dap2 <- read_csv("https://uoepsy.github.io/data/dapr2_2122_report1.csv")Centering in MLM | Logistic MLM
Preliminaries
- Create a new RMarkdown document or R script (whichever you like) for this week.
Centering & Scaling in LM
We have some data from a study investigating how perceived persuasiveness of a speaker is influenced by the rate at which they speak (you may remember this from the first report in DAPR2 last year!).
We can fit a simple linear regression (one predictor) to evaluate how speech rate (variable sp_rate in the dataset) influences perceived persuasiveness (variable persuasive in the dataset). There are various ways in which we can transform the predictor variable sp_rate, which in turn can alter the interpretation of some of our estimates:
Raw X
m1 <- lm(persuasive ~ sp_rate, data = dap2)
summary(m1)$coefficients Estimate Std. Error t value Pr(>|t|)
(Intercept) 55.532060 6.4016670 8.674625 6.848945e-15
sp_rate -0.190987 0.4497113 -0.424688 6.716809e-01The intercept and the coefficient for neuroticism are interpreted as:
(Intercept): A audio clip of someone speaking at zero phones per second is estimated as having an average persuasive rating of 55.53.
sp_rate: For every increase of one phone per second, perceived persuasiveness is estimated to decrease by -0.19.
Mean-Centered X
We can mean center our predictor and fit the model again:
dap2 <- dap2 %>% mutate(sp_rate_mc = sp_rate - mean(sp_rate))
m2 <- lm(persuasive ~ sp_rate_mc, data = dap2)
summary(m2)$coefficients Estimate Std. Error t value Pr(>|t|)
(Intercept) 52.874667 1.3519418 39.110165 6.429541e-80
sp_rate_mc -0.190987 0.4497113 -0.424688 6.716809e-01(Intercept): A audio clip of someone speaking at the mean phones per second is estimated as having an average persuasive rating of 52.87.
sp_rate_mc: For every increase of one phone per second, perceived persuasiveness is estimated to decrease by -0.19.
Standardised X
We can standardise our predictor and fit the model yet again:
dap2 <- dap2 %>% mutate(sp_rate_z = scale(sp_rate))
m3 <- lm(persuasive ~ sp_rate_z, data = dap2)
summary(m3)$coefficients Estimate Std. Error t value Pr(>|t|)
(Intercept) 52.874667 1.351942 39.110165 6.429541e-80
sp_rate_z -0.576077 1.356471 -0.424688 6.716809e-01(Intercept): A audio clip of someone speaking at the mean phones per second is estimated as having an average persuasive rating of 52.87.
sp_rate_z: For every increase of one standard deviation in phones per second, perceived persuasiveness is estimated to decrease by -0.58.
Remember that the scale(sp_rate) is subtracting the mean from each value, then dividing those by the standard deviation. The standard deviation of dap2$sp_rate is:
sd(dap2$sp_rate)[1] 3.016315so in our variable dap2$sp_rate_z, a change of 3.02 gets scaled to be a change of 1 (because we are dividing by sd(dap2$sp_rate)).
coef(m1)[2] * sd(dap2$sp_rate) sp_rate
-0.576077 coef(m3)[2]sp_rate_z
-0.576077 Note that these models are identical. When we conduct a model comparison between the 3 models, the residual sums of squares is identical for all models:
anova(m1,m2,m3)Analysis of Variance Table
Model 1: persuasive ~ sp_rate
Model 2: persuasive ~ sp_rate_mc
Model 3: persuasive ~ sp_rate_z
Res.Df RSS Df Sum of Sq F Pr(>F)
1 148 40576
2 148 40576 0 0
3 148 40576 0 0 What changes when you center or scale a predictor in a standard regression model (one fitted with lm())?
- The variance explained by the predictor remains exactly the same
- The intercept will change to be the estimated mean outcome where that predictor is “0”. Scaling and centering changes what “0” represents, thereby changing this estimate (the significance test will therefore also change because the intercept now has a different meaning)
- The slope of the predictor will change according to any scaling (e.g. if you divide your predictor by 10, the slope will multiply by 10).
- The test of the slope of the predictor remains exactly the same.
Exercises: Centering in the MLM
Data: Hangry
The study is interested in evaluating whether hunger influences peoples’ levels of irritability (i.e., “the hangry hypothesis”), and whether this is different for people following a diet that includes fasting. 81 participants were recruited into the study. Once a week for 5 consecutive weeks, participants were asked to complete two questionnaires, one assessing their level of hunger, and one assessing their level of irritability. The time and day at which participants were assessed was at a randomly chosen hour between 7am and 7pm each week. 46 of the participants were following a five-two diet (five days of normal eating, 2 days of fasting), and the remaining 35 were following no specific diet.
