[1] 10Hypothesis testing: p-values
1 Hypothesis testing
1.1 Introduction
The data for the entire population is often not available. However, researchers typically want to answer questions about population characteristics.
By characteristics of a population we mean population parameters, i.e. numerical summaries. Examples are the mean, the standard deviation, a proportion, etc.
Last week we learned how to provide an estimate of the population mean starting from a random sample, as well as a measure of the precision of our estimate.
- The sample mean \(\bar x\) is the estimate of the unknown population mean.
- The standard error of the mean \(s / \sqrt{n}\) provides the reader with a measure of precision in our estimate, or better, the size of a typical estimation error.
This week we will learn how to test a claim about the population mean, starting from sample data.
1.2 Testable hypotheses
In statistics, a hypothesis is a claim, in the form of a precise mathematical statement, about the value of a population parameter.
Examples:
\(\mu = 100\)
where \(\mu\) is the population mean IQ score.\(\sigma = 15\)
where \(\sigma\) is the standard deviation of IQ scores in the population.
Note:
A hypothesis is a claim about a population parameter and not about a sample statistic.
We can compute the value of the sample statistic, so there is no need to perform a test on what its value might be. We can simply look at the value, unlike population parameters. If your sample has a mean \(\bar x = 2\), would it make sense to ask whether the sample mean is 0? No, clearly the sample mean is 2 which is different from 0.
We make hypotheses about things that are unknown, such as parameters.
1.3 The five parts of a test of significance
To perform a hypothesis test we need:
-
The null hypothesis, denoted \(H_0\).
- This is typically a skeptical reaction to a research hypothesis.
-
The alternative hypothesis, denoted \(H_1\).
- This is the claim we seek evidence for.
-
The test statistic. This is used to measure how consistent the data are with the null hypothesis. For testing a mean we use the t-statistic, denoted \(t\).
- The t-statistic measures measures how many SEs away from the hypothesised mean is the observed sample mean. That is, it measures how much the sample data differ from what expected when the null hypothesis is true.
-
The significance level, denoted \(\alpha\)
- The significance level is a cutoff chosen by the researcher (you!). Typical values are 0.10, 0.05, or 0.01.
- A value of 0.05 would mean that you would obtain such result if \(H_0\) is true only in 1 out of 20 samples (or, equivalently, 5 out of 100).
-
The p-value
- The probability of obtaining a test statistic at least as extreme as the observed test statistic, if the null hypothesis is true.
- If the p-value \(\leq \alpha\), we reject \(H_0\) as the data provide enough evidence (at the chosen \(\alpha\) level) against \(H_0\) and in favour of \(H_1\)
- If the p-value \(> \alpha\), we fail to reject \(H_0\) as the data do not provide sufficient evidence against \(H_0\) and in favour of \(H_1\)
- If \(H_1 : \mu > \mu_0\), compute the p-value by finding \(P(T > t)\)
- If \(H_1 : \mu < \mu_0\), compute the p-value by finding \(P(T < t)\)
- If \(H_1 : \mu \neq \mu_0\), compute the p-value by finding \(P(T < - |t|) + P(T > + |t|)\) or, equivalently, \(2 \times P(T > |t|)\).
2 Example
2.1 Imaginary case
Suppose you have an imaginary toy population of 5 individuals, on which you collect a score, and the mean score is actually equal to 10.
If we could only afford to sample \(n = 2\) individuals, and take all possible random samples, what would all the possible sample means look like?
| sample_id | sample | xbar |
|---|---|---|
| 1 | (8, 6) | 7 |
| 2 | (6, 8) | 7 |
| 3 | (10, 6) | 8 |
| 4 | (6, 10) | 8 |
| 5 | (12, 6) | 9 |
| 6 | (10, 8) | 9 |
| 7 | (8, 10) | 9 |
| 8 | (6, 12) | 9 |
| 9 | (14, 6) | 10 |
| 10 | (12, 8) | 10 |
| 11 | (8, 12) | 10 |
| 12 | (6, 14) | 10 |
| 13 | (14, 8) | 11 |
| 14 | (12, 10) | 11 |
| 15 | (10, 12) | 11 |
| 16 | (8, 14) | 11 |
| 17 | (14, 10) | 12 |
| 18 | (10, 14) | 12 |
| 19 | (14, 12) | 13 |
| 20 | (12, 14) | 13 |
As you see above, each sample leads to a different sample mean. We can plot those means with a histogram, to find what sample means happen more often, and which sample means happen less frequently, when the population mean is in fact \(\mu = 10\). Remember? I gave you a population where the mean was exactly equal to 10.
