Recap of multilevel models
Do children scores in maths improve more in school 2020 vs school 2040?
Consider the following data, representing longitudinal measurements on 10 students from an urban public primary school. The outcome of interest is mathematics achievement.
The data were collected at the end of first grade and annually thereafter up to sixth grade, but not all students have six observations. The variable year has been mean-centred to have mean 0 so that results will have as baseline the average.
How many students in each school?
## schoolid
## 2020 2040 Sum
## 21 21 42
We have 42 students, 21 in school with id 2020 and 21 in school with id 2040:
The number of observations per child are as follows.
table(data$childid)
##
## 253404261 253413681 270199271 273026452 273030991 273059461 278058841 285939962
## 6 3 3 3 5 5 5 3
## 288699161 289970511 292017571 292020281 292020361 292025081 292026211 292027291
## 5 5 3 6 6 5 5 5
## 292027531 292028181 292028931 292029071 292029901 292033851 292772811 293550291
## 5 5 5 5 5 5 3 4
## 295341521 298046562 299680041 301853741 303652591 303653561 303654611 303658951
## 6 3 5 3 5 3 5 3
## 303660691 303662391 303663601 303668751 303671891 303672001 303672861 303673321
## 4 6 6 5 5 3 3 4
## 307407931 307694141
## 3 4
We can see that for some children we have fewer than the 6 observations: some have 3, 4, or 5.
School 2020
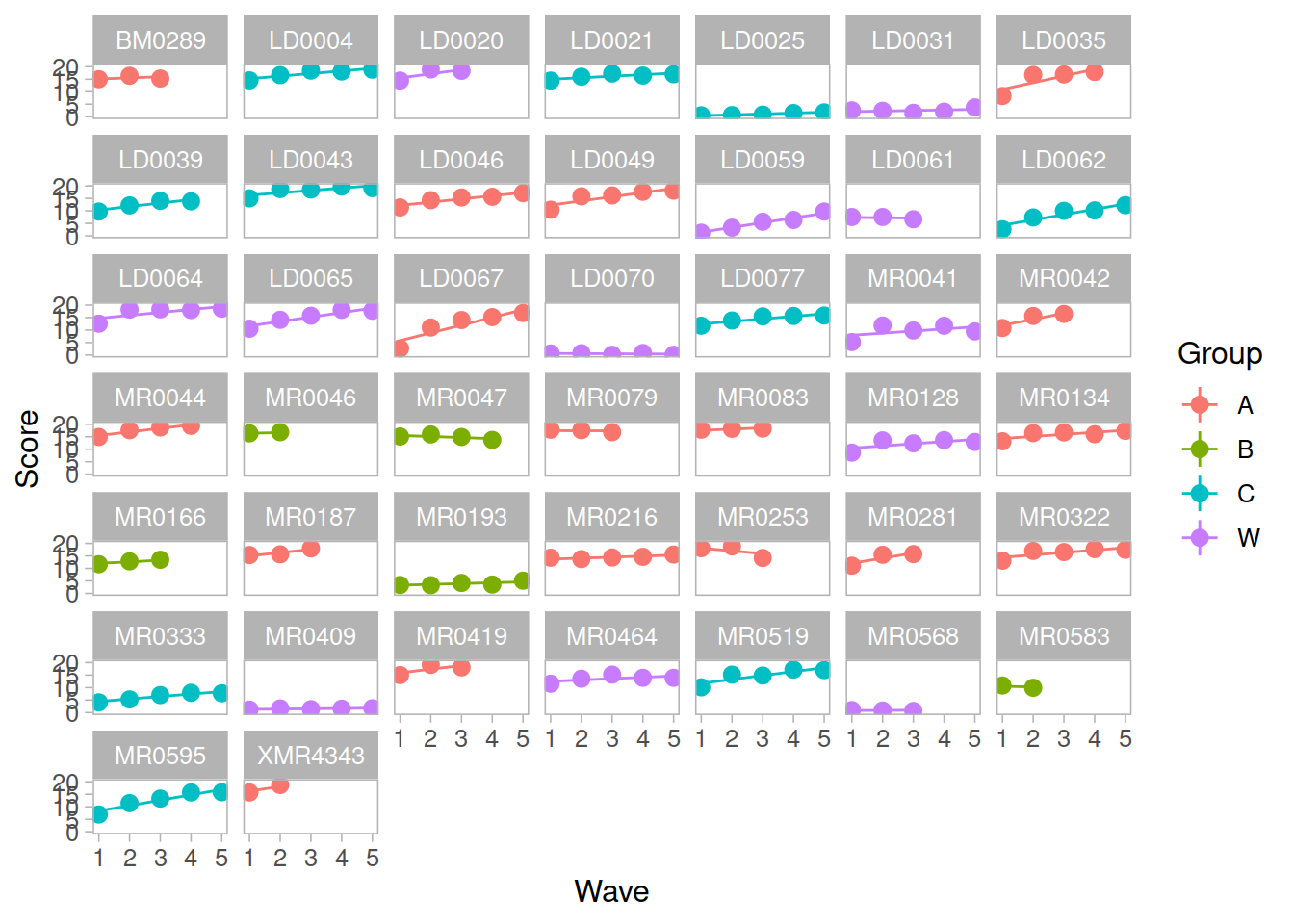
Let’s start by considering only the children in school 2020. The mathematics achievement over time is shown, for each student, in the plot below:
data2020 <- data %>%
filter(schoolid == 2020)
