# A tibble: 2 × 7
Variable M SD Min Med Max NMiss
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <int>
1 age -9.49 57.5 -99 24 32 0
2 read_score NA NA NA NA NA 10
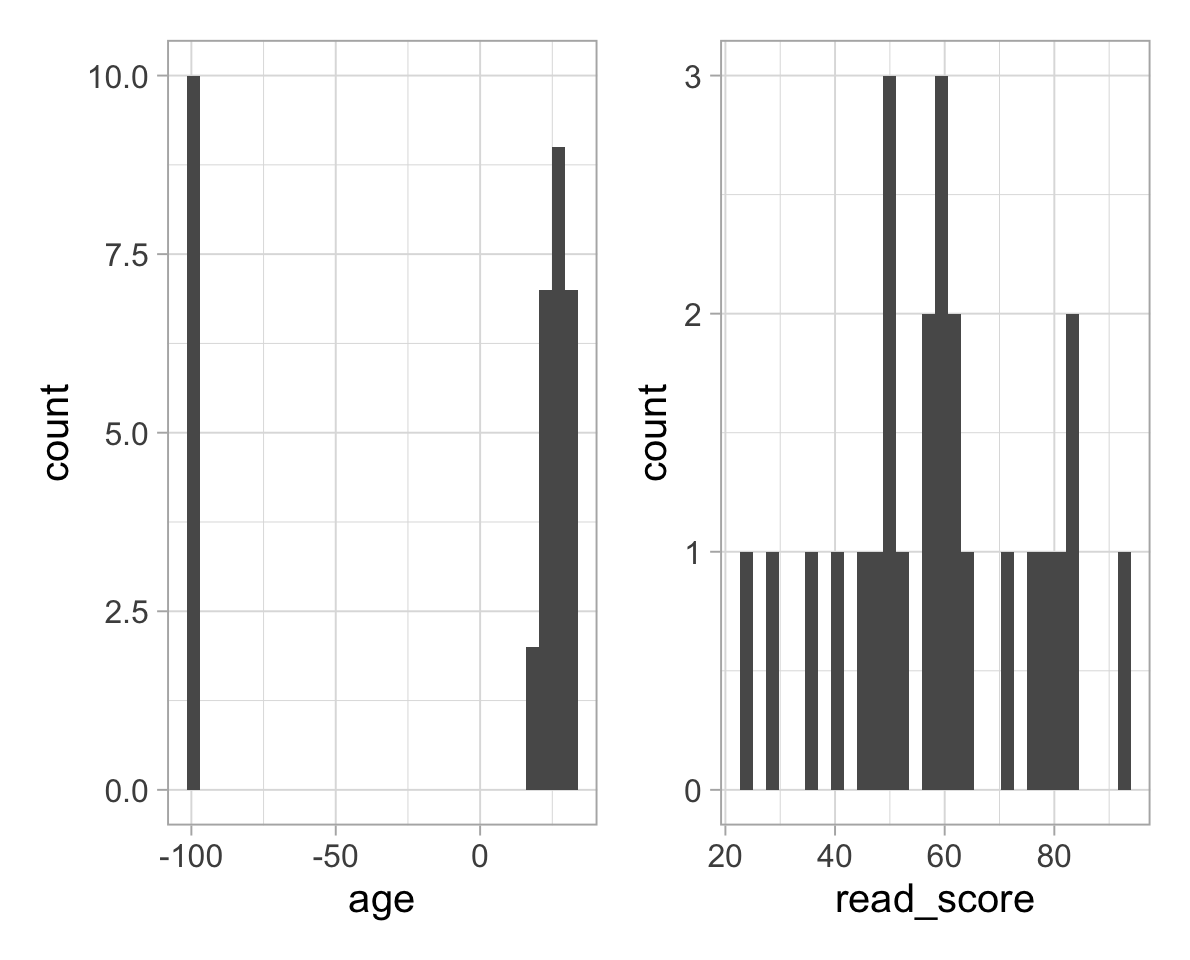
Question 3. What do you notice? Are there any issues with the data that need fixing? If yes, make appropriate changes to the data to fix those issues.
