| variable | description |
|---|---|
| Diagnosis | Diagnosis classifies the three types of individuals: 1 = Amnesic patients, 2 = Huntingtons patients, and 3 = Control group of individuals with no known neurological disorder |
| Task | Task tells us to which one of two tasks each study participant was randomly assigned to: 1 = Grammar (which consists of classifying letter sequences as either following or not following grammatical rules), and 2 = Recognition (which consists of recognising particular stimuli as stimuli that have previously been presented during the task) |
| Y | Score |
Interactions III: Cat x Cat
Learning Objectives
At the end of this lab, you will:
- Understand the concept of an interaction
- Be able to interpret a categorical \(\times\) categorical interaction
- Be able to visualize and probe interactions
What You Need
Required R Packages
Remember to load all packages within a code chunk at the start of your RMarkdown file using library(). If you do not have a package and need to install, do so within the console using install.packages(" "). For further guidance on installing/updating packages, see Section C here.
For this lab, you will need to load the following package(s):
- tidyverse
- psych
- sjPlot
- kableExtra
- sandwich
- interactions
Presenting Results
All results should be presented following APA guidelines.If you need a reminder on how to hide code, format tables/plots, etc., make sure to review the rmd bootcamp.
The example write-up sections included as part of the solutions are not perfect - they instead should give you a good example of what information you should include and how to structure this. Note that you must not copy any of the write-ups included below for future reports - if you do, you will be committing plagiarism, and this type of academic misconduct is taken very seriously by the University. You can find out more here.
Lab Data
You can download the data required for this lab here or read it in via this link https://uoepsy.github.io/data/cognitive_experiment_3_by_2.csv
Study Overview
Research Question
Are there differences in types of memory deficits for those experiencing different cognitive impairment(s)?
Setup
Setup
- Create a new RMarkdown file
- Load the required package(s)
- Read the cognitive_experiment_3_by_2 dataset into R, assigning it to an object named
cog
Exercises
Study & Analysis Plan Overview
Question 1
Examine the dataset, and perform any necessary and appropriate data management steps.
Hint
- The
str()function will return the overall structure of the dataset, this can be quite handy to look at
- Convert categorical variables to factors, and if needed, provide better variable names*
- Label factors appropriately to aid with your model interpretations if required*
- Check that the dataset is complete (i.e., are there any
NAvalues?). We can check this usingis.na()
Note that all of these steps can be done in combination - the mutate() and factor() functions will likely be useful here.
*See the numeric outcomes & categorical predictors flashcard.
Question 2
Choose appropriate reference levels for the Diagnosis and Task variables.
Hint
Read the Study Overview codebook carefully.
Review the specifying reference levels flashcard.
Question 3
Provide a brief overview of the study design and data, before detailing your analysis plan to address the research question.
Hint
- Give the reader some background on the context of the study
- State what type of analysis you will conduct in order to address the research question
- Specify the model to be fitted to address the research question (note that you will need to specify the reference level of your categorical variable(s))
- Specify your chosen significance (\(\alpha\)) level
- State your hypotheses
Much of the information required can be found in the Study Overview codebook.
The statistical models flashcards may also be useful to refer to. Specifically the interaction models flashcards and categorical x categorical example flashcards might be of most use.
Descriptive Statistics & Visualisations
Question 4
Provide a table of descriptive statistics and visualise your data.
Remember to interpret your plot in the context of the study.
Hint
Review the many ways to numerically and visually explore your data by reading over the data exploration flashcards.
For examples, see flashcards on descriptives statistics tables - categorical and numeric values examples and categorical x categorical example - visualise data.
