myfirstvector <- c(1, 5, 3, 7)
myfirstvector[1] 1 5 3 7This reading:
We’ve already seen how to assign a value to a name/symbol using <-. However, we’ve only seen how to assign a single number, e.g, x <- 5.
In almost all cases, the data we are working with is more than just individual numbers. We might have measured the IQ of 20 different people, in which case we have 20 numbers representing IQ scores. More commonly, we work with 2-Dimensional arrays of numbers, e.g. each row is an observation, and each column represents something we have measured.
To store a sequence of numbers into R, we combine the values using c() and give the sequence a name. A sequence of elements all of the same type is called a vector. To view the stored content, simply type the name of the vector.
myfirstvector <- c(1, 5, 3, 7)
myfirstvector[1] 1 5 3 7We can perform arithmetic operations on each value of the vector. For example, to add five to each entry:
myfirstvector + 5[1] 6 10 8 12Recall that vectors are sequences of elements all of the same type. They do not have to be always numbers; they could be words such as real or fictional animals. Words need to be written inside quotations, e.g. “anything”, and instead of being of numeric type, we say they are characters.
wordsvector <- c("cat", "dog", "parrot", "peppapig")
wordsvector[1] "cat" "dog" "parrot" "peppapig"You can use either double-quote or single-quote:
c("cat", "dog", "parrot", "peppapig")[1] "cat" "dog" "parrot" "peppapig"c('cat', 'dog', 'parrot', 'peppapig')[1] "cat" "dog" "parrot" "peppapig"It does not make sense to add a number to words, hence some operations like addition and multiplication are only defined on vectors of numeric type. If you make a mistake, R will warn you with a red error message.
wordsvector + 5Error in wordsvector + 5 : non-numeric argument to binary operator
Finally, it is important to notice that if you combine together in a vector a number and a word, R will transform all elements to be of the same type. Why? Recall: vectors are sequences of elements all of the same type. Typically, R chooses the most general type between the two. In this particular case, it would make everything a character (sequence of letters), check the ““, as it would be harder to transform a word into a number!
mysecondvector <- c(4, "cat")
mysecondvector[1] "4" "cat"Dataframes are simply collections of vectors of the same length.
For instance, we could create a dataframe containing information on the name and birth year of each member of The Beatles. The easiest way to think of this would be to have a row for each Beatle, and a column for each of their names and their birth-years. Note that each vector contains all the same type of information (the names are all strings of characters, and the birth years are all numbers):
data.frame(
name = c("john","paul","george","ringo"),
birth_year = c(1940,1942,1943,1940)
) name birth_year
1 john 1940
2 paul 1942
3 george 1943
4 ringo 1940While we can manually create data like we did above, more often we will need to import into R some data which has been created elsewhere (like in excel, or by some software which is used to present participants with experiments).
Let’s suppose we have instead entered data in something like Microsoft Excel, or LibreOffice Calc, or whatever spreadsheet software we have available (Figure 1).
