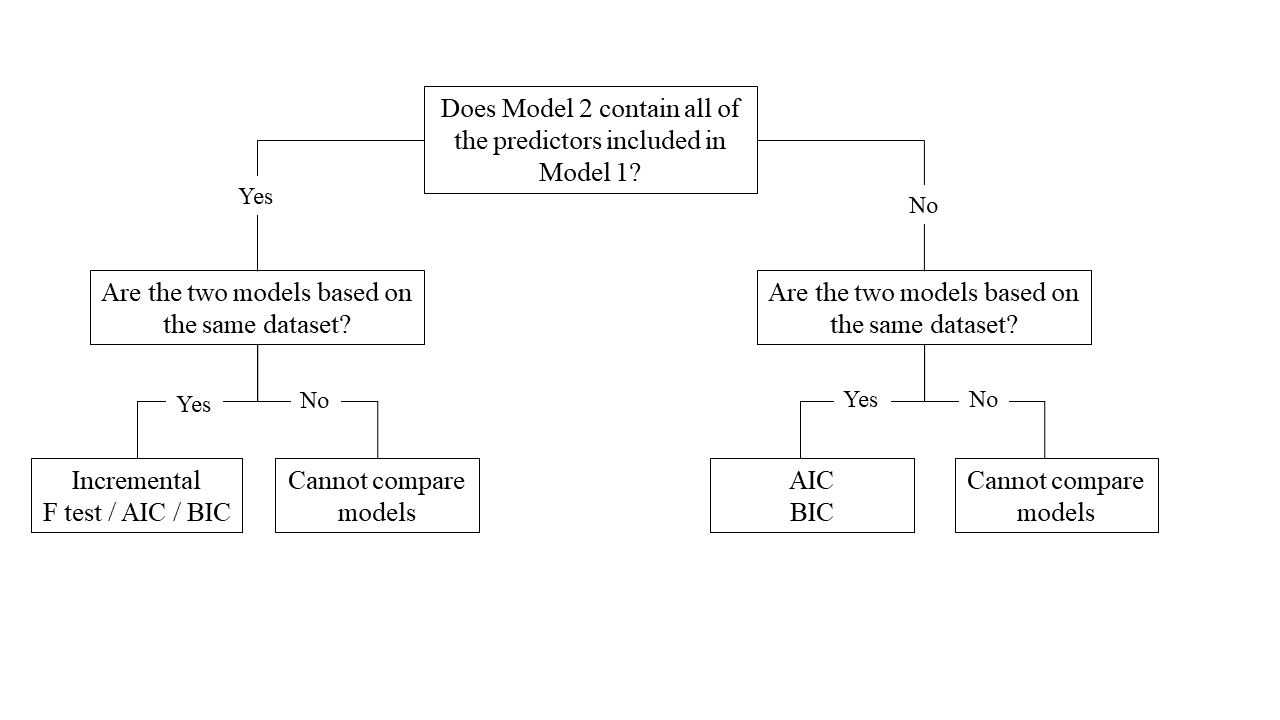
Assessing model fit involves examining metrics like the sum of squares to measure variability explained by the model, the \(F\)-ratio to evaluate the overall significance of the model by comparing explained variance to unexplained variance, and \(R\)-squared / Adjusted \(R\)-squared to quantify the proportion of variance in the dependent variable explained by the independent variable(s).
