| variable | description |
|---|---|
| S | Subject Number |
| Q | Quit attempt - Whether the subject made an attempt to quit using tobacco products (0 = no attempt to quit; 1 = attempted to quit). |
| I | Individuals intention to quit (1 = Never intend to quit; 2 = May intend to quit but not in the next 6 months; 3 = Intend to quit in the next 6 months; 4 = Intend to quit in the next 30 days) |
Logistic Regression II
Learning Objectives
At the end of this lab, you will:
- Understand when to use a logistic model
- Understand how to fit and interpret a logistic model
- Understand how to evaluate model fit
What You Need
- Be up to date with lectures
- Have completed previous lab exercises from Semester 2 Week 7
Required R Packages
Remember to load all packages within a code chunk at the start of your RMarkdown file using library(). If you do not have a package and need to install, do so within the console using install.packages(" "). For further guidance on installing/updating packages, see Section C here.
For this lab, you will need to load the following package(s):
- tidyverse
- patchwork
- kableExtra
- psych
- sjPlot
Presenting Results
All results should be presented following APA guidelines. If you need a reminder on how to hide code, format tables/plots, etc., make sure to review the rmd bootcamp.
The example write-up sections included as part of the solutions are not perfect - they instead should give you a good example of what information you should include and how to structure this. Note that you must not copy any of the write-ups included below for future reports - if you do, you will be committing plagiarism, and this type of academic misconduct is taken very seriously by the University. You can find out more here.
Lab Data
You can download the data required for this lab here or read it in via this link https://uoepsy.github.io/data/QuitAttempts.csv
Study Overview
Research Question
Is attempting to quit tobacco products associated with an individuals intentions?
Setup
Setup
- Create a new RMarkdown file
- Load the required package(s)
- Read in the QuitAttempts dataset into R, assigning it to an object named
smoke
Exercises
Study & Analysis Plan Overview
