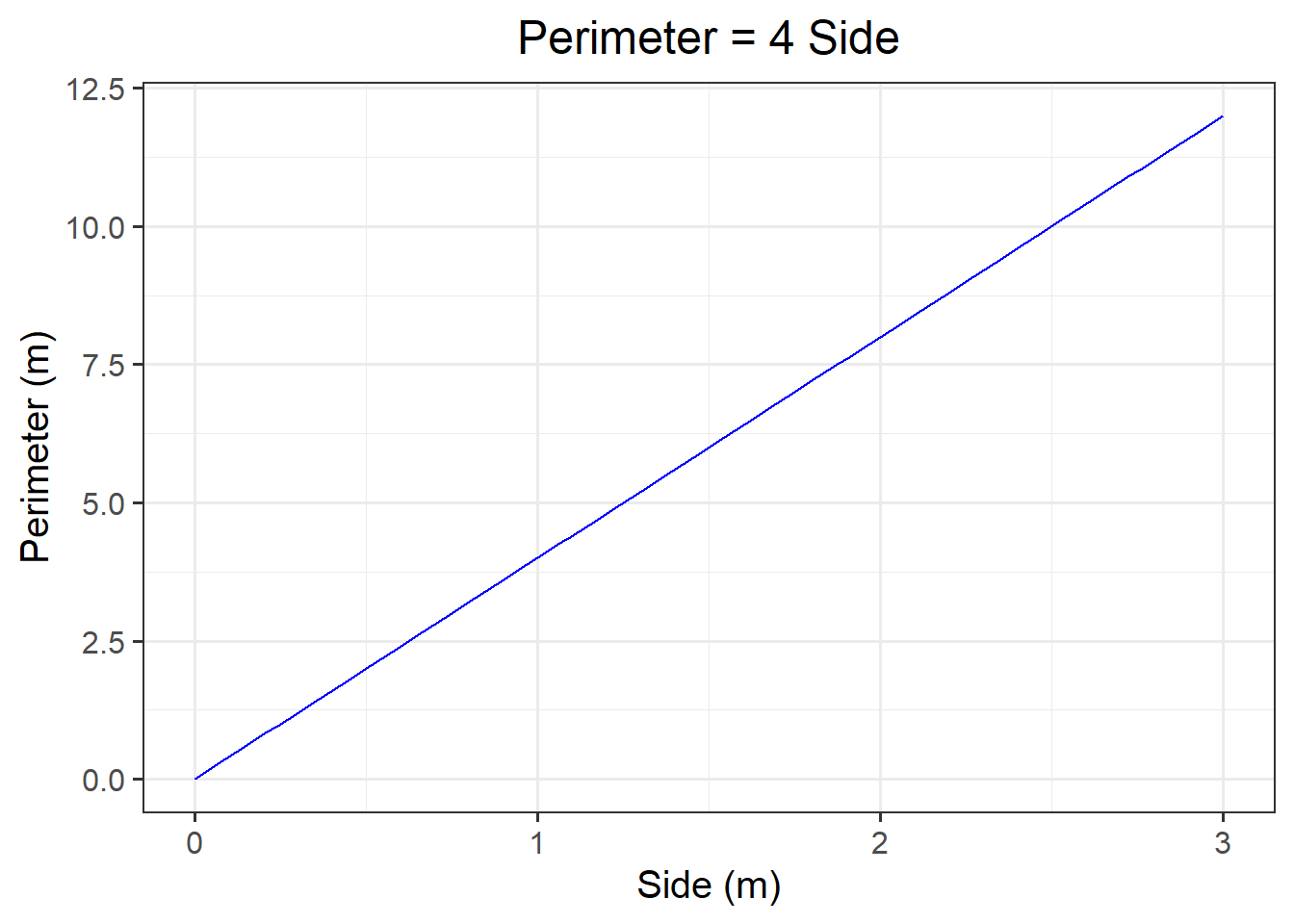
The function \(y = 4 \ x\) that you plotted above is an example of a function representing a mathematical model.
We typically validate a model using experimental data. However, we all know how squares work and that two squares with the same side will have the same perimeter. Hence this is a deterministic model as it is a model of an exact relationship.