The data are available at: https://uoepsy.github.io/data/hangry.csv.
| variable | description |
|---|---|
| q_irritability | Score on irritability questionnaire (0:100) |
| q_hunger | Score on hunger questionnaire (0:100) |
| ppt | Participant |
| fivetwo | Whether the participant follows the five-two diet |
Question 1
Read carefully the description of the study above, and try to write out (in lmer syntax) an appropriate model to test the research aims.
e.g.:
outcome ~ explanatory variables + (???? | grouping)Try to think about the maximal random effect structure (i.e. everything that can vary by-grouping is estimated as doing so).
To help you think through the steps to get from a description of a research study to a model specification, think about your answers to the following questions.
Q: What is our outcome variable?
Hint: The research is looking at how hunger influences irritability, and whether this is different for people on the fivetwo diet.
Q: What are our explanatory variables?
Hint: The research is looking at how hunger influences irritability, and whether this is different for people on the fivetwo diet.
Q: Is there any grouping (or “clustering”) of our data that we consider to be a random sample? If so, what are the groups?
Hint: We can split our data in to groups of each participant. We can also split it into groups of each diet. Which of these groups have we randomly sampled? Do we have a random sample of participants? Do we have a random sample of diets? Another way to think of this is “if i repeated the experiment, what these groups be different?”
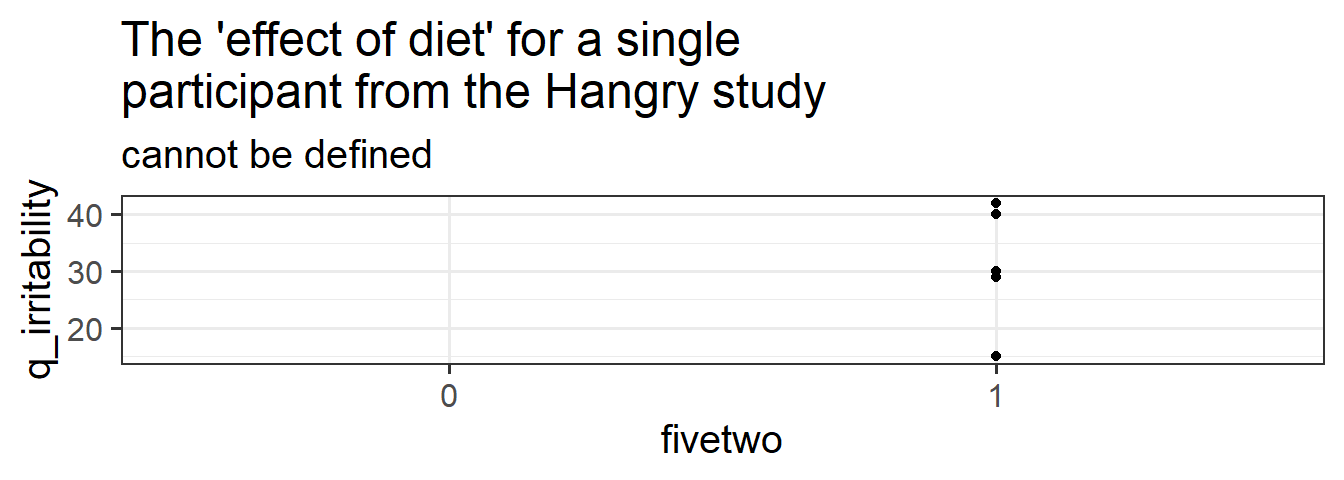
Total, Within, Between
Recall our research aim:
… whether hunger influences peoples’ levels of irritability (i.e., “the hangry hypothesis”), and whether this is different for people following a diet that includes fasting.
Forgetting about any differences due to diet, let’s just think about the relationship between irritability and hunger. How should we interpret this research aim?
Was it:
- “Are people more irritable if they are, on average, more hungry than other people?”
- “Are people more irritable if they are, for them, more hungry than they usually are?”
- Some combination of both a. and b.
This is just one demonstration of how the statistical methods we use can constitute an integral part of our development of a research project, and part of the reason that data analysis for scientific cannot be so easily outsourced after designing the study and collecting the data.