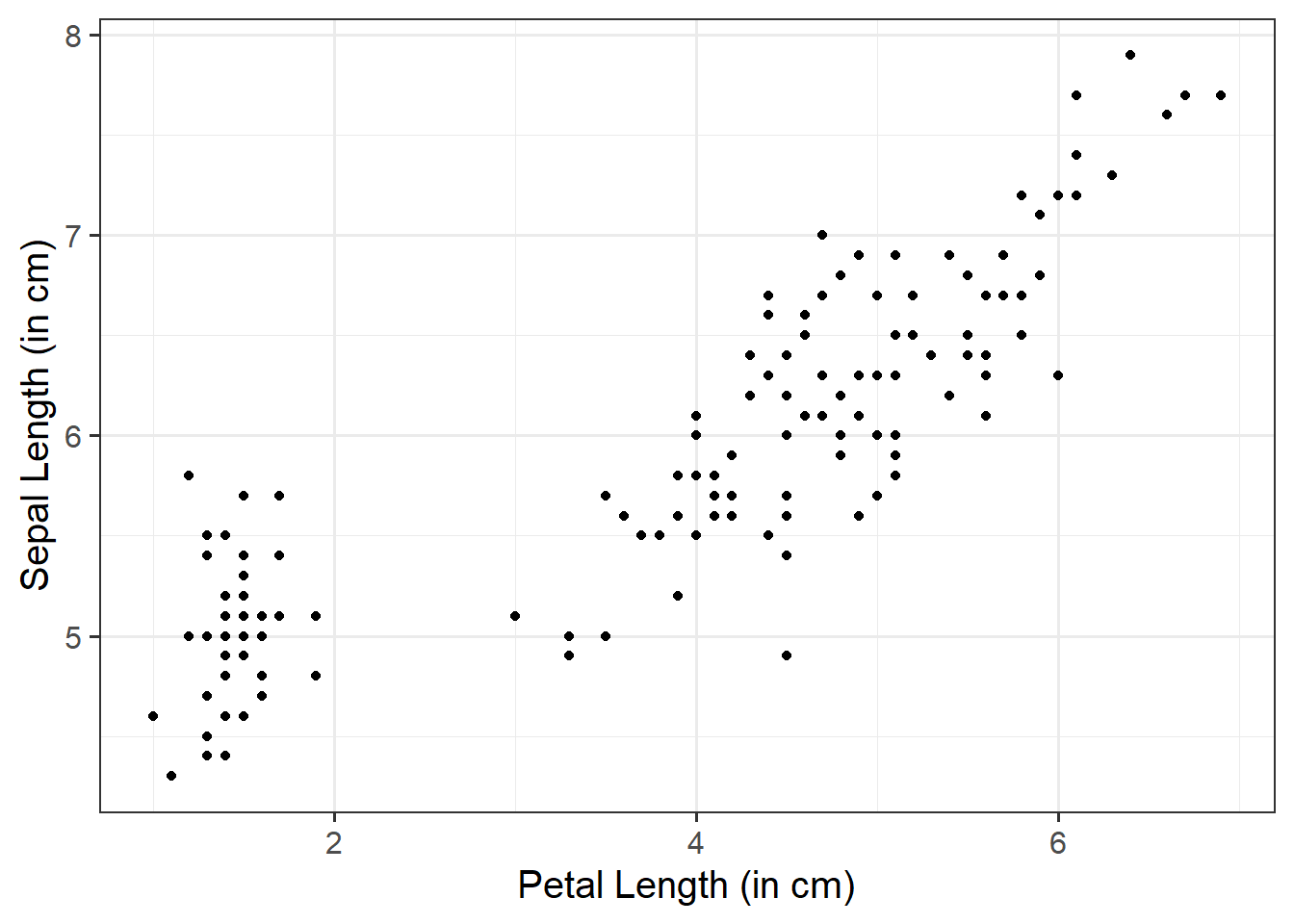
To quantify and assess a model’s utility in explaining variance in an outcome variable, we can split the total variability of that outcome variable into two terms: the variability explained by the model plus the variability left unexplained in the residuals.
The sum of squares measures the deviation or variation of data points away from the mean (i.e., how spread out are the numbers in a given dataset). We are trying to find the equation/function that best fits our data by varying the least from our data points.
Total Sum of Squares
Formula:
\[
SS_{Total} = \sum_{i=1}^{n}(y_i - \bar{y})^2
\] Can also be derived from:
\[
SS_{Total} = SS_{Model} + SS_{Residual}
\]
In words:
Squared distance of each data point from the mean of \(y\).
Description:
How much variation there is in the DV.
Residual Sum of Squares
Formula:
\[
SS_{Residual} = \sum_{i=1}^{n}(y_i - \hat{y}_i)^2
\]
In words:
Squared distance of each point from the predicted value.