Question 1
Examine the dataset, and perform any necessary and appropriate data management steps.
Hint
- Convert categorical variables to factors
- Label appropriately factors to aid with your model interpretations if required
- If needed, provide better variable names
Descriptive Statistics & Visualisations
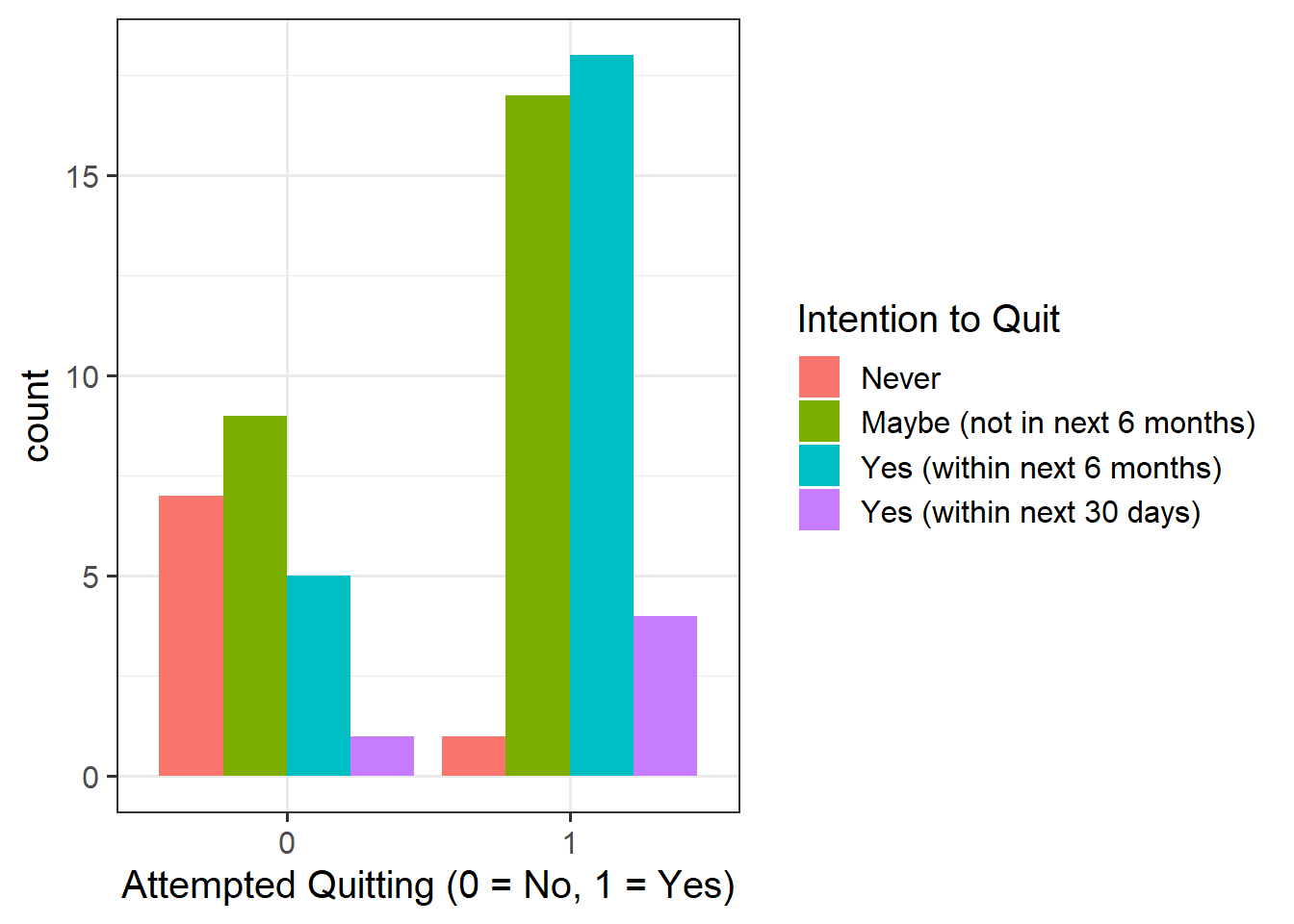
Question 2
Provide a table of descriptive statistics and visualise your data.
Remember to interpret these in the context of the study.
Hint
- For your table of descriptive statistics, since we have two categorical variables, the
select()andtable()functions will come in handy here. - Recall that when visualising a continuous outcome across several groups,
geom_boxplot()may be most appropriate to use. - For your visualisations, you will need to specify
as_factor()when plotting theQuit_Attemptvariable since this is numeric, but we want it to be treated as a factor only for plotting purposes - Make sure to comment on any observed differences among the sample means of the four intention conditions.
Model Fitting & Interpretation
Question 3
Fit your model using glm(), and assign it as an object with the name “smoke_mdl1”.
Question 4
Interpret your coefficients in the context of the study. When doing so, it may be useful to translate the log-odds back into odds.
Hint
The opposite of the natural logarithm is the exponential (see here for more details if you are interested), and in R these functions are log() and exp().
Recall that we can obtain our parameter estimates using various functions such as summary(),coef(), coefficients(), etc. Thus, we want to exponentiate the coefficients from our model in order to translate them back from log-odds.
Question 5
Calculate the predicted probability of each group attempting to quit smoking.
Hint
Conversions
Between probabilities, odds and log-odds (“logit”):
\[ \begin{aligned} &\text{for probability p of Y for observation i:}\\ \qquad \\ odds_i & = \frac{p_i}{1-p_i} \\ \qquad \\ logit_i &= ln(odds_i) = ln(\frac{p_i}{1-p_i}) \\ \qquad \\ p_i & = \frac{odds_i}{1 + odds_i} = \frac{e^{logit_i}}{(1+e^{logit_i})} \end{aligned} \]
To calculate via R, you can use the predict, or plogis functions.