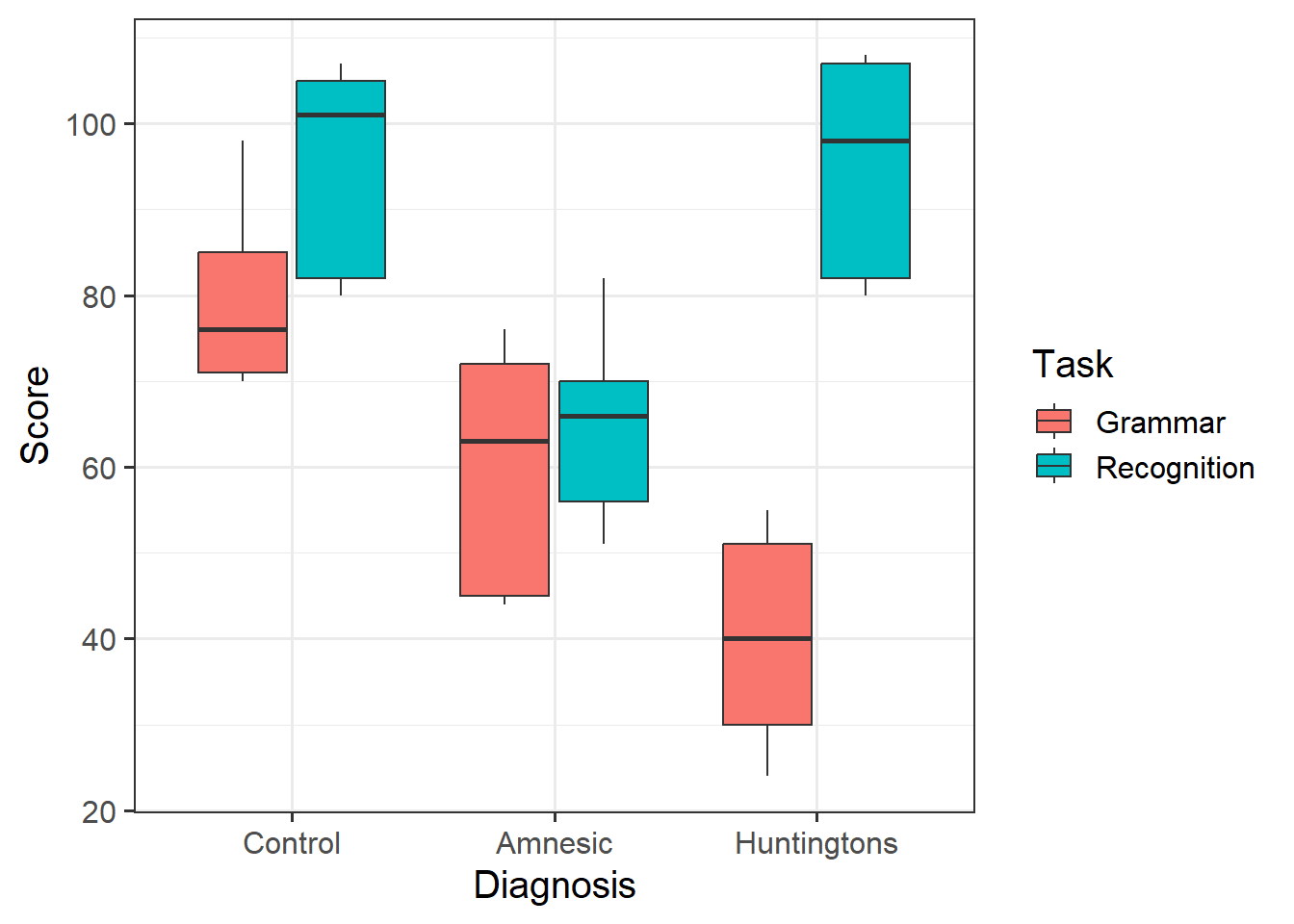
Model Fitting & Interpretation
Question 5
Fit the specified model using lm(), and assign it the name “cog_mdl”.
Hint
We can fit interaction models using the lm() function.
For an overview, see the interaction models flashcards.
For an example, review the interaction models > categorical x categorical example > model building flashcards.
Question 6
Recall your table of descriptive statistics - map each coefficient from the summary() output from “cog_mdl” to the group means.
Question 7
Interpret your coefficients in the context of the study.
Hint
Recall that we can obtain our parameter estimates using various functions such as summary(),coef(), coefficients(), etc.
You may find it helpful to review your descriptive statistics from Q4, or the findings from your mapping exercise in Q6.
For an overview of how to interpret coefficients, review the interaction models > interpreting coefficients flashcard.
For a specific example of coefficient interpretation, review the interaction models > categorical x categorical example > results interpretation flashcards.
Visualise Interaction Model
Question 8
Using the cat_plot() function from the interactions package, visualise the interaction effects from your model.
Try to summarise the interaction effects in a few short and concise sentences.
Hint
For an overview and example, review the interaction models > categorical x categorical example > model visualisation flashcards.