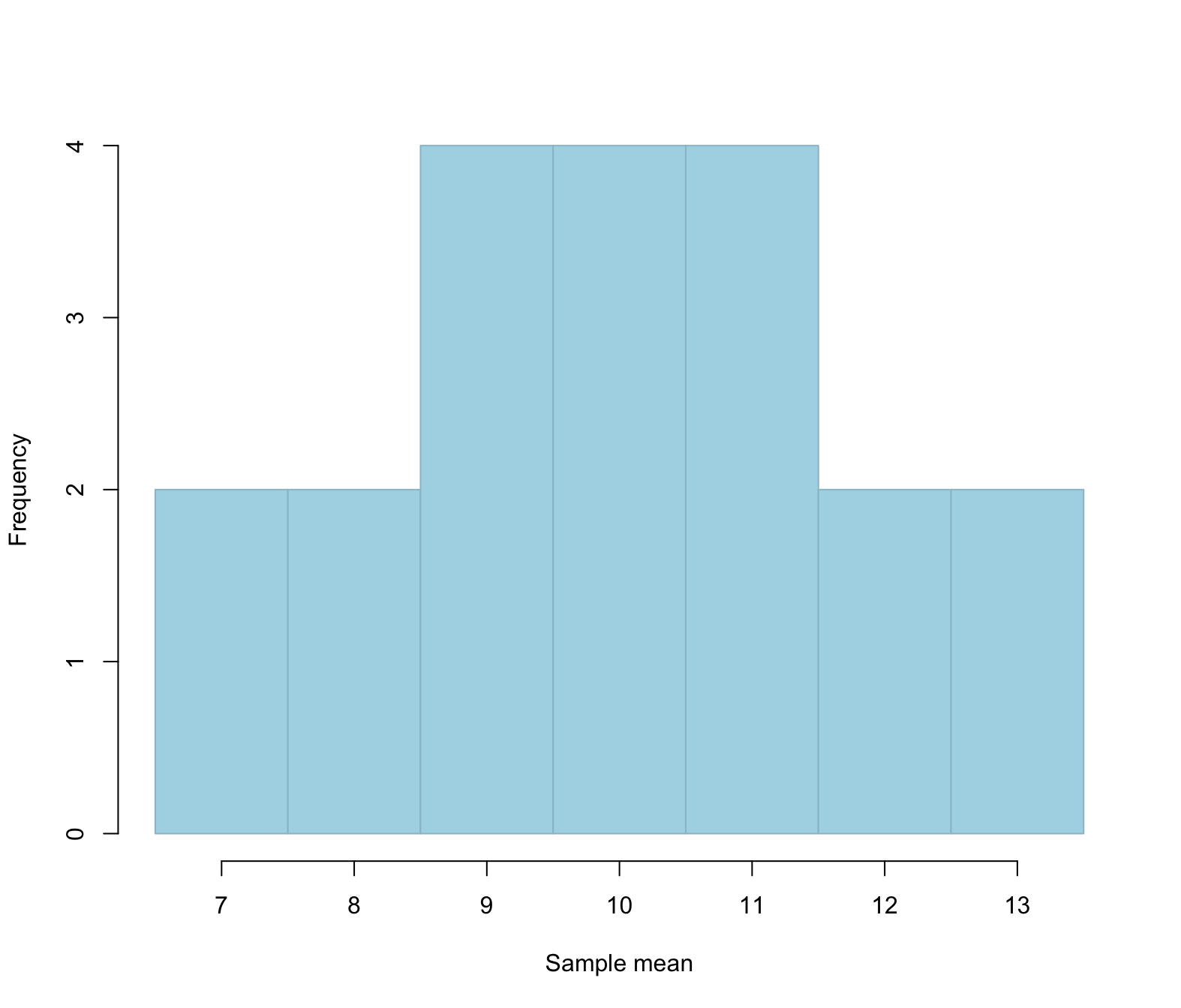
We notice a few things. When the population mean is \(\mu = 10\):
- Most samples will have a sample mean which is close to the true population mean
- Very few samples will have a sample mean that is far away from the true population mean
In this case,
- 4 samples only have a sample mean \(\leq\) 8
- 12 samples have a sample mean between 9 and 11
- 4 samples only have a sample mean \(\leq\) 12
So, if the population mean is truly \(\mu = 10\), it is less likely to obtain a sample with a mean of 7, and it is more likely to obtain a sample with a mean of 9, 10, or 11 for example.
