Model fit and standardization
Information about solutions
Solutions for these exercises are available immediately below each question.
We would like to emphasise that much evidence suggests that testing enhances learning, and we strongly encourage you to make a concerted attempt at answering each question before looking at the solutions. Immediately looking at the solutions and then copying the code into your work will lead to poorer learning.
We would also like to note that there are always many different ways to achieve the same thing in R, and the solutions provided are simply one approach.
Be sure to check the solutions to last week’s exercises.
You can still ask any questions about previous weeks’ materials if things aren’t clear!
LEARNING OBJECTIVES
- Understand the calculation and interpretation of the coefficient of determination.
- Understand the calculation and interpretation of the F-test of model utility.
- Understand how to standardize model coefficients and when this is appropriate to do.
- Understand the relationship between the correlation coefficient and the regression slope.
Data recap
Read the riverview data from the previous lab into R, and fit a linear model to investigate how income varies with years of formal education.
Partitioning variation
We might ask ourselves if the model is useful. To quantify and assess model utility, we split the total variability of the response into two terms: the variability explained by the model plus the variability left unexplained in the residuals.
\[ \text{total variability in response = variability explained by model + unexplained variability in residuals} \]
Each term is quantified by a sum of squares:
\[ \begin{aligned} SS_{Total} &= SS_{Model} + SS_{Residual} \\ \sum_{i=1}^n (y_i - \bar y)^2 &= \sum_{i=1}^n (\hat y_i - \bar y)^2 + \sum_{i=1}^n (y_i - \hat y_i)^2 \end{aligned} \]
What is the proportion of the total variability in incomes explained by the linear relationship with education level?
Hint: The question asks to compute the value of \(R^2\).
Model utility test
To test if the model is useful — that is, if the explanatory variable is a useful predictor of the response — we test the following hypotheses:
\[ \begin{aligned} H_0 &: \text{the model is ineffective, } \beta_1 = 0 \\ H_1 &: \text{the model is effective, } \beta_1 \neq 0 \end{aligned} \]
The relevant test-statistic is the F-statistic:
\[ \begin{split} F = \frac{MS_{Model}}{MS_{Residual}} = \frac{SS_{Model} / 1}{SS_{Residual} / (n-2)} \end{split} \]
which compares the amount of variation in the response explained by the model to the amount of variation left unexplained in the residuals.
The sample F-statistic is compared to an F-distribution with \(df_{1} = 1\) and \(df_{2} = n - 2\) degrees of freedom.1
Perform a model utility test at the 5% significance level, by computing the F-statistic using its definition.
Look at the output of summary(mdl) and anova(mdl).
For each output, identify the relevant information to conduct an F-test against the null hypothesis that the model is ineffective at predicting income using education level.
Consider the F value output of anova(mdl) and the t value for education returned by summary(mdl)
F value = 51.452
t value = 7.173Do you notice any relationship between the F-statistic for overall model utility and the t-statistic for \(H_0: \beta_1 = 0\)?
Back to regression coefficients
Compute the average education level and the average income in the sample.
Use the predict() function to compute the predicted income for those with average education level.
What do you notice?
Let’s formalise the previous question using symbols. Consider the fitted model \(\hat{y} = \hat \beta_0 + \hat \beta_1 x\).
What is the predicted response for an individual having an explanatory variable at the average level \(\bar{x}\)?
Hint: Substitute the formula of \(\hat \beta_0\) into the equation of the fitted model.
Binary predictors
Let’s suppose that instead of having measured education in years, we had data instead on “Obtained College Degree: Yes/No.” Our explanatory variable would be binary categorical (think back to our discussion of types of data).
