Interactions: Numeric * Categorical
Information about solutions
Solutions for these exercises are available immediately below each question.
We would like to emphasise that much evidence suggests that testing enhances learning, and we strongly encourage you to make a concerted attempt at answering each question before looking at the solutions. Immediately looking at the solutions and then copying the code into your work will lead to poorer learning.
We would also like to note that there are always many different ways to achieve the same thing in R, and the solutions provided are simply one approach.
Be sure to check the solutions to last week’s exercises.
You can still ask any questions about previous weeks’ materials if things aren’t clear!
LEARNING OBJECTIVES
- Understand the concept of an interaction.
- Interpret the meaning of a numeric * categorical interaction.
- Understand the principle of marginality and why this impacts modelling choices with interactions.
- Visualize and probe interactions.
Exercises
Reseachers have become interested in how the number of social interactions might influence mental health and wellbeing differently for those living in rural communities compared to those in cities and suburbs. They want to assess whether the effect of social interactions on wellbeing is moderated by (depends upon) whether or not a person lives in a rural area.
Create a new RMarkdown file, load the tidyverse package, and read in the wellbeing data into R.
The data is available at the following link: https://uoepsy.github.io/data/wellbeing.csv
Count the number of respondents in each location (City/Location/Rural).
Open-ended: Do you think there is enough data to answer this question?
Research Question: Does the relationship between number of social interactions and mental wellbeing differ between rural and non-rural residents?
To investigate how the relationship between the number of social interactions and mental wellbeing might be different for those living in rural communities, the researchers conduct a new study, collecting data from 200 randomly selected residents of the Edinburgh & Lothian postcodes.
Specify a multiple regression model to answer the research question.
Read in the data, and assign it the name “mwdata2.” Then fully explore the variables and relationships which are going to be used in your analysis.
“Except in special circumstances, a model including a product term for interaction between two explanatory variables should also include terms with each of the explanatory variables individually, even though their coefficients may not be significantly different from zero. Following this rule avoids the logical inconsistency of saying that the effect of \(X_1\) depends on the level of \(X_2\) but that there is no effect of \(X_1\).”
— Ramsey and Schafer (2012)
- Tip 1: Install the
psychpackage (remember to use the console, not your script to install packages), and then load it (load it in your script). Thepairs.panels()function will plot all variables in a dataset against one another. This will save you the time you would have spent creating individual plots.
