| variable | description |
|---|---|
| age | Age in years of respondent |
| outdoor_time | Self report estimated number of hours per week spent outdoors |
| social_int | Self report estimated number of social interactions per week (both online and in-person) |
| routine | Binary 1=Yes/0=No response to the question 'Do you follow a daily routine throughout the week?' |
| wellbeing | Warwick-Edinburgh Mental Wellbeing Scale (WEMWBS), a self-report measure of mental health and well-being. The scale is scored by summing responses to each item, with items answered on a 1 to 5 Likert scale. The minimum scale score is 14 and the maximum is 70 |
| location | Location of primary residence (City, Suburb, Rural) |
| steps_k | Average weekly number of steps in thousands (as given by activity tracker if available) |
Multiple Linear Regression
Learning Objectives
At the end of this lab, you will:
- Extend the ideas of single linear regression to consider regression models with two or more predictors
- Understand and interpret the coefficients in multiple linear regression models
Requirements
- Be up to date with lectures
- Have completed Week 1 lab exercises
Required R Packages
Remember to load all packages within a code chunk at the start of your RMarkdown file using library(). If you do not have a package and need to install, do so within the console using install.packages(" "). For further guidance on installing/updating packages, see Section C here.
For this lab, you will need to load the following package(s):
- tidyverse
- psych
- patchwork
- sjPlot
- kableExtra
Presenting Results
All results should be presented following APA guidelines.If you need a reminder on how to hide code, format tables/plots, etc., make sure to review the rmd bootcamp.