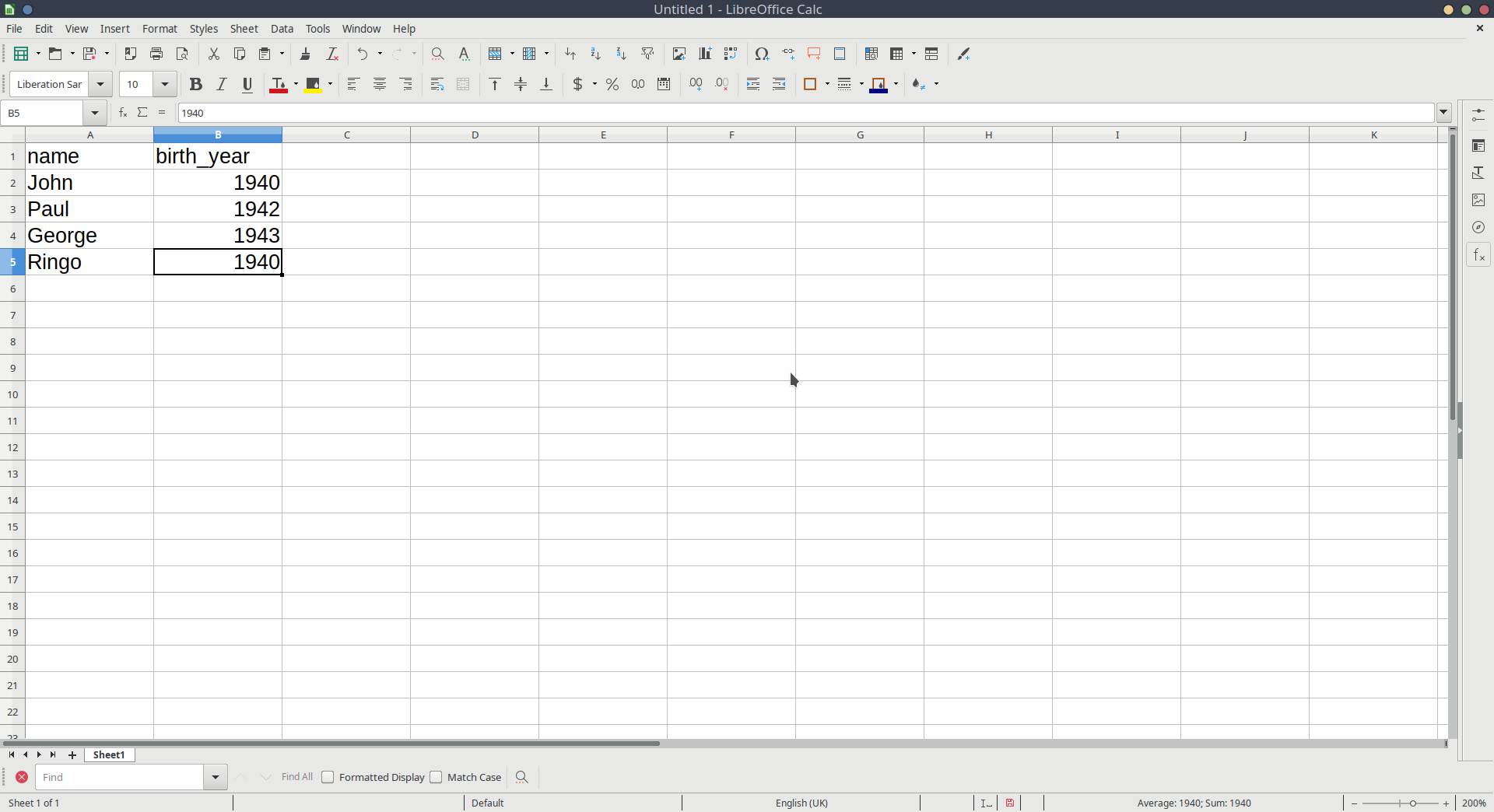
We can then save that data as a .csv file. Although R can read data when it’s saved in Microsoft/LibreOffice formats, the simplest, and most universal way to save data is as simple text, with the values separated by some character. The .csv format stands for comma separated values.1
Back in RStudio, we need to have a way of getting the information contained in that file into R’s environment, so that we can do things with it. We can do this by using the read.csv() function, and directing it to the file you just saved.
note: if you are using RStudio on a server - i.e. accessing it via a web-browser - then you will need to upload the file you just saved to the server (see the “upload” button in the Files tab in the bottom right pane of R).
read.csv("data_from_excel.csv") name birth_year
1 John 1940
2 Paul 1942
3 George 1943
4 Ringo 1940Helpful tip
If you have your text-cursor inside the quotation marks, and press the tab key on your keyboard, it will show you the files inside your project. You can then use the arrow keys to choose between them and press Enter to add the code:
There’s one more thing that we need to do, and that is to actually store this information in our environment. Currently, it is just printing out the data. We need to assign it a name:
beatles <- read.csv("data_from_excel.csv")We should now have something called “beatles” which is visible in the environment pane of RStudio (top right).
And we can print it out by simply invoking its name:
beatles name birth_year
1 John 1940
2 Paul 1942
3 George 1943
4 Ringo 1940And we can do things such as ask R how many rows and columns there are (asking for the “dimensions” using dim()):
dim(beatles)[1] 4 2This says that there are 4 members of the Beatles, and for each we have 2 measurements.
