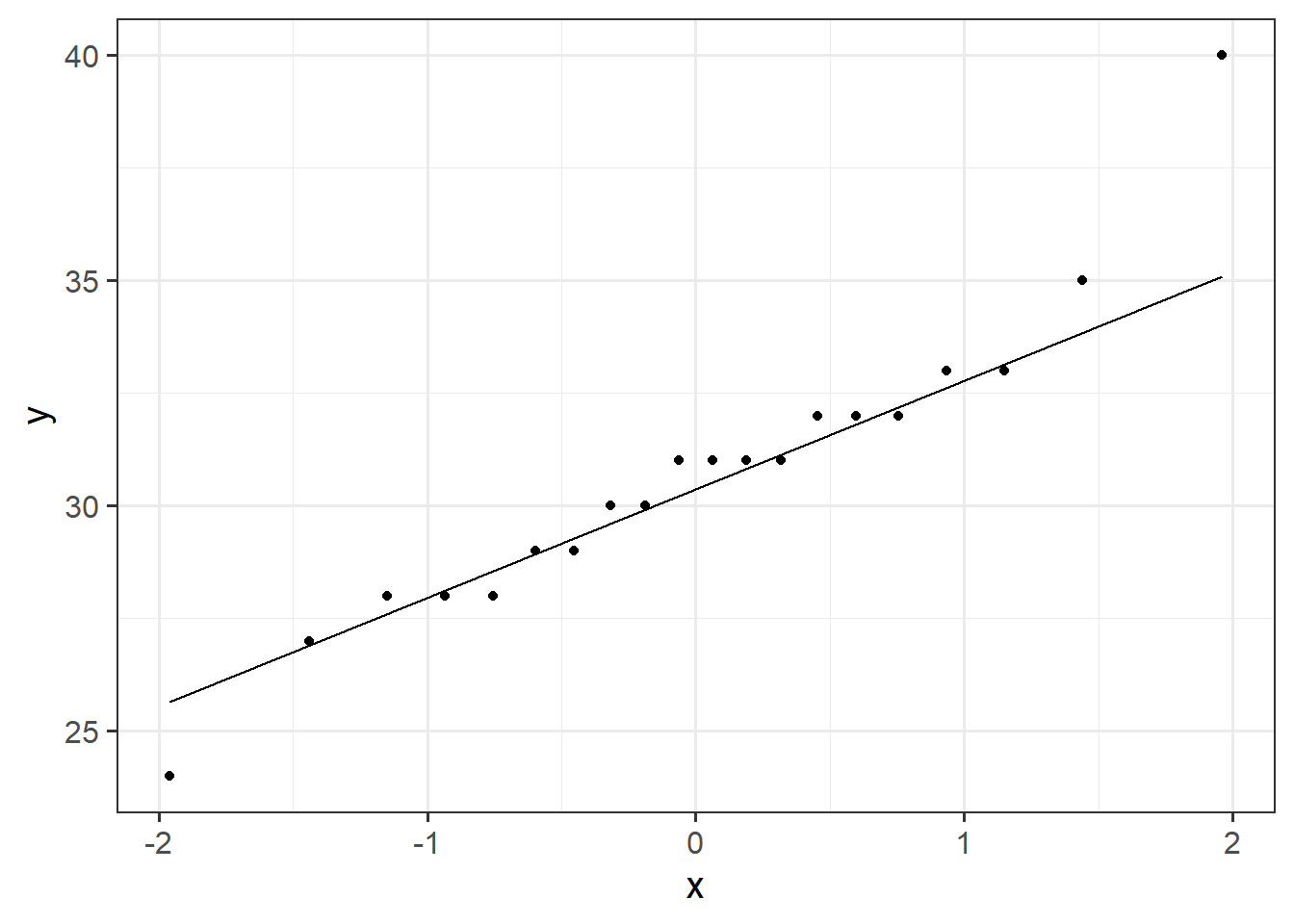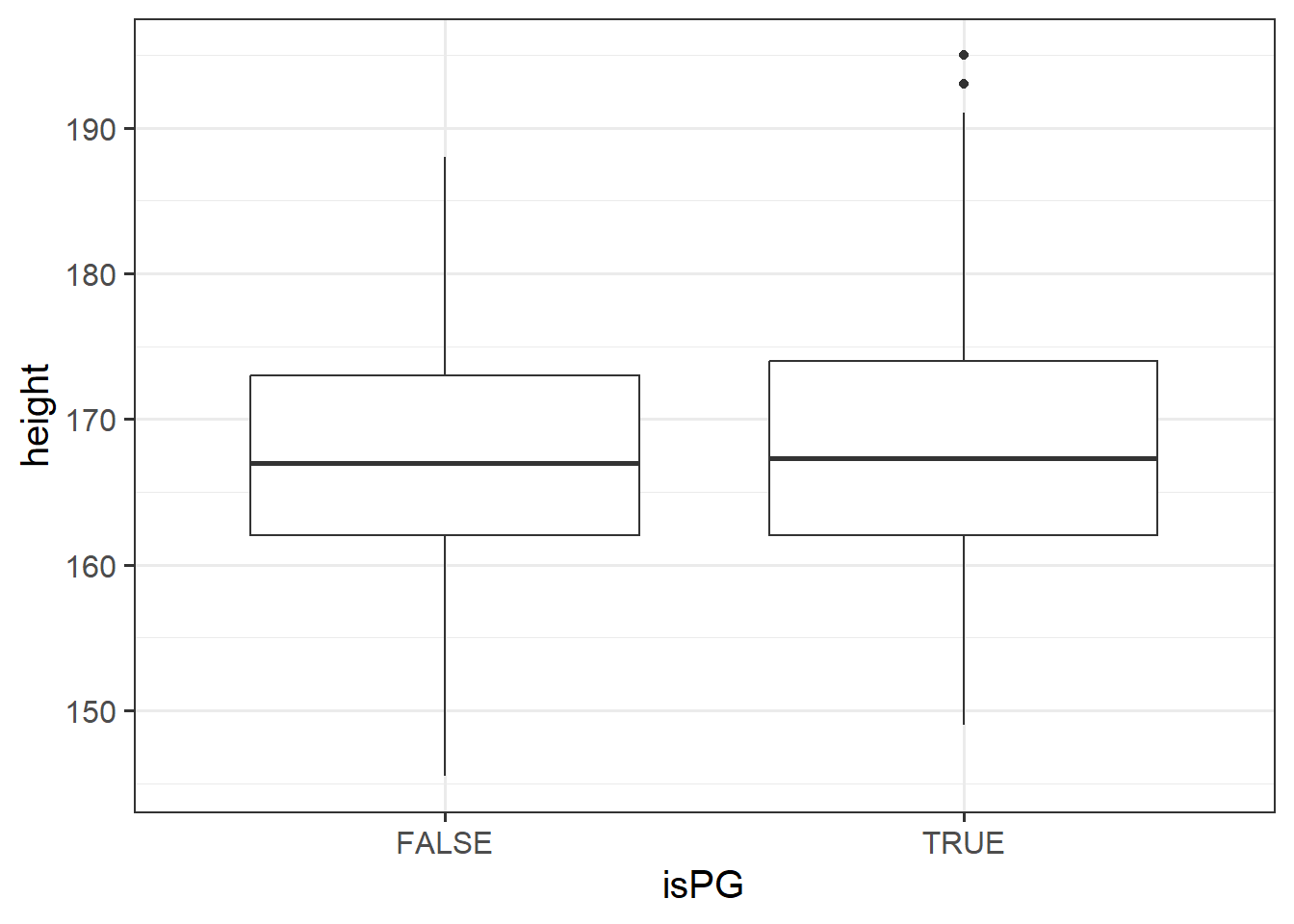qnorm(c(0.025, 0.975))[1] -1.959964 1.959964At the end of last week’s exercises, we estimated the mean sleep-quality rating, and computed a confidence interval, using the formula below.
\[ \begin{align} \text{95\% CI: }& \bar x \pm 1.96 \times SE \\ \end{align} \]
Can you use R to show where the 1.96 comes from?
qnorm! (see the end of 03A #uncertainty-due-to-sampling)
As we learned in 3B #t-distributions, the sampling distribution of a statistic has heavier tails the smaller the size of the sample it is derived from. In practice, we are better using \(t\)-distributions to construct confidence intervals and perform statistical tests.
The code below creates a dataframe that contains the number of books read by 7 people in 2023.