The example write-up sections included as part of the solutions are not perfect - they instead should give you a good example of what information you should include and how to structure this. Note that you must not copy any of the write-ups included below for future reports - if you do, you will be committing plagiarism, and this type of academic misconduct is taken very seriously by the University. You can find out more here.
Lab Data
You can download the data required for this lab here or read it in via this link https://uoepsy.github.io/data/wellbeing_rural.csv
Study Overview
Research Question
Is there an association between wellbeing and time spent outdoors after taking into account the association between wellbeing and social interactions?
Setup
Setup
- Create a new RMarkdown file
- Load the required package(s)
- Read the wellbeing dataset into R, assigning it to an object named
mwdata
Exercises
Study & Analysis Plan Overview
Question 1
Provide a brief overview of the study design and data, before detailing your analysis plan to address the research question.
Hint
- Give the reader some background on the context of the study (you might be able to re-use some of the content you wrote for Lab 1 Q10 here)
- State what type of analysis you will conduct in order to address the research question
- Specify the model to be fitted to address the research question
- Specify your chosen significance (\(\alpha\)) level
- State your hypotheses
Much of the information required can be found in the Study Overview codebook. The statistical models flashcards may also be useful to refer to.
Descriptive Statistics & Visualisations
Question 2
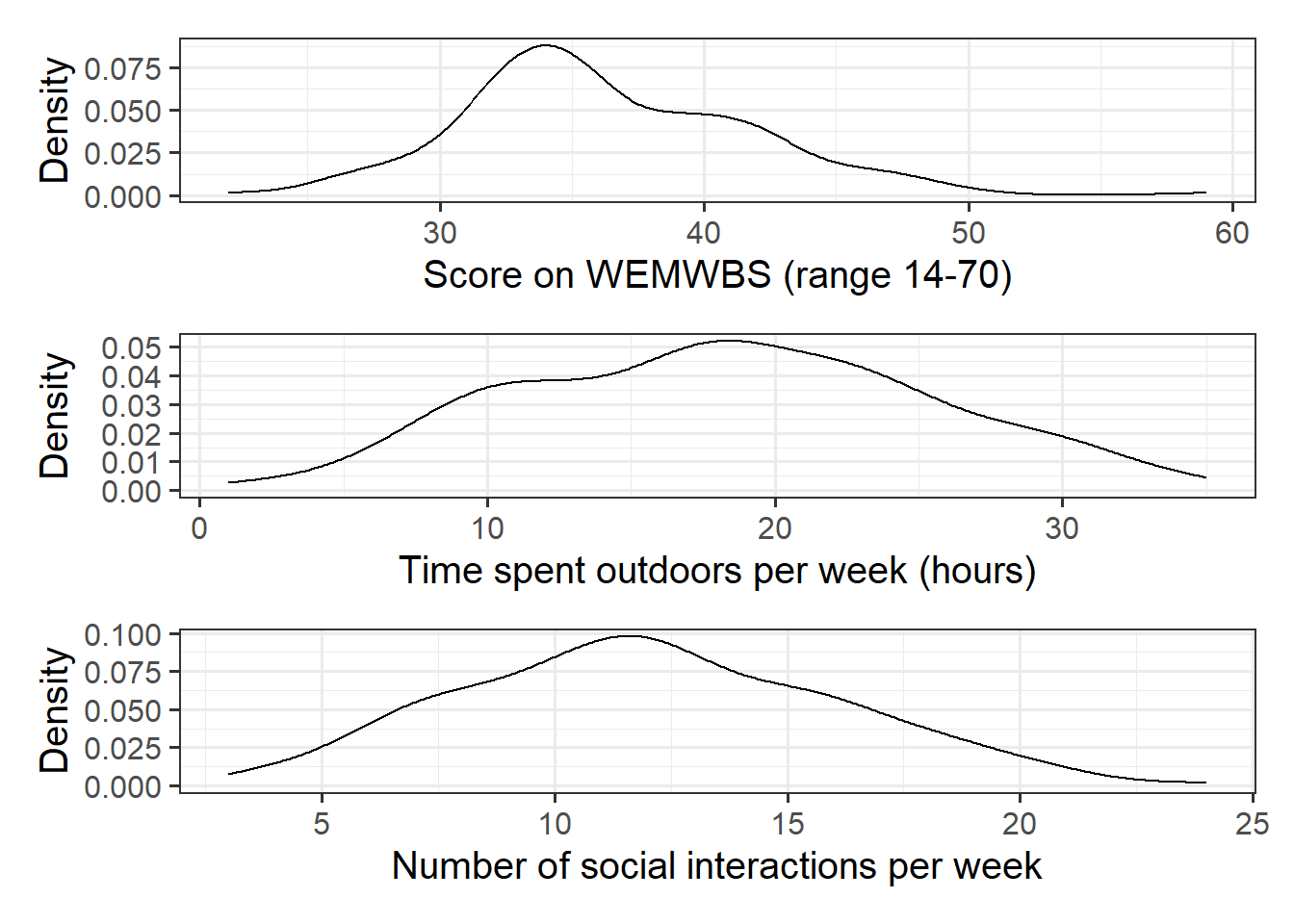
Alongside descriptive statistics, visualize the marginal distributions of the wellbeing, outdoor_time, and social_int variables.
Hint
Review the many ways to numerically and visually explore your data by reading over the data exploration flashcards.
For examples, see flashcards on descriptives statistics tables and data visualisation - marginal.
