Throughout the report we used a significance level \(\alpha\) of 5%.
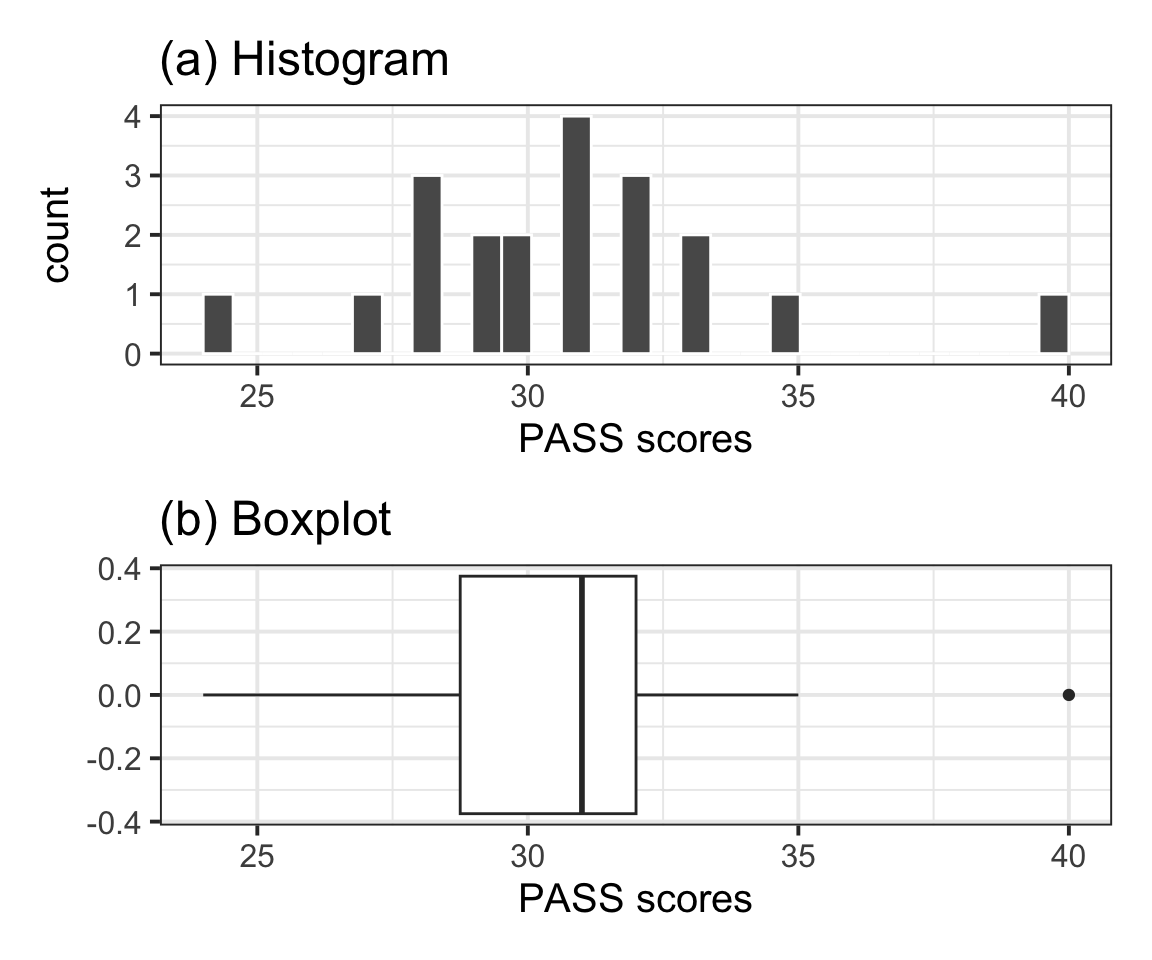
The distribution of PASS scores, as shown in Figure 1(a), is roughly bell shaped and does not have any impossible values. The outlier (40) depicted in the boxplot shown in Figure 1(b) is well within the range of plausible values for the PASS scale (0–90) and as such was not removed for the analysis.
Table 1: Descriptive statistics for PASS scores
| 20 |
24 |
40 |
30.7 |
3.31 |
Table 1 displays summary statistics for the PASS scores in the sample of Edinburgh University students. From the sample data we obtain an average procrastination score of \(M = 30.7\), 95% CI [29.15, 32.25]. Hence, we are 95% confident that a Edinburgh University student will have a procrastination score between 29.15 and 32.25, which is between 0.75 and 3.85 lower than the average score of 33 reported by Solomon & Rothblum.
To investigate whether the mean PASS scores of all Edinburgh University students, \(\mu\) say, differs from the Solomon & Rothblum reported average of 33, we performed a one sample t-test of \(H_0 : \mu = 33\) against \(H_1 : \mu \neq 33\). The sample data provided very strong evidence against the null hypothesis and in favour of the alternative one that the mean procrastination score of Edinburgh University students is significantly different from the Solomon & Rothblum reported average of 33: \(t(19) = -3.11, p = .006\), two-sided. The size of the effect was also found to be medium to large \((D = -0.69)\).