(Note tibble is just a tidyverse version of data.frame):
bookdata <-
tibble(
person = c("Martin","Umberto","Monica","Emma","Josiah","Dan","Aja"),
books_read = c(12,19,9,11,8,28,13)
)Calculate the mean number of books read in 2023, and construct an appropriate 95% confidence interval.
Will a 90% confidence interval be wider or narrow?
Calculate it and see.
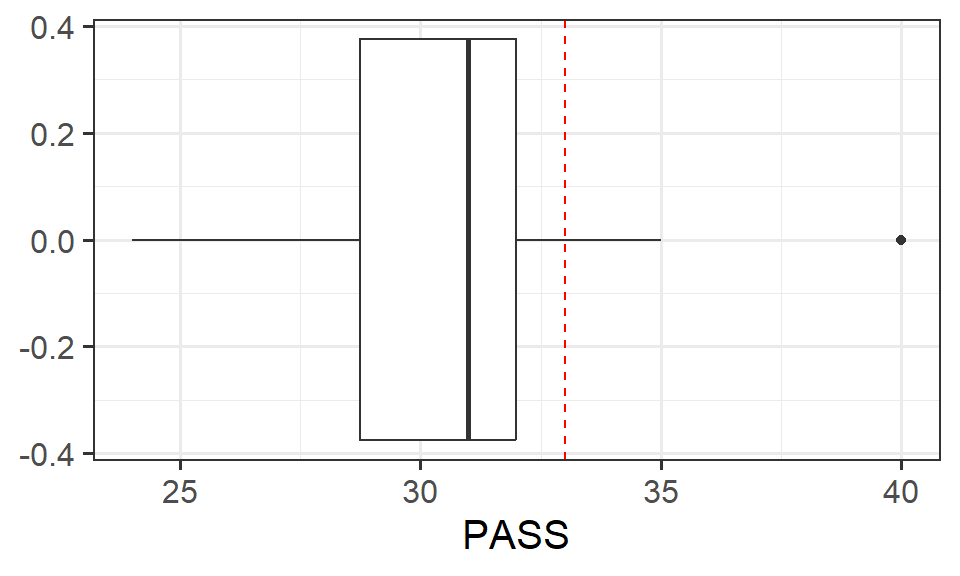
Research Question Do Edinburgh University students report endorsing procrastination less than the norm?
The Procrastination Assessment Scale for Students (PASS) was designed to assess how individuals approach decision situations, specifically the tendency of individuals to postpone decisions (see Solomon & Rothblum, 1984). The PASS assesses the prevalence of procrastination in six areas: writing a paper; studying for an exam; keeping up with reading; administrative tasks; attending meetings; and performing general tasks. For a measure of total endorsement of procrastination, responses to 18 questions (each measured on a 1-5 scale) are summed together, providing a single score for each participant (range 0 to 90). The mean score from Solomon & Rothblum, 1984 was 33.
A student administers the PASS to 20 students from Edinburgh University.
The data are available at https://uoepsy.github.io/data/pass_scores.csv.
Our test here is going to be have the following hypotheses:
Manually calculate the relevant test statistic.
Note, we’re doing this manually right now as it’s a useful learning process. In later questions we will switch to the easy way!
Using the test statistic calculated in question 1, compute the p-value.
pt() function.
Now using the t.test() function, conduct the same test. Check that the numbers match with your step-by-step calculations in the previous two questions.
Check out the help page for t.test() - there is an argument in the function that allows us to easily change between whether our alternative hypothesis is “less than”, “greater than” or “not equal to”.
Create a visualisation to illustrate the results.
Write up the results.