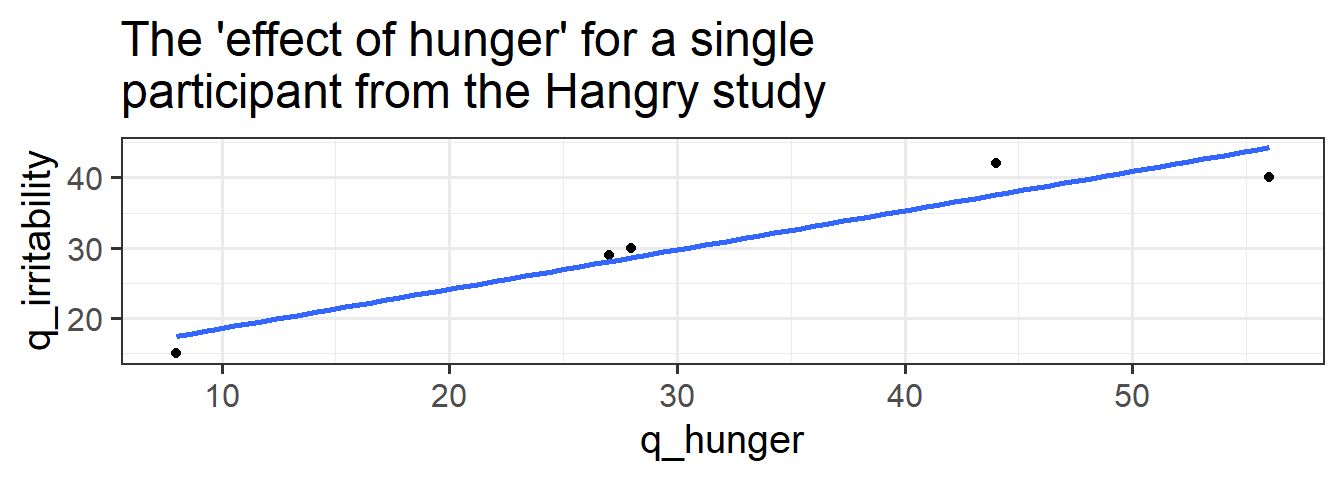
As our data currently is currently stored, the relationship between irritability and the raw scores on the hunger questionnaire q_hunger represents some ‘total effect’ of hunger on irritability. This is a bit like interpretation c. above - it’s a composite of both the ‘within’ ( b. ) and ‘between’ ( a. ) effects. The problem with this is that the ‘total effect’ isn’t necessarily all that meaningful. It may tell us that ‘being higher on the hunger questionnaire is associated with being more irritable’, but how can we apply this information? It is not specifically about the comparison between hungry people and less hungry people, and nor is it about how person i changes when they are more hungry than usual. It is both these things smushed together.
To disaggregate the ‘within’ and ‘between’ effects of hunger on irritability, we can group-mean center. For ‘between’, we are interested in how irritability is related to the average hunger levels of a participant, and for ‘within’, we are asking how irritability is related to a participants’ relative levels of hunger (i.e., how far above/below their average hunger level they are.).
Question 2
Add to the data these two columns:
- a column which contains the average hungriness score for each participant.
- a column which contains the deviation from each person’s hunger score to that person’s average hunger score.
Hint: You’ll find group_by() %>% mutate() very useful here.
Question 3
For each of the new variables you just added, plot the irritability scores against those variables.
- Does it look like hungry people are more irritable than less hungry people?
- Does it look like when people are more hungry than normal, they are more irritable?
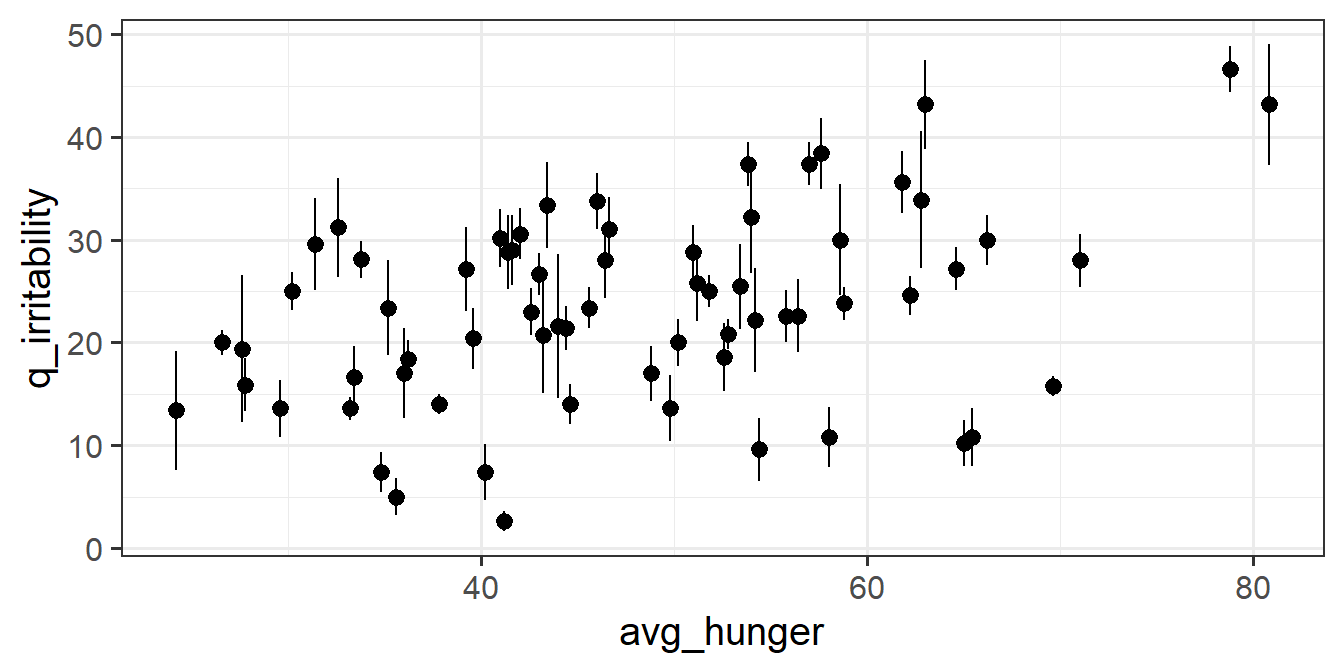
Question 4
We have taken the raw hunger scores and separated them into two parts (raw hunger scores = participants’ average hunger score + observation level deviations from those averages), that represent two different aspects of the relationship between hunger and irritability.