To get more insight into what the data actually are, you can either use the structure str() function:
str(beatles)'data.frame': 4 obs. of 2 variables:
$ name : chr "John" "Paul" "George" "Ringo"
$ birth_year: int 1940 1942 1943 1940We’ve just seen some use of c(), read.csv(), dim() and str().
There’s something that all these things have in common - they are functions.
Functions perform specific operations / transformations in computer programming.
They can have inputs and outputs. For example, dim() takes some data you have stored in R as its input, and gives the dimensions of the data as its output.
There are loads and loads of functions in R. This is really where the power lies. Here is a demonstration of a couple of basic ones. Hopefully you can guess what they are doing?
myfirstvector <- c(1, 5, 3, 7)
sum(myfirstvector)[1] 16mean(myfirstvector)[1] 4Getting Help on Functions
Almost all functions in R will have associated documentation describing what they do. If we don’t know what a function does, we can read the help docs by typing a question mark and then the function name, and running it in R. ?mean will bring up a little help page in the bottom-right pane of RStudio
Alongside the basic installation of R and RStudio, there are many add-on packages which the R community create and maintain. The thousands of packages are part of what makes R such a powerful and useful tool - there is a package for almost everything you could want to do in R.
Packages are bundles of functions, code, data, documentation, etc.
To install a package onto our computer we use install.packages("package name").
Then, any time that we want to use that package we just need to load it into our current R session with library(package name).

Here we’re going to install a silly package called cowsay:
install.packages("cowsay")This spits out a lot of messages, before (hopefully) ending with something similar to:
…
…
* DONE (cowsay)
The downloaded source packages are in
‘/tmp/RtmpIRbMnh/downloaded_packages’
>
Now that we’ve installed it, to use it we just need to load it into our R session, by using library():
library(cowsay)Which enables us to now use some of the functionality that is in that package, such as the say() function, which makes some silly art out of punctuation symbols:
say("Welcome to the USMR course!", by = "owl")
-----
Welcome to the USMR course!
------
\
\
\
/\___/\
{o}{o}|
\ v /|
| \ \
\___/_/ [ab]
| | It’s good practice to have all the packages you use for an analysis loaded at the top of your script.
A typical structure for an R script is to:
We will be using these packages quite a lot in this course, so you might want to install them now:
Hopefully, if you are following along with us, you are writing your code in a script, and not in the console. Remember: Code that you write in the console is not saved.
Sometimes, however, for certain things, we might not want to keep a record of that bit of code.
Consider the example code below. The 2nd, 3rd, and 5th lines do absolutely nothing to our computations with x and y. They are just for our own workings. Because lines like this have no consequences on code below, our R script will have the same end-point with and without those line.
x <- 4
x
4*33
y <- 6/100
?mean
answer <- x*yIn general, the vast majority of the code you write will be in the script, and you will only use the console occasionally for quick commands that aren’t doing anything to change our analysis. For example, we don’t want to keep re-installing packages over and over again (each time we run a script), so we’ll tend to use install.packages() in the console. Similarly, when we look up the help documentation for a function (e.g. by running ?mean), we type that into the console, and not a script.
This will become second nature as you use R more and more, but it’s helpful to get into good habits early on.
Rules of thumb
If we don’t follow the above suggestions, then our work will not be* reproducible (e.g. you send your script to someone and they will get a different answer from you when they run it).
Now that we’ve started to learn about vectors and dataframes, we’re going to look at reading in some data, exploring some of the variables, and the syntax we can use to access and edit certain bits of a dataset.
First we’ll read in some data:
starwars2 <- read.csv("https://uoepsy.github.io/data/starwars2.csv")Reading data from a URL
Note that when you have a url for some data (e.g. this) you can read it in directly by giving functions like read.csv() the url inside quotation marks.