We can also add a density above:
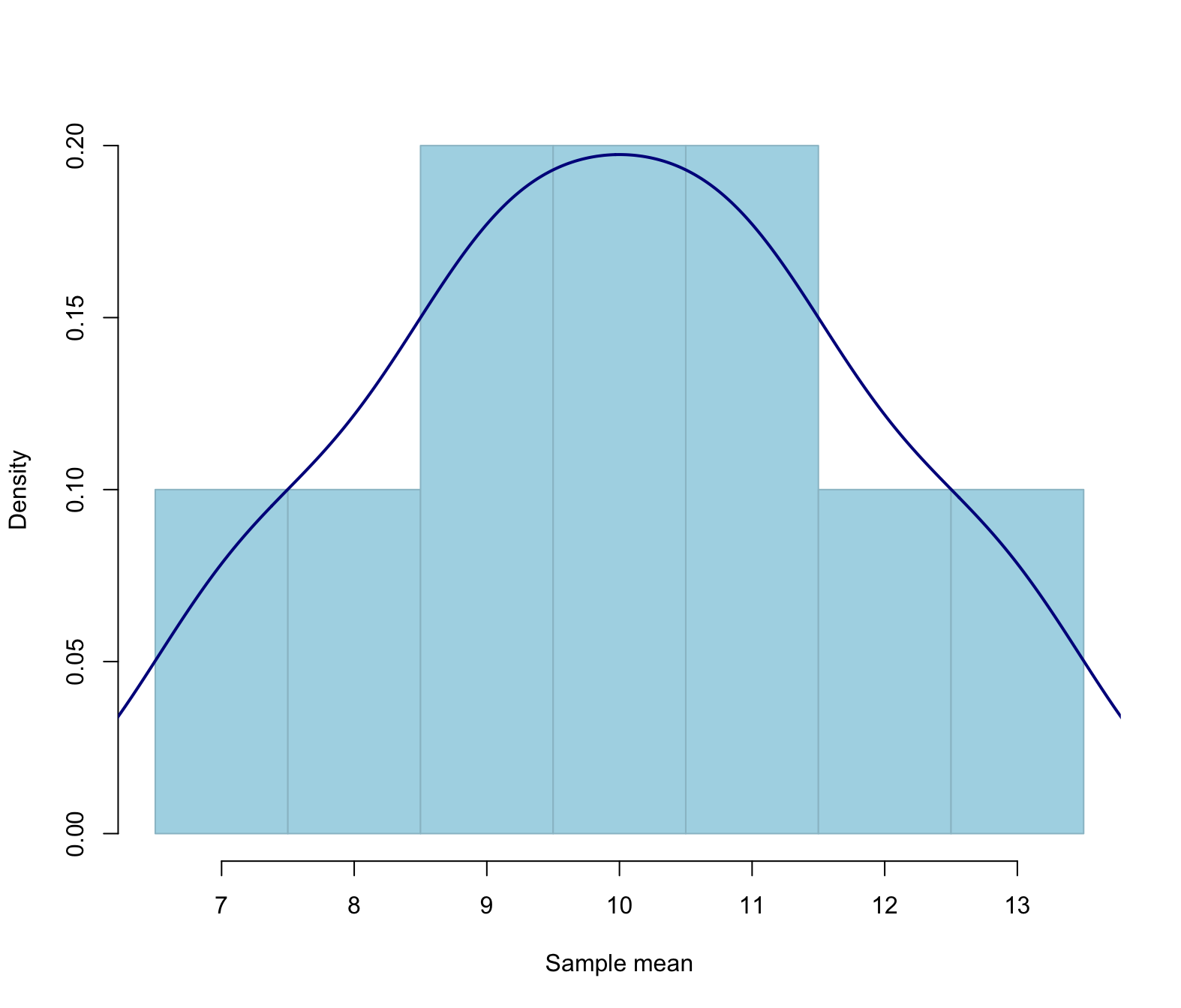
The plot above shows us the possible values that the sample means can take, assuming that the population mean is equal to some value (in this case assuming \(\mu = 10\))
Key question
If you obtained a sample with a mean of 20, would you find this consistent with a population having a mean of 10, or would you start doubting this and perhaps find it more likely that the population mean was different from 10?