Description:
How much of the variation in the DV the model did not explain - a measure that captures the unexplained variation in your regression model. Lower residual sum of squares suggests that your model fits the data well, and higher suggests that the model poorly explains the data (in other words, the lower the value, the better the regression model). If the value was zero here, it would suggest the model fits perfectly with no error.
Model Sum of Squares
Formula:
\[
SS_{Model} = \sum_{i=1}^{n}(\hat{y}_i - \bar{y})^2
\]
Can also be derived from:
\[
SS_{Model} = SS_{Total} - SS_{Residual}
\] In words:
The deviance of the predicted scores from the mean of \(y\).
Description:
How much of the variation in the DV your model explained - like a measure that captures how well the regression line fits your data.
Overview:
We can perform a test to investigate if a model is ‘useful’ — that is, a test to see if our explanatory variable explains more variance in our outcome than we would expect by just some random chance variable.
With one predictor, the \(F\)-statistic is used to test the null hypothesis that the regression slope for that predictor is zero:
\[
H_0: \text{the model is ineffective, }b_1 = 0 \\
\] \[
H_1 : \text{the model is effective, }b_1 \neq 0 \\
\]
In multiple regression, the logic is the same, but we are now testing against the null hypothesis that all regression slopes are zero. Our test is framed in terms of the following hypotheses:
\[
H_0: \text{the model is ineffective, }b_1,...., b_k = 0 \\
\]
\[
H_1 : \text{the model is effective, }b_1,...., b_k \neq 0 \\
\]
The relevant test-statistic is the \(F\)-statistic, which uses “Mean Squares” (these are Sums of Squares divided by the relevant degrees of freedom). We then compare that against (you guessed it) an \(F\)-distribution! \(F\)-distributions vary according to two parameters, which are both degrees of freedom.
Formula:
\[
F_{(df_{model},~df_{residual})} = \frac{MS_{Model}}{MS_{Residual}} = \frac{SS_{Model}/df_{Model}}{SS_{Residual}/df_{Residual}} \\
\quad \\
\]
\[
\begin{align}
& \text{Where:} \\
& df_{model} = k \\
& df_{residual} = n-k-1 \\
& n = \text{sample size} \\
& k = \text{number of explanatory variables} \\
\end{align}
\]
Description:
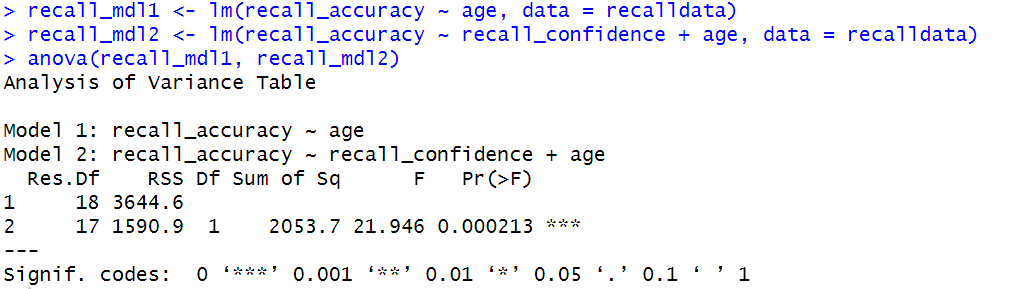
To test the significance of an overall model, we can conduct an \(F\)-test. The \(F\)-test compares your model to a model containing zero predictor variables (i.e., the intercept only model), and tests whether your added predictor variables significantly improved the model.
It is called the \(F\)-ratio because it is the ratio of the how much of the variation is explained by the model (per parameter) versus how much of the variation is unexplained (per remaining degrees of freedom).
The \(F\)-test involves testing the statistical significance of the \(F\)-ratio.
Q: What does the \(F\)-ratio test?
A: The null hypothesis that all regression slopes in a model are zero (i.e., explain no variance in your outcome/DV). The alternative hypothesis is that at least one of the slopes is not zero.