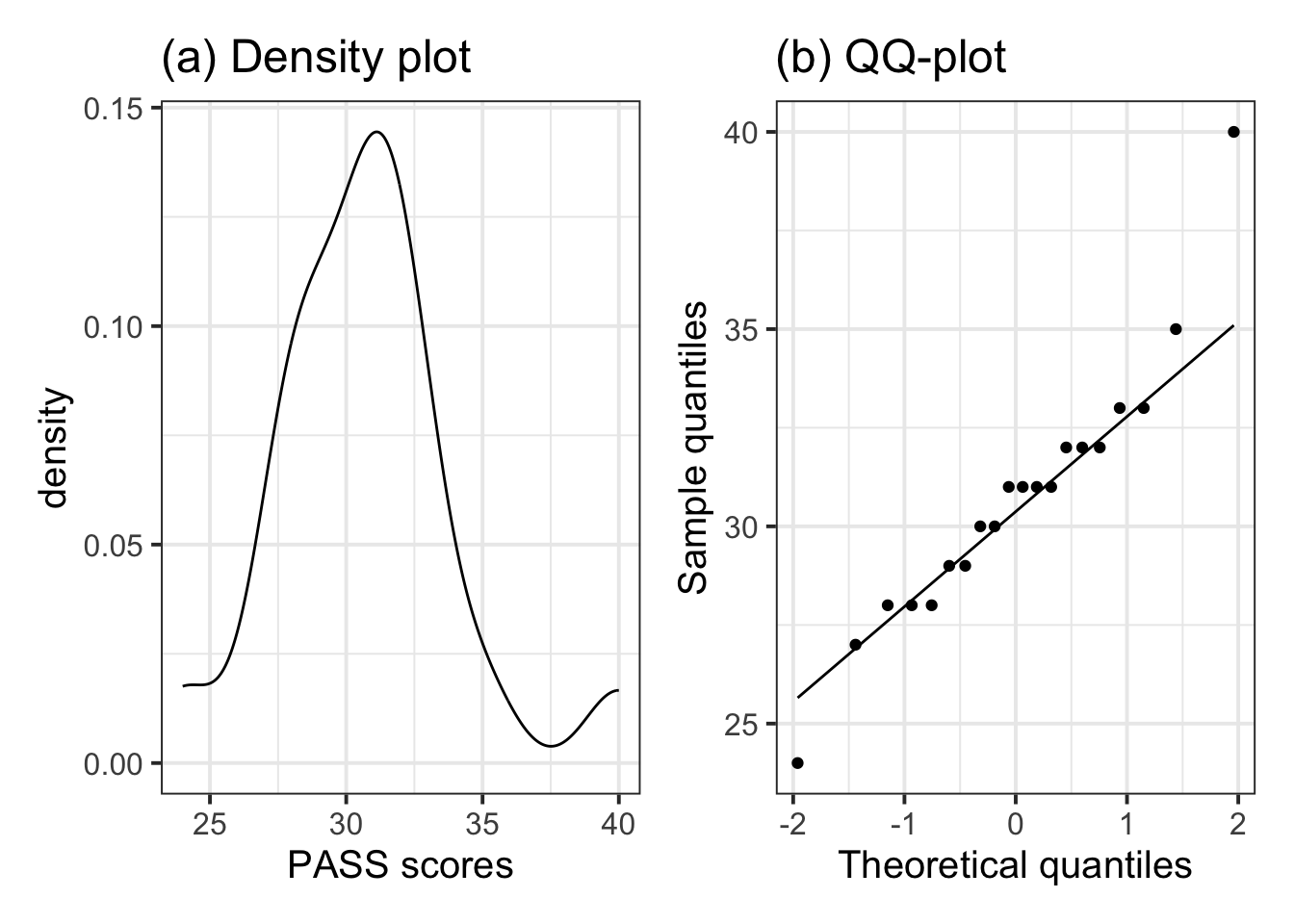
The sample data did not show violations of the assumptions required for the t-test results to be valid. Specifically, the data were collected on a random sample of students from Edinburgh University, hence independence was met. Figure 2(a) shows that the distribution of PASS scores is roughly bell-shaped, with a single mode and as such does not raise any concerns of violations of normality. Similarly, the QQ-plot in Figure 2(b) shows agreement between the sample and theoretical quantiles, as they almost all fall on the line. We also performed a Shapiro-Wilk test against the null hypothesis of normality of the population data: \(W = 0.94\), \(p = .20\). The sample data did not provide sufficient evidence at the 5% level to reject the null hypothesis that the population data follow a normal distribution.