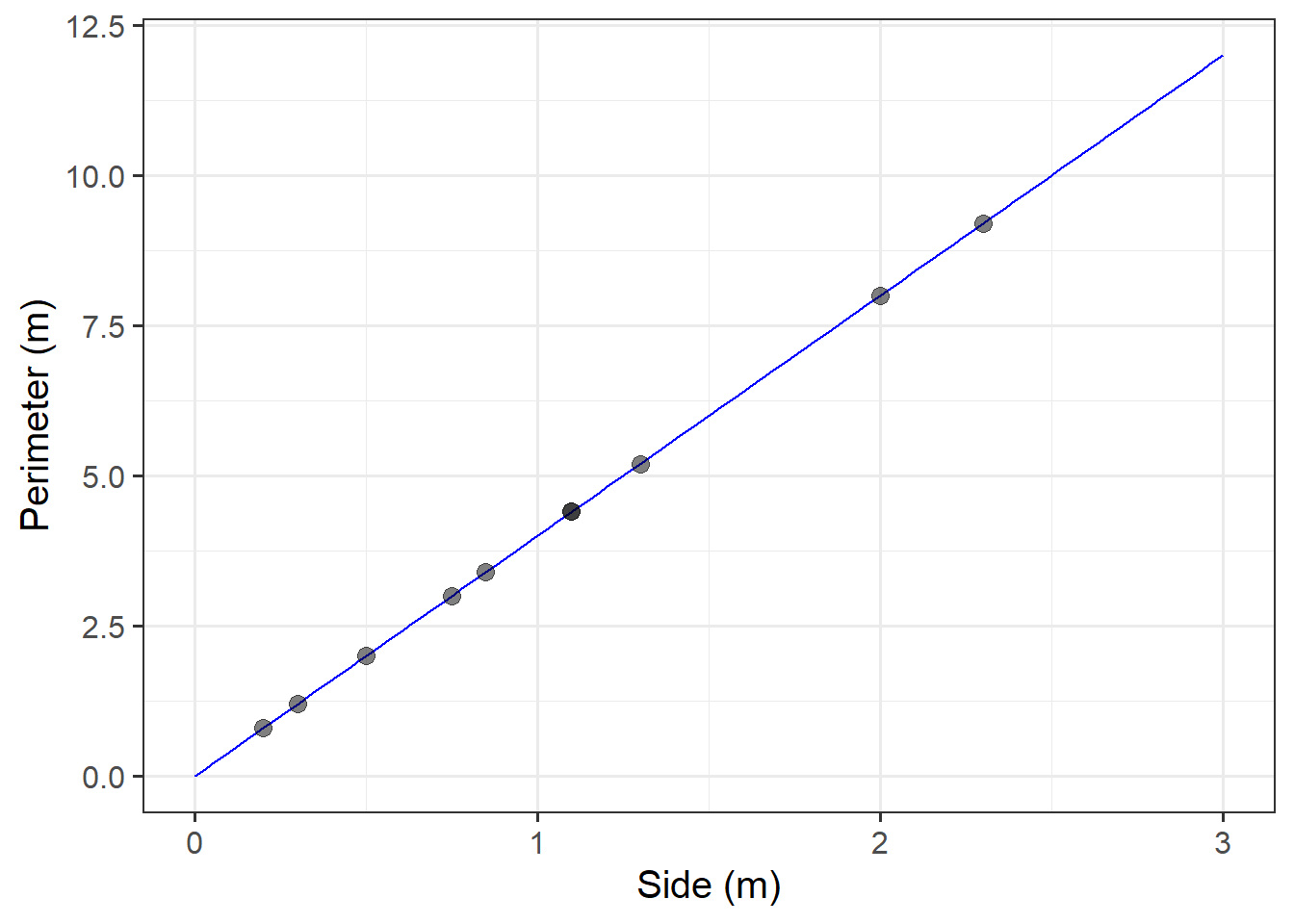
The Scottish National Gallery kindly provided us with measurements of side and perimeter (in metres) for a sample of 10 square paintings.
The data are provided below:
sng <- tibble(
side = c(1.3, 0.75, 2, 0.5, 0.3, 1.1, 2.3, 0.85, 1.1, 0.2),
perimeter = c(5.2, 3.0, 8.0, 2.0, 1.2, 4.4, 9.2, 3.4, 4.4, 0.8)
)Plot the mathematical model of the relationship between side and perimeter for squares, and superimpose on top the experimental data from the Scottish National Gallery.
Use the mathematical model to predict the perimeter of a painting with a side of 1.5 metres.

Note!
In this labs workbook we often provide examples of write-ups or interpretations of results in boxes that look like the one below. Keep an eye on them as they will help you in reporting your results!
Example!
Statistical models
Consider now the relationship between height (in inches) and handspan (in cm). Utts and Heckard (2015) provides data for a sample of 167 students which reported their height and handspan as part of a class survey.
Read the handheight data into R and name the data set handheight.
Investigate how handspan varies as a function of height for the students in the sample.
Do you notice any outliers or points that do not fit with the pattern in the rest of the data?
Comment on any main differences you notice with the relationship between side and perimeter of squares.
Hint: Use a scatterplot to visualise the relationship between two numeric variables.