There are some quick example write-ups for each test in 3B #basic-tests
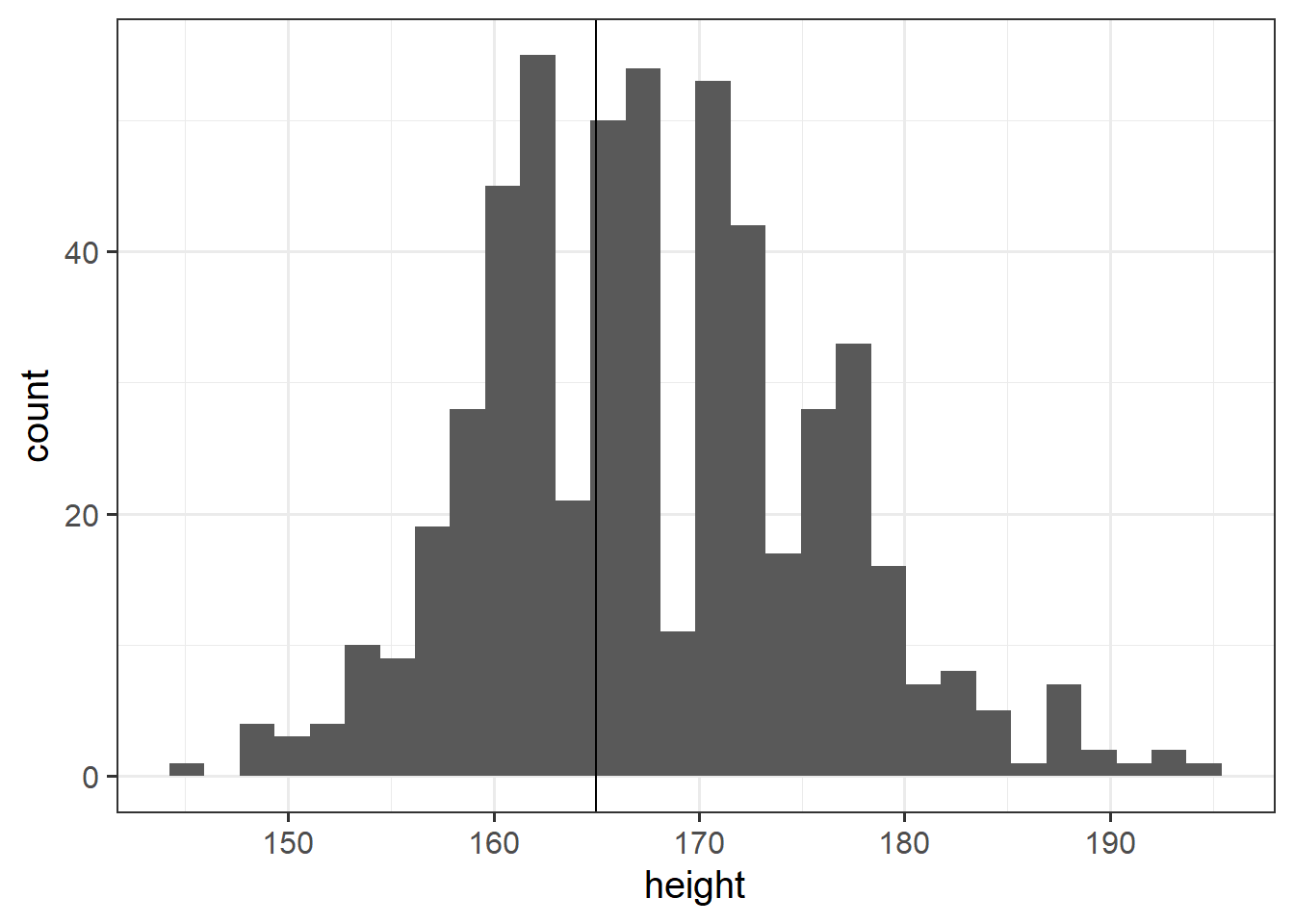
Research Question Is the average height of University of Edinburgh Psychology students different from 165cm?

Data: Past Surveys
In the last few years, we have asked students of the statistics courses in the Psychology department to fill out a little survey.
Anonymised data are available at https://uoepsy.github.io/data/surveydata_historical.csv.
Note: this does not contain the responses from this year.
surveydata <-
read_csv("https://uoepsy.github.io/data/surveydata_historical.csv")No more manual calculations of test statistics and p-values for this week.
