| variable | description |
|---|---|
| patient | A patient code in which the labels take the form <Therapist initials>_<group>_<patient number>. |
| visit_0 | Score on the GAD7 at baseline |
| visit_1 | GAD7 at 1 month assessment |
| visit_2 | GAD7 at 2 month assessment |
| visit_3 | GAD7 at 3 month assessment |
| visit_4 | GAD7 at 4 month assessment |
Week 4 Exercises: Nested and Crossed
Psychoeducation Treatment Effects
Data: gadeduc.csv
This is synthetic data from a randomised controlled trial, in which 30 therapists randomly assigned patients (each therapist saw between 4 and 30 patients) to a control or treatment group, and monitored their scores over time on a measure of generalised anxiety disorder (GAD7 - a 7 item questionnaire with 5 point likert scales).
The control group of patients received standard sessions offered by the therapists. For the treatment group, 10 mins of each sessions was replaced with a specific psychoeducational component, and patients were given relevant tasks to complete between each session. All patients had monthly therapy sessions. Generalised Anxiety Disorder was assessed at baseline and then every visit over 4 months of sessions (5 assessments in total).
The data are available at https://uoepsy.github.io/data/msmr_gadeduc.csv
You can find a data dictionary below:
Question 1
Uh-oh… these data aren’t in the same shape as the other datasets we’ve been giving you..
Can you get it into a format that is ready for modelling?
Hints
- It’s wide, and we want it long.
- Once it’s long. “visit_0”, “visit_1”,.. needs to become the numbers 0, 1, …
- One variable (
patient) contains lots of information that we want to separate out. There’s a handy function in the tidyverse calledseparate(), check out the help docs!
Question 2
Visualise the data. Does it look like the treatment had an effect?
Does it look like it worked for every therapist?
Hints
- remember,
stat_summary()is very useful for aggregating data inside a plot.
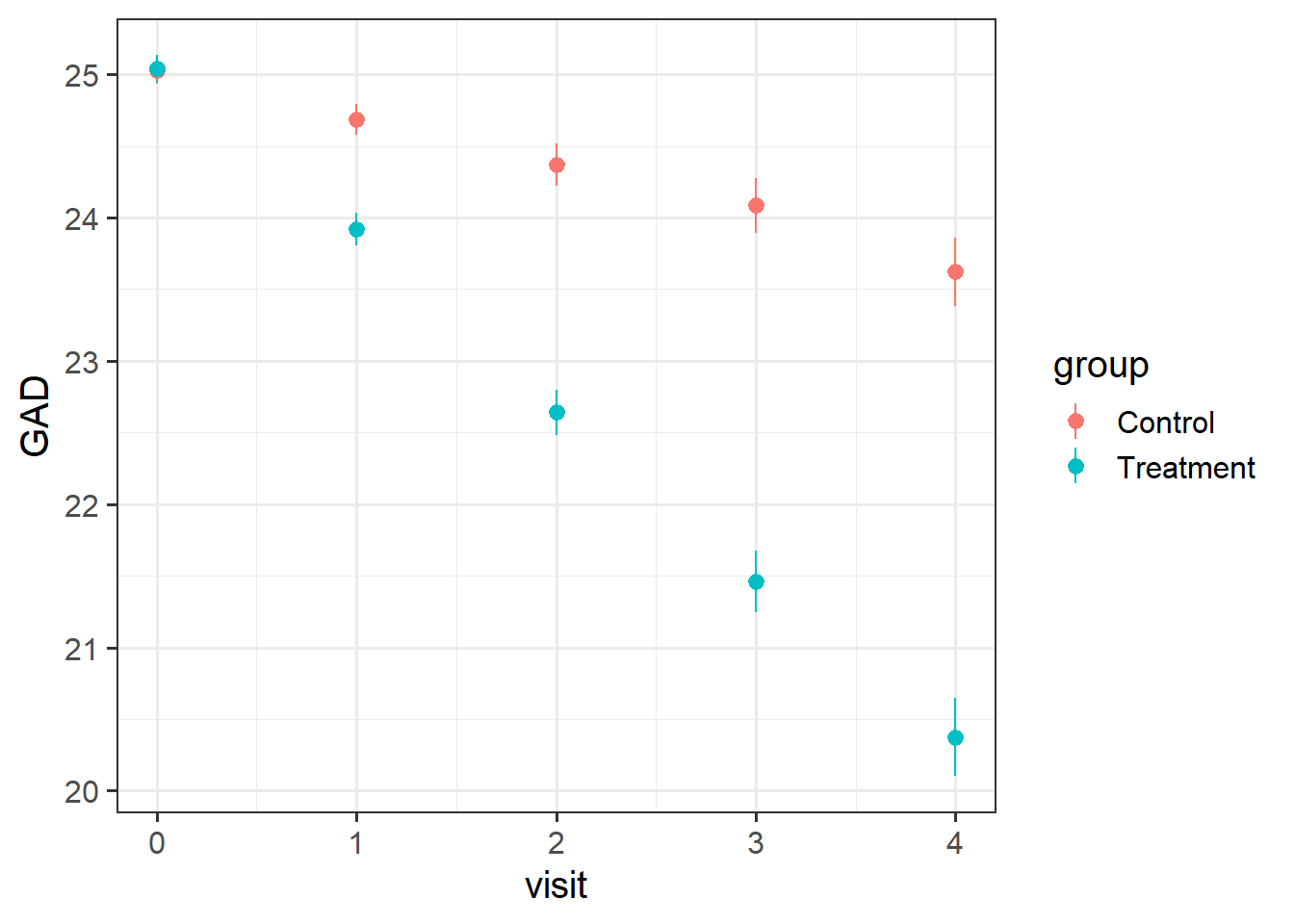
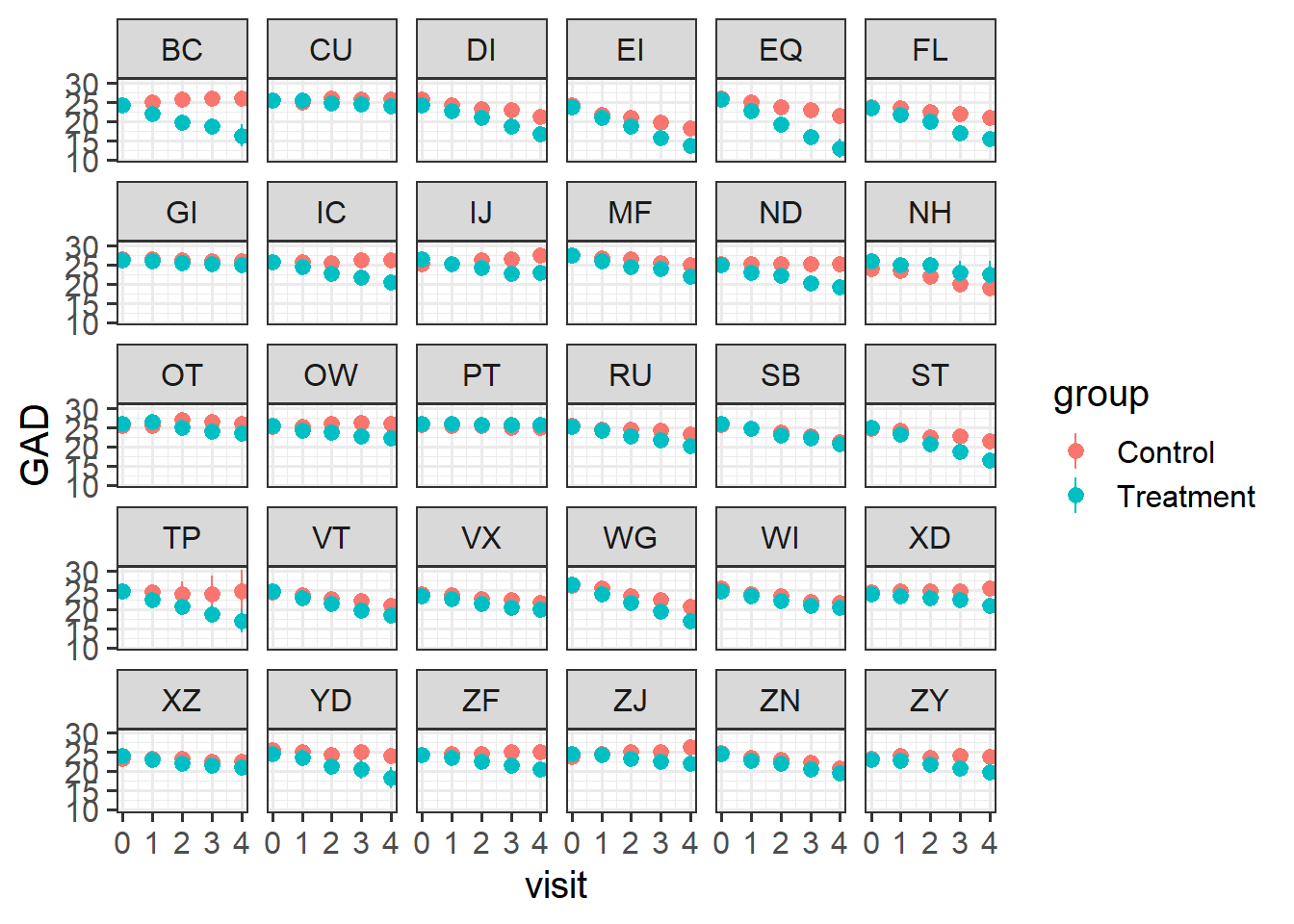
Question 3
Fit a model to test if the psychoeducational treatment is associated with greater improvement in anxiety over time.
Question 4
For each of the models below, what is wrong with the random effect structure?
modelA <- lmer(GAD ~ visit*group +
(1+visit*group|therapist)+
(1+visit|patient),
geduc_long)modelB <- lmer(GAD ~ visit*group +
(1+visit*group|therapist/patient),
geduc_long)
Question 5
Let’s suppose that I don’t want the psychoeducation treatment, I just want the standard therapy sessions that the ‘Control’ group received. Which therapist should I go to?
Hints
dotplot.ranef.mer() might help here!