The data contains information on various characteristics of characters from Star Wars. We can print out the top of the data by using the head() function which displays the first six rows of the data by default. You could change this by saying, for example, head(data, n = 10):
head(starwars2, n = 10) name height hair_color eye_color homeworld species
1 Luke Skywalker 172 blond blue Tatooine Human
2 C-3PO 167 <NA> yellow Tatooine Human
3 R2-D2 96 <NA> red Naboo Droid
4 Darth Vader 202 none yellow Tatooine Human
5 Leia Organa 150 brown brown Alderaan Human
6 Owen Lars 178 brown, grey blue Tatooine Human
7 Beru Whitesun lars 165 brown blue Tatooine Human
8 R5-D4 97 <NA> red Tatooine Droid
9 Biggs Darklighter 183 black brown Tatooine Human
10 Obi-Wan Kenobi 182 auburn, white blue-gray Stewjon Human(Don’t worry about the NAs for now, they are just how R tells you an entry is missing, i.e. Not Available.)
Tip: Try clicking on the data in your environment (the top right window of RStudio). It will open the data in a tab in the editor window - this is another way of looking at the data, more like you would in spreadsheet software like Microsoft Excel. This can be time-consuming if your data file is big.
We can take a look at how big the data is (the dimensions), using dim()
dim(starwars2)[1] 75 6We can see that there are 75 rows and 6 columns. In this dataset, each Star Wars character is an observational unit, and there are 6 variables (things which vary between units) such as their height, species, homeworld, etc.
observations and variables
The individual entities on which data are collected are called observational units or cases. Often (but not always), these equate to the rows of a dataset.
A variable is any characteristic that varies from observational unit to observational unit (these are often the columns of the dataset)
What if we want to extract certain subsections of our dataset, such as specific observational units or variables? This is where we learn about two important bits of R code used to access parts of data - the dollar sign $, and the square brackets [].
The dollar sign $
The dollar sign allows us to extract a specific variable from a dataframe. For instance, we can pull out the variable named “eye_color” in the data, by using $eye_color after the name that we gave our dataframe.
Remember that each variable in a dataframe is a vector (a set of values). Once extracted, we will have a vector and not a dataframe.
starwars2$eye_color [1] "blue" "yellow" "red" "yellow"
[5] "brown" "blue" "blue" "red"
[9] "brown" "blue-gray" "blue" "blue"
[13] "blue" "brown" "black" "orange"
[17] "hazel" "blue" "yellow" "brown"
[21] "red" "brown" "blue" "orange"
[25] "blue" "brown" "black" "red"
[29] "blue" "orange" "orange" "orange"
[33] "yellow" "orange" NA "brown"
[37] "yellow" "pink" "hazel" "yellow"
[41] "black" "orange" "brown" "yellow"
[45] "black" "brown" "blue" "orange"
[49] "yellow" "black" "blue" "brown"
[53] "brown" "blue" "yellow" "blue"
[57] "blue" "brown" "brown" "brown"
[61] "brown" "yellow" "yellow" "black"
[65] "black" "blue" "unknown" "unknown"
[69] "gold" "black" "green, yellow" "blue"
[73] "brown" "black" NA The square brackets []
Square brackets are used to do what is known as indexing (finding specific entries in your data).
We can retrieve bits of data by identifying the \(i^{th}\) entry(s) inside the square brackets, for instance:
# assign the numbers 10, 20 ... 100 to the name "somevalues"
somevalues <- c(10, 20, 30, 40, 50, 60, 70, 80, 90, 100)
# pull out the 3rd entry
somevalues[3][1] 30Let’s look at some examples:
# first row, fourth column
starwars2[1, 4]
# tenth row, first column
starwars2[10, 1]# tenth row, all columns
starwars2[10, ]
# all rows, 2nd column
starwars2[ , 2]# first row, "species" column
starwars2[1, "species"]c():# the 1st AND the 6th rows, and the 1st AND 3rd columns
starwars2[c(1,6), c(1,3)] from:to:# FROM the 1st TO the 6th row, all columns
starwars2[1:6, ] Why? Because the colon operator, `from:to`, creates a vector from the value `from` to the value `to` in steps of 1.1:6[1] 1 2 3 4 5 6# extract the variable called "name" and show the 20th entry
starwars2$name[20] This represents the 20th name in the data.