Adjust your model specification to include these two separate variables as predictors, instead of the raw hunger scores.
Hints:
hunger * dietcould be replaced by(hunger1 + hunger2) * diet, thereby allowing each aspect of hunger to interact with diet.- We can only put one of these variables in the random effects
(1 + hunger | participant). Recall that above we discussed how we cannot have(diet | participant), because “an effect of diet” makes no sense for a single participant (they are either on the diet or they are not, so there is no ‘effect’). Similarly, each participant has only one value for their average hungriness.
Question 5
Hopefully, you have fitted a model similar to the below:
hangrywb <- lmer(q_irritability ~ (avg_hunger + hunger_gc) * fivetwo +
(1 + hunger_gc | ppt), data = hangry,
control = lmerControl(optimizer="bobyqa"))Below, we have obtained p-values using the Satterthwaite Approximation of \(df\) for the test of whether the fixed effects are zero, so we can see the significance of each estimate.
Provide an answer for each of these questions:
- For those following no diet, is there evidence to suggest that people who are on average more hungry are more irritable?
- Is there evidence to suggest that this is different for those following the five-two diet? In what way?
- Do people following no diet tend to be more irritable when they are more hungry than they usually are?
- Is there evidence to suggest that this is different for those following the five-two diet? In what way?
- (Trickier:) What does the
fivetwocoefficient represent?
| term | Estimate | Std. Error | df | t value | Pr(>|t|) |
|---|---|---|---|---|---|
| (Intercept) | 17.131 | 5.15 | 77 | 3.33 | 0.0013 |
| avg_hunger | 0.004 | 0.11 | 77 | 0.04 | 0.9708 |
| hunger_gc | 0.186 | 0.08 | 65.4 | 2.46 | 0.0167 |
| fivetwo1 | -10.855 | 6.54 | 77 | -1.66 | 0.1008 |
| avg_hunger:fivetwo1 | 0.466 | 0.13 | 77 | 3.49 | <0.001 |
| hunger_gc:fivetwo1 | 0.381 | 0.1 | 68.5 | 3.76 | <0.001 |
Question 6
Construct two plots showing the two model estimated interactions. Think about your answers to the previous question, and check that they match with what you are seeing in the plots (do not underestimate the utility of this activity for helping understanding!).
Hint: This isn’t as difficult as it sounds. the sjPlot package can do it in one line of code!