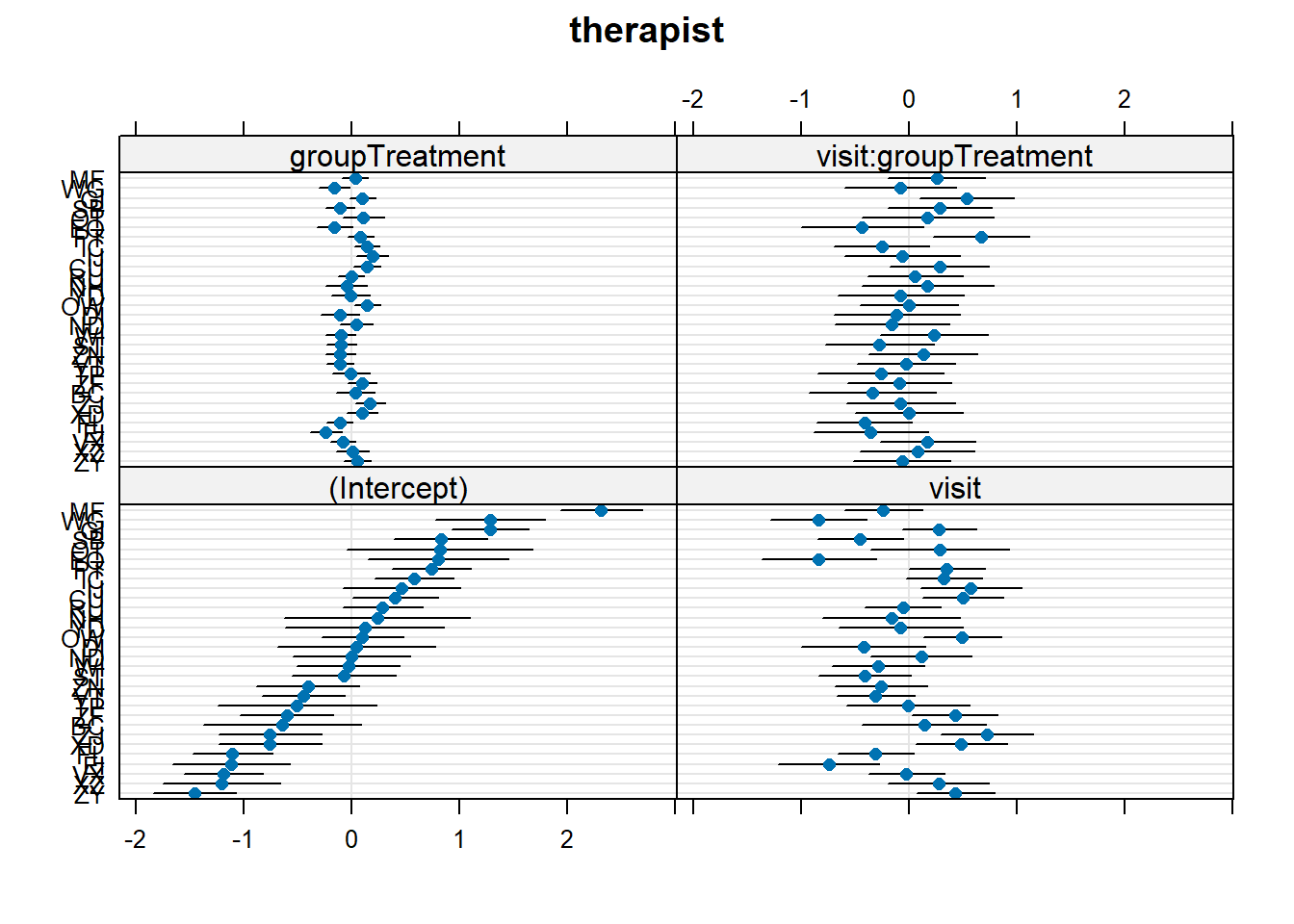
Question 6
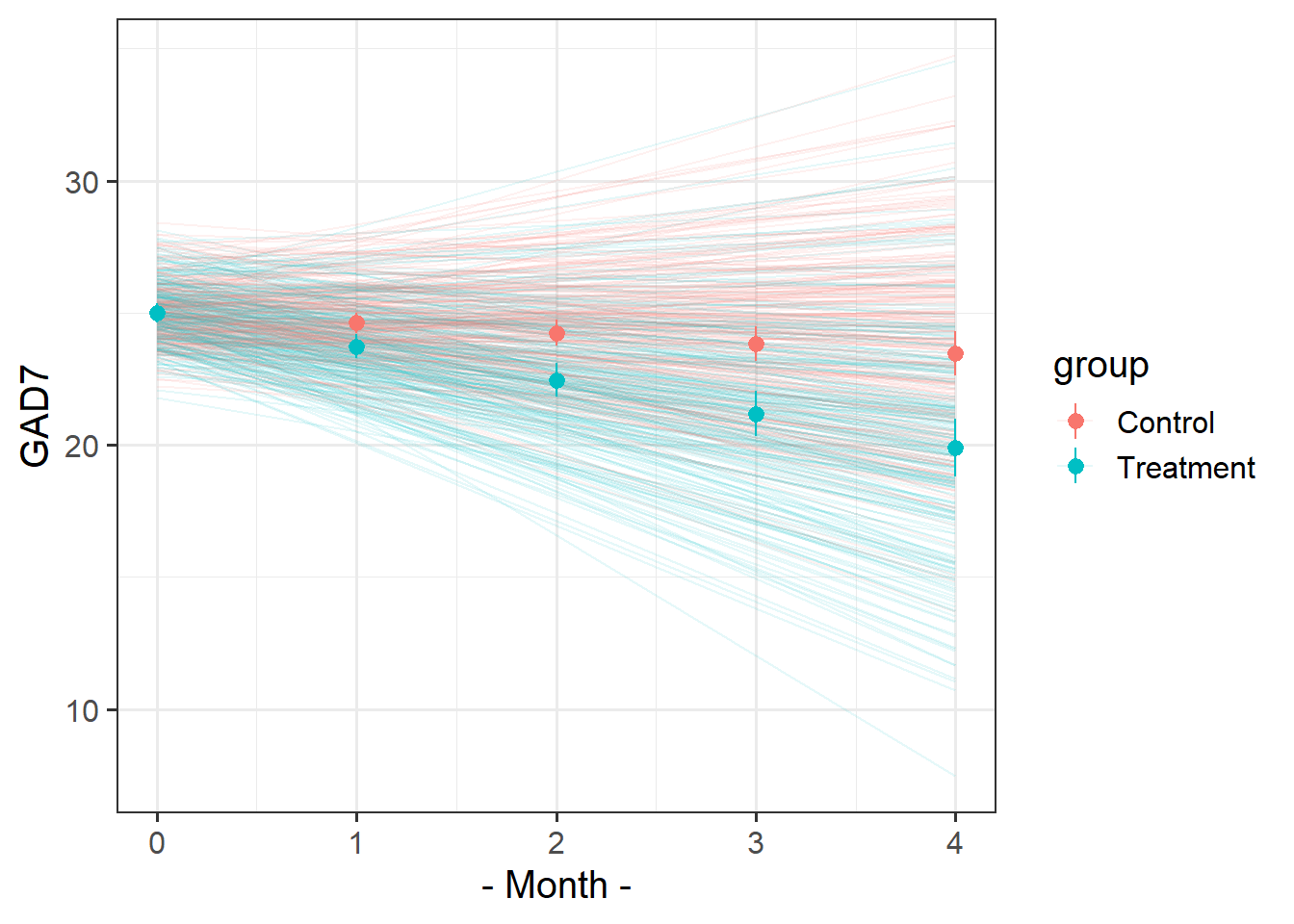
Recreate this plot.
The faint lines represent the model estimated lines for each patient. The points and ranges represent our fixed effect estimates and their uncertainty.
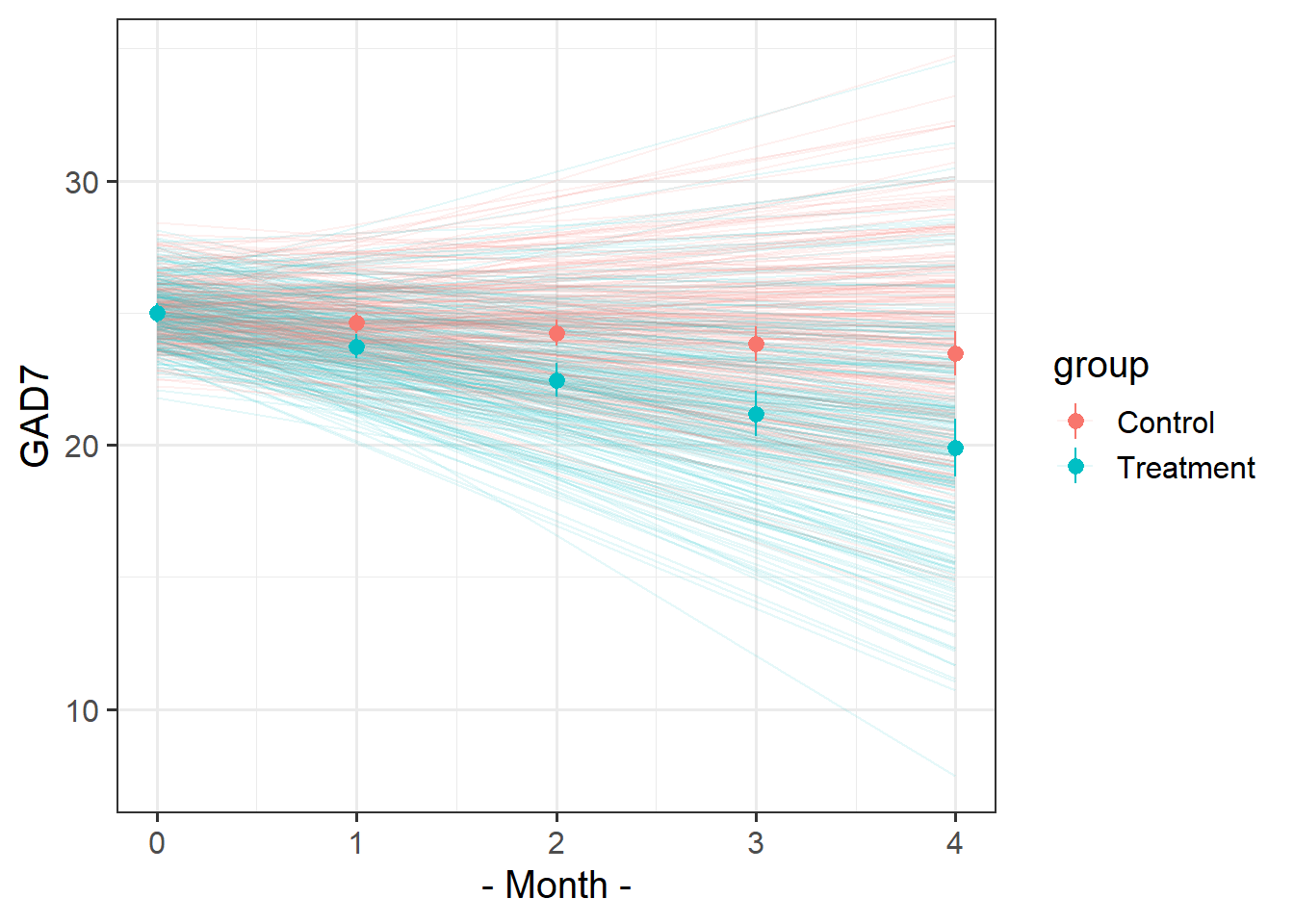
Hints
- you can get the patient-specific lines using
augment()from the broom.mixed package, and the fixed effects estimates using the effects package. - remember you can pull multiple datasets into ggplot:
ggplot(data = dataset1, aes(x=x,y=y)) +
geom_point() + # points from dataset1
geom_line(data = dataset2) # lines from dataset2
Test Enhanced Learning
Data: Test-enhanced learning
An experiment was run to conceptually replicate “test-enhanced learning” (Roediger & Karpicke, 2006): two groups of 25 participants were presented with material to learn. One group studied the material twice (StudyStudy), the other group studied the material once then did a test (StudyTest). Recall was tested immediately (one minute) after the learning session and one week later. The recall tests were composed of 175 items identified by a keyword (Test_word).