Note: When we do this, we don't have the comma inside the square brackets. When we use the `$` to pull out a variable, such as `starwars2$name`, we no longer have a dataframe - `starwars2$name` doesn't have rows and columns, it just has a series of values - _it's a vector!_. So when you are using `[]` with a __vector__ (1 dimension) rather than a __dataframe__ (2 dimensions), you don't specify `[rows, columns]`, but simply `[entry]`. # first row, fourth column
starwars2[1, 4][1] "blue"# tenth row, first column
starwars2[10, 1][1] "Obi-Wan Kenobi"# tenth row, all columns
starwars2[10, ] name height hair_color eye_color homeworld species
10 Obi-Wan Kenobi 182 auburn, white blue-gray Stewjon Human# all rows, 2nd column
starwars2[ , 2] [1] 172 167 96 202 150 178 165 97 183 182 188 180 228 180 173 175 170 180 170
[20] 183 190 177 175 180 150 88 160 191 170 196 224 206 137 112 170 163 175 180
[39] 178 94 122 163 188 198 196 171 184 188 264 188 196 185 157 183 183 170 166
[58] 165 193 191 183 168 198 229 213 167 79 193 191 178 216 234 188 206 180# first row, "species" column
starwars2[1, "species"][1] "Human"c():# the 1st AND the 6th rows, and the 1st AND 3rd columns
starwars2[c(1,6), c(1,3)] name hair_color
1 Luke Skywalker blond
6 Owen Lars brown, greyfrom:to:# FROM the 1st TO the 6th row, all columns
starwars2[1:6, ] name height hair_color eye_color homeworld species
1 Luke Skywalker 172 blond blue Tatooine Human
2 C-3PO 167 <NA> yellow Tatooine Human
3 R2-D2 96 <NA> red Naboo Droid
4 Darth Vader 202 none yellow Tatooine Human
5 Leia Organa 150 brown brown Alderaan Human
6 Owen Lars 178 brown, grey blue Tatooine Human# extract the variable called "name" and show the 20th entry
starwars2$name[20] [1] "Boba Fett"The dollar sign $
Used to extract a variable from a dataframe:
dataframe$variableThe square brackets []
Used to extract parts of an R object by identifying rows and/or columns, or more generally, “entries”. Left blank will return all.
vector[entries]dataframe[rows, columns]We can also do something really useful, which is to access all the entries in the data for which a specific condition is true.
Let’s take a simple example to start:
somevalues <- c(10, 10, 0, 20, 15, 40, 10, 40, 50, 35)To only select values which are greater than 20, we can use:
somevalues[somevalues > 20][1] 40 40 50 35Unpacking: somevalues[somevalues > 20]
First, let’s look at what somevalues > 20 does. It returns TRUE for the entries of somevalues which are greater than 20, and FALSE for the entries of somevalues that are not (that is, which are less than, or equal to, 20.
This statement somevalues > 20 is called the condition.
somevalues > 20 [1] FALSE FALSE FALSE FALSE FALSE TRUE FALSE TRUE TRUE TRUEWe can give a name to this sequence of TRUEs and FALSEs
condition <- somevalues > 20
condition [1] FALSE FALSE FALSE FALSE FALSE TRUE FALSE TRUE TRUE TRUENow consider putting the sequence of TRUEs and FALSEs inside the square brackets in somevalues[]. This returns only the entries of somevalues for which the condition is TRUE.
somevalues[condition][1] 40 40 50 35So what we can do is use a condition inside the square brackets to return all the values for which that condition is TRUE.
Note that you don’t have to always give a name to the condition. This works too:
somevalues[somevalues > 20][1] 40 40 50 35
We can extend this same logic to a dataframe. Let’s suppose we want to access all the entries in our Star Wars data who have the value “Droid” in the species variable. To work out how to do this, we first need a line of code which defines our condition - one which returns TRUE for each entry of the species variable which is “Droid”, and FALSE for those that are not “Droid”.