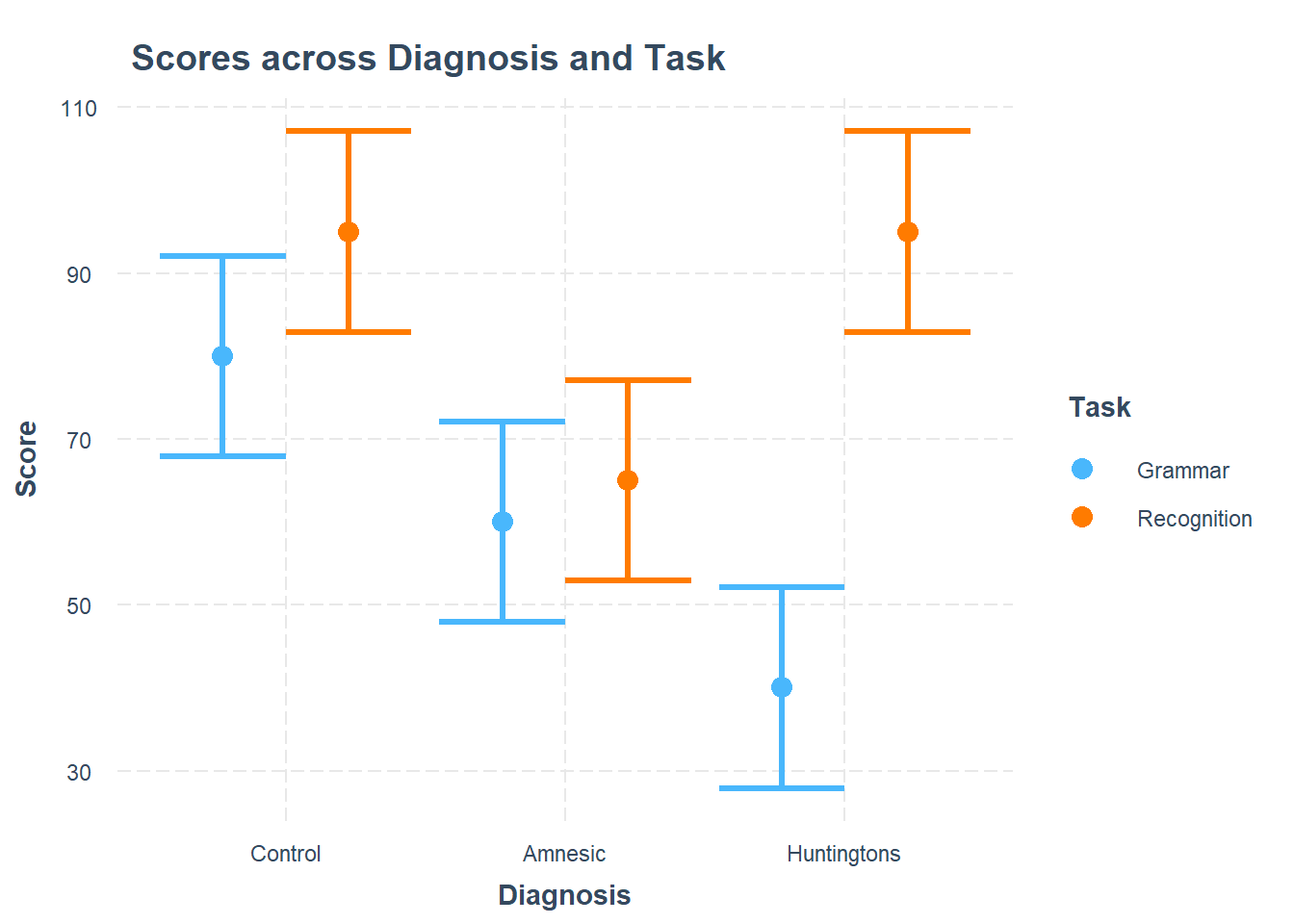
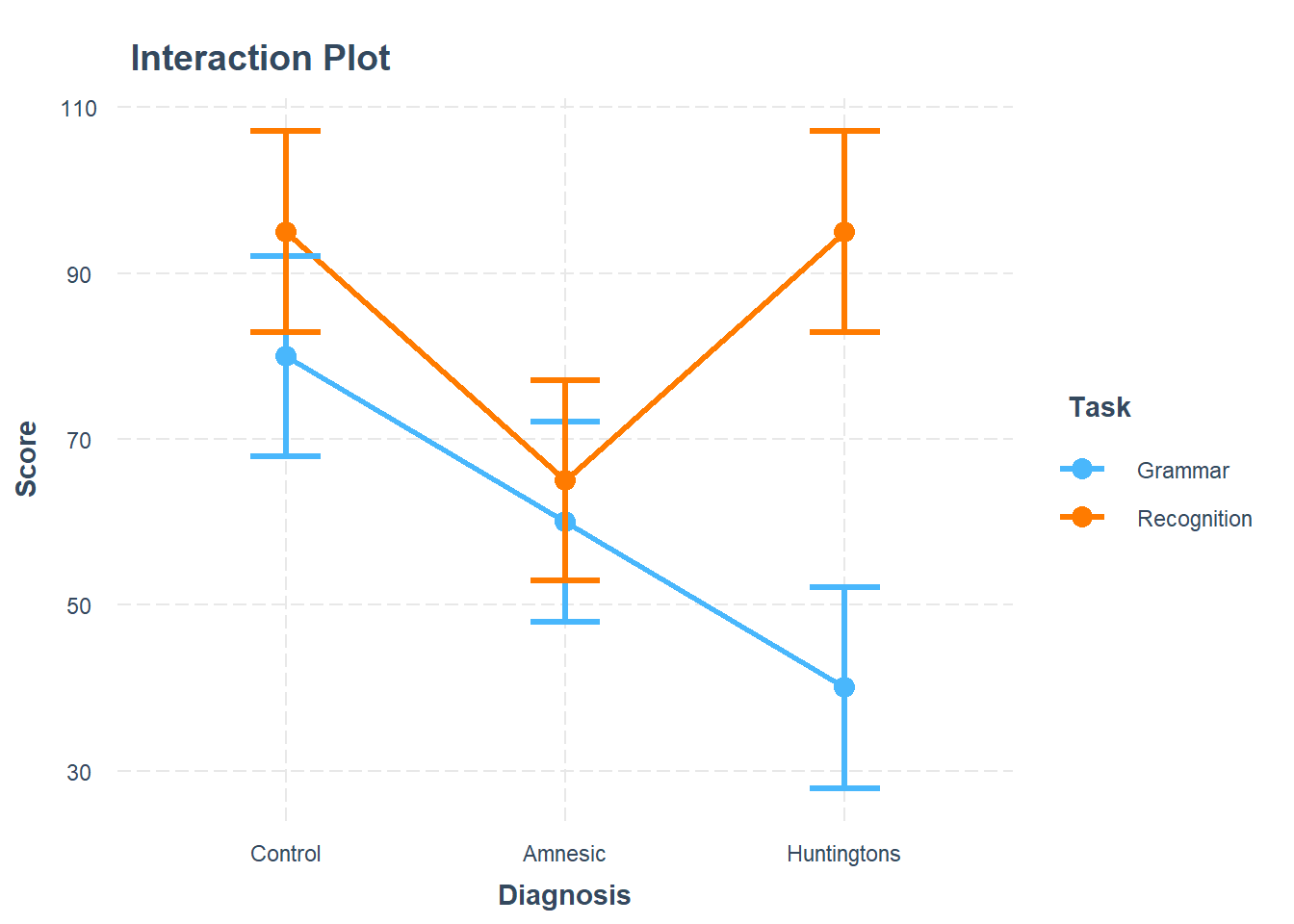
Writing Up & Presenting Results
Question 9
Provide key model results in a formatted table.
Hint
Use tab_model() from the sjPlot package. For a quick guide, review the tables flashcard.
Question 10
Interpret your results in the context of the research question and report your model in full.
Make reference to the interaction plot and regression table.
Hint
For an example of coefficient interpretation, review the interaction models > categorical x categorical example > results interpretation flashcards.
Compile Report
Compile Report
Knit your report to PDF, and check over your work. To do so, you should make sure:
- Only the output you want your reader to see is visible (e.g., do you want to hide your code?)
- Check that the tinytex package is installed
- Ensure that the ‘yaml’ (bit at the very top of your document) looks something like this:
---
title: "this is my report title"
author: "B1234506"
date: "07/09/2024"
output: bookdown::pdf_document2
---
What to do if you cannot knit to PDF
If you are having issues knitting directly to PDF, try the following:
- Knit to HTML file
- Open your HTML in a web-browser (e.g. Chrome, Firefox)
- Print to PDF (Ctrl+P, then choose to save to PDF)
- Open file to check formatting
Hiding Code and/or Output
To not show the code of an R code chunk, and only show the output, write:
```{r, echo=FALSE}
# code goes here
```To show the code of an R code chunk, but hide the output, write:
```{r, results='hide'}
# code goes here
```To hide both code and output of an R code chunk, write:
```{r, include=FALSE}
# code goes here
```
Tinytex
You must make sure you have tinytex installed in R so that you can “Knit” your Rmd document to a PDF file:
install.packages("tinytex")
tinytex::install_tinytex()
Footnotes
Some researchers may point out that a design where each person was assessed on both tasks might have been more efficient. However, the task factor in such design would then be within-subjects, meaning that the scores corresponding to the same person would be correlated. To analyse such design we will need a different method which (spoiler alert!) will be discussed next year in DAPR3.↩︎