The critical (replication) prediction is that the StudyStudy group recall more items on the immediate test, but the StudyTest group will retain the material better and thus perform better on the 1-week follow-up test.
The following code loads the data into your R environment by creating a variable called tel:
load(url("https://uoepsy.github.io/data/testenhancedlearning.RData"))| variable | description |
|---|---|
| Subject_ID | Unique Participant Identifier |
| Group | Group denoting whether the participant studied the material twice (StudyStudy), or studied it once then did a test (StudyTest) |
| Delay | Time of recall test ('min' = Immediate, 'week' = One week later) |
| Test_word | Word being recalled (175 different test words) |
| Correct | Whether or not the word was correctly recalled |
| Rtime | Time to recall word (milliseconds) |
Question 7
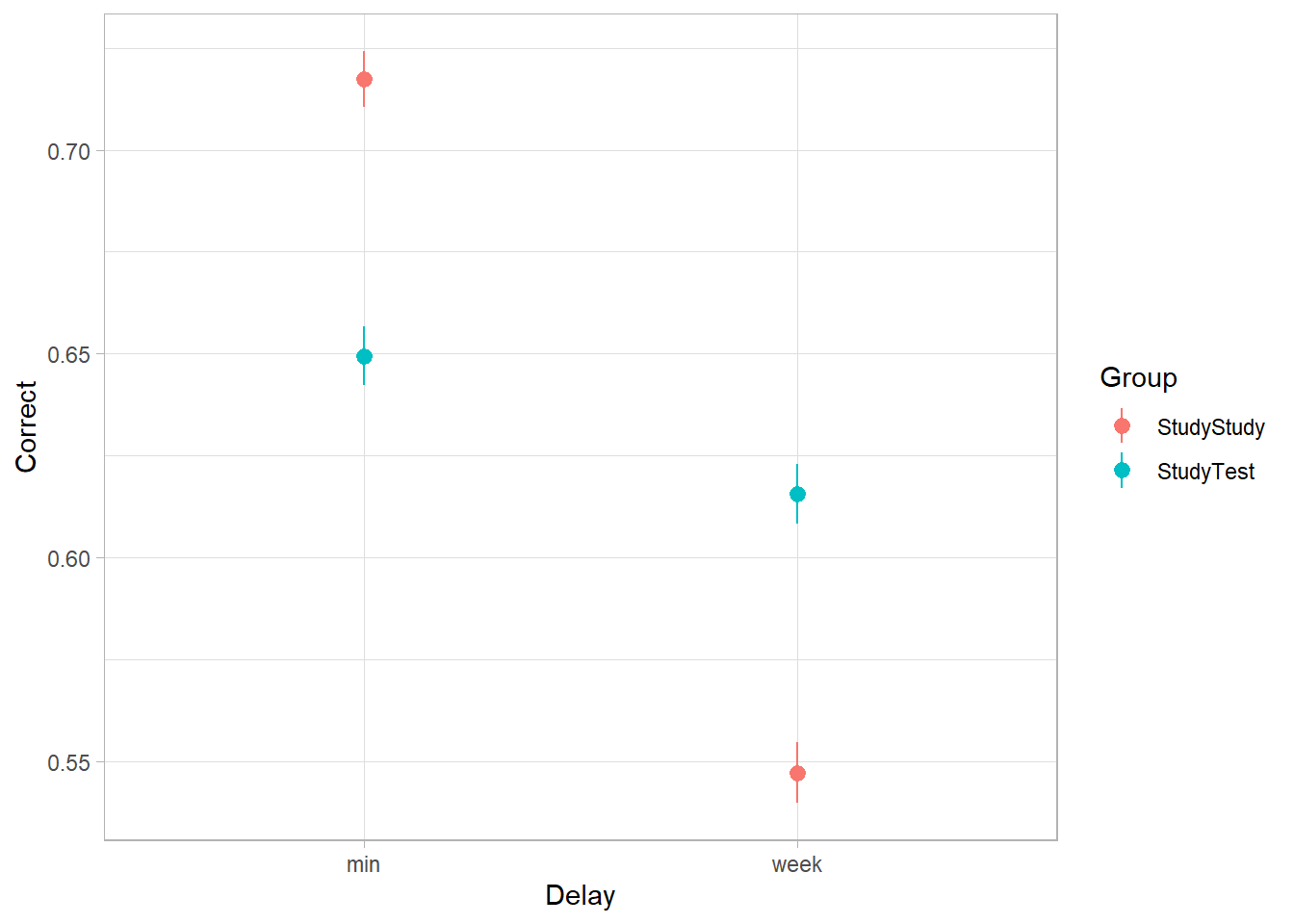
Load and plot the data. Does it look like the effect was replicated?