ggplot(data2020, aes(x = year, y = math)) +
geom_point() +
facet_wrap(~ childid, labeller = label_both) +
labs(x = "Year (mean centred)", y = "Maths achievement score")
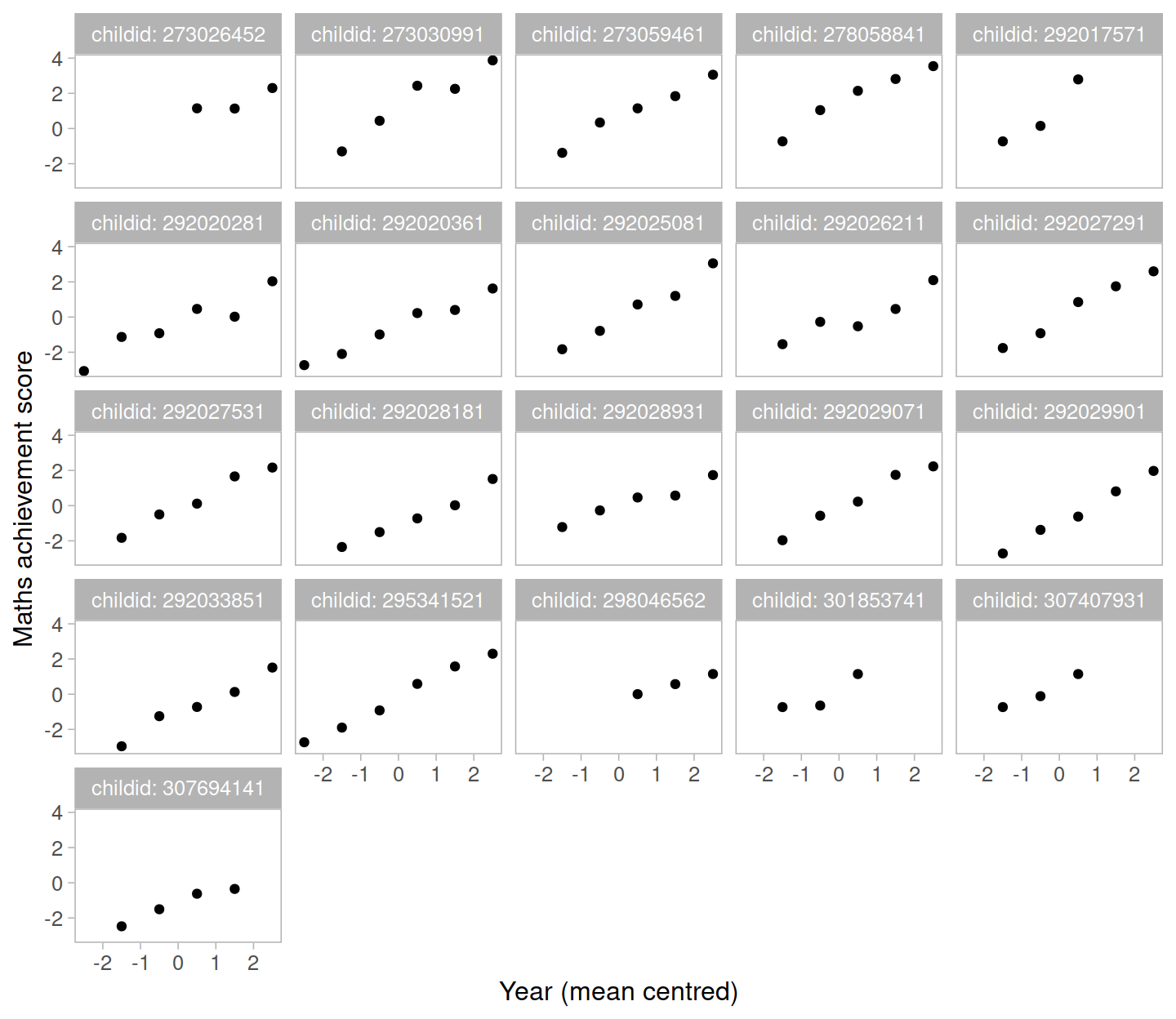
Clearly, the measurements of mathematics achievement related to each student are grouped data as they refer to the same entity.
If we were to ignore this grouping and consider all children as one single population, we would obtain misleading results.The observations for the same student are clearly correlated. Some students consistently have a much better performance than other students, perhaps due to underlying numerical skills.
A fundamental assumption of linear regression models is that the residuals, and hence the data too, should be uncorrelated. In this example this is not the case.