If your sample had a mean of 20, when in fact this is a value you don’t expect to happen that often in the above distribution, we would find this a surprising result, and we would doubt the population has a mean of 10.
Now we must go back to reality and realise that we cannot really take all possible samples from a population. We can only afford one and we must work with that single sample we have.
2.2 Real life: One sample only
Suppose your sample is (6, 12).
Let’s compute the observed sample mean:
We wish to test whether the population the sample came from has a mean different from 10.
\[H_0: \mu = 10\] \[H_1: \mu \neq 10\]
Key question:
The mean in our sample is 9. Could a sample mean of 9 easily come from a population that has a mean of 10? Or is it very unlikely for a population with mean 10 to give rise to a sample with mean 9?
2.3 t-distribution
Instead of working with the sample means directly, we work with the standardised sample means, using the t-statistic to standardise them. (Call it t-score if you prefer, to remind you of the z-score). The formula is:
\[ t = \frac{\bar x - \mu_0}{s / \sqrt n} \]
First let’s compute the observed value of the t-statistic, which uses the mean from the observed sample. Furthermore, remember that in our case \(H_0 : \mu = 10\).
So:
\[ t = \frac{9 - 10}{3} = -0.33 \]
We know that the t-statistic follows a \(t(n-1)\) distribution. So, in our case a \(t(1)\) distribution.
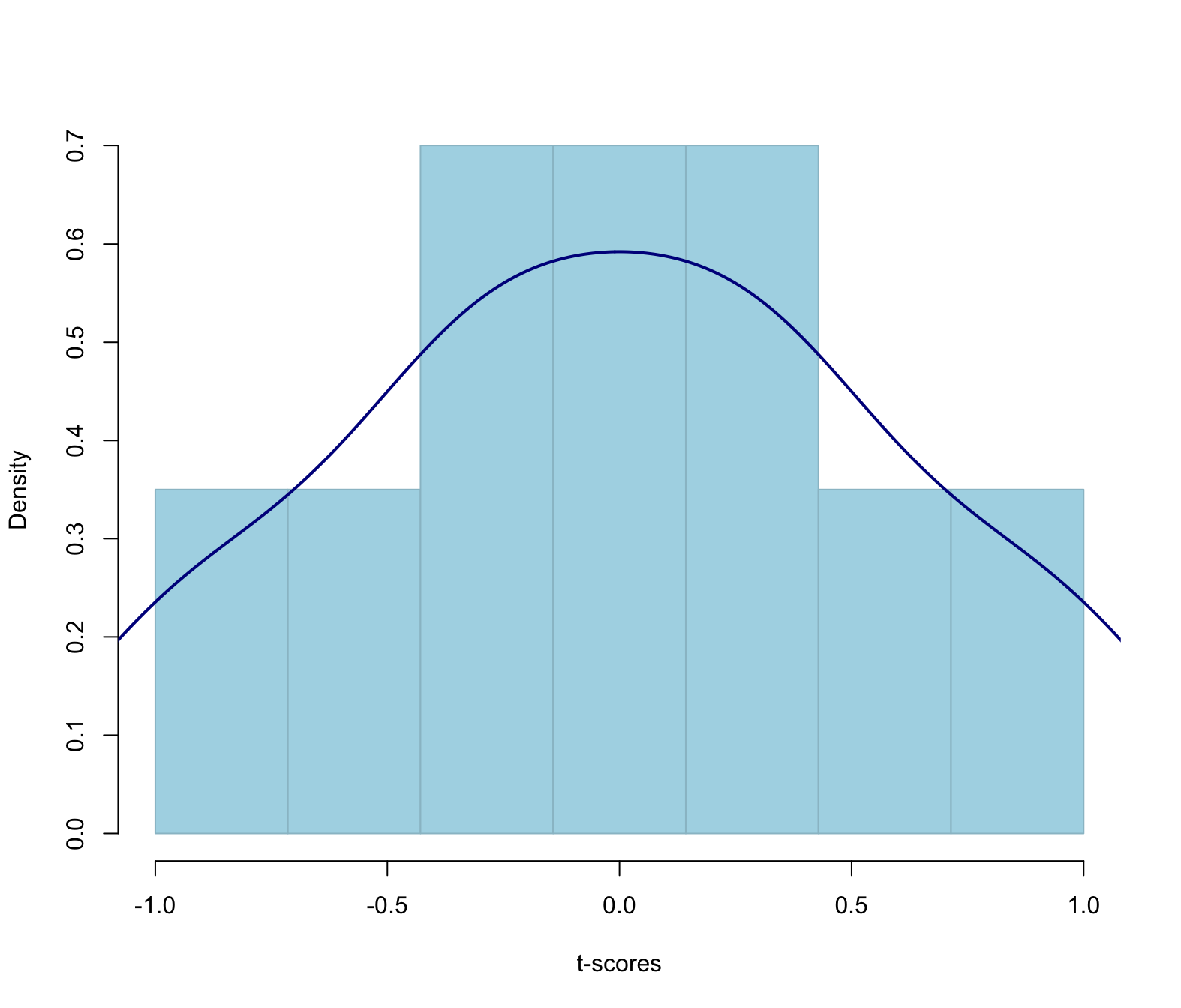
Visualise the t-statistics
We can use the previous histogram of sample means and, instead of plotting the actual means, we can plot the t-score of each mean from 10. This will show how far is each sample mean from the hypothesised value (10), in SE units:
Let’s add the observed t-score on the plot
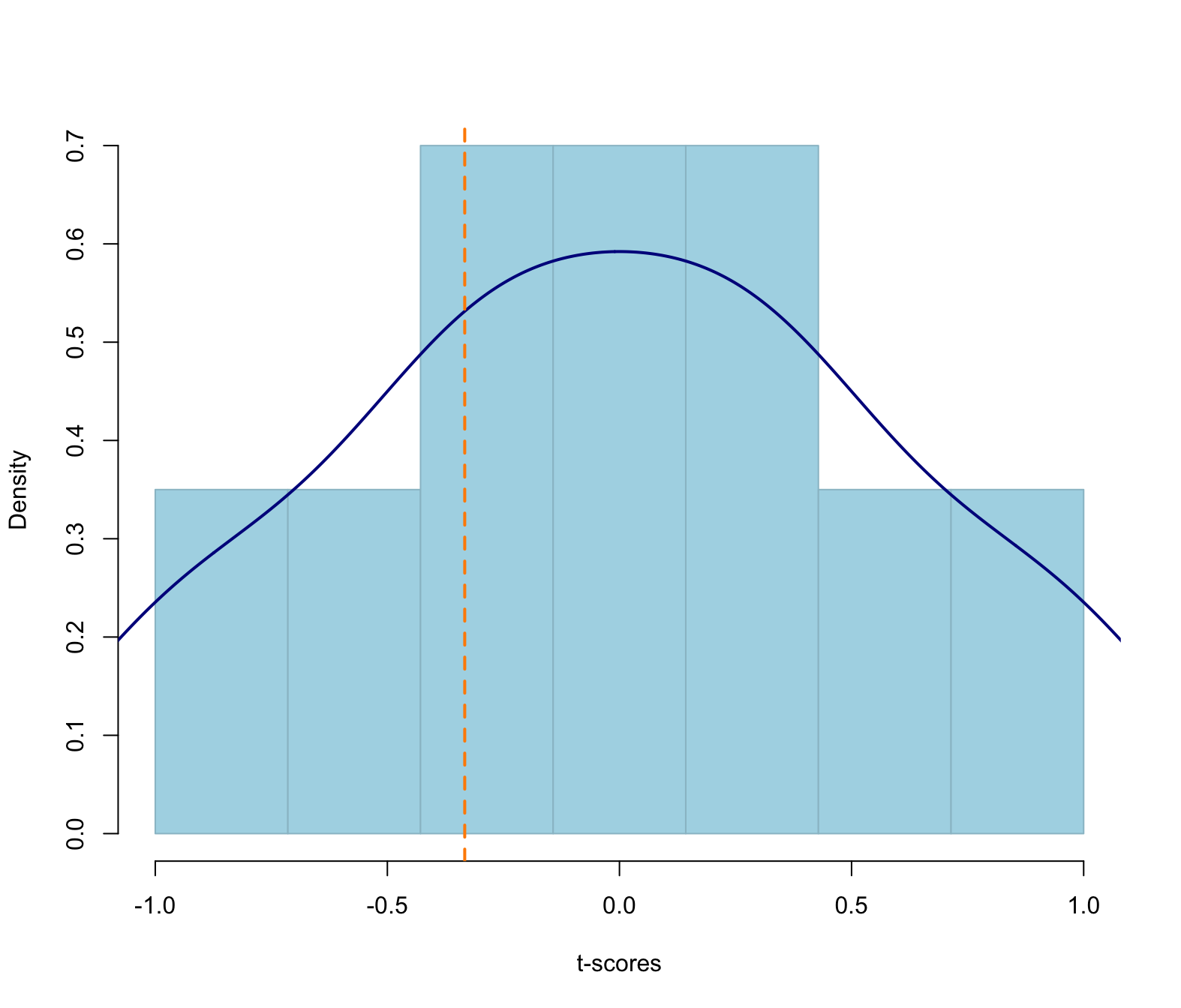
How likely is it to obtain a t-score at least as extreme as -0.33?