- Tip 2: Check the “location” variable. It currently has three levels (Rural/Suburb/City), but we only want two (Rural/Not Rural). You’ll need to fix this. One way to do this would be to use
ifelse()to define a variable which takes one value (“Rural”) if the observation meets from some condition, or another value (“Not Rural”) if it does not. Type?ifelsein the console if you want to see the help function. You can use it to add a new variable either insidemutate(), or usingdata$new_variable_name <- ifelse(test, x, y)syntax.
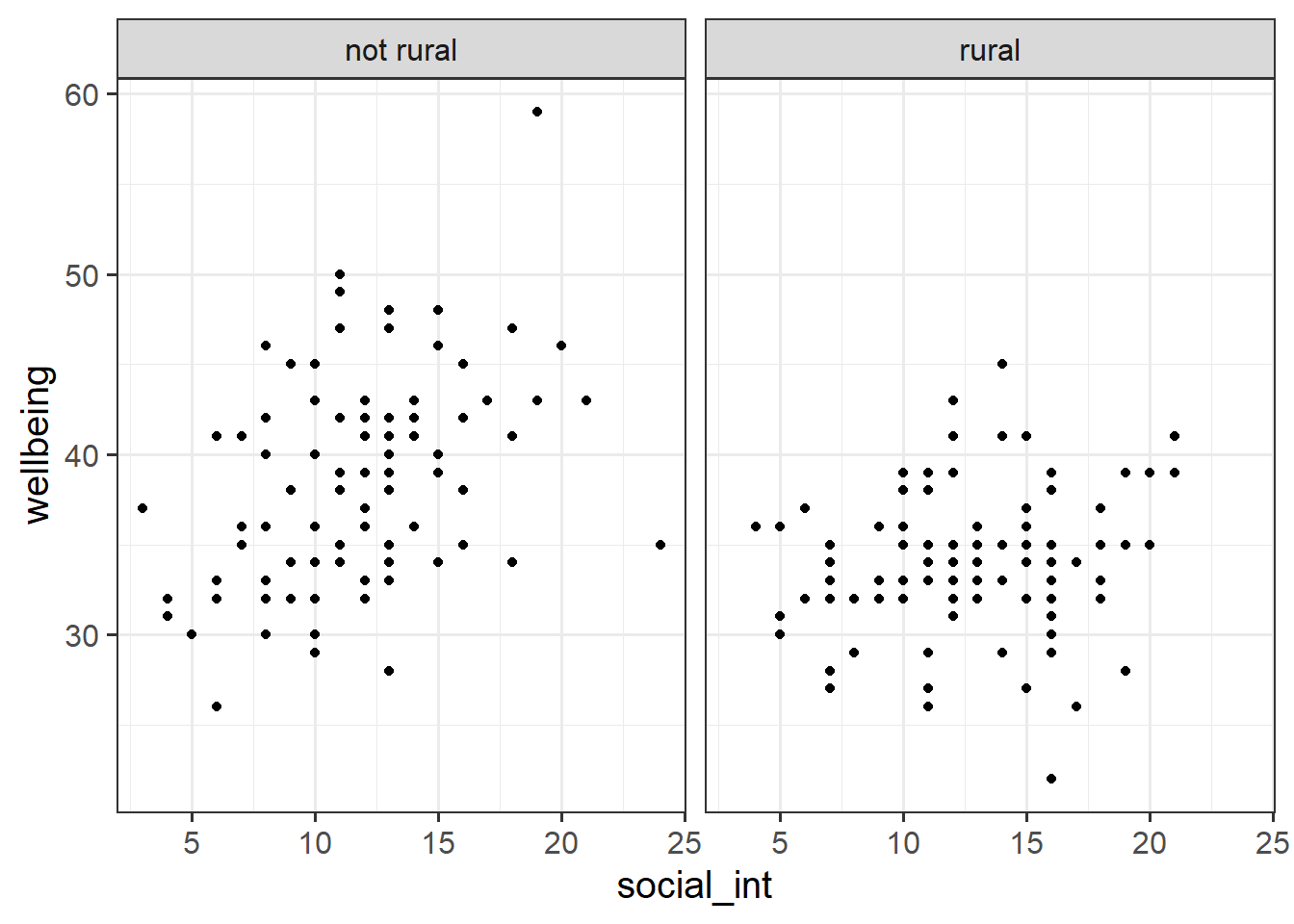
Produce a visualisation of the relationship between weekly number of social interactions and well-being, with separate facets for rural vs non-rural respondents.
Fit your model using lm(), and assign it as an object with the name “rural_mod.”
Hint: When fitting a regression model in R with two explanatory variables A and B, and their interaction, these two are equivalent:
- y ~ A + B + A:B
- y ~ A*B
Interpreting coefficients for A and B in the presence of an interaction A:B
When you include an interaction between \(x_1\) and \(x_2\) in a regression model, you are estimating the extent to which the effect of \(x_1\) on \(y\) is different across the values of \(x_2\).
What this means is that the effect of \(x_1\) on \(y\) depends on/is conditional upon the value of \(x_2\).
(and vice versa, the effect of \(x_2\) on \(y\) is different across the values of \(x_1\)).
This means that we can no longer talk about the “effect of \(x_1\) holding \(x_2\) constant.” Instead we can talk about a marginal effect of \(x_1\) on \(y\) at a specific value of \(x_2\).
When we fit the model \(y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 (x_1 \cdot x_2) + \epsilon\) using lm():
- the parameter estimate \(\hat \beta_1\) is the marginal effect of \(x_1\) on \(y\) where \(x_2 = 0\)
- the parameter estimate \(\hat \beta_2\) is the marginal effect of \(x_2\) on \(y\) where \(x_1 = 0\)
N.B. Regardless of whether or not there is an interaction term in our model, all parameter estimates in multiple regression are “conditional” in the sense that they are dependent upon the inclusion of other variables in the model. For instance, in \(y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \epsilon\) the coefficient \(\hat \beta_1\) is conditional upon holding \(x_2\) constant.
Interpreting the interaction term A:B
The coefficient for an interaction term can be thought of as providing an adjustment to the slope.
In the model below, we have a numeric*categorical interaction: \[ \begin{align} \text{wellbeing} \ = \ &\beta_0 + \beta_1 \text{social_interactions} + \beta_2 \text{isRural} + \\ &\beta_3 (\text{social_interactions} \cdot \text{isRural}) + \epsilon \end{align} \]
The estimate \(\hat \beta_3\) is the adjustment to the slope \(\hat \beta_1\) to be made for the individuals in the \(\text{isRural}=1\) group.
Look at the parameter estimates from your model, and write a description of what each one corresponds to on the plot shown in Figure 1 (it may help to sketch out the plot yourself and annotate it).