The following plot considers all data as a single population
ggplot(data2020, aes(x = year, y = math)) +
geom_point() +
geom_smooth(method = lm, se = FALSE) +
labs(x = "Year (mean centred)", y = "Maths achievement score")
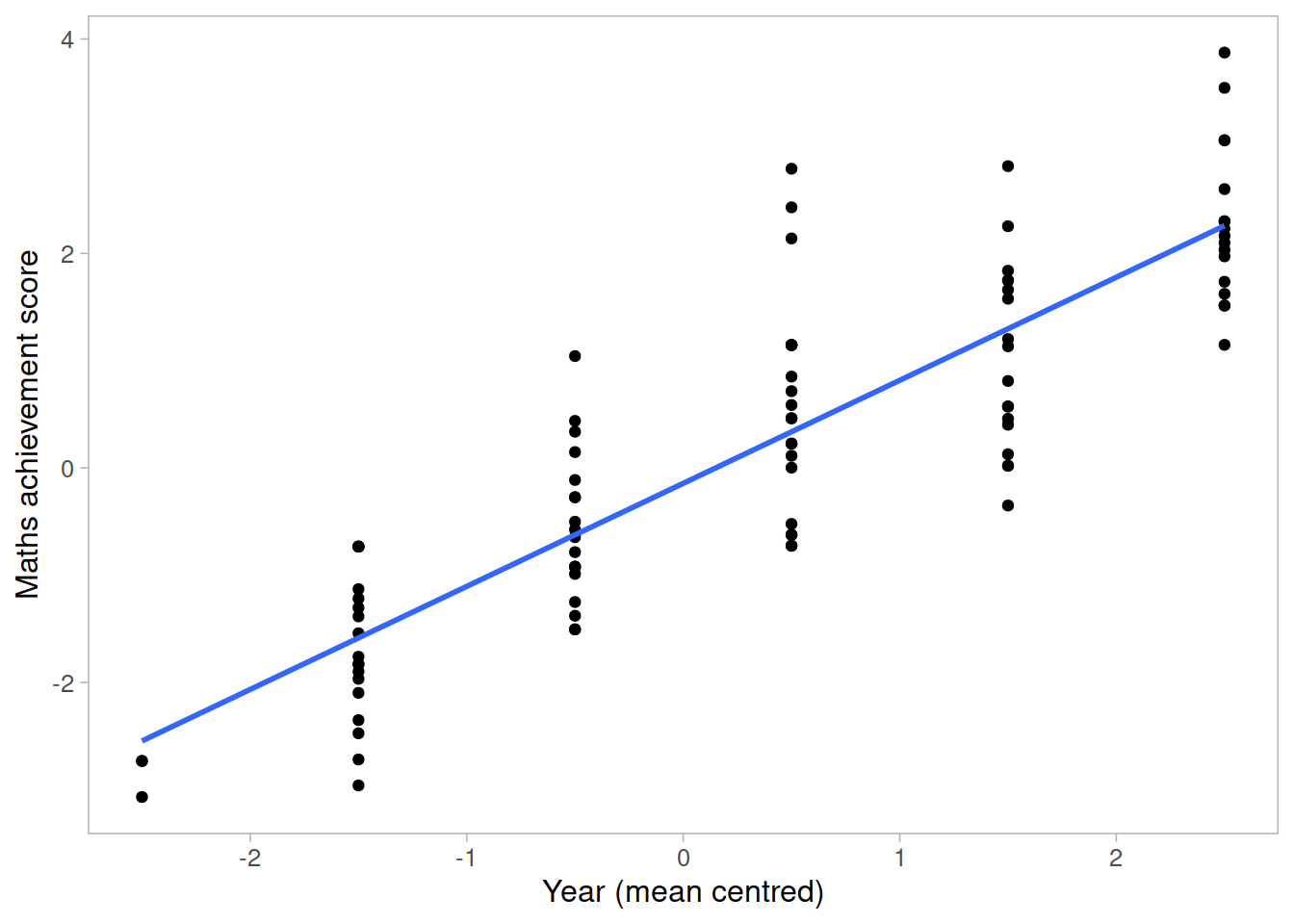
This is a simple linear regression model for the mathematics measurement of individual \(i\) on occasion \(j\):
\[
\text{math}_{ij} = \beta_0 + \beta_1 \ \text{year}_{ij} + \epsilon_{ij}
\]
where the subscript \(ij\) denotes the \(j\)th measurement from child \(i\).
Let’s fit this in R
m0 <- lm(math ~ year, data = data2020)
summary(m0)
##
## Call:
## lm(formula = math ~ year, data = data2020)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.6478 -0.6264 -0.1101 0.4543 2.4529
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.14323 0.08493 -1.687 0.095 .