It looks like some students had their age stored as “-99”. This is an impossible value for age, and it was used by those entering the data as a missing value; i.e. when a student preferred to not disclose that information. The values “-99” should be replaced to be NAs.
The reading scores for some students were also missing but, if you look at the CSV file itself you will see that those were stored as spaces rather than -99s. This is in the CSV file, and not the object created into R when you read the CSV file data into R.
However, R is smart enough that when you read CSV data into R and there are spaces, those are interpreted as missing values and converted to NAs automatically.
If you used na.omit(students) or drop_na(), you would remove students having NAs also for age. However, students may not have provided their age, but we can have their reading score, so if we were to do this, we would throw away available data!
Question 5. At the 5% significance level, test whether the sample data provide significance evidence that the mean reading score for all students in that university is not equal to 50.
Question 6. The t-test for one population mean relies on some assumptions for the results to be valid. Check whether these are satisfied or not in this sample.
The data come from a random sample of students from that university, hence the independence assumption is satisfied.
The sample size - that is, the number of data points that are not missing - is \(n = 25\). This is not a large enough sample size for the sample mean to be normally distributed, so we will check whether the sample came from a population that follows a normal distribution. If this is the case, then the sample mean would be normally distributed irrespectively of the sample size.
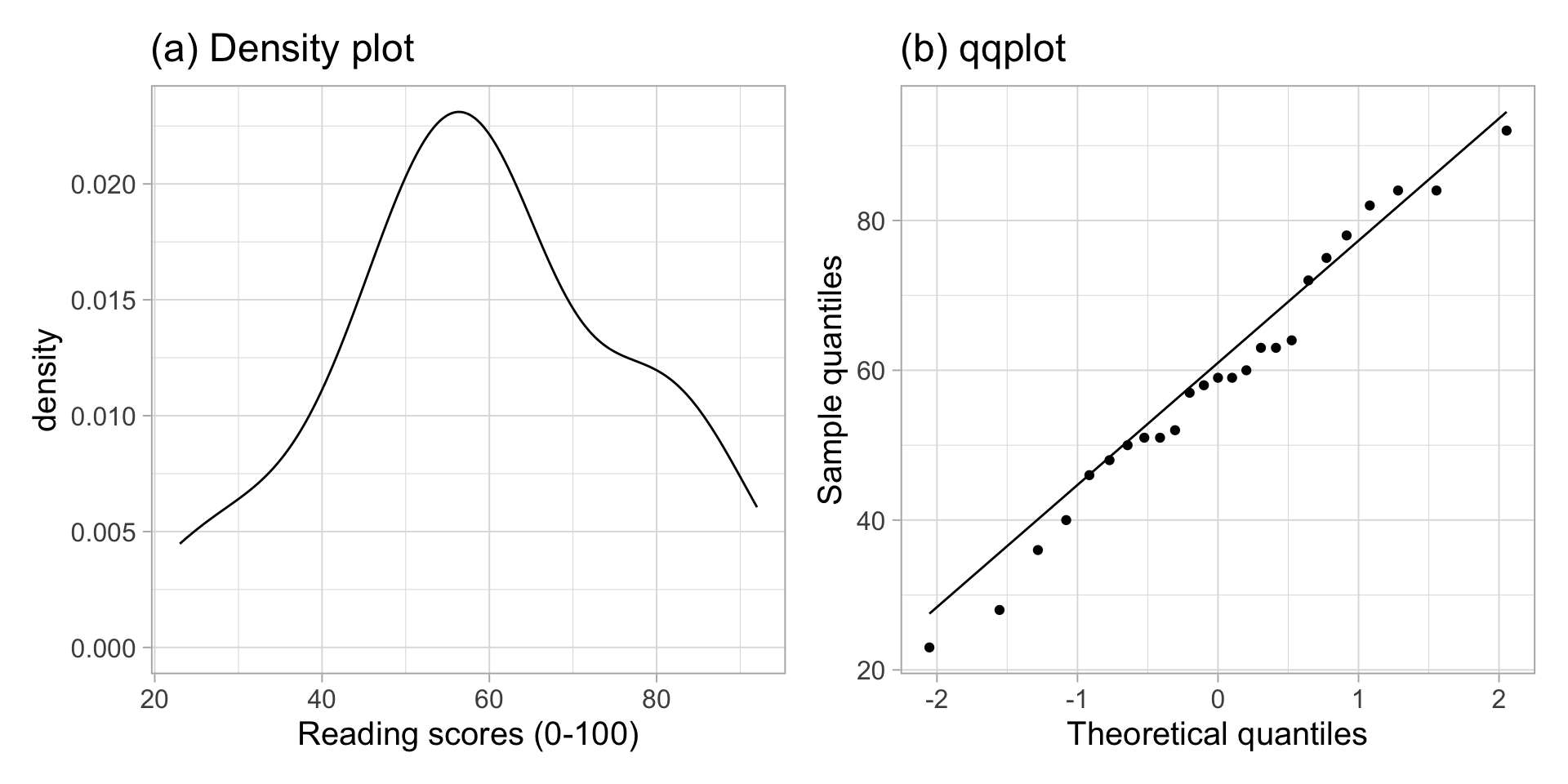
plt1<-ggplot(students_tidy, aes(x =read_score))+geom_density()+labs(x ="Reading scores (0-100)", title ="(a) Density plot")plt2<-ggplot(students_tidy, aes(sample =read_score))+geom_qq()+geom_qq_line()+labs(x ="Theoretical quantiles", y ="Sample quantiles", title ="(b) qqplot")plt1|plt2
Figure 1: Distribution of reading scores
The density plot highlights a roughly bell-shaped distribution with a single peak near 60. The qqplot doesn’t highlight any severe departures from normality, in fact the sample quantiles follow the theoretical quantiles from a normal distribution pretty closely.
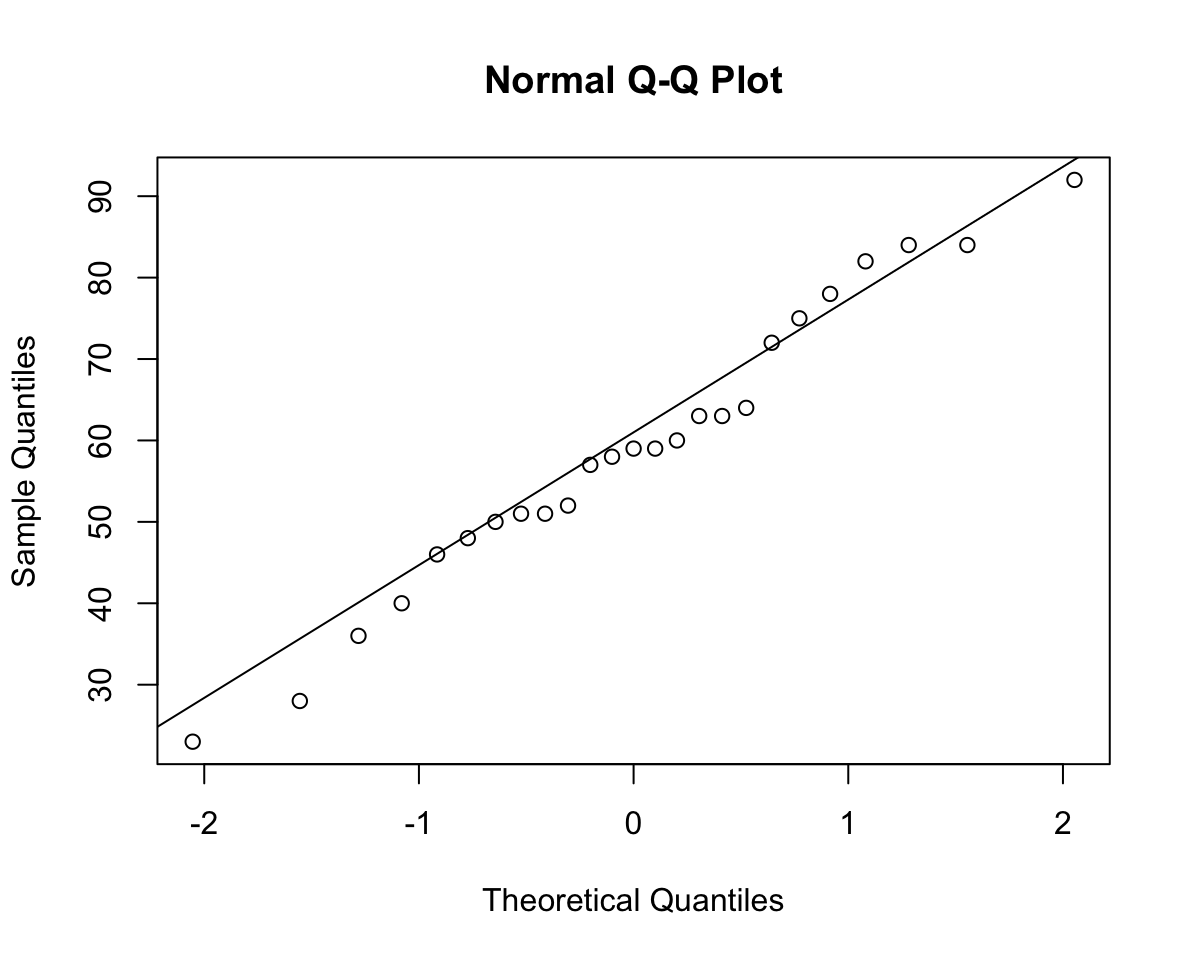
Alternatively, you can also obtain the qqplot as follows:
Shapiro-Wilk normality test
data: students_tidy$read_score
W = 0.97792, p-value = 0.8411
Question 7. Provide a write up pf your results in the context of the study.
Data were obtained from https://uoepsy.github.io/data/students_reading_scores.csv. The dataset contains measurements on age and reading scores for 35 randomly sampled students from a hypothetical university. Due to random sampling of the students, the independence assumption is satisfied. Some students had missing values for their reading scores, so those students were dropped from the analysis, leaving a sample of 25 students for the analysis. A Shapiro-Wilk normality test was performed at the 5% significance level (\(W = 0.98, p = 0.84\)). The sample data do not provide sufficient evidence to reject the null hypothesis of normality of the population data. Furthermore, the density plot shown in Figure 1(a) highlights a roughly bell-shaped distribution, and the qqplot in Figure 1(b) doesn’t show violations from normality.
At the 5% significance level, we performed a hypothesis test against the null hypothesis that the mean reading score of all students in that university was equal to 50. The sample data provide very strong evidence to reject the null hypothesis in favour of the alternative one that the population mean reading score is different from 50: \(t(24) = 2.56, p = 0.02\), two-sided.
We are 95% confident that the mean reading score for all students in that university is between 52 and 66.
Question 8. Is there a significant effect? Is the effect important?
Yes, there is a significant effect, as we found a p-value smaller than the significance level of 5%. However, this is no guarantee that the effect is of practical importance.
To judge whether the effect is important, we need to compute the effect size, i.e. Cohen’s D:
D<-(xbar-mu0)/sD
[1] 0.5121302
Cohen’D highlights a medium effect size, highlighting that the sample result is not only significant, but perhaps also of moderate importance and worth noting.