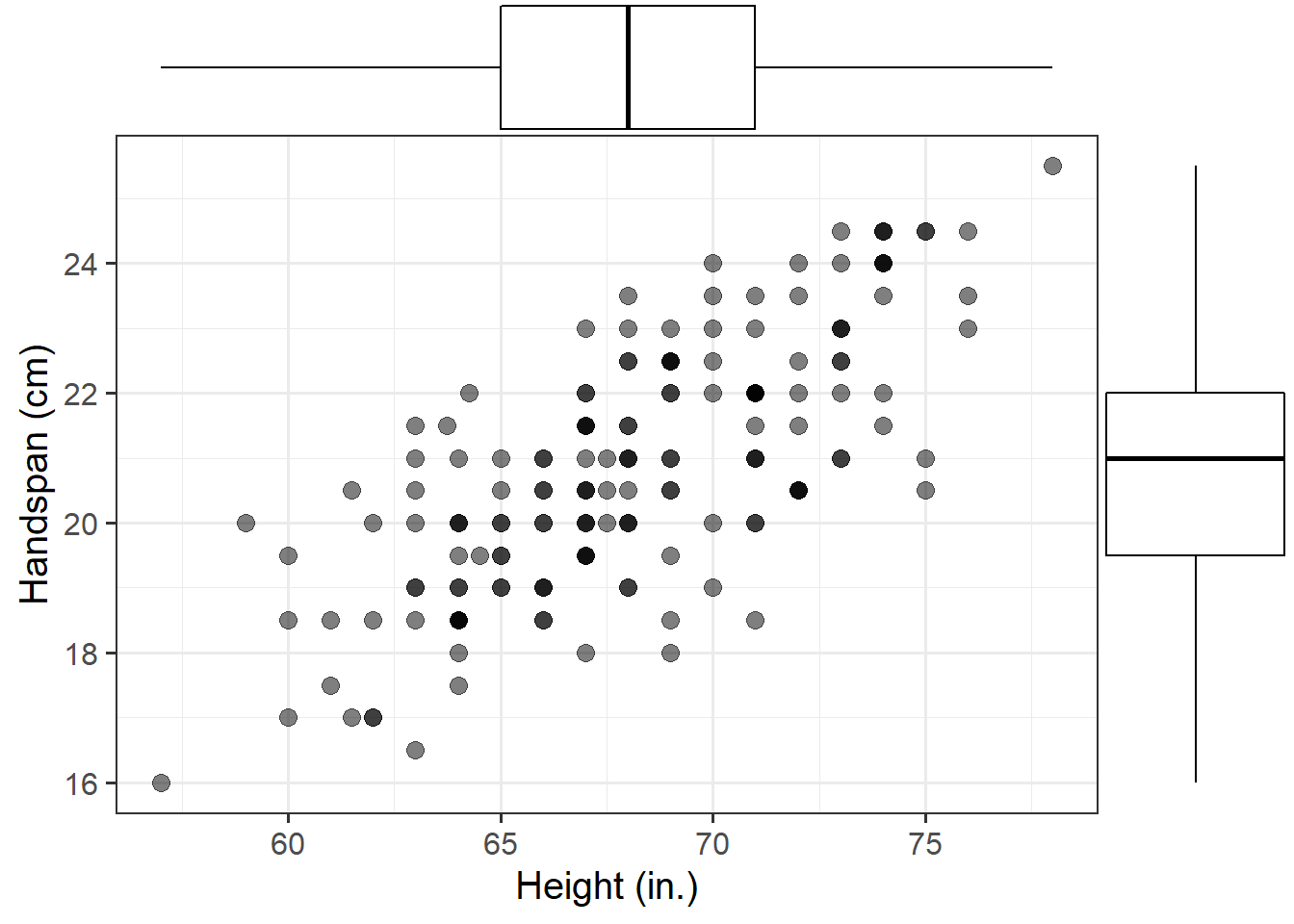
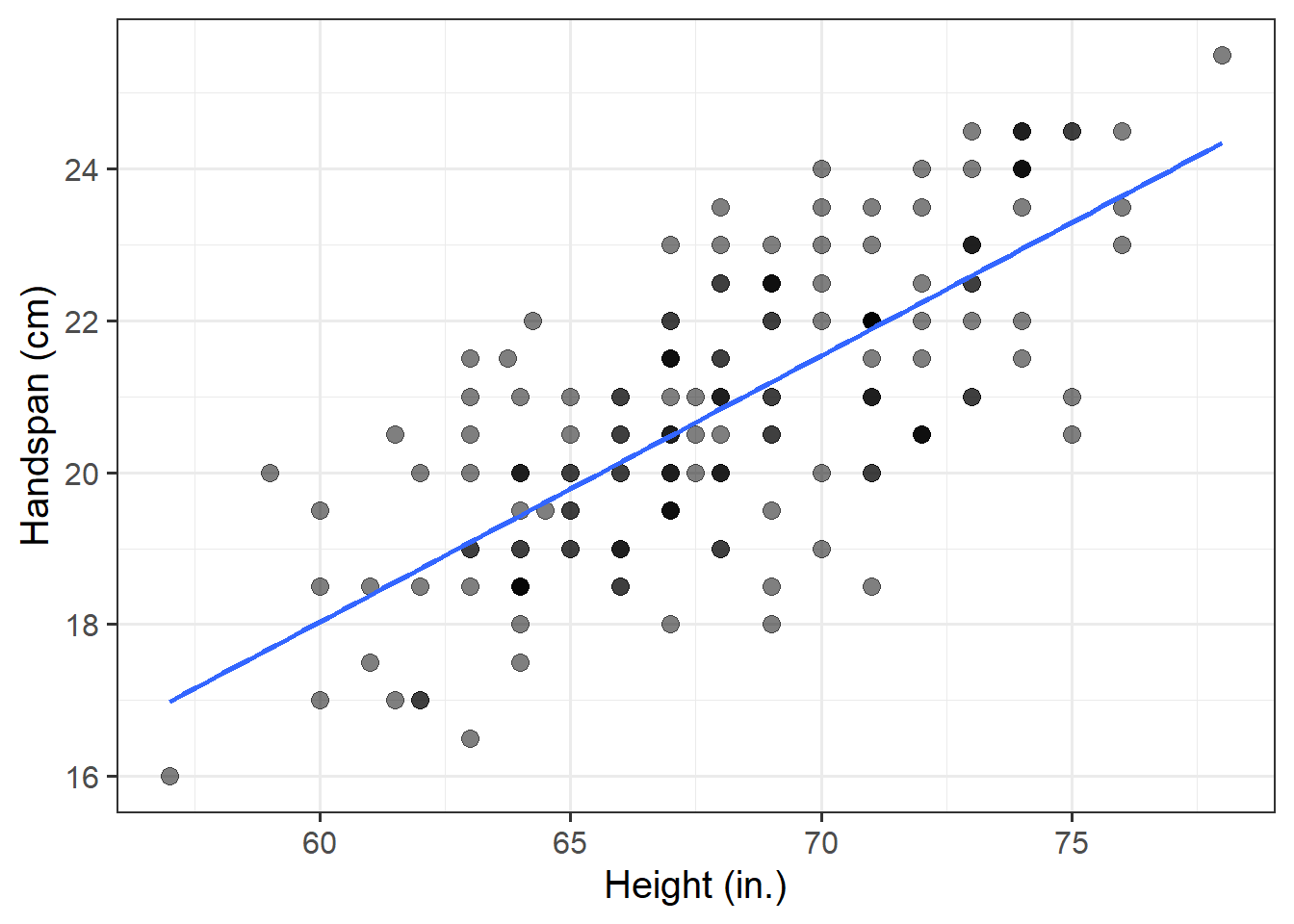
Using the following command, superimpose on top of the scatterplot a best-fit line describing how handspan varies as a function of height.
For the moment, the argument se = FALSE tells R to not display uncertainty bands.
geom_smooth(method = lm, se = FALSE)Comment on any differences you notice with the line summarising the linear relationship between side and perimeter.
The mathematical model \[ Perimeter = 4 * Side \] or, equivalently, \[ y = 4 * x \] represents the exact relationship between side and perimeter of squares.
Contrary to the relationship represented by the mathematical model above, the relationship between height and handspan shows deviations from the “average pattern.” Hence, we need to create a model that allows for deviations from the linear relationship. This is called a statistical model.
A statistical model includes both a deterministic function and a random error term: \[ Handspan = \beta_0 + \beta_1 * Height + \epsilon \] or, in short, \[ y = \underbrace{\beta_0 + \beta_1 * x}_{\text{function of }x} + \underbrace{\epsilon}_{\text{random error}} \]
The deterministic function need not be linear if the scatterplot displays signs of nonlinearity. In the equation above, the terms \(\beta_0\) and \(\beta_1\) are numbers specifying where the line going through the data meets the y-axis and its slope (rate of increase/decrease).
The line of best-fit is given by:1 \[ \widehat{Handspan} = -3 + 0.35 \ Height \]
What is your best guess for the handspan of a student who is 73in tall?
And for students who are 5in?

References
Yes, the error term is gone. This is because the line of best-fit gives you the prediction of the average handspan for a given height, and not the individual handspan of a person, which will almost surely be different from the prediction of the line.↩︎