Question 3
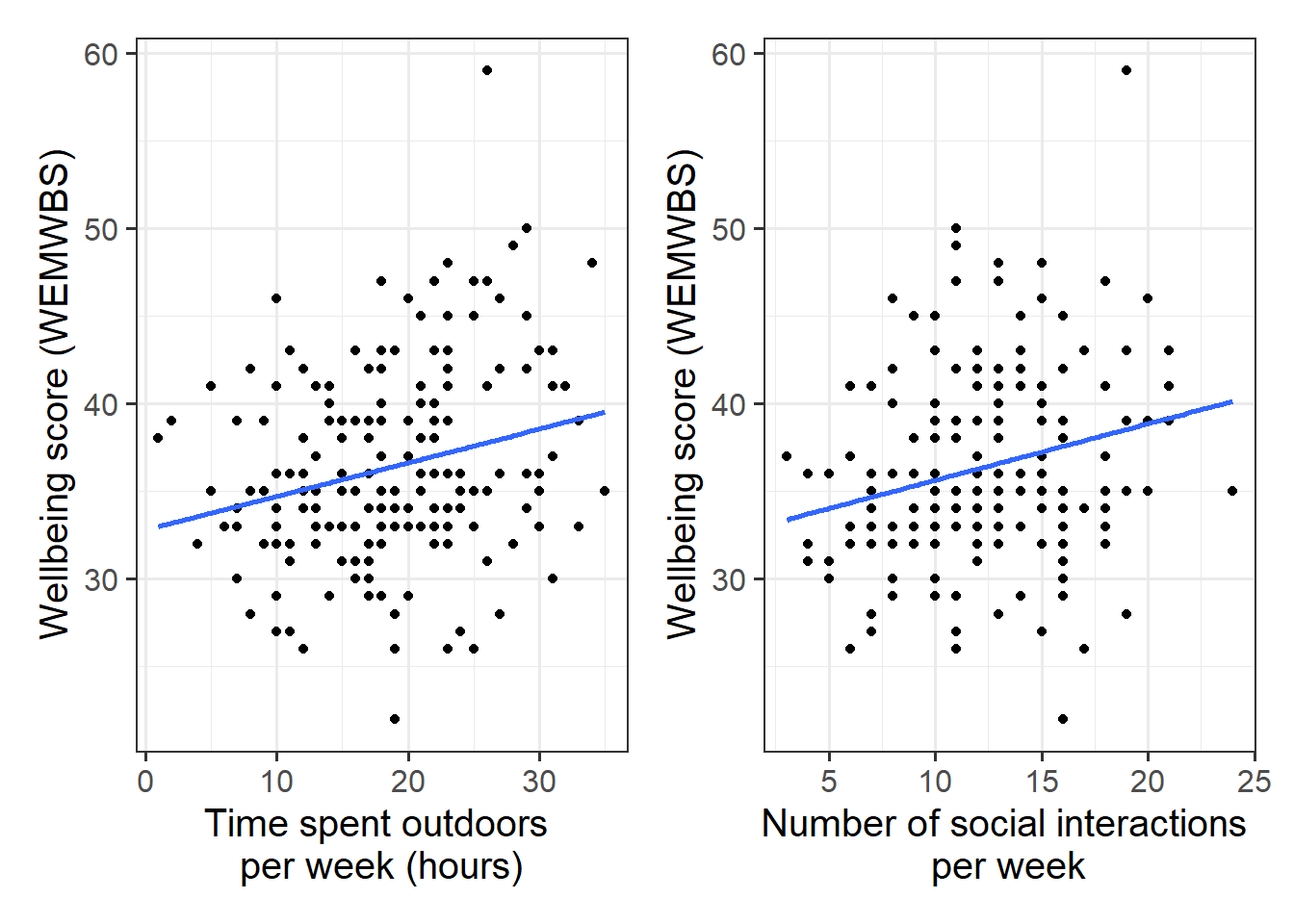
Produce plots of the associations between the outcome variable (wellbeing) and each of the explanatory variables.
Hint
Review how to visually explore bivariate associations via the data visualisation flashcards.
For specifically visualising associations between variables, see the bivariate examples flashcards.
Question 4
Produce a correlation matrix of the variables which are to be used in the analysis, and write a short paragraph describing the associations.
Hint
Review the correlation flashcards, and remember to interpret in the context of the research question.
Model Fitting & Interpretation
Question 5
Recall the model specified in Q1, and:
- State the parameters of the model. How do we denote parameter estimates?
- Fit the linear model in using
lm(), assigning the output to an object calledmdl1.
Hint
As we did for simple linear regression, we can fit our multiple regression model using the lm() function. For a recap, see the statistical models flashcards.