Let us pretend that everyone with >18 years of education has a college degree:
riverview <-
riverview %>%
mutate(
degree = ifelse(education > 18, "Yes", "No")
)We may then plot our relationship as a boxplot. If you want to see the individual points, you could always “jitter” them (right-hand plot below)
ggplot(riverview, aes(x = degree, y = income)) +
geom_boxplot() +
ggplot(riverview, aes(x = degree, y = income)) +
geom_jitter(height=0, width=.05)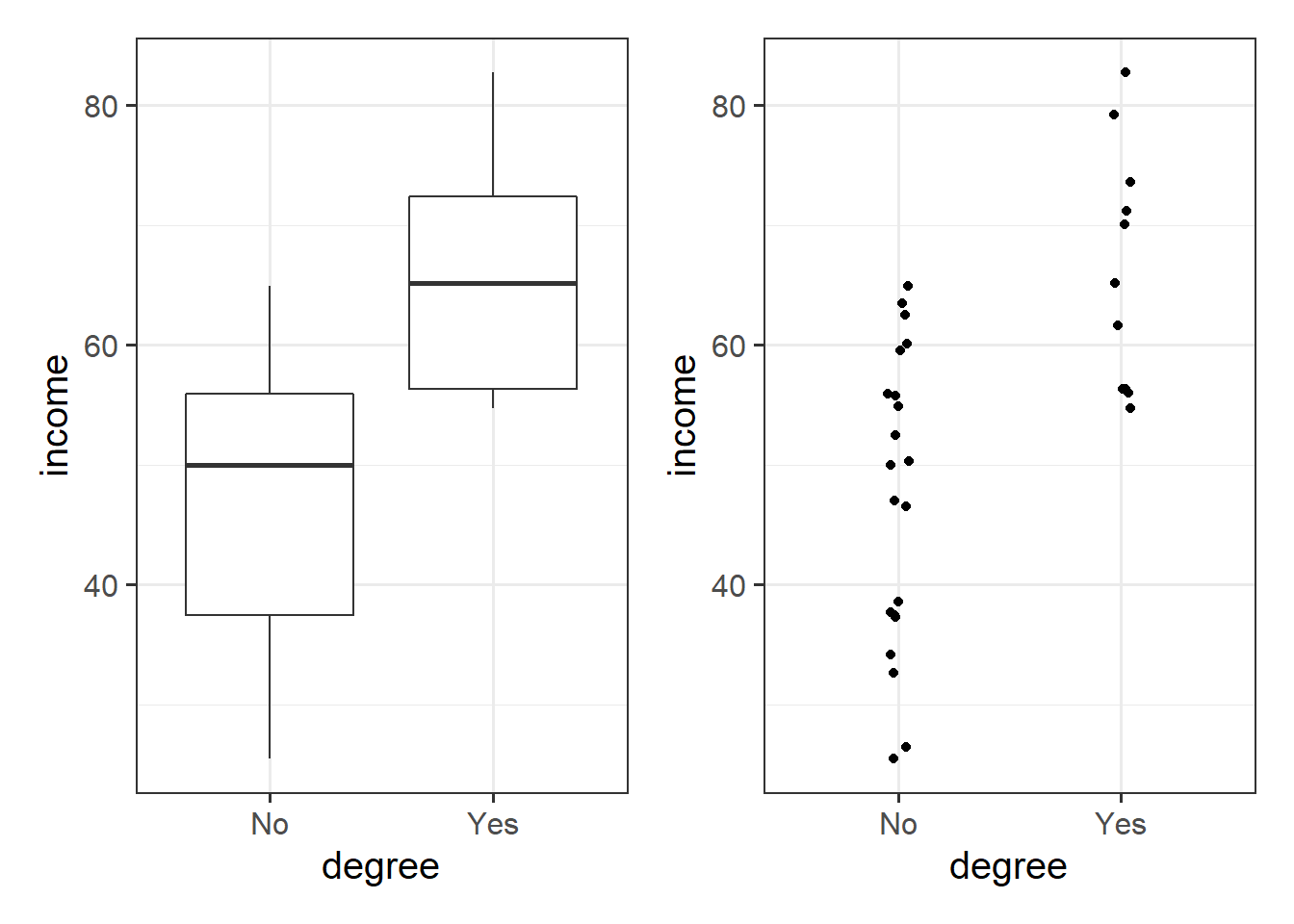
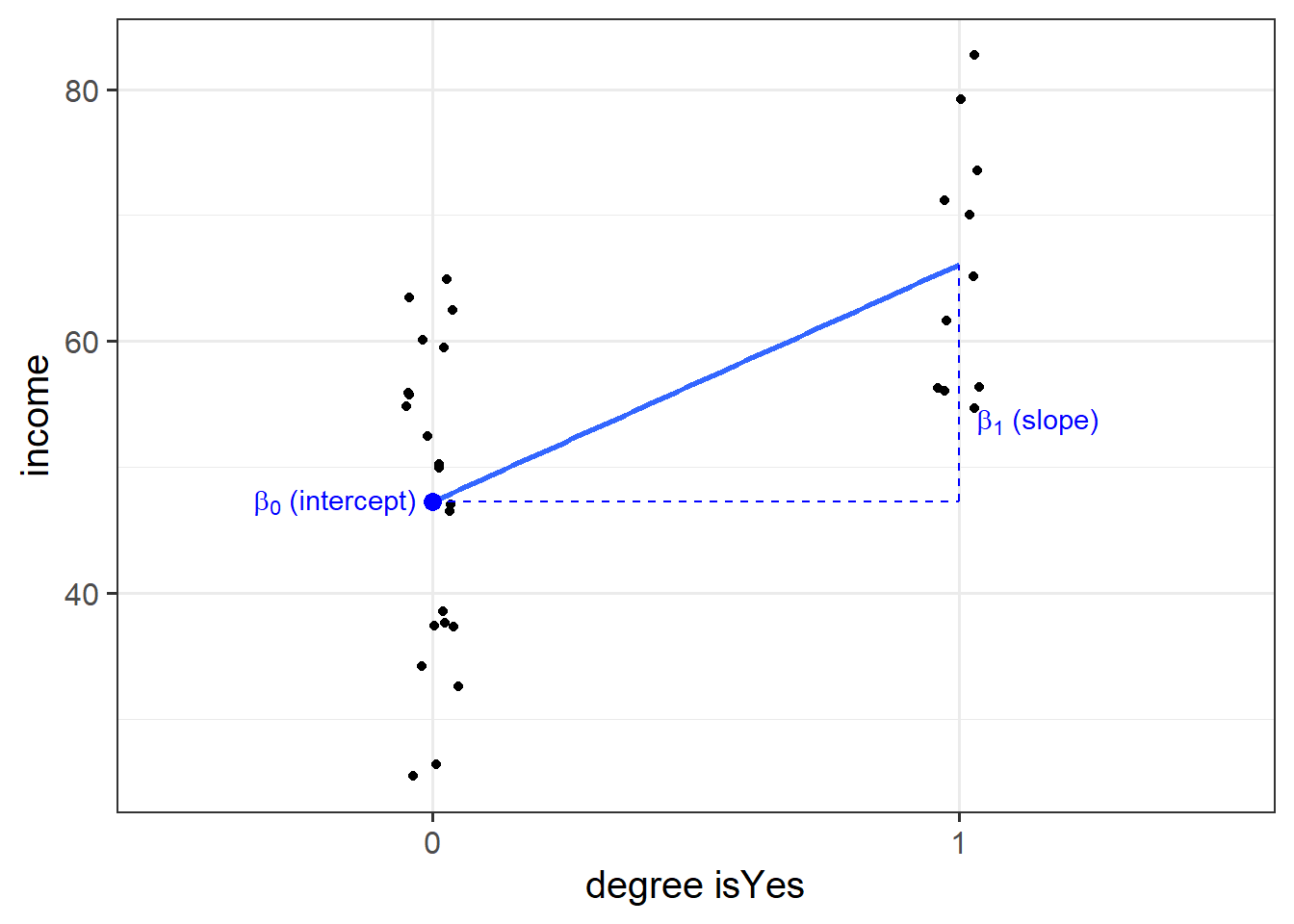
Binary predictors in linear regression
We can include categorical predictors in a linear regression, but the interpretation of the coefficients is very specific. Whereas we talked about coefficients being interpreted as “the change in \(y\) associated with a 1-unit increase in \(x\),” for categorical explanatory variables, coefficients can be considered to examine differences in group means. However, they are actually doing exactly the same thing - the model is simply translating the levels (like “Yes”/“No”) in to 0s and 1s!
So while we may have in our dataframe a categorical predictor like the middle column “degree,” below, what is inputted into our model is more like the third column, “isYes.”
## # A tibble: 32 x 3
## income degree isYes
## <dbl> <chr> <dbl>
## 1 37.7 No 0
## 2 37.4 No 0
## 3 26.4 No 0
## 4 73.5 Yes 1
## 5 65.1 Yes 1
## 6 50.0 No 0
## 7 55.8 No 0
## 8 59.5 No 0
## 9 60.1 No 0
## 10 70.0 Yes 1
## # ... with 22 more rowsOur coefficients are just the same as before. The intercept is where our predictor equals zero, and the slope is the change in our outcome variable associated with a 1-unit change in our predictor.
However, “zero” for this predictor variable now corresponds to a whole level. This is known as the “reference level.” Accordingly, the 1-unit change in our predictor (the move from “zero” to “one”) corresponds to the difference between the two levels.
Standardization
Add to the riverview dataset two variables called z_education and z_income representing the standardized education and income variables, respectively.
Without using R, if you were to fit a linear regression model using the standardized response and standardized predictor, what would the intercept be?
Hint: Recall the formula for the \(z\)-score:
\[
z_x = \frac{x - \bar{x}}{s_x}, \qquad z_y = \frac{y - \bar{y}}{s_y}
\]
Using R, fit the regression model using the standardized response and explanatory variables.
What is the slope equal to?
Interpret the slope of the standardized variables.
References
\(SS_{Total}\) has \(n - 1\) degrees of freedom as one degree of freedom is lost in estimating the population mean with the sample mean \(\bar{y}\). \(SS_{Residual}\) has \(n - 2\) degrees of freedom. There are \(n\) residuals, but two degrees of freedom are lost in estimating the intercept and slope of the line used to obtain the \(\hat y_i\)s. Hence, by difference, \(SS_{Model}\) has \(n - 1 - (n - 2) = 1\) degree of freedom.↩︎