We can use the dollar sign to pull out the species variable:
starwars2$species [1] "Human" "Human" "Droid" "Human" "Human"
[6] "Human" "Human" "Droid" "Human" "Human"
[11] "Human" "Human" "Wookiee" "Human" "Rodian"
[16] "Hutt" "Human" "Human" "Human" "Human"
[21] "Trandoshan" "Human" "Human" "Mon Calamari" "Human"
[26] "Ewok" "Sullustan" "Neimodian" "Human" "Gungan"
[31] "Gungan" "Gungan" "Toydarian" "Dug" "unknown"
[36] "Human" "Zabrak" "Twi'lek" "Twi'lek" "Vulptereen"
[41] "Xexto" "Toong" "Human" "Cerean" "Nautolan"
[46] "Zabrak" "Tholothian" "Iktotchi" "Quermian" "Kel Dor"
[51] "Chagrian" "Human" "Human" "Human" "Geonosian"
[56] "Mirialan" "Mirialan" "Human" "Human" "Human"
[61] "Human" "Clawdite" "Besalisk" "Kaminoan" "Kaminoan"
[66] "Human" "Aleena" "Skakoan" "Muun" "Togruta"
[71] "Kaleesh" "Wookiee" "Human" "Pau'an" "unknown" And we can ask R whether each value is equal to “Droid” (Remember: in R, we ask whether something is equal to something else by using a double-equals, ==). A single equal sign would be wrong, as it denotes assignment.
starwars2$species == "Droid" [1] FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE
[13] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[25] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[37] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[49] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[61] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[73] FALSE FALSE FALSEFinally, we can use this condition inside our square brackets to access the entries of the data for which this condition is TRUE:
# I would read the code below as:
# "In the starwars2 dataframe, give me all the rows for which the
# condition starwars2$species=="Droid" is TRUE, and give me all the columns."
starwars2[starwars2$species == "Droid", ] name height hair_color eye_color homeworld species
3 R2-D2 96 <NA> red Naboo Droid
8 R5-D4 97 <NA> red Tatooine DroidThinking back to Section 1A when we first introduced R, we talked briefly about “logical operators”. Specifically, the operators &, |, and ! (for “and”, “or”,” and “not”), will come in handy now.
For instance, we can now extract all those in the dataset which are humans and taller than 190cm:
# "In the starwars2 dataframe, give me all the rows for which the
# condition starwars2$species=="Human" AND starwars2$height > 190 are TRUE,
# and give me all the columns."
starwars2[starwars2$species == "Human" & starwars2$height > 190, ] name height hair_color eye_color homeworld species
4 Darth Vader 202 none yellow Tatooine Human
59 Dooku 193 white brown Serenno Human
60 Bail Prestor Organa 191 black brown Alderaan HumanOr we can extract all those in the dataset which are either droids or ewoks:
# "In the starwars2 dataframe, give me all the rows for which the
# condition starwars2$species=="Droid" OR starwars2$species=="Ewok" is TRUE,
# and give me all the columns."
starwars2[starwars2$species == "Droid" | starwars2$species == "Ewok", ] name height hair_color eye_color homeworld species
3 R2-D2 96 <NA> red Naboo Droid
8 R5-D4 97 <NA> red Tatooine Droid
26 Wicket Systri Warrick 88 brown brown Endor EwokNow that we’ve seen a few ways of accessing sections of data, we can learn how to edit them! One of the most common reasons you will need to modify entries in your data is in data cleaning. This is the process of identifying incorrect/incomplete/irrelevant data, and replacing/modifying/deleting them.
Above, we looked at the subsection of the data where the species variable had the entry “Droid”. Some of you may have noticed earlier that we had some data on C3PO. Is he not also a droid?

(Looks pretty Droid-y to me! disclaimer: I know nothing about Star Wars 🙂 )
Just as we saw above how to access specific entries, e.g.:
# 2nd row, all columns
starwars2[2, ] name height hair_color eye_color homeworld species
2 C-3PO 167 <NA> yellow Tatooine Human# 2nd row, 6th column (the "species" column)
starwars2[2,6][1] "Human"We can change these by assigning them a new value (remember the <- symbol). In doing so, we replace / overwrite / reassign the entry in the 2nd row and 6th column of the data (starwars2[2,6]) with the value “Droid”.