In this case \(H_1\) has the \(\neq\) symbol. Something is different from 10 when it’s either much larger or much smaller. So we find the probability of t-statistics that are either more distant from the hypothesised value of 10 on the left tail, but also on the right tail.
How likely is it to obtain a t-score either lower than -0.33 \((=-|t|)\) or larger than 0.33 \((= +|t|)\)?
[1] 0.7951672Comparing the p-value with \(\alpha\) = 0.05, we find that the p-value is larger than the significance level and as such we do not reject \(H_0\).
The sample data do not provide sufficient evidence to reject the null hypothesis that the sample \((6, 12)\) came from a population with mean 10.
2.4 Test your knowledge
What about if the sample you collected was (172, 194)? Could this come from a population having mean = 10?
Answer
[1] 11tobs <- (xbar - 10) / SE
tobs[1] 15.72727[1] 0.0404243or
The p-value is \(\leq 0.05\) so we reject \(H_0\)
At the 5% significance level, the sample data provide strong evidence against the null hypothesis that the sample \((172, 194)\) came from a population with a mean of 10, and in favour of the alternative hypothesis that the sample came from a population with a mean different from 10.
3 Summary
We have learned to assess how much evidence the sample data bring against the null hypothesis and in favour of the alternative hypothesis.
The null hypothesis, denoted \(H_0\), is a claim about a population parameter that is initially assumed to be true. It typically represents “no effect” or “no difference between groups”.
The alternative hypothesis, denoted \(H_1\), is the claim we seek evidence for.
-
We performed a hypothesis test against \(H_0\) (and in favour of \(H_1\)) following these steps:
- Formally state your null and alternative hypotheses using precise symbols
- Consider the distribution of the t-statistics when \(H_0\) is true
- Compute the observed value of the t-statistic in our sample
- Obtain the p-value: the probability, computed assuming that \(H_0\) is true, of obtaining a t-statistic at least as extreme as that observed. Note: as extreme means “in the direction specified by \(H_1\)”.
4 Worked example
A 2011 study by Courchesne et al.1 examined brain tissue of seven autistic male children between the ages of 2 and 16. The mean number of neurons in the prefrontal cortex in non-autistic male children of the same age is about 1.15 billion. The prefrontal cortex is the part of the brain most disrupted in autism, as it deals with language and social communication.
In the exercises you will perform a test of significance to assess whether this sample provides evidence that autistic male children have more neurons (on average) in the prefrontal cortex than non-autistic children.
Data codebook
Download link
The data can be found at this address: https://uoepsy.github.io/data/NeuronCounts.csv
Preview
| Case | Age | PFC_NC |
|---|---|---|
| 1 | 2 | 2.42 |
| 2 | 3 | 1.80 |
| 3 | 3 | 2.21 |
| 4 | 4 | 2.18 |
| 5 | 7 | 1.28 |
| 6 | 8 | 1.59 |
| 7 | 16 | 2.09 |
Codebook
- The first column,
Case, is an anonymised index used to identify each child. - The second column,
Age, records the age of each child. - The last column,
PFC_NC, contains the prefrontal cortex neuron counts (in billions).