For the former, you will need to specify type = "response" to obtain the predicted probabilities, and this requires the model coefficients to be in log-odds. When specifying newdata =, it might be useful to ask for each unique level of our “Intention” variable.
For the latter, we can calculate the probability corresponding to a given value of logit(p).
Model Fit
Question 6
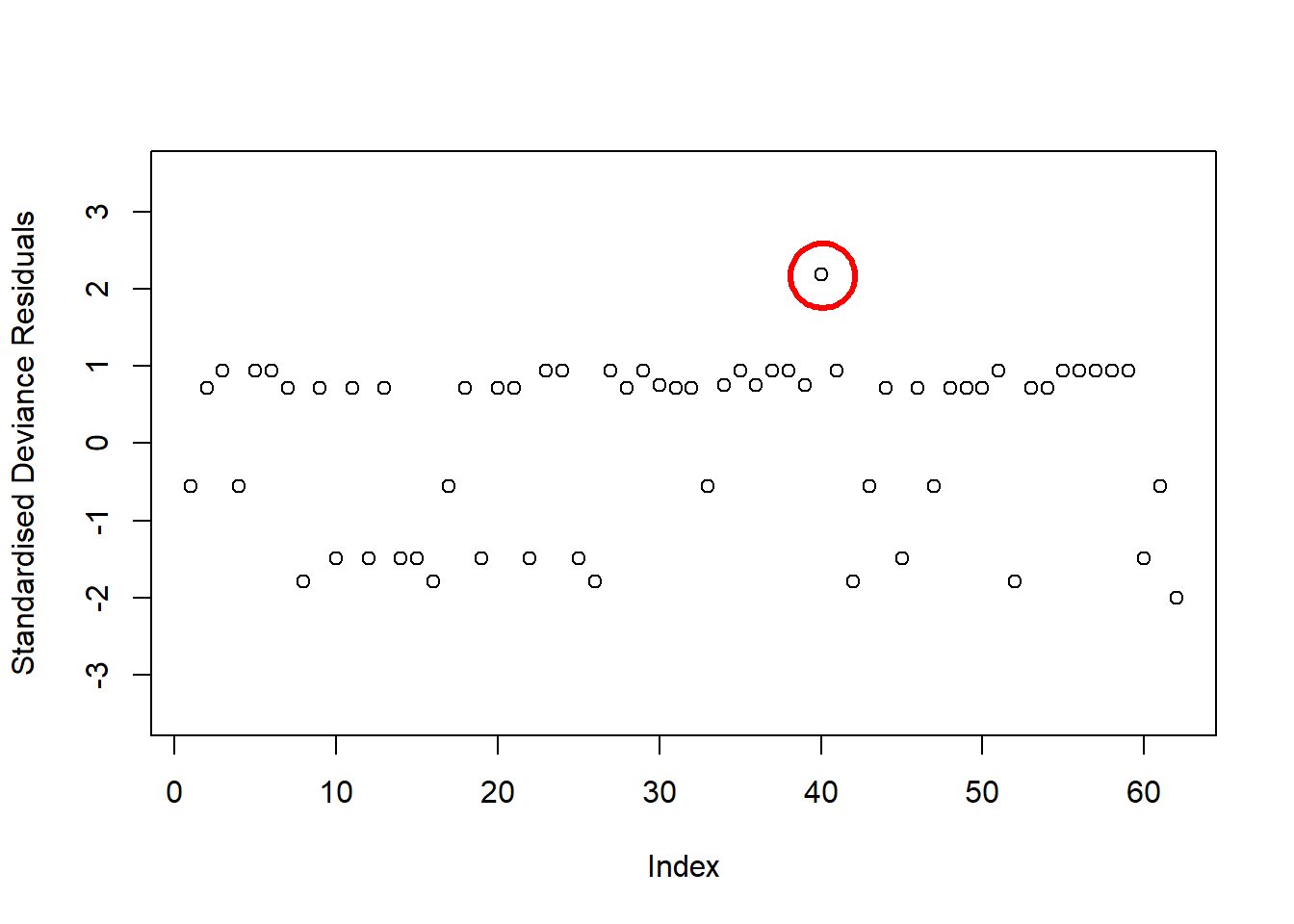
Examine the below plot to determine if the deviance residuals raise concerns about outliers:

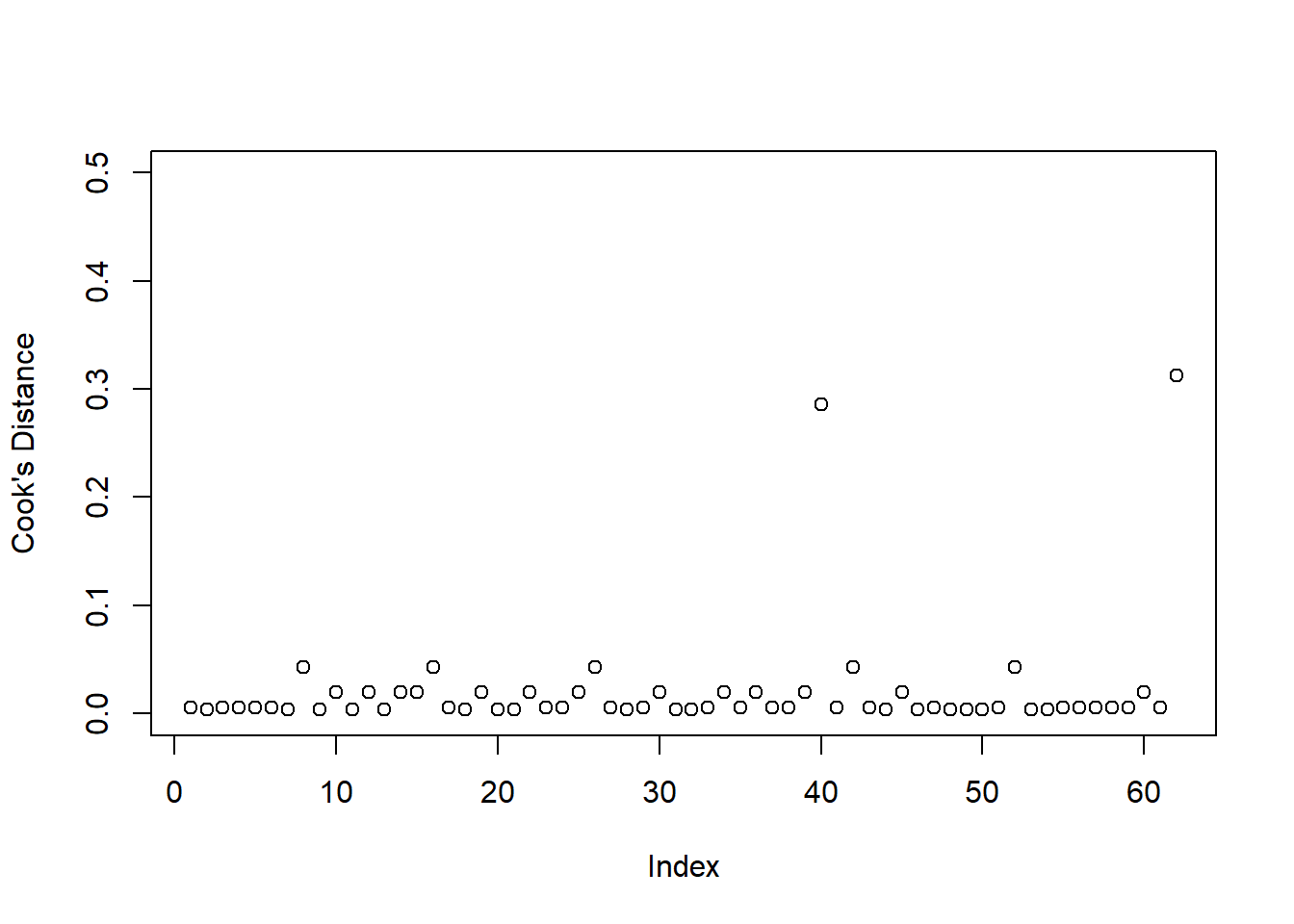
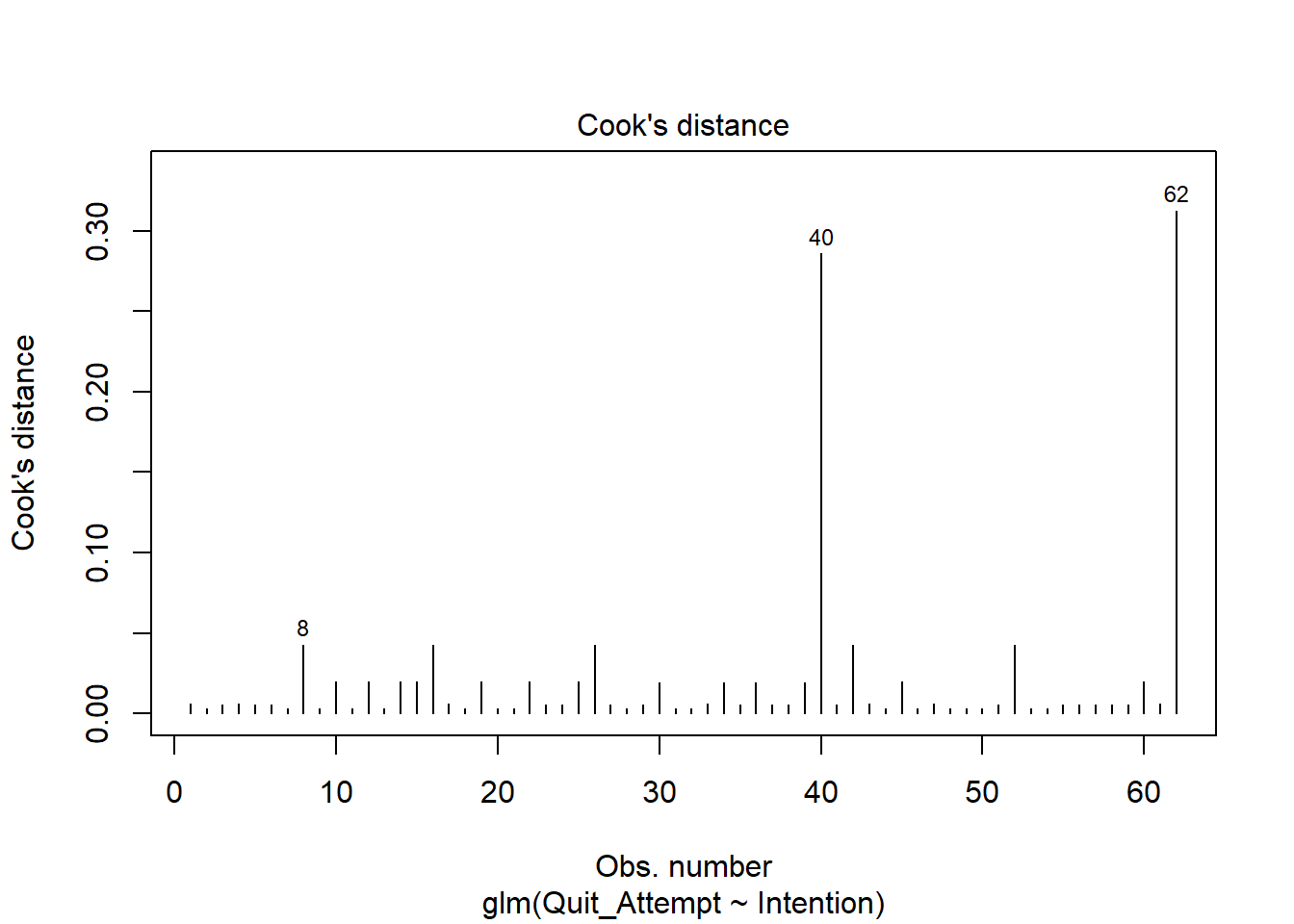
Based on this plot, are there any residuals of concern? Are there any additional plots you could check to determine if there are influential observations?