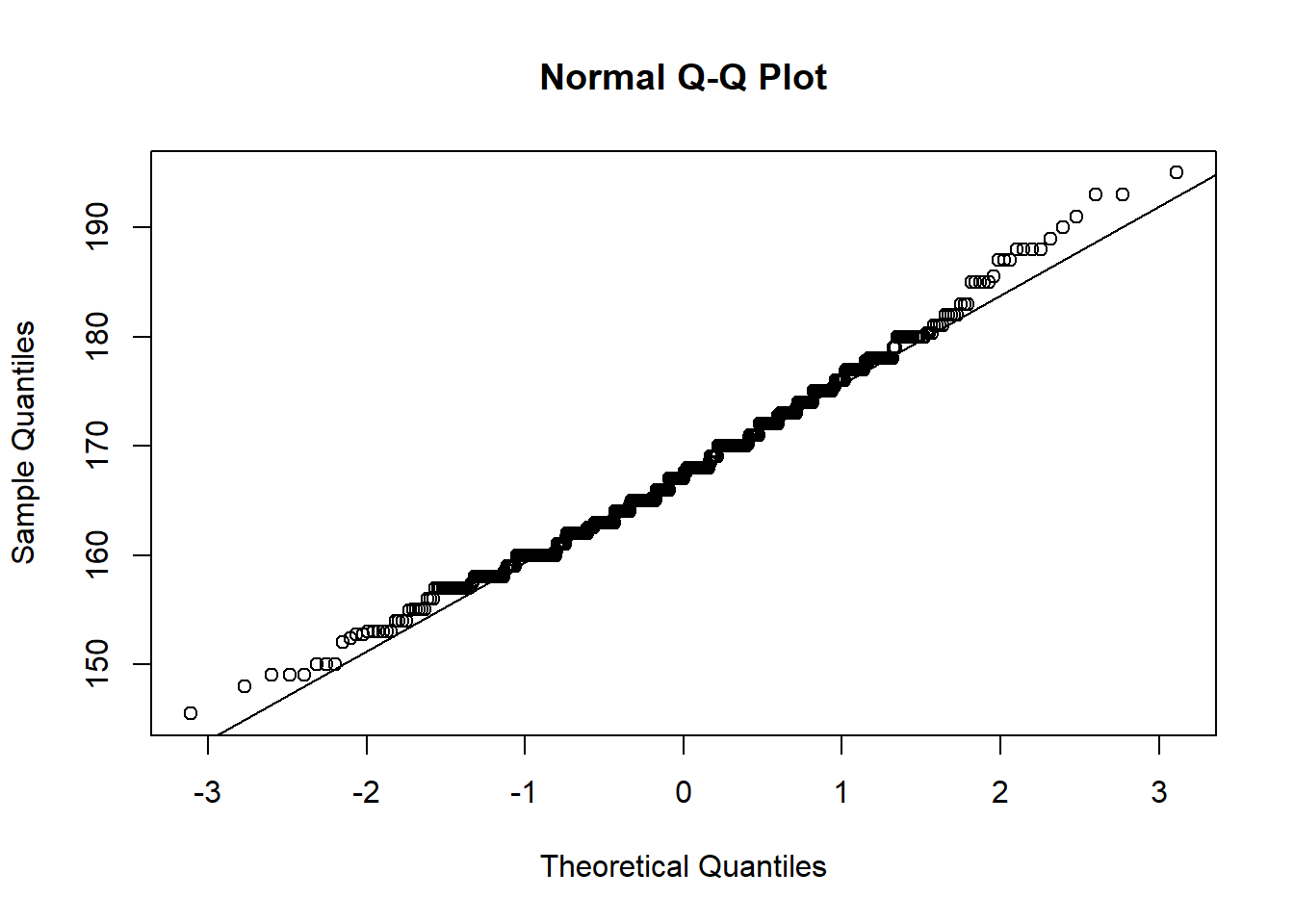
Conduct a one sample \(t\)-test to evaluate whether the average height of UoE psychology students in the last few years was different from 165cm.
Make sure to consider the assumptions of the test!