“The best method of communicating findings about the presence of significant interaction may be to present a table of graph of the estimated means at various combinations of the interacting variables.”
— Ramsey and Schafer (2012)
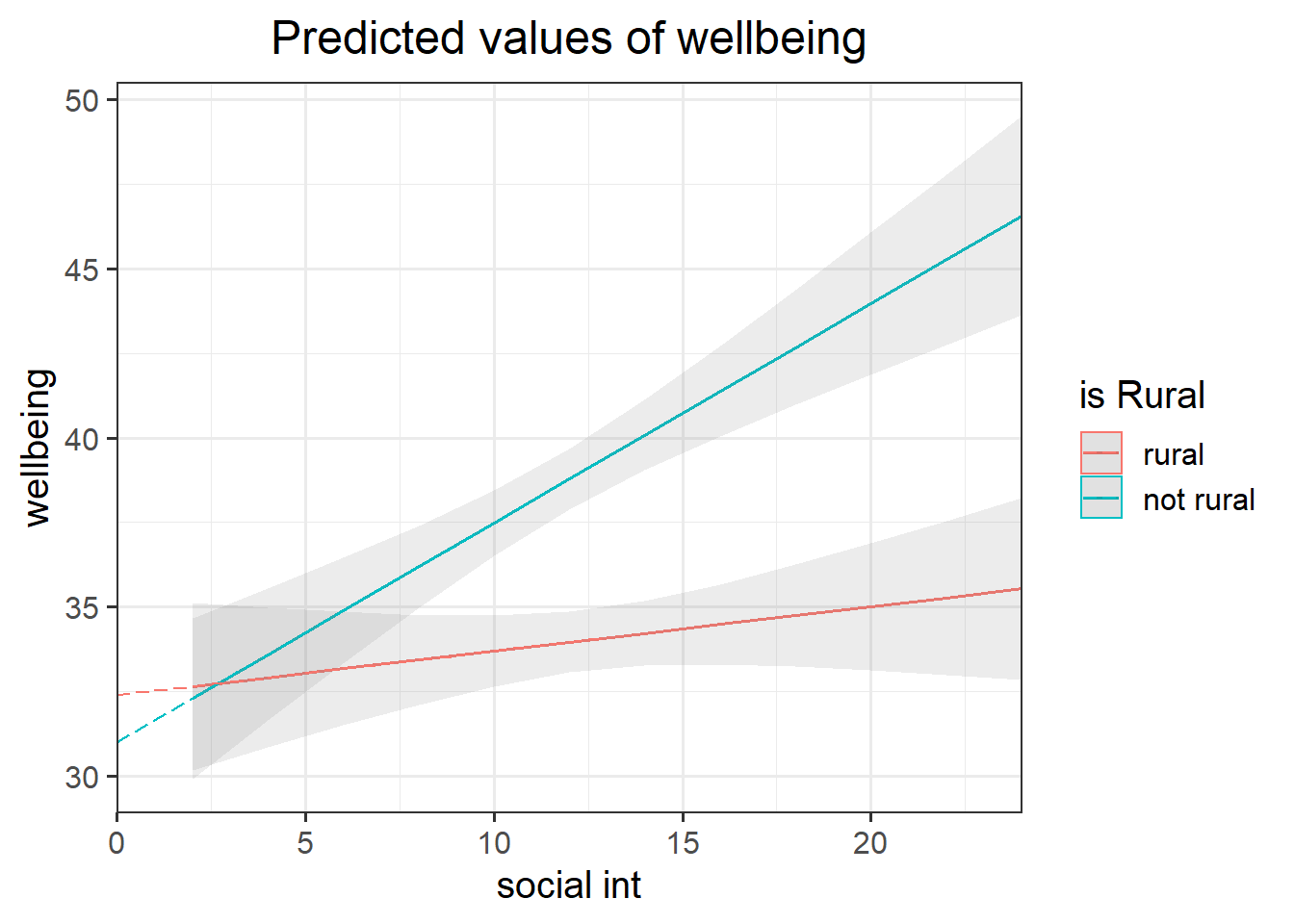
Figure 1: Multiple regression model: Wellbeing ~ Social Interactions * is Rural
Note that the dashed lines represent predicted values below the minimum observed number of social interactions, to ensure that zero on the x-axis is visible
Load the sjPlot package and try using the function plot_model().
The default behaviour of plot_model() is to plot the parameter estimates and their confidence intervals. This is where type = "est".
Try to create a plot like Figure 1, which shows the two lines (Hint: what are this weeks’ exercises all about? type = ???.)