The critical (replication) prediction is that the
StudyStudygroup recall more items on the immediate test, but theStudyTestgroup will retain the material better and thus perform better on the 1-week follow-up test.
Hints
We can actually look at this from a couple of different angles. The most obvious option is to take successful learning as “correctly recalling” an item. This means we take the Correct variable as our outcome.
Note we also have Rtime - the “time-to-recall” of an item. This could also work as an outcome, but note that it also includes the time it took participants to provide an incorrect response too. If this was your own project, you may well want to provide analyses of Correct, and then also of the time-taken, but on the subset of correcty recalled items.
Question 8
Test the critical hypothesis using a mixed-effects model.
Fit the maximal random effect structure supported by the experimental design. Simplify the random effect structure until you reach a model that converges.
Note: Some of the models you attempt here might take time to fit. This is normal, and you can cancel the estimation at any time by pressing the escape key.
I suggest that you write your initial model, set it running, and then look at the first solution to see if it converged for me. You can assume that if it didn’t work for me, it also won’t work for you. I’ve shown the random effects for each model, in case it helps in deciding your next step.
Hints
What we’re aiming to do here is to follow Barr et al.’s advice of defining our maximal model and then removing only the terms to allow a non-singular fit.
- What kind of model will you use? What is our outcome? is it binary, or continuous?
- We can expect variability across subjects (some people are better at learning than others) and across items (some of the recall items are harder than others). How should this be represented in the random effects?
Question 9
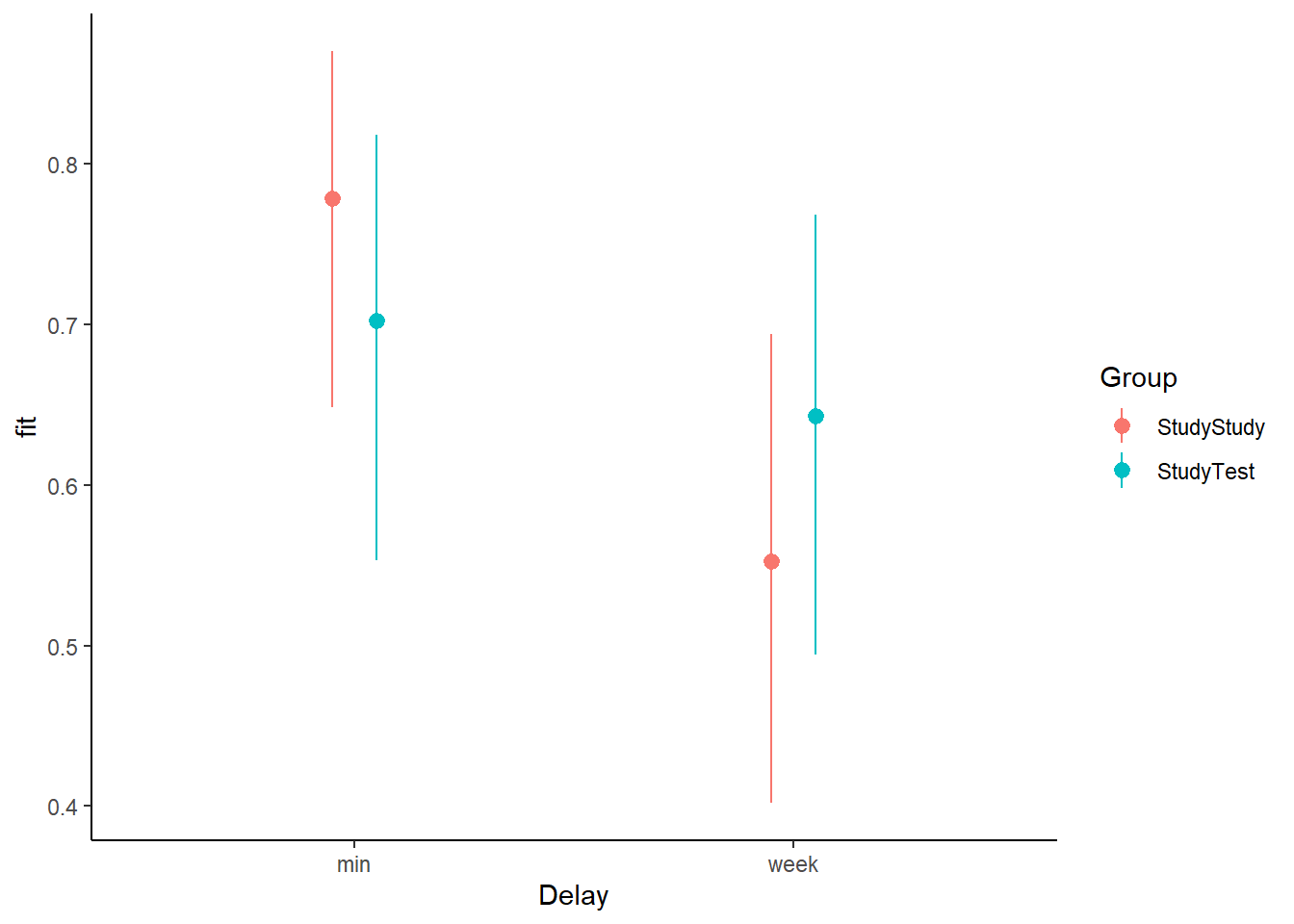
Create a plot of the predicted probabilities and uncertainty for each of the Delay * Group combinations.