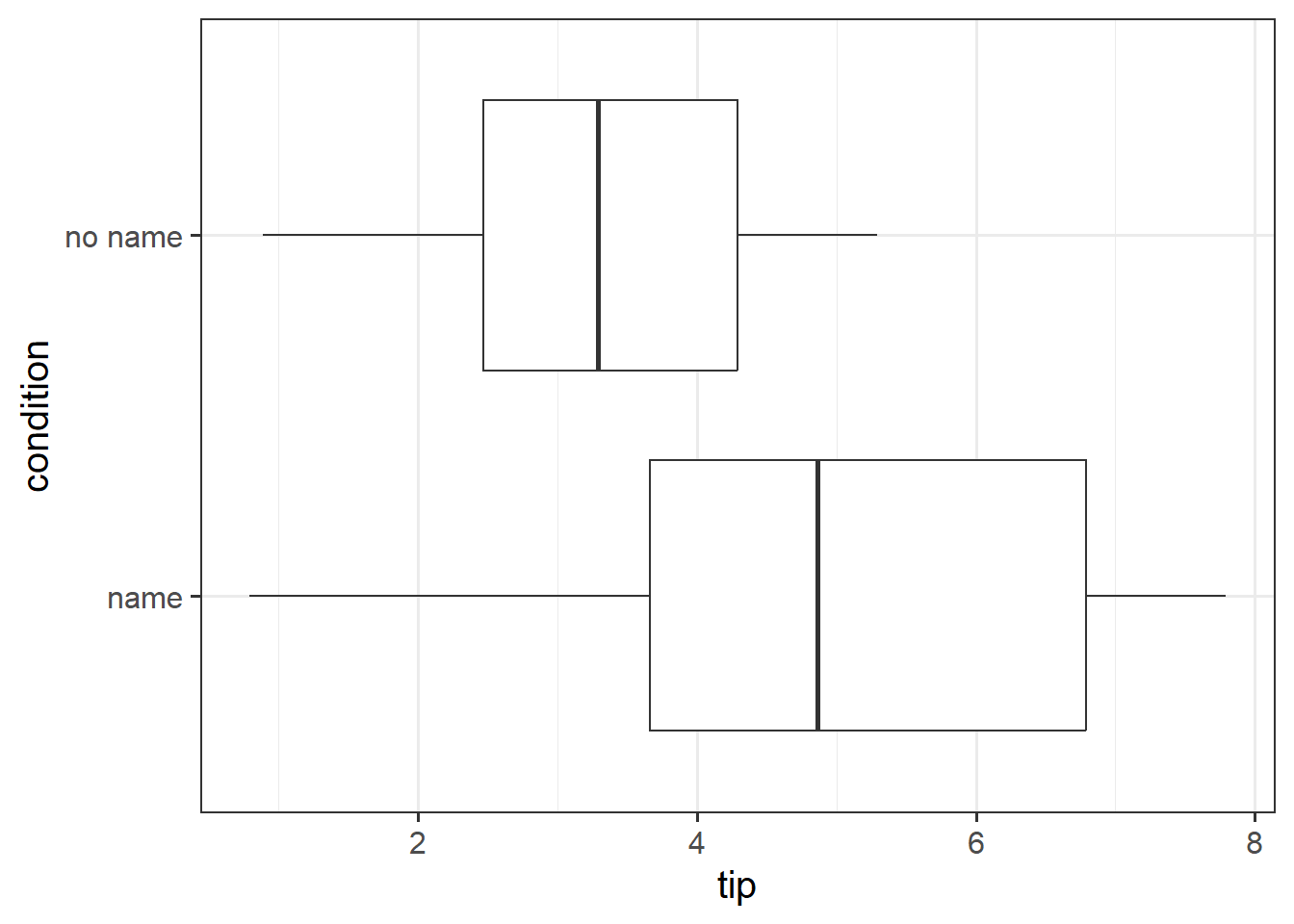
Research Question Can a server earn higher tips simply by introducing themselves by name when greeting customers?
Researchers investigated the effect of a server introducing herself by name on restaurant tipping. The study involved forty, 2-person parties eating a $23.21 fixed-price buffet Sunday brunch at Charley Brown’s Restaurant in Huntington Beach, California, on April 10 and 17, 1988.
Each two-person party was randomly assigned by the waitress to either a name or a no-name condition. The total amount paid by each party at the end of their meal was then recorded.
The data are available at https://uoepsy.github.io/data/gerritysim.csv. (This is a simulated example based on Garrity and Degelman (1990))
Conduct an independent samples \(t\)-test to assess whether higher tips were earned when the server introduced themselves by name, in comparison to when they did not.
alternative = ??.var.test() function.