The \(F\)-ratio you see at the bottom of summary(model) is actually a comparison between two models: your model (with some explanatory variables in predicting \(y\)) and the null model.
In regression, the null model can be thought of as the model in which all explanatory variables have zero regression coefficients. It is also referred to as the intercept-only model, because if all predictor variable coefficients are zero, then we are only estimating \(y\) via an intercept (which will be the mean - \(\bar y\)).
Interpretation:
Alongside viewing the \(F\)-ratio, you can see the results from testing the null hypothesis that all of the coefficients are \(0\) (the alternative hypothesis is that at least one coefficient is \(\neq 0\). Under the null hypothesis that all coefficients = 0, the ratio of explained:unexplained variance should be approximately 1)
If your model predictors do explain some variance, the \(F\)-ratio will be significant, and you would reject the null, as this would suggest that your predictor variables included in your model improved the model fit (in comparison to the intercept only model).
Points to note:
- The larger your \(F\)-ratio, the better your model
- The \(F\)-ratio will be close to 1 when the null is true (i.e., that all slopes are zero)
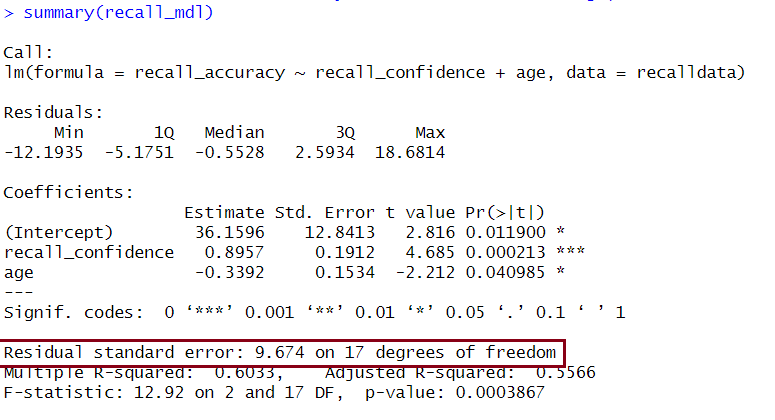
In R
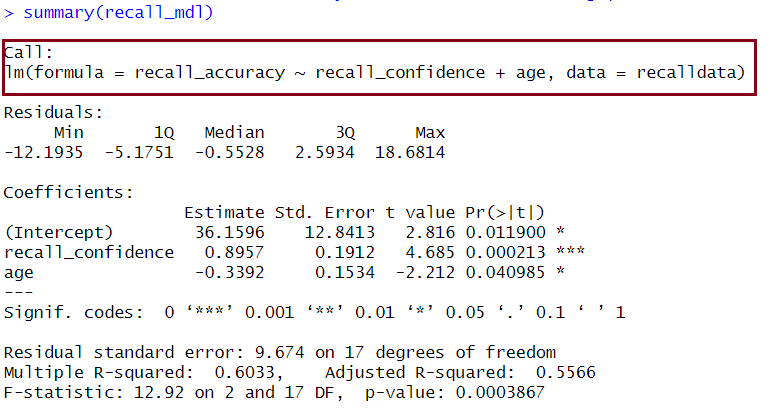
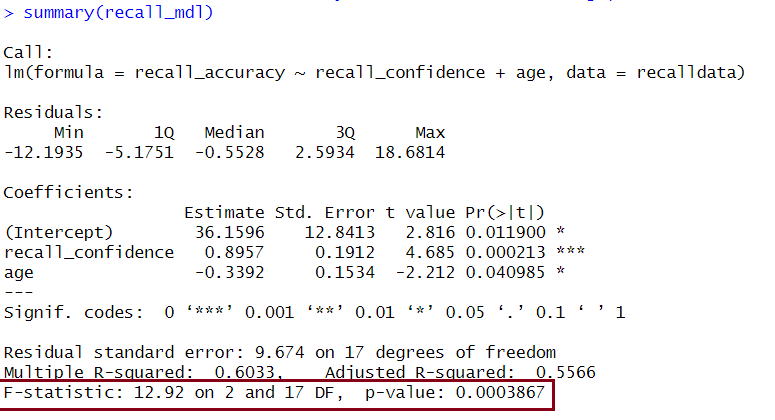
We can see the \(F\)-statistic and associated \(p\)-value at the bottom of the output of summary(<modelname>):
Example Interpretation
The linear model with recall confidence and age explained a significant amount of variance in recall accuracy beyond what we would expect by chance \(F(2, 17) = 12.92, p < .001\).