Additional Visual Explanation
Note that for simple linear regression we talked about our model as a line in 2 dimensions: the systematic part \(\beta_0 + \beta_1 x\) defined a line for \(\mu_y\) across the possible values of \(x\), with \(\epsilon\) as the random deviations from that line. But in multiple regression we have more than two variables making up our model.
In this particular case of three variables (one outcome + two explanatory), we can think of our model as a regression surface (see Figure 3). The systematic part of our model defines the surface across a range of possible values of both \(x_1\) and \(x_2\). Deviations from the surface are determined by the random error component, \(\hat \epsilon\).
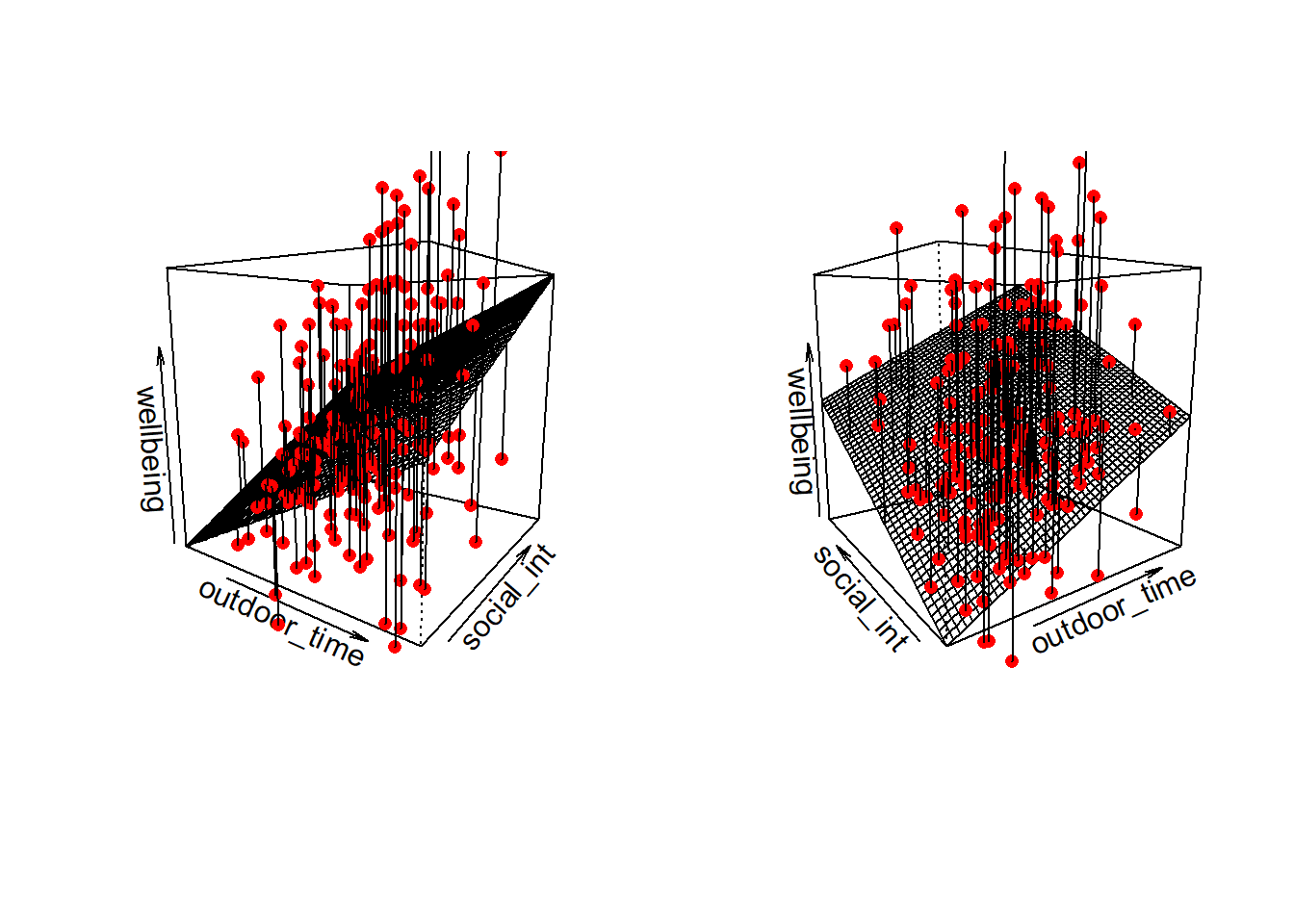
Don’t worry about trying to figure out how to visualise it if we had any more explanatory variables! We can only concieve of 3 spatial dimensions. One could imagine this surface changing over time, which would bring in a 4th dimension, but beyond that, it’s not worth trying!