Here are a few extra questions for you to practice performing tests and making plots:
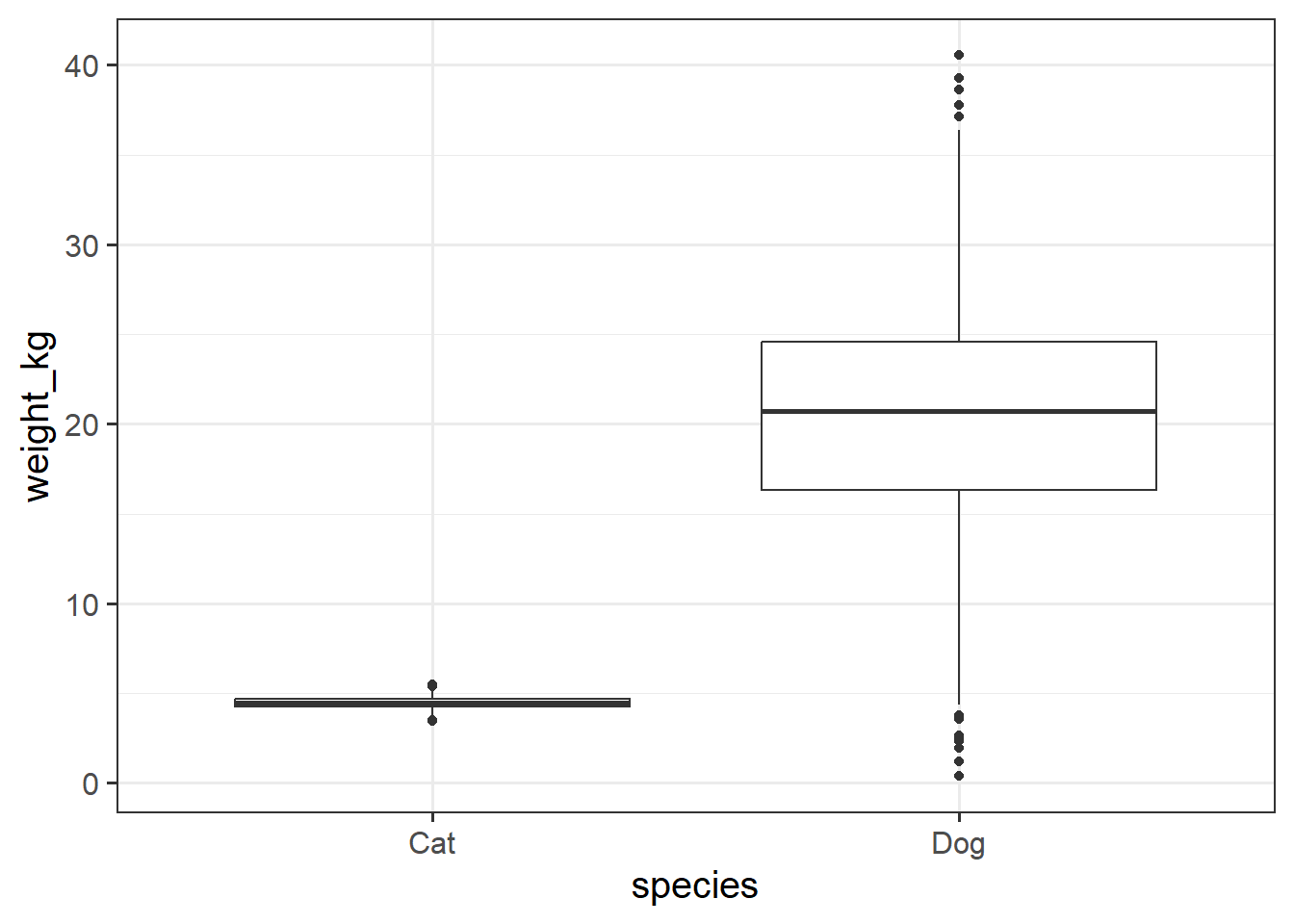
Are dogs heavier on average than cats?
Data from Week 1: https://uoepsy.github.io/data/pets_seattle.csv
Is taking part in a cognitive behavioural therapy (CBT) based programme associated with a greater reduction, on average, in anxiety scores in comparison to a Control group?
Data are at https://uoepsy.github.io/data/cbtanx.csv. The dataset contains information on each person in an organisation, recording their professional role (management vs employee), whether they are allocated into the CBT programme or not (control vs cbt), and scores on anxiety at both the start and the end of the study period.
Are students on our postgraduate courses shorter/taller than those on our undergraduate courses?
We can again use the data from the past surveys: https://uoepsy.github.io/data/surveydata_historical.csv.
“USMR” is our only postgraduate course.
(Why 97.5? and not 95? We want the middle 95%, and \(t\)-distributions are symmetric, so we want to split that 5% in half, so that 2.5% is on either side. We could have also used qt(0.025, df = 6), which will just give us the same number but negative: -2.4469119)↩︎