Hint
Because logistic regression models don’t have the same expected error distribution (we don’t expect residuals to be normally distributed around the mean, with constant variance), checking the assumptions of logistic regression is a little different.
Typically, we look at the “deviance residuals”. But we don’t examine plots for patterns, we simply examine them for potentially outlying observations. If we use a standardised residual, it makes it easier to explore extreme values as we expect most residuals to be within -2, 2 or -3, 3 (depending on how strict we feel).
To check for influential observations, we can use cooks.distance(), and plot this using plot(). Alternatively, you can specify which = 4 when plotting your fitted model (i.e., plot(model, which = ?).
In logistic regression, we can use the arbitrary cut-offs of 0.5 (moderately influential) or 1 (highly influential) to describe influential points.
Question 7
Perform a Deviance goodness-of-fit test to compare your fitted model to the null (denoted as \(M_1\) and \(M_0\) respectively below).
\[ \begin{aligned} M_0 &: \qquad \log \left( \frac{p}{1 - p}\right) ~=~ \beta_0 \\ M_1 &: \qquad \log \left( \frac{p}{1 - p}\right) ~=~ \beta_0 + \beta_1 \cdot Intention_2 + \beta_2 \cdot Intention_3 + \beta_3 \cdot Intention_4 \end{aligned} \]
\[ \begin{aligned} \text{where}~{p}~ &=~ \text{probability of attempting to quit using tobacco products} \end{aligned} \]
Report the results of the model comparison in APA format, and state which model you think best fits the data.
Hint
Consider whether or not your models are nested. The flowchart in Semester 1 Week 4 Lab, Q10 may be helpful to revisit.
Question 8
Check the AIC and BIC values for smoke_mdl0 and smoke_mdl1 - which model should we prefer based on these model fit indices?
Writing Up & Presenting Results
Question 9
Provide key model results in a formatted table.
Hint
Use tab_model() from the sjPlot package.
Remember that you can rename your DV and IV labels by specifying dv.labels and pred.labels.
Question 10
Interpret your results in the context of the research question and report your model in full.
Compile Report
Compile Report
Knit your report to PDF, and check over your work. To do so, you should make sure:
- Only the output you want your reader to see is visible (e.g., do you want to hide your code?)
- Check that the tinytex package is installed
- Ensure that the ‘yaml’ (bit at the very top of your document) looks something like this:
---
title: "this is my report title"
author: "B1234506"
date: "07/09/2024"
output: bookdown::pdf_document2
---
What to do if you cannot knit to PDF
If you are having issues knitting directly to PDF, try the following:
- Knit to HTML file
- Open your HTML in a web-browser (e.g. Chrome, Firefox)
- Print to PDF (Ctrl+P, then choose to save to PDF)
- Open file to check formatting
Hiding Code and/or Output
To not show the code of an R code chunk, and only show the output, write:
```{r, echo=FALSE}
# code goes here
```To show the code of an R code chunk, but hide the output, write:
```{r, results='hide'}
# code goes here
```To hide both code and output of an R code chunk, write:
```{r, include=FALSE}
# code goes here
```
Tinytex
You must make sure you have tinytex installed in R so that you can “Knit” your Rmd document to a PDF file:
install.packages("tinytex")
tinytex::install_tinytex()
Footnotes
Kalkhoran, S., Grana, R. A., Neilands, T. B., & Ling, P. M. (2015). Dual use of smokeless tobacco or e-cigarettes with cigarettes and cessation. American Journal of Health Behavior, 39(2), 277–284. https://doi.org/10.5993/AJHB.39.2.14↩︎