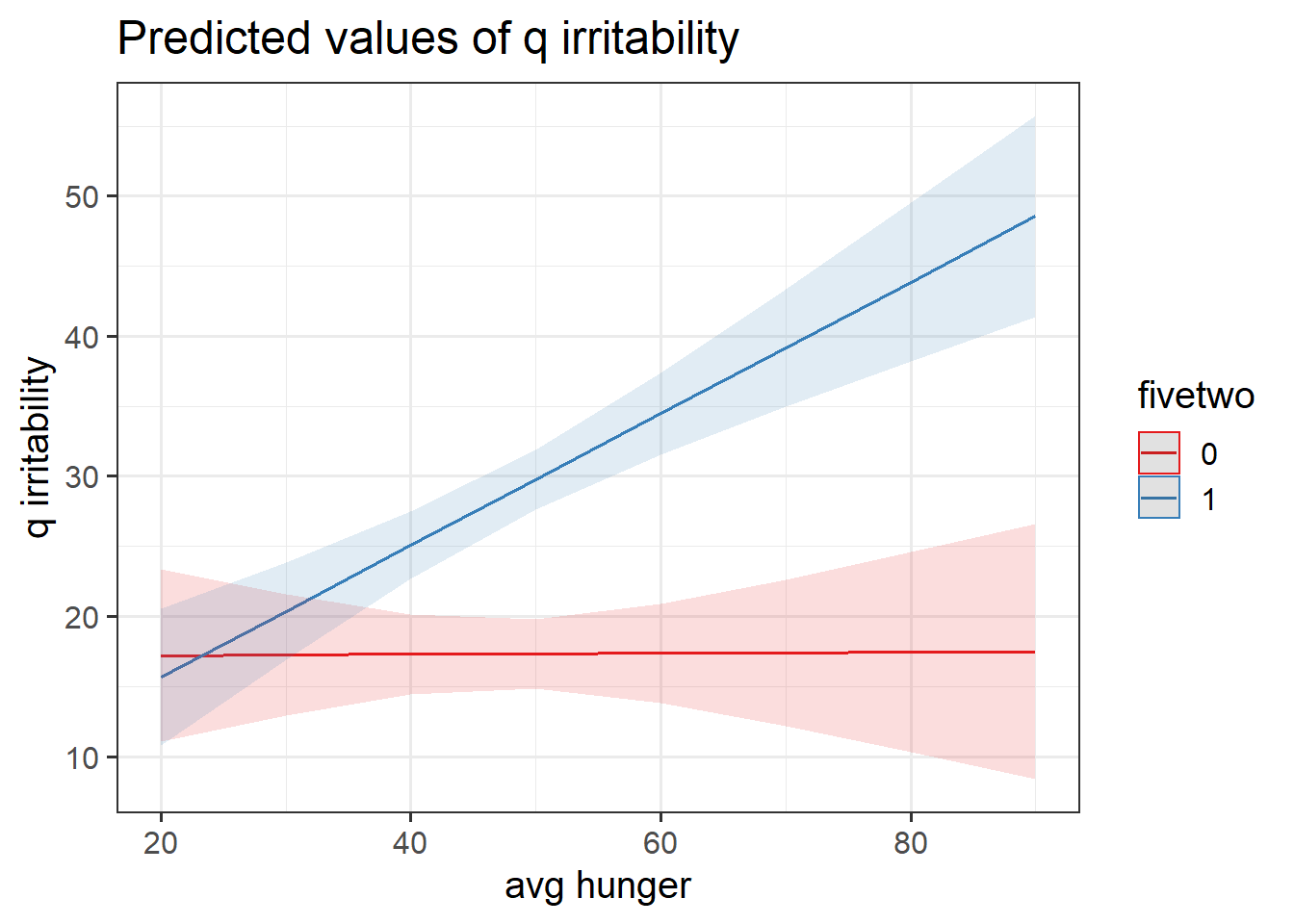
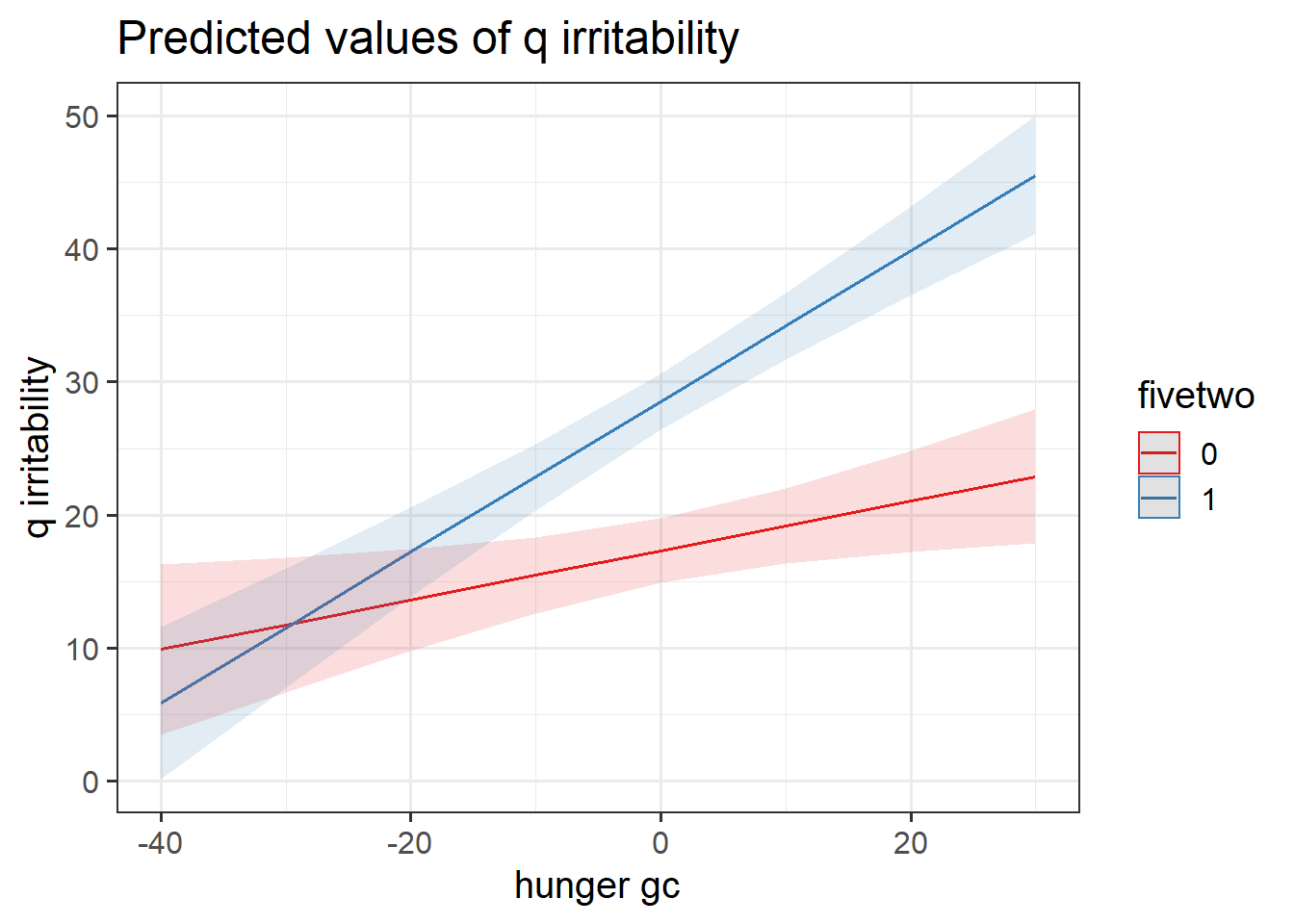
Question 7
Load the lmerTest package and fit the model again. Take a look at the summary - you should now have the \(df\), \(t\)-value, and \(p\)-value for each estimate.
Write-up the results.
Other within-group transformations
As well as within-group mean centering a predictor (like we have done above). There are quite a few similar things we can do, for which the logic is the same.
For instance, we can within-group standardise a predictor. This would disagregate within and between effects, but interpretation would of the within effect would be the estimated change in \(y\) associated with being 1 standard deviation higher in \(x\) for that group.
We can also do within-group transformations on our outcome variable. This allows to address questions such as:
“Are people more irritable than they usually are (\(y\) is group-mean centered) if they are, for them, more hungry than they usually are (\(x\) is group-mean centered)?”
Optional Exercises: Logistic MLM
Don’t forget to look back at other materials!
Back in DAPR2, we introduced logistic regression in semester 2, week 8. The lab contained some simulated data based on a hypothetical study about inattentional blindness. That content will provide a lot of the groundwork for this week, so we recommend revisiting it if you feel like it might be useful.
lmer() >> glmer()
Remember how we simply used glm() and could specify the family = "binomial" in order to fit a logistic regression? Well it’s much the same thing for multi-level models!
- Gaussian model:
lmer(y ~ x1 + x2 + (1 | g), data = data)
- Binomial model:
glmer(y ~ x1 + x2 + (1 | g), data = data, family = binomial(link='logit'))- or just
glmer(y ~ x1 + x2 + (1 | g), data = data, family = "binomial") - or
glmer(y ~ x1 + x2 + (1 | g), data = data, family = binomial)
- or just
Memory Recall & Finger Tapping
Research Question: After accounting for effects of sentence length, does the rhythmic tapping of fingers aid memory recall?
Researchers recruited 40 participants. Each participant was tasked with studying and then recalling 10 randomly generated sentences between 1 and 14 words long. For 5 of these sentences, participants were asked to tap their fingers along with speaking the sentence in both the study period and in the recall period. For the remaining 5 sentences, participants were asked to sit still.
The data are available at https://uoepsy.github.io/data/memorytap.csv, and contains information on the length (in words) of each sentence, the condition (static vs tapping) under which it was studied and recalled, and whether the participant was correct in recalling it.
| variable | description |
|---|---|
| ppt | Participant Identifier (n=40) |
| slength | Number of words in sentence |
| condition | Condition under which sentence is studied and recalled ('static' = sitting still, 'tap' = tapping fingers along to sentence) |
| correct | Whether or not the sentence was correctly recalled |
Question 8 (Optional)
Research Question: After accounting for effects of sentence length, does the rhythmic tapping of fingers aid memory recall?
Fit an appropriate model to answer the research question.
Hint:
- our outcome is conceptually ‘memory recall’, and it’s been measured by “Whether or not a sentence was correctly recalled”. This is a binary variable.
