So far we’ve seen a couple of instances of categorical variables as predictors in linear models. We’ve seen what happens for a “binary” predictor (two levels, 7A#binary-predictors), and we’ve talked briefly about what happens for variables with more levels (8A#multiple-categories-multiple regression).
Let’s bring back our example of primate brain mass. We can see the species variable has 3 levels indicating whether the observation is a Human, a Rhesus monkey, or a Potar monkey. The isMonkey variable (created below), is a binary variable indicating if it is a monkey (of any type) or not.
# A tibble: 6 × 4
species mass_brain age isMonkey
<chr> <dbl> <dbl> <chr>
1 Rhesus monkey 0.449 5 YES
2 Human 0.577 2 NO
3 Potar monkey 0.349 30 YES
4 Human 0.626 27 NO
5 Potar monkey 0.316 31 YES
6 Rhesus monkey 0.398 11 YES
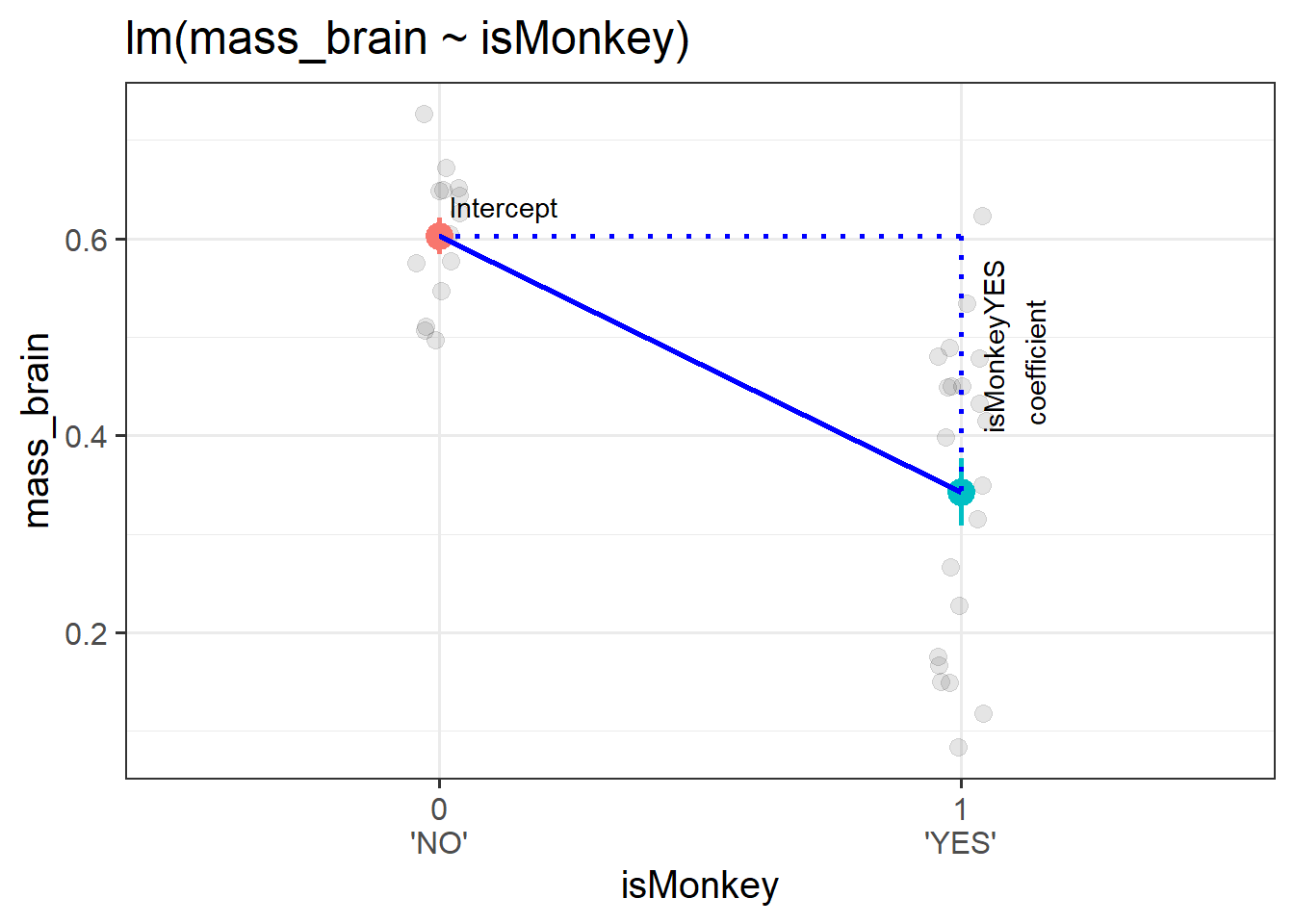
When we talked about categorical predictors initially, we mentioned that they get inputted into the model as a series of 0s and 1s. Our coefficients from linear models are, if we remember, interpreted as “the change in \(y\) associated with a 1 unit change in \(x\)”. By using 0s and 1s for different levels of a categorical variable we can make “a 1 unit change in \(x\)” represent moving from one level to another.
This means that we can get out an estimate of, for instance, the difference in brain mass from the group isMonkey == "NO" to the group isMonkey == "YES", as visualised in Figure 1
monkmod <-lm(mass_brain~isMonkey, data = braindata)summary(monkmod)
Call:
lm(formula = mass_brain ~ isMonkey, data = braindata)
...
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.60271 0.03475 17.346 < 2e-16 ***
isMonkeyYES -0.25986 0.04486 -5.793 1.78e-06 ***
Figure 1: A binary categorical predictor
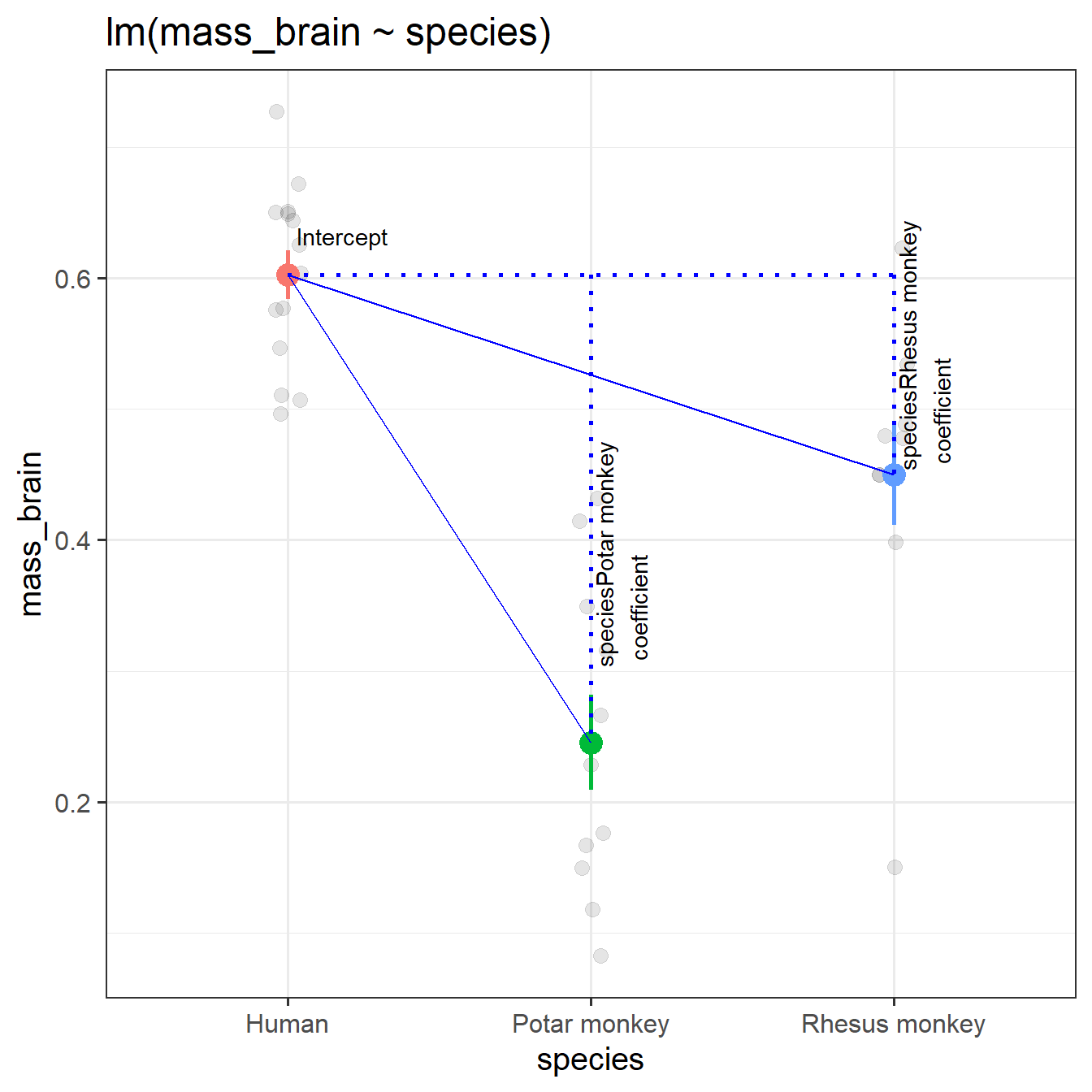
When we have categorical predictors with multiple levels, we end up having \(\text{number-of-levels}-1\) coefficients in our model. These are, in fact, still just a number of variables that contain sets of 0s and 1s. To determine which of \(k\) levels an observation is in, we only need \(k-1\) sets of binary variables. For instance, we can re-express the information in the species variable (with 3 levels) with 2 binary variables:
For a Potar monkey, isPotar == 1 and isRhesus == 0
For a Rhesus monkey, isPotar == 0 and isRhesus == 1
These two coefficients are actually what is coming out of our model, even though we only put the one species variable into it!
Recall that the intercept is the estimated outcome when all predictors are zero. In this case, when both variables are zero, we are looking at the Humans group. And when we move 1 on the isPotar scale, we move from the humans to the Potar monkeys. When we move 1 on the isRhesus scale, we move from humans to Rhesus monkeys. So each coefficient is comparing a level to the “reference level” (as in Figure 2).
specmod1 <-lm(mass_brain ~ species, data = braindata)summary(specmod1)
Try fitting a model that uses the two binary variables we made above instead of using species. Take a look at the coefficients, try to compare the models to one another.
They are identical!
specmod2 <-lm(mass_brain ~ isPotar + isRhesus, data = braindata)summary(specmod2)
All this is happening as part of the model fitting process. Because we have variables with sets of characters (“YES” and “NO”, or “Human”, “Potar monkey” and “Rhesus monkey”), when we use these in our model, they get interpreted as a set of categories. It gets interpreted as a ‘factor’ (see 2A#categorical).
Good practice
If we have a variable where a set of categories is represented by numbers, then the model will interpret them as numerical values (i.e. 2 is twice 1 etc).
If a variable is categorical, it is good practice to make it a factor when you read in your data. That way you don’t get into errors later on when modelling.
Contrasts
We can do lots of clever things with categorical predictors in regression models, in order to compare different groups to one another.
The first thing we need to do is to explicitly tell R that they are categorical variables (i.e. we need to make them ‘factors’):
Once we have done this we can see (and also manipulate) the way in which it gets treated by our model. This is because factors in R have some special attributes called “contrasts”. Contrasts are ultimately the thing that the model will use to decide what you want to compare to what.
The following code shows us the “contrast matrix” for a given variable. The rows of this show each level of our variable, and the columns are the coefficients (the comparisons which are estimated when we put the variable into a model).
