Rows: 157
Columns: 7
$ Bill <dbl> 23.70, 36.11, 31.99, 17.39, 15.41, 18.62, 21.56, 19.58, 23.59, …
$ Tip <dbl> 10.00, 7.00, 5.01, 3.61, 3.00, 2.50, 3.44, 2.42, 3.00, 2.00, 1.…
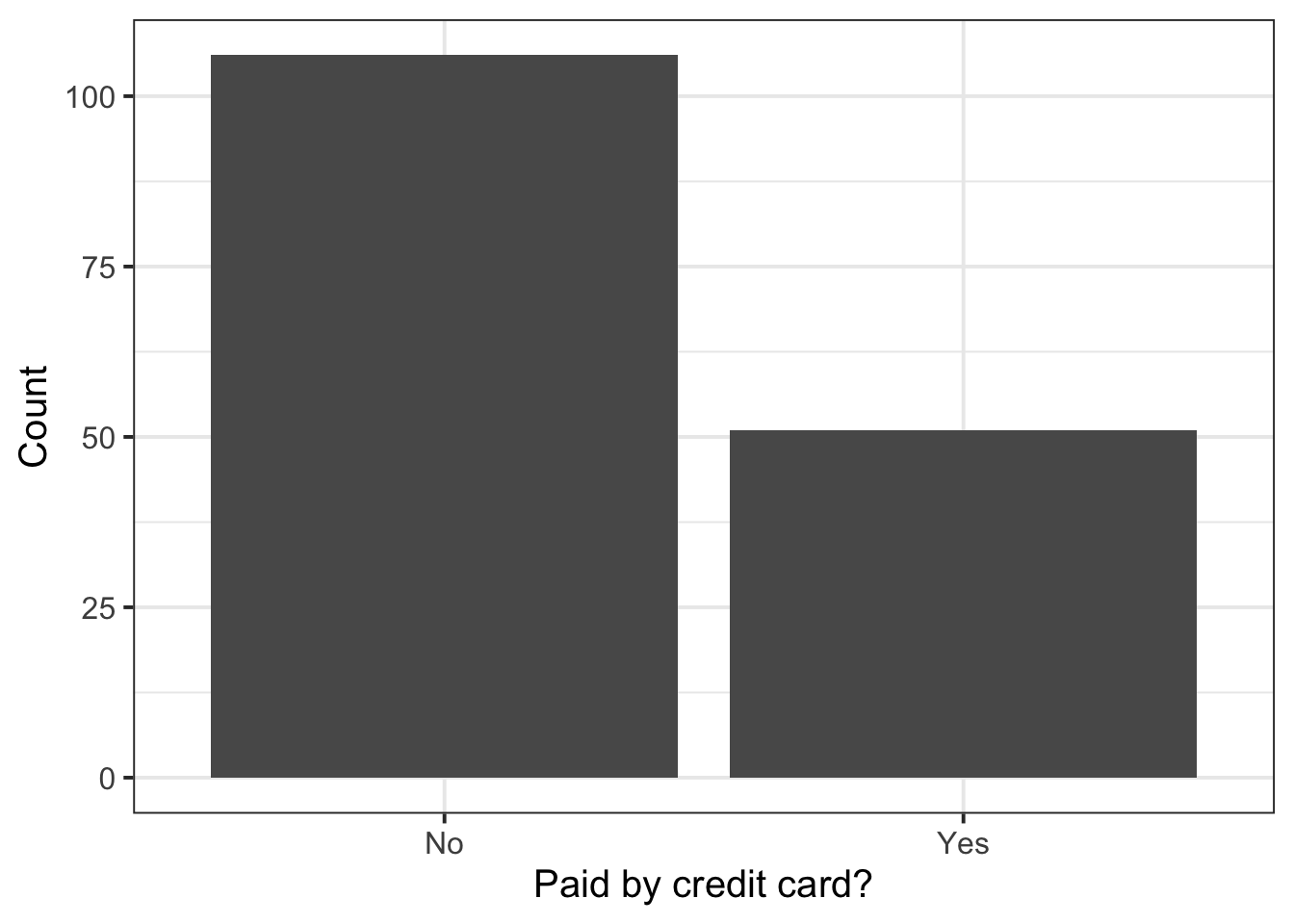
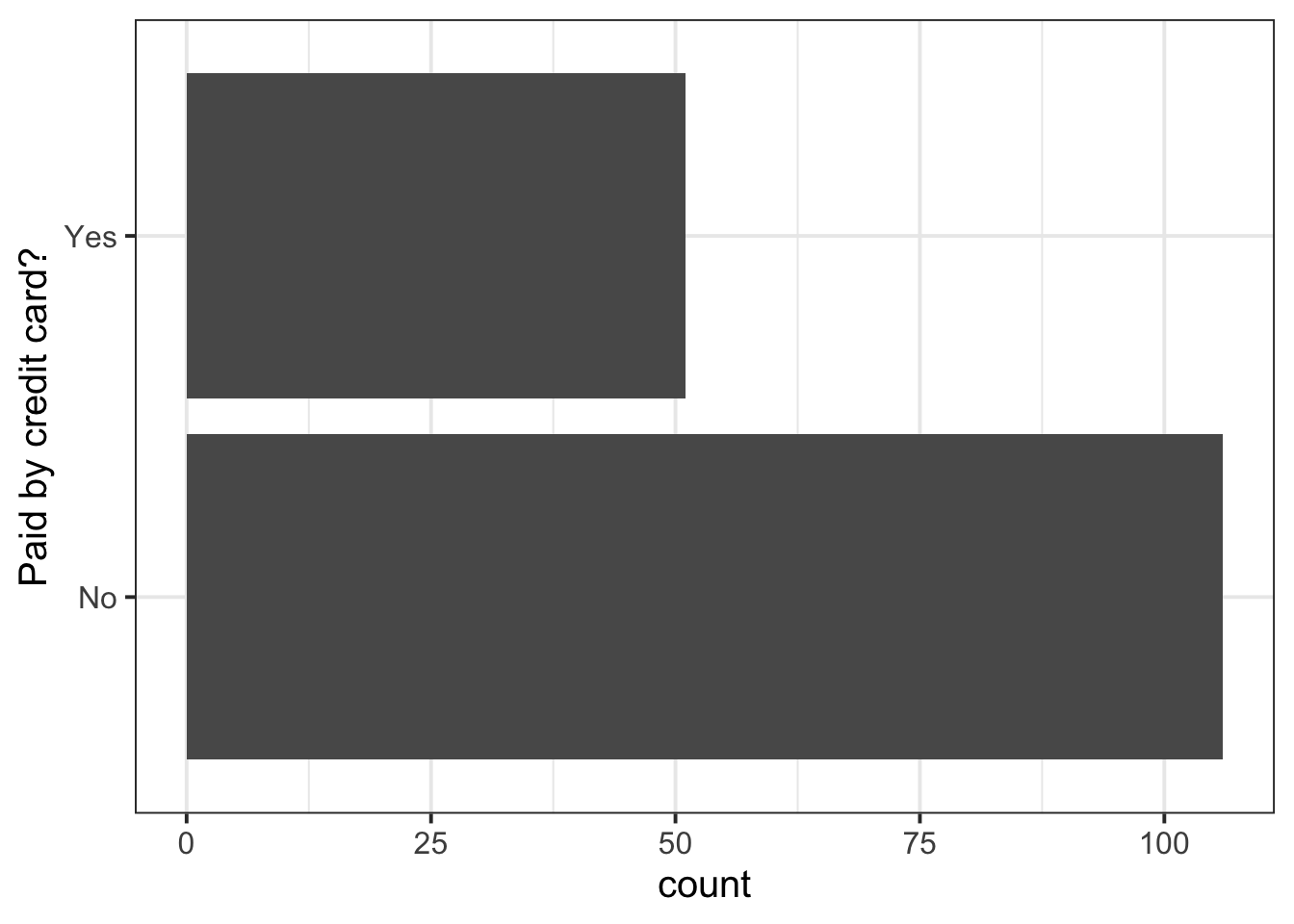
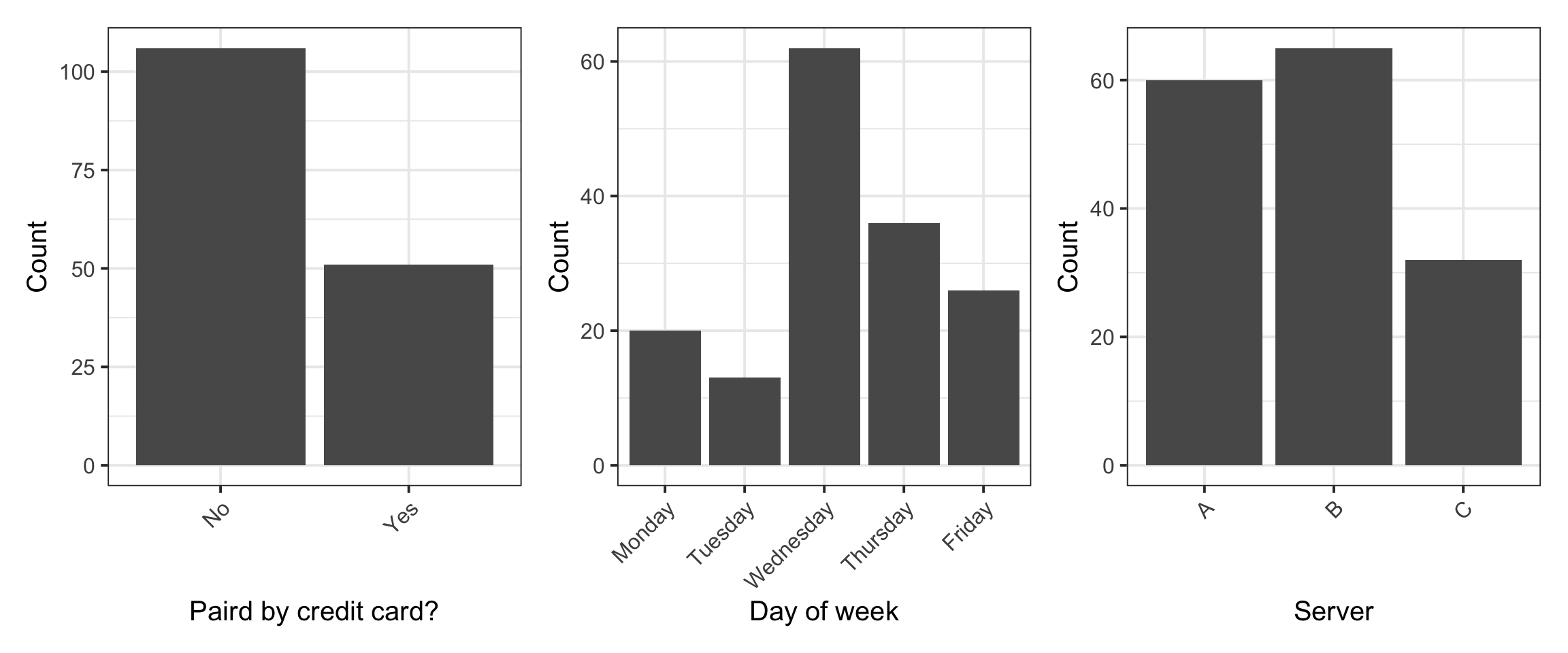
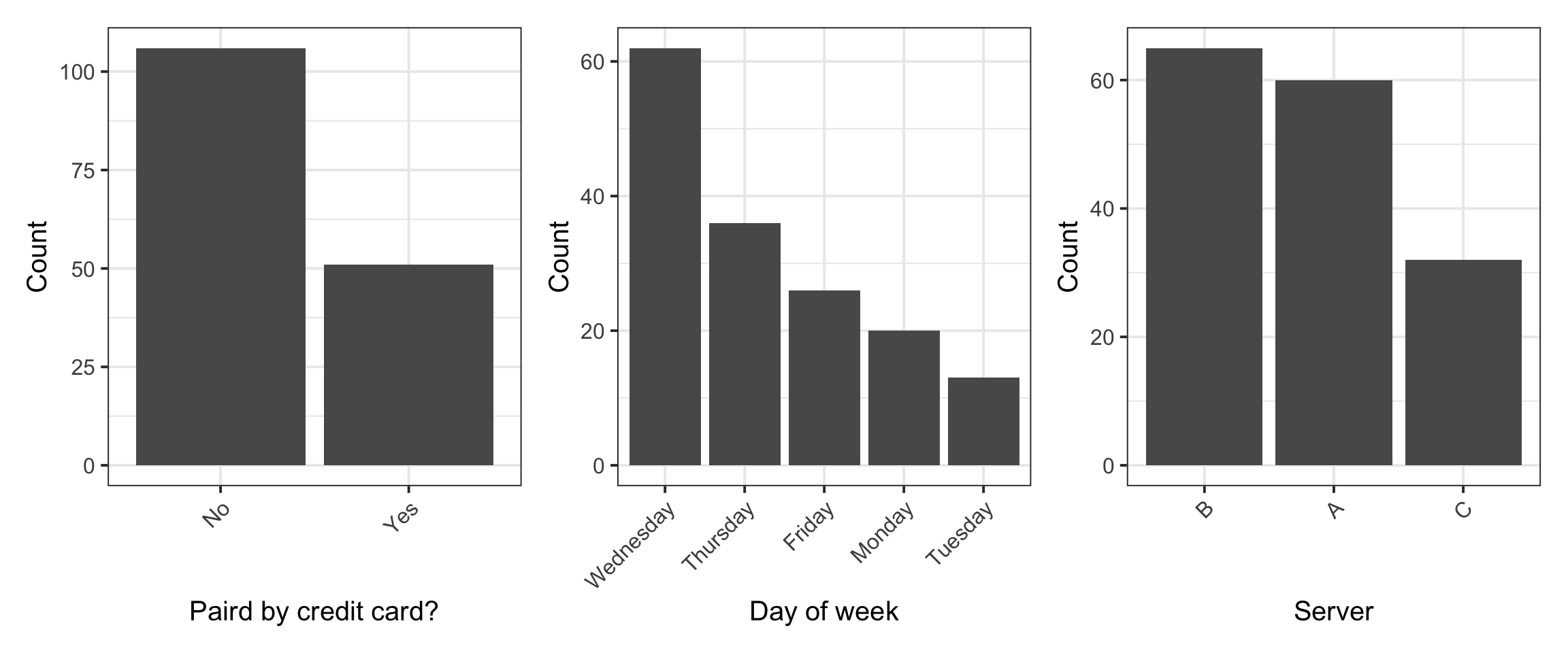