- we have multiple observations for each ?????
This will define our( | ??? )bit
Take some time to remind yourself from DAPR2 of the interpretation of logistic regression coefficients.
In family = binomial(link='logit'), we are modelling the log-odds. We can obtain estimates on this scale using:
fixef(model)summary(model)$coefficientstidy(model)from broom.mixed
- (there are probably more ways, but I can’t think of them right now!)
We can use exp(), to get these back into odds and odds ratios.
Question 9 (Optional)
Interpret each of the fixed effect estimates from your model.
Question 10 (Optional)
Checking the assumptions in non-gaussian models in general (i.e. those where we set the family to some other error distribution) can be a bit tricky, and this is especially true for multilevel models.
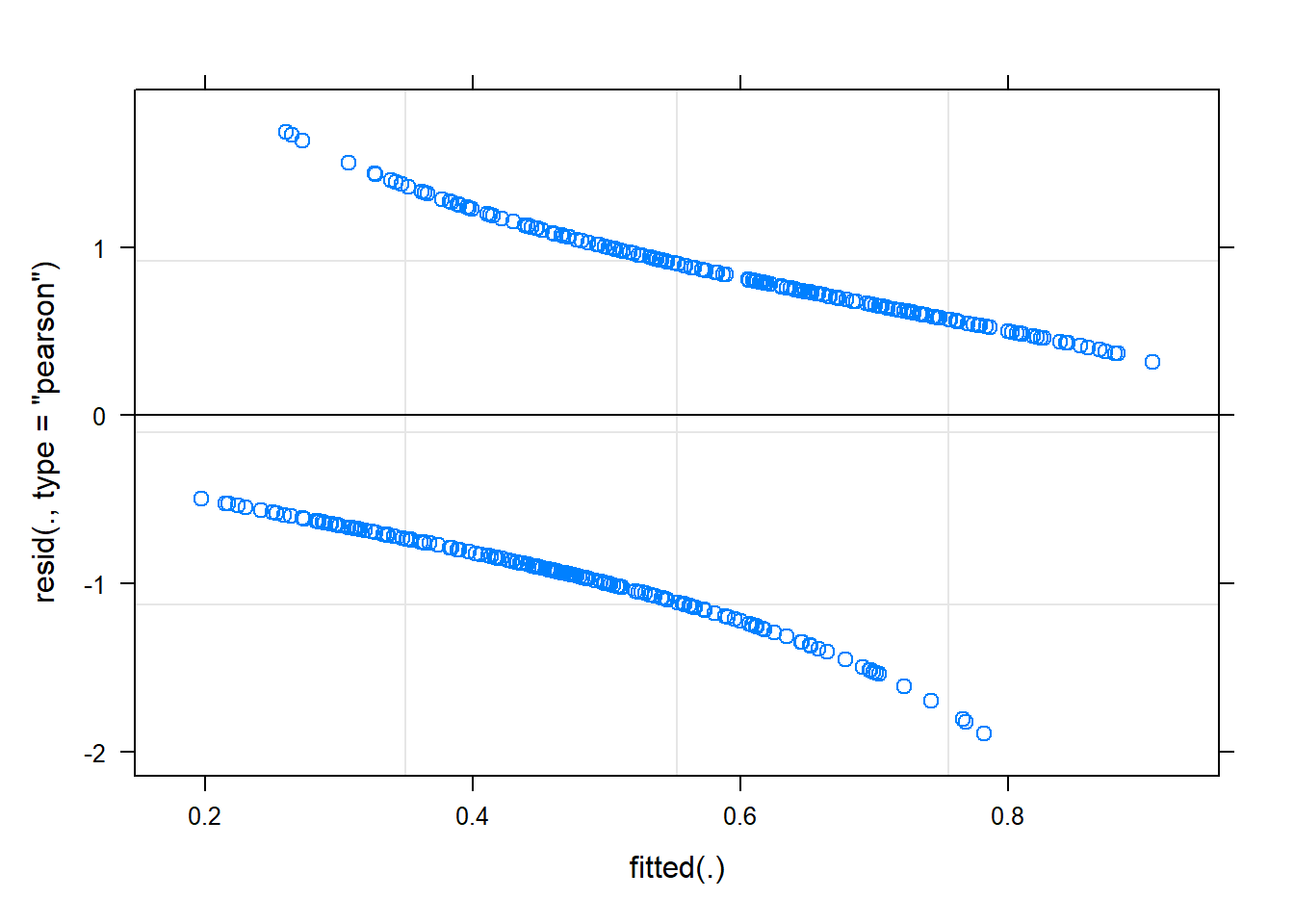
For the logistic MLM, the standard assumptions of normality etc for our Level 1 residuals residuals(model) do not hold. However, it is still useful to quickly plot the residuals and check that \(|residuals|\leq 2\) (or \(|residuals|\leq 3\) if you’re more relaxed). We don’t need to worry too much about the pattern though.