We can see that the default contrasts are the ones we had created manually just above:
contrasts(braindata$species)
As we saw in 9A#relevelling-factors, we can “relevel” factor, thereby changing which one is the ‘reference level’ (the level against which all other levels are compared).
For instance, if we wanted to see how each species compared to Rhesus monkeys, relevelling the factor changes the contrasts accordingly:
Human Potar monkey
Rhesus monkey 0 0
Human 1 0
Potar monkey 0 1
We’re not going to delve too far into contrasts in this course (it’s a bit of a rabbit hole!), but it’s worth knowing about a couple of different types, and what we can use them to extract from our model.
Setting contrasts in R
As we will see in action below, in order to change the contrasts used in a model, we can assign specific types of contrasts to the variable in the data, by using code such as:
contrasts(data$variable) <- ...
This means that any model subsequently fitted to that data will now use the assigned contrasts.
To revert to the default, we can either a) read in the data again, or b) tell R that we now want to use the default contrasts, known as ‘treatment contrasts’, by using:
# To reset the contrasts to the default used in Rcontrasts(data$variable) <-"contr.treatment"
Treatment Contrasts (the default)
“Treatment contrasts” are the default that R uses. These are the ones we’ve discussed above. It compares each level to a reference level. A common example is to compare people taking drug A, drug B and drug C to a placebo group (the reference level).
When you use this approach:
the intercept is the estimated y when all predictors are zero. Because the reference level is kind of like “0” in our contrast matrix, this is part of the intercept estimate.
we get out a coefficient for each subsequent level, which are the estimated differences from each level to the reference group.
Sum Contrasts
“sum contrasts” (sometimes called “deviation contrasts” and “effects coding”) are the next most commonly used in psychological research. These are a way of comparing each level to the overall mean.
This involves a bit of trickery that uses -1s and 1s rather than 0s and 1s, in order to make “0” be mid-way between all the levels - the average of the levels.
We can adjust the coding scheme that we use like so:
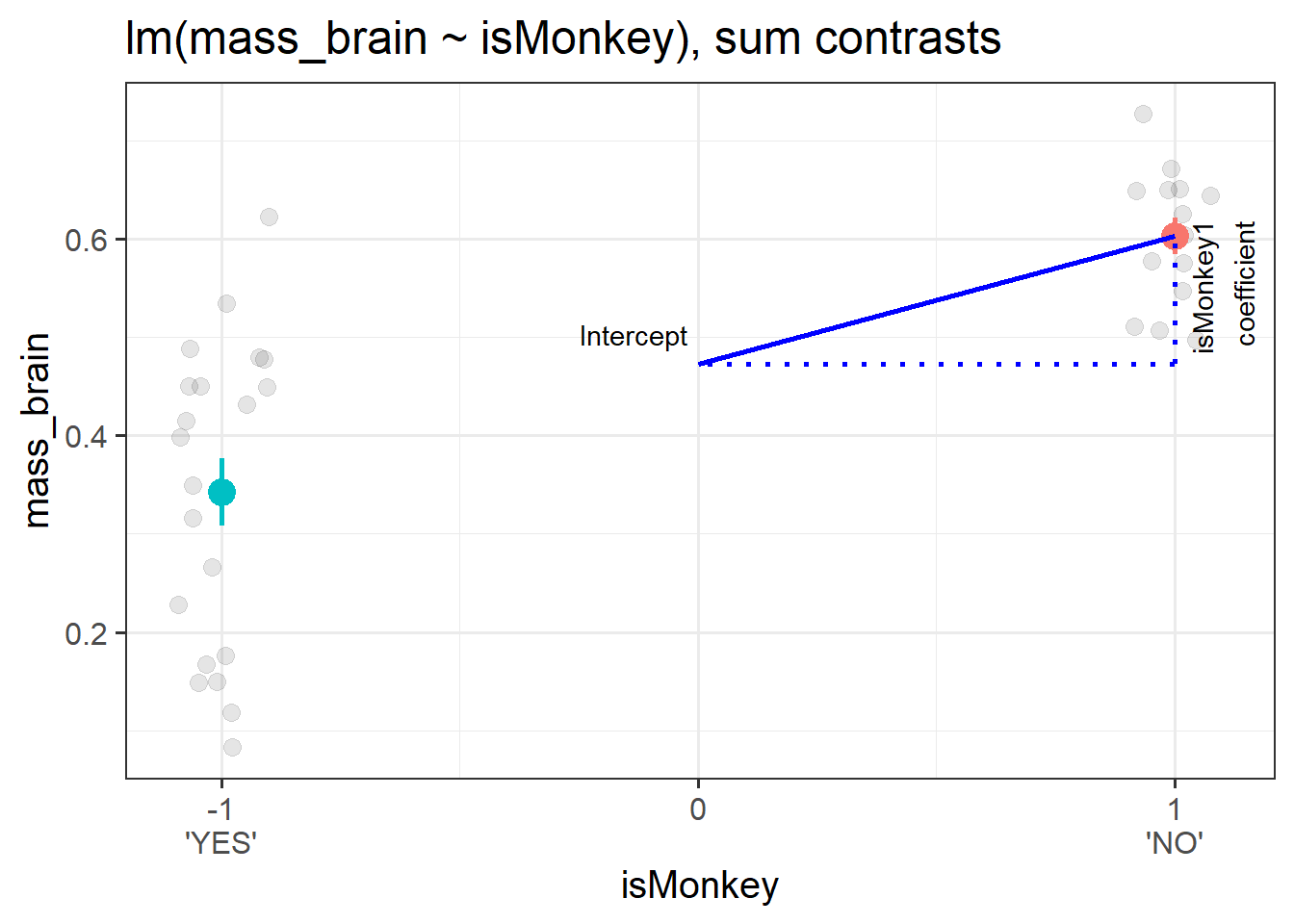
note that the column of the contrast matrix no longer has a name! It’s just got a [,1]. This means that the coefficient we get out is not going to have a name either:
Call:
lm(formula = mass_brain ~ isMonkey, data = braindata)
...
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.47279 0.02243 21.079 < 2e-16 ***
isMonkey1 0.12993 0.02243 5.793 1.78e-06 ***
The intercept from this model is the estimated average brain mass averaged across monkeys and non-monkeys. i.e. the estimated ‘grand mean’ brain mass.
The coefficient represents moving from the overall mean brain mass to the isMonkey=="NO" mean brain mass.1 This is visualised in Figure 3.
Figure 3: A binary categorical predictor with sum contrasts
When we move to using variables with more than 2 levels, sum contrasts can look a lot more confusing, but the interpretation stays the same.
Our intercept is the ‘grand mean’ (the estimated mean brain mass averaged across species).
Our first coefficient is the difference from the grand mean to the mean of humans.
Our second coefficient is the difference from the grand mean to the mean of Potar monkeys.
Because our intercept is the grand mean, and we express \(k\)-levels with \(k-1\) coefficients, we no longer have an estimate for our Rhesus monkeys (models can’t cope with redundant information, and it already knows that if an observation is not human, and is not Potar monkey, it must be a rhesus monkey).
There are a whole load of other types of contrasts we can use, and we can even set custom ones of our own. The choices are endless, and confusing, and it really depends on what exactly we want to get out of our model, which is going to depend on our research.
Some useful resources for your future research:
A page showing many many different contrast coding schemes (with R code and interpretation): https://stats.oarc.ucla.edu/r/library/r-library-contrast-coding-systems-for-categorical-variables/
The emmeans package (“estimated marginal means”) can come in handy for lots and lots of ways to compare groups. The package ‘vignette’ is at https://cran.r-project.org/web/packages/emmeans/vignettes/comparisons.html
Footnotes
we know it is to this group because a 1 increase in the column of our contrast matrix takes us to this group↩︎