Question 1. Read the data into R.
# A tibble: 7 × 3
Case Age PFC_NC
<dbl> <dbl> <dbl>
1 1 2 2.42
2 2 3 1.8
3 3 3 2.21
4 4 4 2.18
5 5 7 1.28
6 6 8 1.59
7 7 16 2.09Question 2. Compute and interpret a table of descriptive statistics.
stats <- autism %>%
summarise(
SampleSize = n(),
M_Age = mean(Age), SD_Age = sd(Age),
M_PFC_NC = mean(PFC_NC), SD_PFC_NC = sd(PFC_NC)
) %>%
round(2)
stats# A tibble: 1 × 5
SampleSize M_Age SD_Age M_PFC_NC SD_PFC_NC
<dbl> <dbl> <dbl> <dbl> <dbl>
1 7 6.14 4.88 1.94 0.4In the sample of seven autistic children, the mean age was 6.14 years, with a SD of 4.88 years, and the mean number of neurons in the prefrontal cortex was 1.94 billion with a standard deviation of 0.40 billion.
Question 3. State the null and alternative hypotheses.
We wish to test the claim that the mean number of neurons in the prefrontal cortex is larger than 1.15 billion (the value for non-autistic male children). At this is our research hypothesis, we must place this into the alternative hypothesis.
Remember: A hypothesis test looks for evidence against a null hypothesis and in favour of the alternative.
The null hypothesis is typically a skeptical reaction to a research hypothesis. In our case, a skeptic would say that there is no difference in mean number of neurons, so the mean number of neurons for autistic children will be equal to that of non-autistic children (1.15).
The answer is then:
\[H_0 : \mu = 1.15\] \[H_1 : \mu > 1.15\]
where \(\mu\) is the mean number of neurons (in billions) in the prefrontal cortex for all autistic male children.
Question 4. Compute the value of the t-statistic from the sample mean number of neurons.
Recall the formula for the t-statistic:
\[ t = \frac{\bar x - \mu_0}{\frac{s}{\sqrt{n}}} \]
where
- \(\bar x\) is the sample average number of neurons in the prefrontal cortex
- \(\mu_0\) is the hypothesised value for the population parameter found in \(H_0\)
- \(s\) is the sample standard deviation
- \(n\) is the sample size
Hence, the value of the t-statistic for the observed sample is given by:
xbar <- mean(autism$PFC_NC)
xbar[1] 1.938571s <- sd(autism$PFC_NC)
s[1] 0.4002261n <- nrow(autism)
n[1] 7mu0 <- 1.15
tobs <- (xbar - mu0) / (s / sqrt(n))
tobs[1] 5.212963The sample mean neuron count, 1.94 billion, is 5.21 standard errors larger than the hypothesised value.
Question 5. Identify the null distribution.
When \(H_0: \mu = 1.15\) is true, the t values will follow a \(t(6)\) distribution.
Question 6. Compute the p-value for the test.
The alternative hypothesis is \(H_1 : \mu > 1.15\). This involves the “greater than sign”, so we compute the p-value by finding the probability of observing a t-statistic at least as large as the observed t value:
# P(T >= tobs)
pt(tobs, df = n-1, lower.tail = FALSE)[1] 0.0009948463or
# P(T >= tobs) = 1 - P(T <= tobs)
1 - pt(tobs, df = n-1)[1] 0.0009948463Question 7. Using a 5% significance level, i.e. \(\alpha = 0.05\), report whether or not you reject the null hypothesis.
The p-value is smaller than \(\alpha = 0.05\), so we reject \(H_0\).
Question 8. Write up your results in the context of the research question.
The estimated mean number of neurons in the prefrontal cortex of male autistic children is 1.94 billion, with a standard error of 0.15 billion.
At the 5% significance level, we performed a one-sided test of significance against the null hypothesis that the mean number of neurons in the prefrontal cortex of all male autistic children was equal to that of all non-autistic male children. The sample results indicate that there is very strong evidence that the mean number of neurons in the prefrontal cortex may be larger for autistic compared to non-autistic male children: \(t(6) = 5.21, p < .001\), one-sided.
Footnotes
Courchesne, E., et al., “Neuron Number and Size in Prefrontal Cortex of Children with Autism,” Journal of the American Medical Association, November 2011;306(18): 2001–2010.↩︎