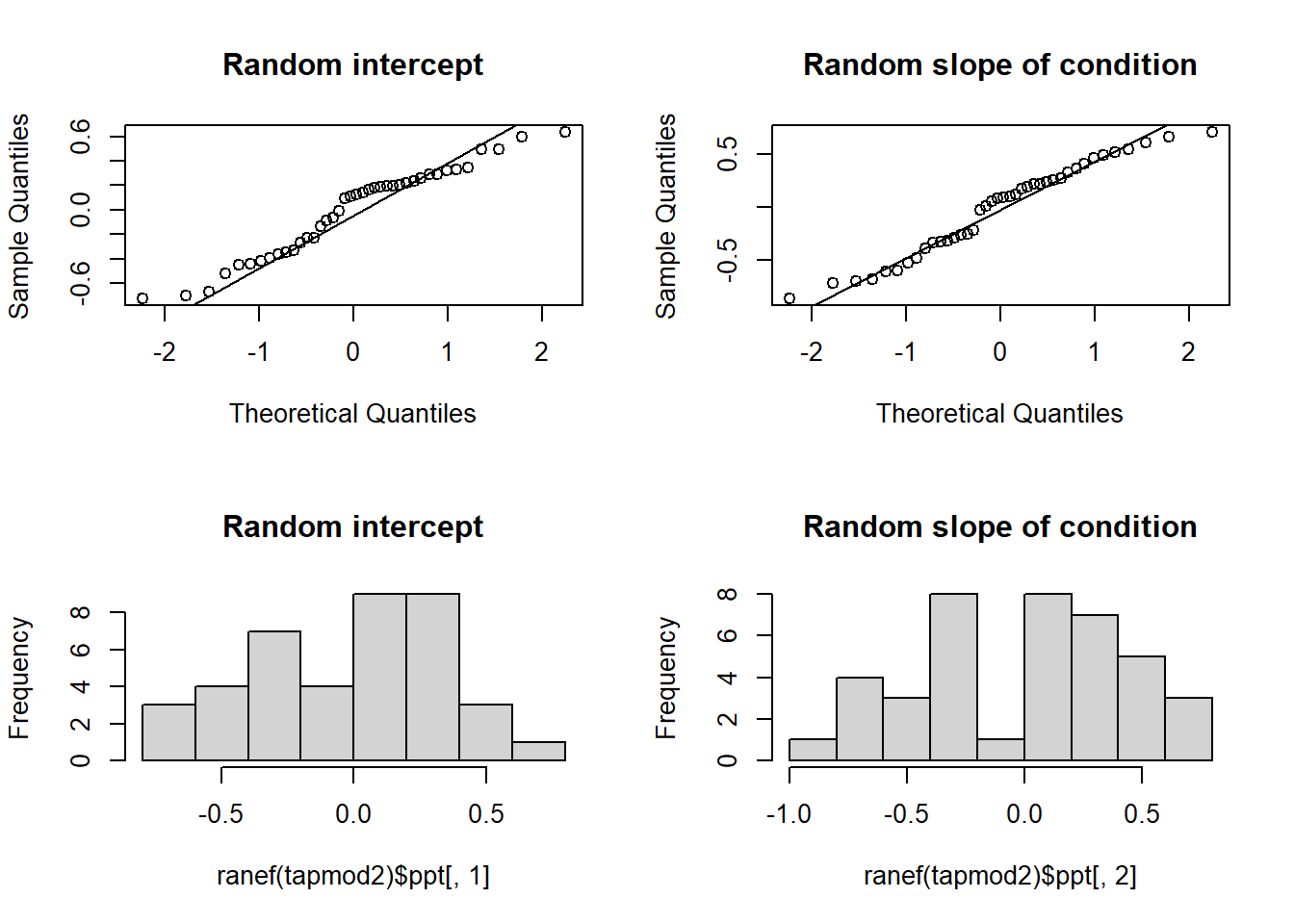
While we’re more relaxed about Level 1 residuals, we do still want our random effects ranef(model) to look fairly normally distributed.
- Plot the level 1 residuals and check whether any are greater than 3 in magnitude
- Plot the random effects (the level 2 residuals) and assess the normality.
for beyond DAPR3
- The HLMdiag package doesn’t support diagnosing influential points/clusters for
glmer, but there is a package called influence.me which might help: https://journal.r-project.org/archive/2012/RJ-2012-011/RJ-2012-011.pdf - There are packages which aim to create more interpretable residual plots for these models via simulation, such as the DHARMa package: https://cran.r-project.org/web/packages/DHARMa/vignettes/DHARMa.html