Overview:
\(R^2\) represents the proportion of variance in \(Y\) that is explained by the model predictor variables.
Formula:
The \(R^2\) coefficient is defined as the proportion of the total variability in the outcome variable which is explained by our model: \[
R^2 = \frac{SS_{Model}}{SS_{Total}} = 1 - \frac{SS_{Residual}}{SS_{Total}}
\]
The Adjusted \(R^2\) coefficient is defined as: \[
\hat R^2 = 1 - \frac{(1 - R^2)(n-1)}{n-k-1}
\quad \\
\]
\[
\begin{align}
& \text{Where:} \\
& n = \text{sample size} \\
& k = \text{number of explanatory variables} \\
\end{align}
\]
When to report Multiple \(R^2\) vs. Adjusted \(R^2\):
The Multiple \(R^2\) value should be reported for a simple linear regression model (i.e., one predictor).
Unlike \(R^2\), Adjusted-\(R^2\) does not necessarily increase with the addition of more explanatory variables, by the inclusion of a penalty according to the number of explanatory variables in the model. Since Adjusted-\(R^2\) is adjusted for the number of predictors in the model, this should be used when there are 2 or more predictors in the model. As a side note, the Adjusted-\(R^2\) should always be less than or equal to \(R^2\).
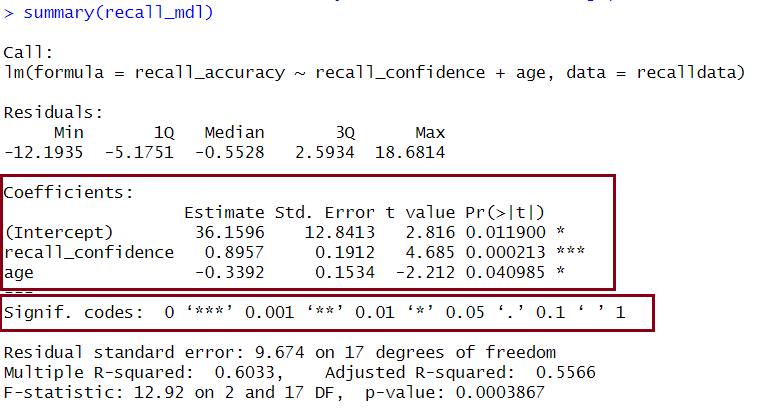
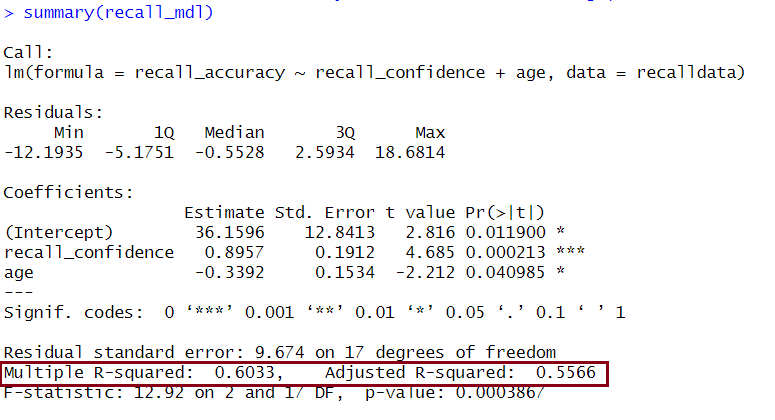
In R
We can see both \(R^2\) and Adjusted-\(R^2\) in the second bottom row of the summary(<modelname>):
Example Interpretation
Together, recall confidence and age explained approximately 55.66% of the variance in recall accuracy.