2 Worked example: power
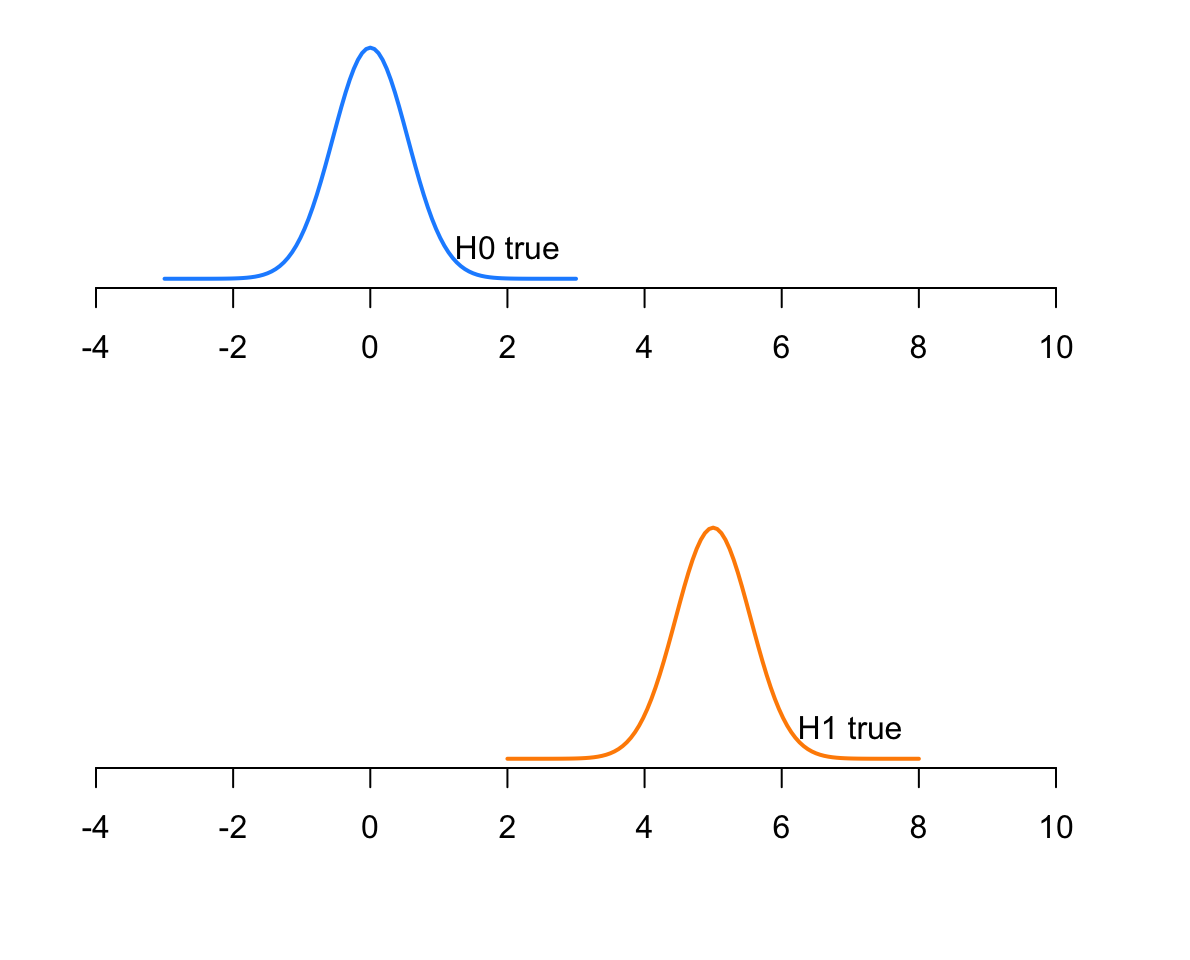
To compute power, you need to know the distribution of the sample mean
when \(H_0\) is true
when \(H_1\) is true
This seldom happens in practice, so these exercises will be more conceptual.
Before going ahead, though, remember that if the population has mean \(\mu\) the sampling distribution of the mean is \(N(\mu, \frac{\sigma}{\sqrt n})\), where \(\sigma\) is the population SD and \(n\) the size of a sample.