$ Credit <fct> No, No, Yes, Yes, No, No, No, No, No, No, No, No, No, No, No, N…
$ Guests <dbl> 2, 3, 2, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 2, 2, 3, 2, 2, 1, 5, 5, …
$ Day <fct> Friday, Friday, Friday, Friday, Friday, Friday, Friday, Friday,…
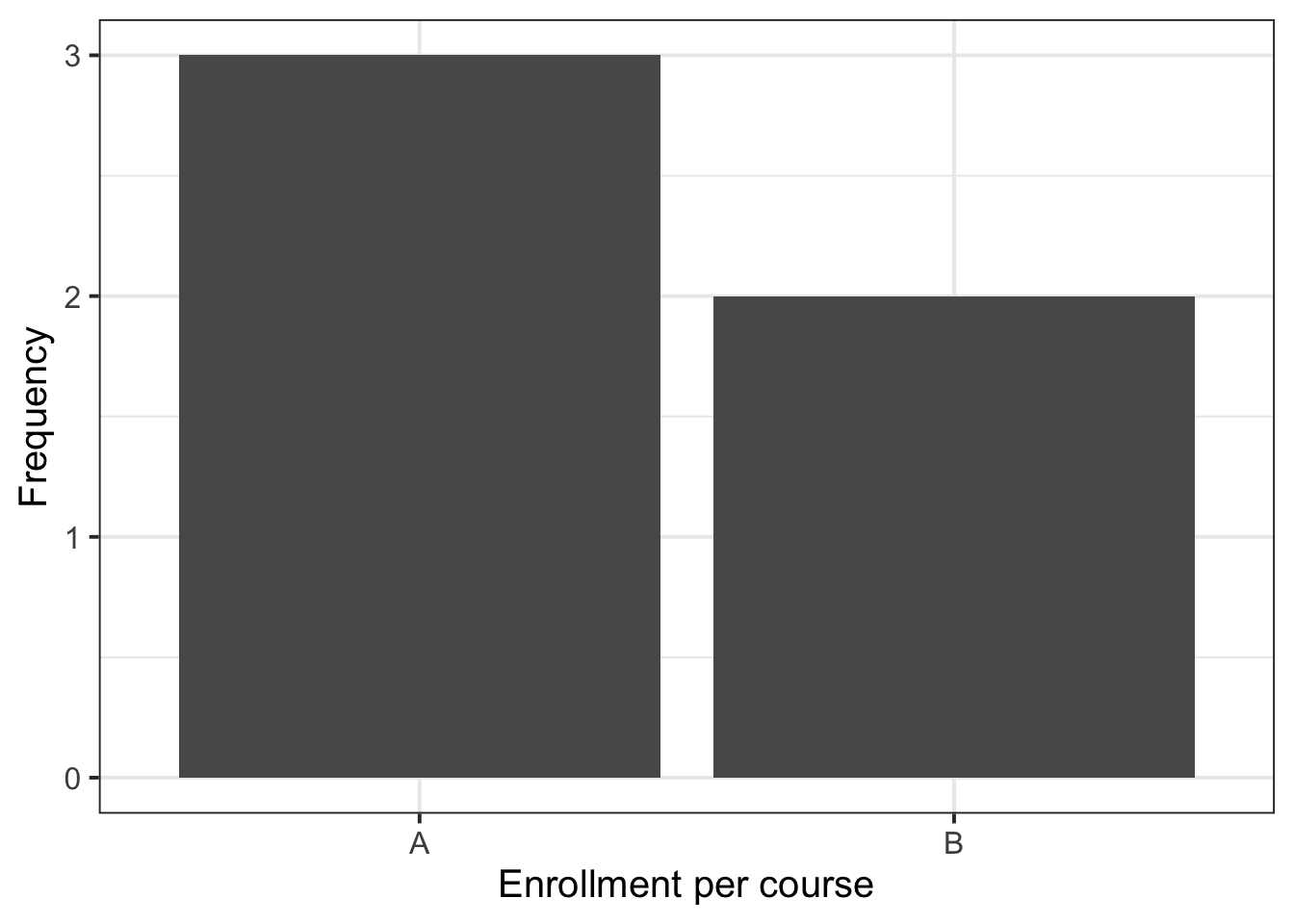
$ Server <fct> A, B, A, B, B, A, B, A, A, B, B, A, B, B, B, B, C, C, C, C, C, …
$ PctTip <dbl> 42.2, 19.4, 15.7, 20.8, 19.5, 13.4, 16.0, 12.4, 12.7, 10.7, 11.…