Question 6
Using any of:
mdl1mdl1$coefficientscoef(mdl1)coefficients(mdl1)summary(mdl1)
Write out the estimated parameter values of:
-
\(\hat \beta_0\), the estimated average wellbeing score associated with zero hours of outdoor time and zero social interactions per week.
-
\(\hat \beta_1\), the estimated increase in average wellbeing score associated with an additional social interaction per week (an increase of one), holding weekly outdoor time constant.
- \(\hat \beta_2\), the estimated increase in average wellbeing score associated with one hour increase in weekly outdoor time, holding the number of social interactions constant
Hint
To interpret and extract information, see the simple & multiple regression models - extracing information flashcards
Question 7
Within what distance from the model predicted values (the regression line) would we expect 95% of WEMWBS wellbeing scores to be?
Hint
Either sigma() or part of the output from summary() will help you here. See Lab 1 Q5 for an example, or the simple & multiple regression models - extracting information flashcard.
Question 8
Based on the model, predict the wellbeing scores for the following individuals who were not included in the original sample:
- Leah: Social Interactions = 25; Outdoor Time = 3
- Sean: Social Interactions = 19; Outdoor Time = 36
- Mike: Social Interactions = 15; Outdoor Time = 20
- Donna: Social Interactions = 7; Outdoor Time = 1
Who has the highest predicted wellbeing score, and who has the lowest?
Hint
It might be helpful to review the predicted values > model predicted values for other (unobserved) data.
Writing Up & Presenting Results
Question 9
Provide key model results in a formatted table.
Hint
Use tab_model() from the sjPlot package. For a quick guide, review the tables flashcard.
Question 10
Interpret your results in the context of the research question.
Make reference to the regression table.
Hint
Make sure to include a decision in relation to your null hypothesis - based on the evidence, should you reject or fail to reject the null?
Compile Report
Compile Report
Knit your report to PDF, and check over your work. To do so, you should make sure:
- Only the output you want your reader to see is visible (e.g., do you want to hide your code?)
- Check that the tinytex package is installed
- Ensure that the ‘yaml’ (bit at the very top of your document) looks something like this:
---
title: "this is my report title"
author: "B1234506"
date: "07/09/2024"
output: bookdown::pdf_document2
---
What to do if you cannot knit to PDF
If you are having issues knitting directly to PDF, try the following:
- Knit to HTML file
- Open your HTML in a web-browser (e.g. Chrome, Firefox)
- Print to PDF (Ctrl+P, then choose to save to PDF)
- Open file to check formatting
Hiding Code and/or Output
Review Lesson 5 of the rmd bootcamp for a detailed description/worked examples.
To not show the code of an R code chunk, and only show the output, write:
```{r, echo=FALSE}
# code goes here
```To show the code of an R code chunk, but hide the output, write:
```{r, results='hide'}
# code goes here
```To hide both code and output of an R code chunk, write:
```{r, include=FALSE}
# code goes here
```
Tinytex
You must make sure you have tinytex installed in R so that you can “Knit” your Rmd document to a PDF file:
install.packages("tinytex")
tinytex::install_tinytex()