Suppose you are testing
\[H_0 : \mu = 0\]\[H_1 : \mu > 0\]
What is the power of the test if:
the population has a mean \(\mu = 5\)
the population has a standard deviation \(\sigma = 3\)
you will take a sample of size 30
The distribution of the sample mean in the population is
\[\bar X \sim N(5, \frac{3}{\sqrt{30}})\]
If \(H_0\) is true, however, the distribution would be:
\[\bar X \sim N(0, \frac{3}{\sqrt{30}})\]
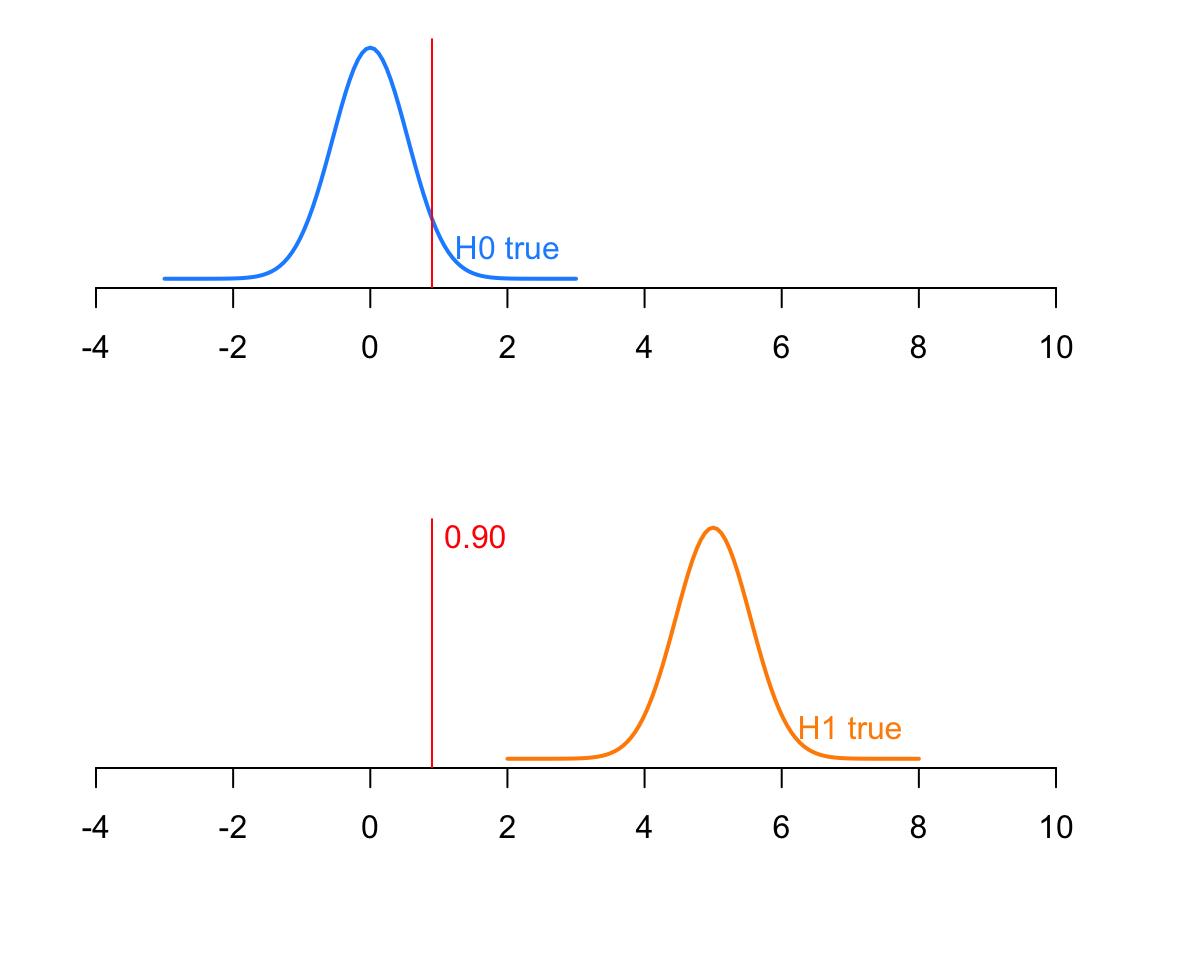
You would reject the null hypothesis, at the 5% significance level, for values larger the 0.95 quantile of a \(N(0, \frac{3}{\sqrt{30}})\) distribution:
The power is the probability of rejecting the null hypothesis when the null is false.
So, if the null is false, the mean follows the distribution \(N(5, \frac{3}{\sqrt{30}})\). The probability of correctly rejecting the null would be the probability under that distribution beyond -1.07
The power, i.e. the probability that the test rejects the null hypothesis when it is false, is 0.98.