Question 10
Here are odds ratios for our model:
Code
# cbind combines columns
cbind(
# the odds ratios:
OR = exp(fixef(mod4)),
# the CIs:
exp(confint(mod4, method="Wald", parm="beta_"))
) OR 2.5 % 97.5 %
(Intercept) 3.5155077 1.8444914 6.7003803
Delayweek 0.3510452 0.3075298 0.4007181
GroupStudyTest 0.6715269 0.2761216 1.6331515
Delayweek:GroupStudyTest 2.1734992 1.7894502 2.6399723What should we do with this information? How should we apply test-enhanced learning to learning R and statistics?
Vocab Development
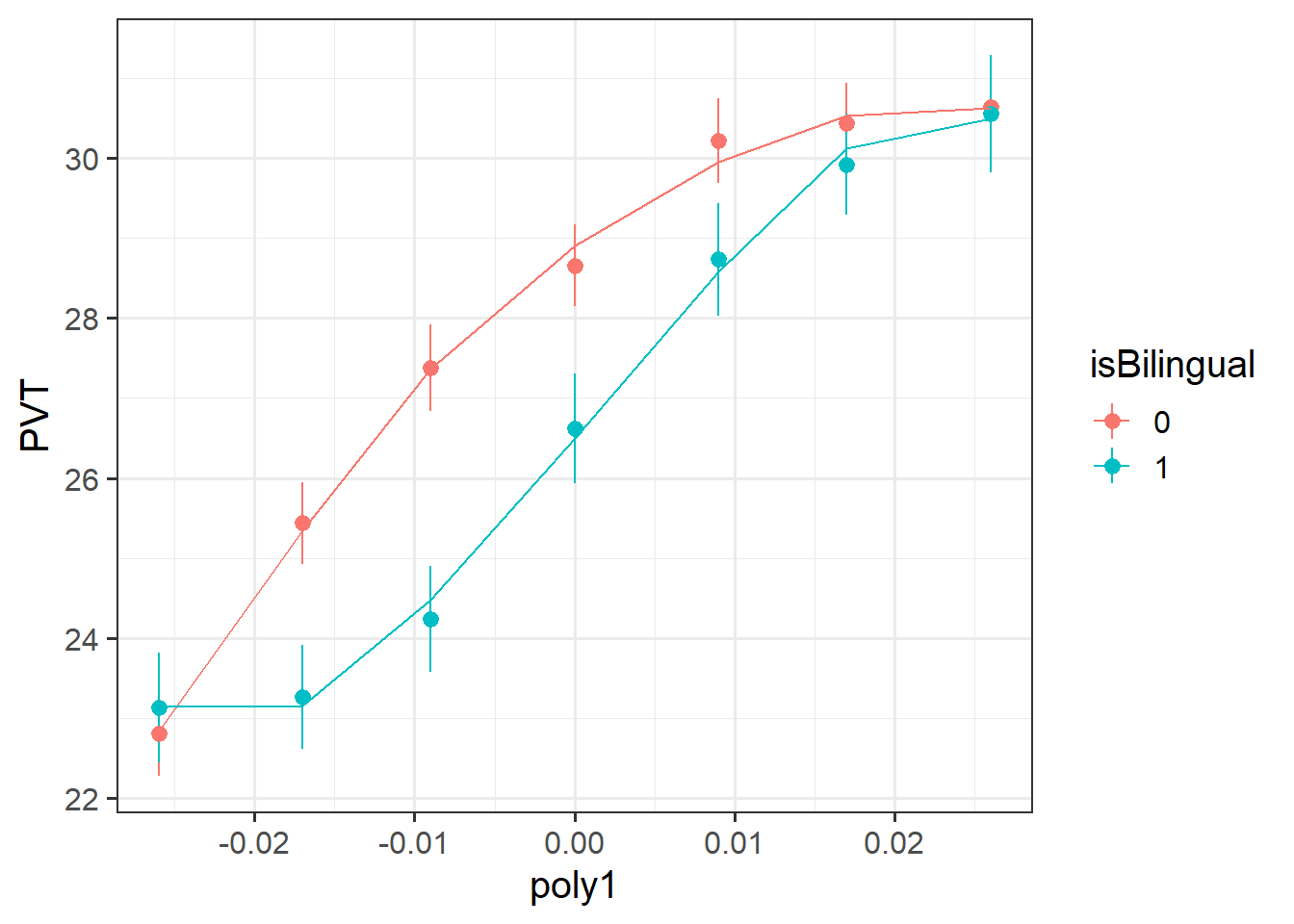
Data: pvt_bilingual.csv
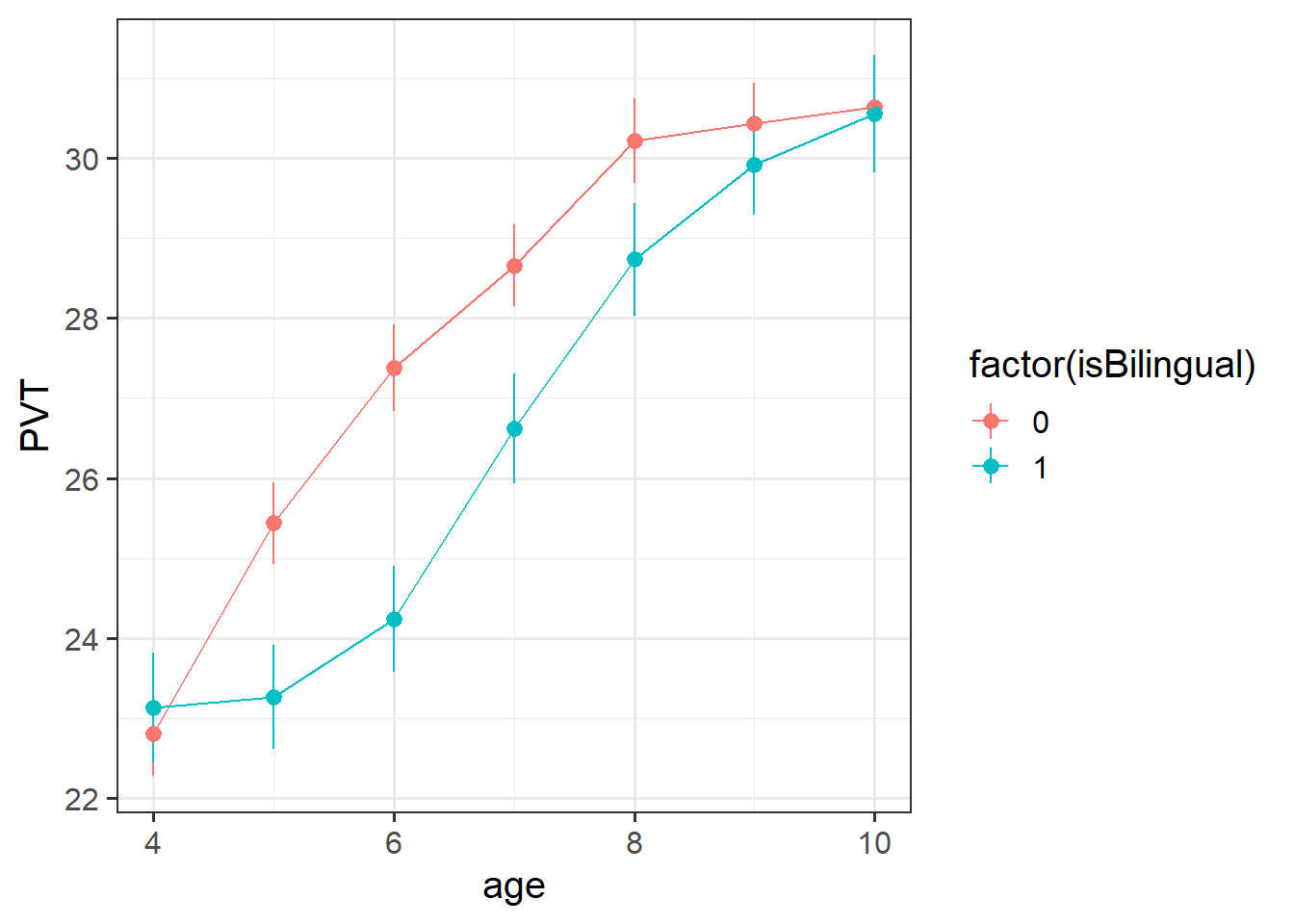
488 children from 30 schools were included in the study. Children were assessed on a yearly basis for 7 years throughout primary school on a measure of vocabulary administered in English, the Picture Vocab Test (PVT). 295 were monolingual English speakers, and 193 were bilingual (english + another language).
Previous research conducted on monolingual children has suggested that that scores on the PVT increase steadily up until the age of approximately 7 or 8 at which point they begin to plateau. The aim of the present study is to investigate differences in the development of vocabulary between monolingual and bilingual children.
The data are available at https://uoepsy.github.io/data/pvt_bilingual.csv.
| variable | description |
|---|---|
| child | Child's name |
| school | School Identifier |
| isBilingual | Binary variable indicating whether the child is monolingual (0) or bilingual (1) |
| age | Age (years) |
| PVT | Score on the Picture Vocab Test (PVT). Scores range 0 to 60 |
Question 11 - Less Guided
Conduct an analysis to estimate the differences in trajectories of vocabulary development between children attending bilingual schools vs those attending monolingual schools.
Write up your results.
Hints
- make things factors
- always plot your data!
- read the study background: “increase steadily … before beginning to plateau” describes a curve!
- plotting the data can give an initial sense of the possible need for higher order polynomials.
Footnotes
if it does, head back to where we learned about interactions in the single level regressions
lm(). It’s just the same here.↩︎