# C3PO is a droid, not a human
starwars2[2,6] <- "Droid"
# Look at the 2nd row now -
# the entry in the "species" column has changed:
starwars2[2, ] name height hair_color eye_color homeworld species
2 C-3PO 167 <NA> yellow Tatooine DroidWe saw above how to access parts of data by means of a condition, with code such as:
# "In the starwars2 dataframe, give me all the rows for which the
# condition starwars2$homeworld=="Naboo" is TRUE, and give me all the columns."
starwars2[starwars2$homeworld=="Naboo", ] name height hair_color eye_color homeworld species
3 R2-D2 96 <NA> red Naboo Droid
19 Palpatine 170 grey yellow Naboo Human
30 Jar Jar Binks 196 none orange Naboo Gungan
31 Roos Tarpals 224 none orange Naboo Gungan
32 Rugor Nass 206 none orange Naboo Gungan
52 Gregar Typho 185 black brown Naboo Human
53 Cordé 157 brown brown Naboo Human
58 Dormé 165 brown brown Naboo HumanWhat if we wanted to modify it so that every character from “Naboo” was actually of species “Nabooian”?
We can do that in a number of ways, all of which do the same thing - namely, they access parts of the data and assign them the new value “Nabooian”.
Study the lines of code below and their interpretations:
# In the starwars2 data, give the rows for which condition
# starwars2$homeworld=="Naboo" is TRUE, and select only the "species" column.
# Assign to these selected entries the value "Nabooian".
starwars2[starwars2$homeworld=="Naboo", "species"] <- "Nabooian"
# In the starwars2 data, give the rows for which condition
# starwars2$homeworld=="Naboo" is TRUE, and select only the 6th column.
# Assign to these selected entries the value "Nabooian".
starwars2[starwars2$homeworld=="Naboo", 6] <- "Nabooian"
# Extract the species variable from the starwars2 data (it's a vector).
# Pick the entries for which the condition starwars2$homeworld=="Naboo" is TRUE.
# Assign to these selected entries the value "Nabooian".
starwars2$species[starwars2$homeworld=="Naboo"] <- "Nabooian"Another thing we might want to do is change a whole variable (a whole column) in some way.
The logic is exactly the same, for instance, we can take the variable “height” from the dataframe “starwars2”, dividing it by 100 via starwars2$height / 100, and then assign the result to the same variable name in the data, i.e. we overwrite the column:
starwars2$height <- starwars2$height / 100We could instead have added a new column named “height_m” with those values if we did not want to overwrite “height”:
starwars2$height_m <- starwars2$height / 100This would have left the “height” variable as-is, and created a new one called “height2” which was the values in “height” divided by 100.
Lastly, we might want to change the data by removing a row or a column. Again, the logic remains the same, in that we use <- to assign the edited data to a name (either a new name, thus creating a new object, or an existing name, thereby overwriting that object).
For instance, notice that the 35th and 75th rows of our data probably aren’t a valid observation - I’m reasonably sure that Marge and Homer Simpson never appeared in Star Wars:
starwars2[c(35,75), ] name height hair_color eye_color homeworld species
35 Marge Simpson 1.7 Blue <NA> Springfield unknown
75 Homer Simpson 1.8 <NA> <NA> Springfield unknownWe can remove a certain row(s) by using a minus sign - inside the square brackets
# everything minus the 75th row
starwars2[-75, ]
# everything minus the (35th and 75th rows)
starwars2[-c(35, 75), ]And we can simply re-use the name “starwars2” to overwrite the data and make this change take effect (rather than just print out the result, which the code above did):
starwars2 <- starwars2[-c(35, 75), ](now, in the environment pane of Rstudio, the object named “starwars2” will say 73 observations, rather than 75, which it had before - we’ve removed the 2 rows)
The same logic applies for columns:
# Create a new object called "anonymous_starwars2" and assign it
# to the values which are the "starwars2" dataframe minus the
# 1st column (the "name" column):
anonymous_starwars2 <- starwars2[, -1]
# dimensions of our initial data
dim(starwars2)[1] 73 6# the data we just assigned has one fewer columns
dim(anonymous_starwars2)[1] 73 5To save as .csv in Microsoft Excel, we go to File > Save as, and then in the Save as Type box, choose to save the file as CSV (Comma delimited)↩︎