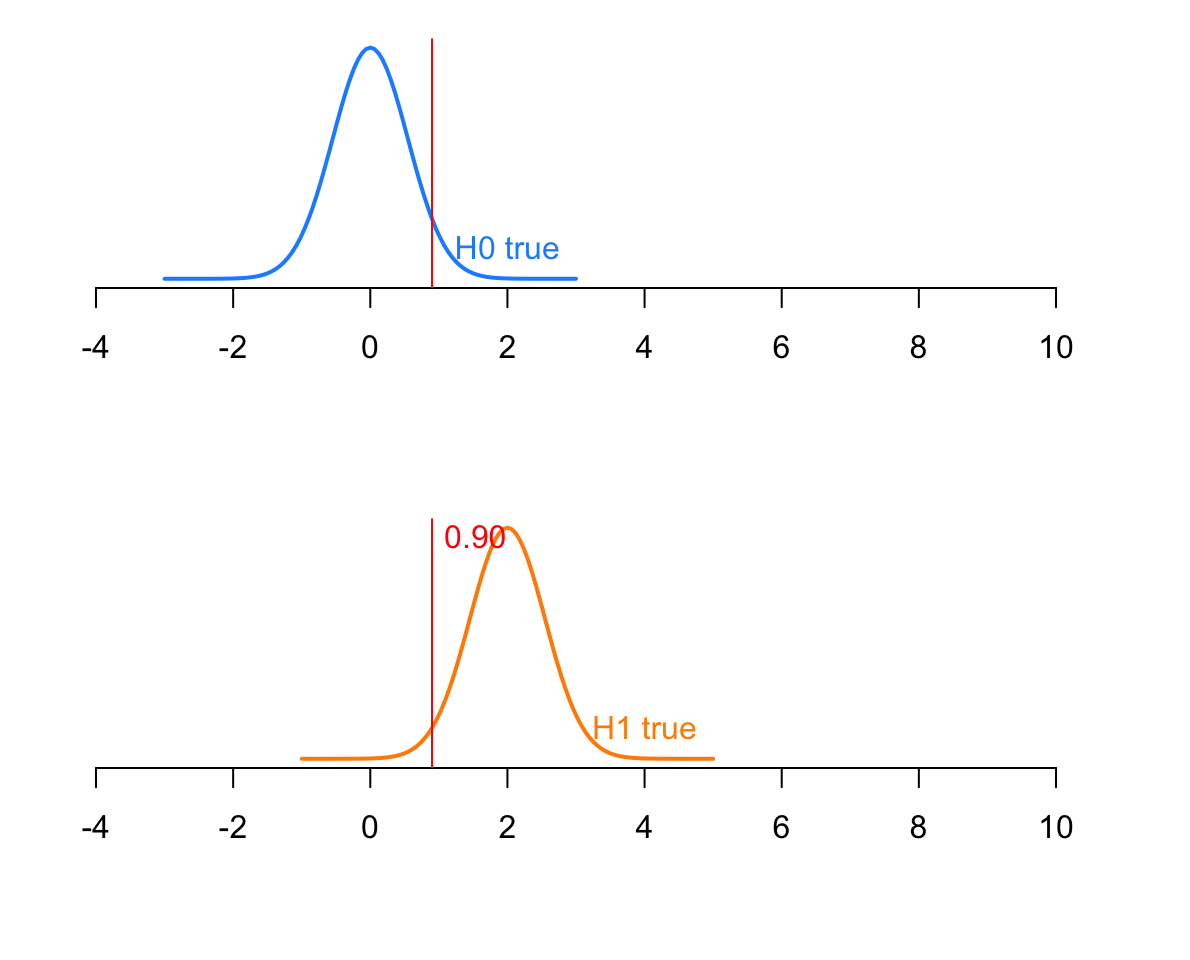
Question 10. Assume now that the true population mean is \(\mu = 2\). What is the probability of a Type II error?
The easiest way to compute it is as \(\beta = 1 - \text{Power}\) because \(\text{Power} = 1 - \beta\).
beta<-1-Powbeta
[1] 0.02230486
The probability of not rejecting the null when it is false is 0.02.
If you want to compute it from scratch you can compute it as the probability to the left of 0.90. This is because values below 0.90 lead to not rejecting the null hypothesis.