## year 0.96072 0.05662 16.968 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.8126 on 95 degrees of freedom
## Multiple R-squared: 0.7519, Adjusted R-squared: 0.7493
## F-statistic: 287.9 on 1 and 95 DF, p-value: < 2.2e-16
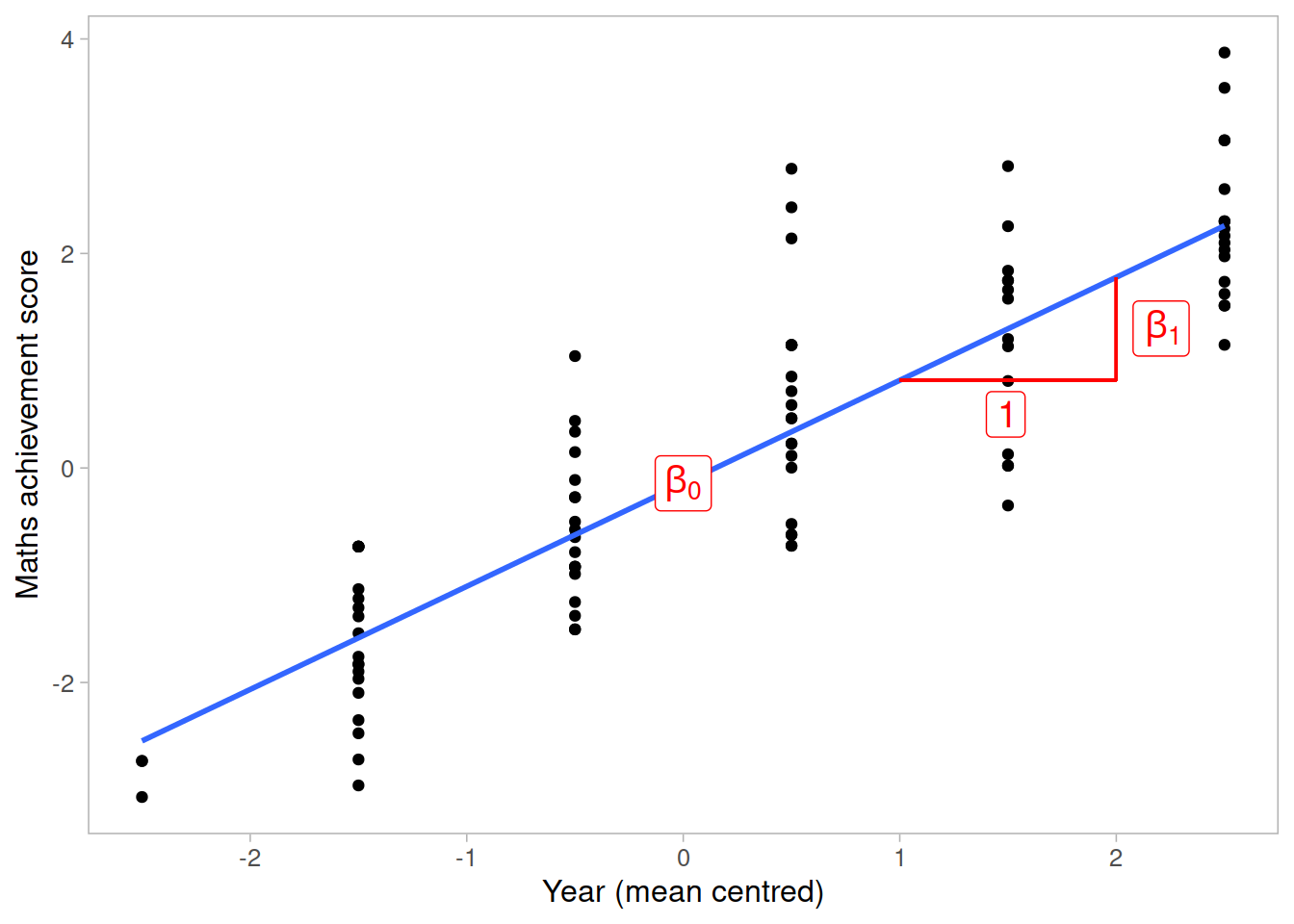
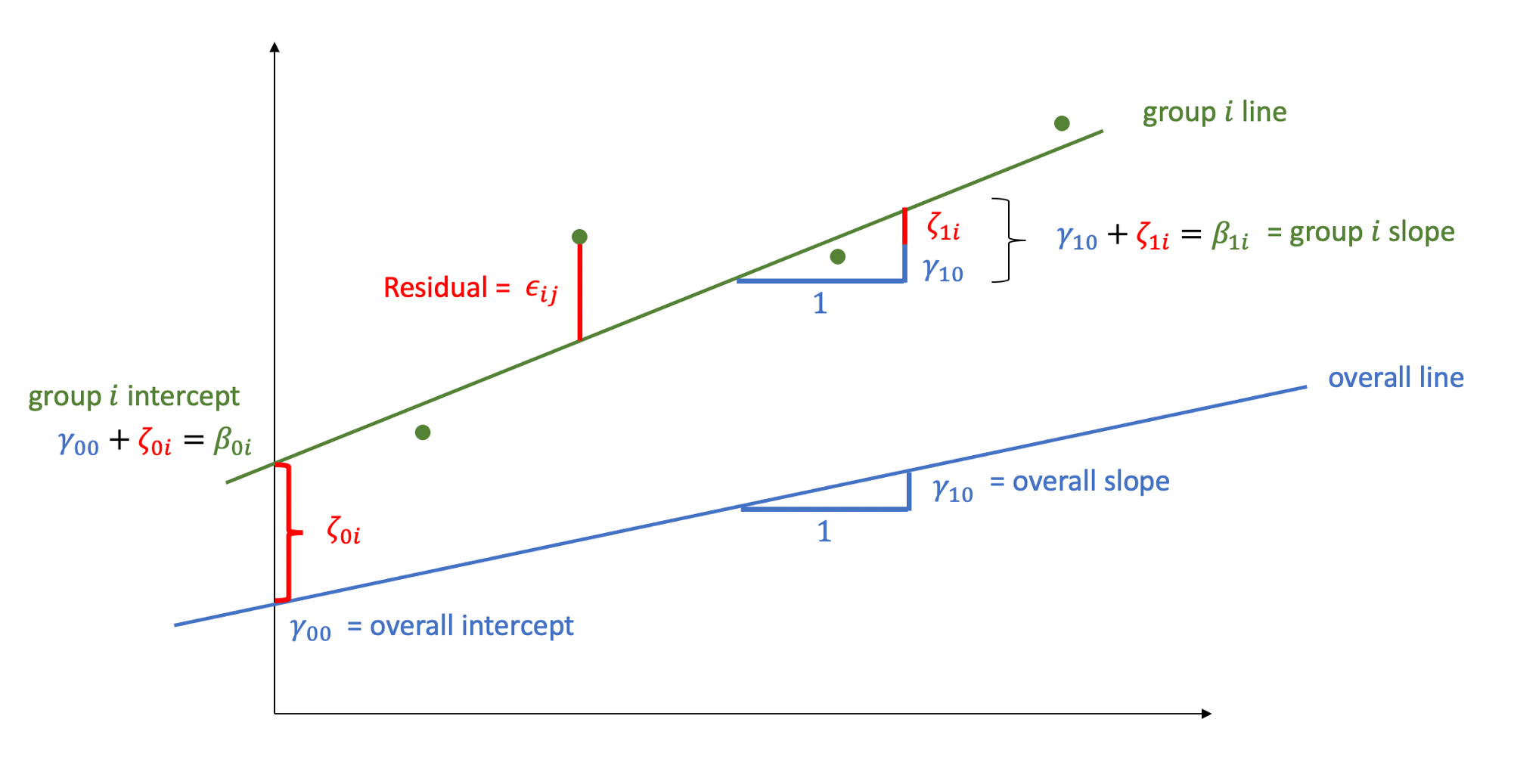
The intercept and slope of this model can be visually represented as:
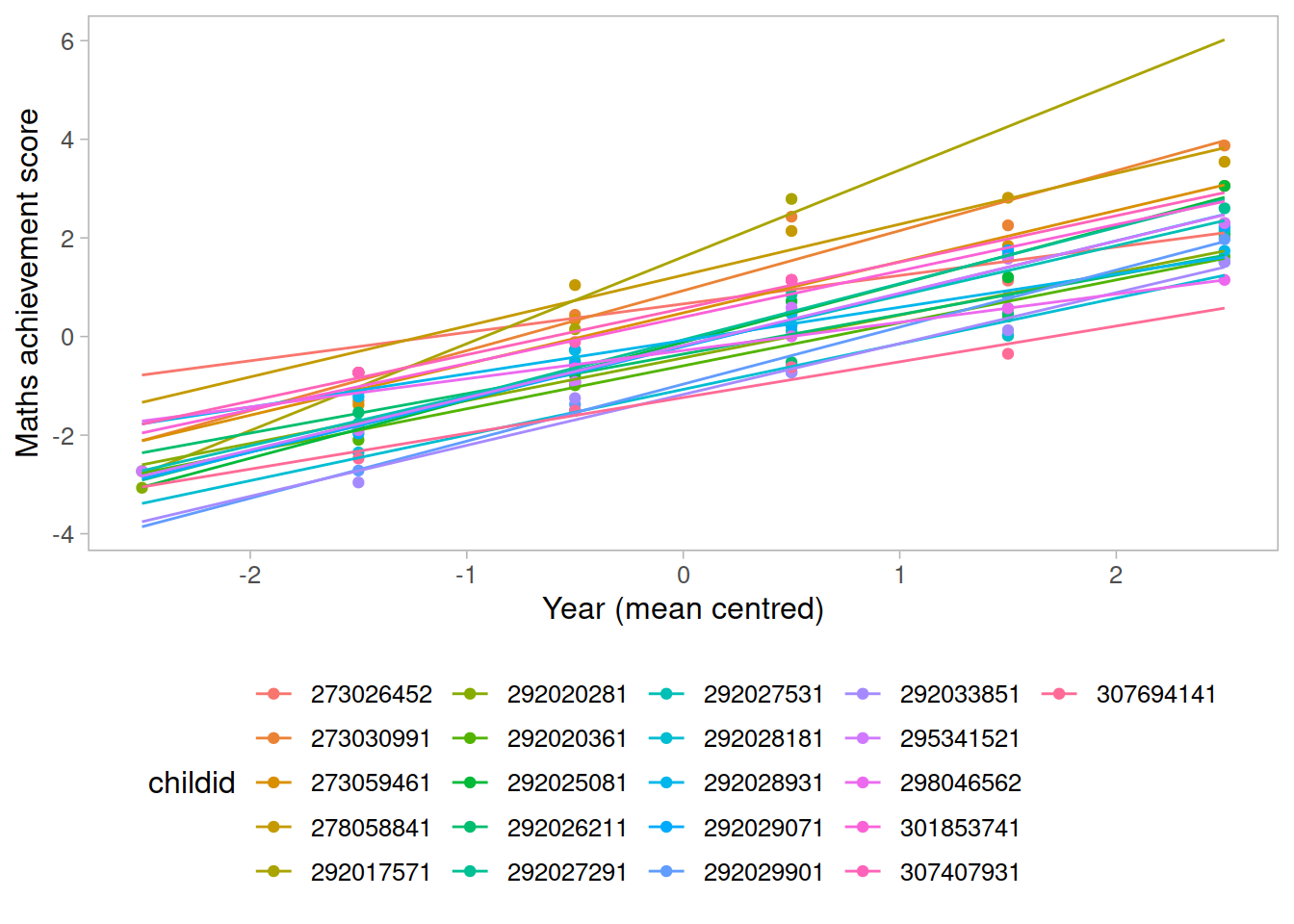
Random intercept and slopes
In reality, we see that each student has their own line, with a different intercept and slope.
In other words, they all have different values of maths achievement when year = 0 and they also differ in their learning rate.
ggplot(data2020, aes(x = year, y = math, color = childid)) +
geom_point() +
geom_smooth(method = lm, se = FALSE, fullrange = TRUE,
size = 0.5) +
labs(x = "Year (mean centred)", y = "Maths achievement score") +
theme(legend.position = 'bottom')
Let’s now write a model where each student has their own intercept and slope:
\[
\begin{aligned}
\text{math}_{ij}
&= \beta_{0i} + \beta_{1i} \ \text{year}_{ij} + \epsilon_{ij} \\
&= (\text{intercept for child } i) + (\text{slope for child } i) \ \text{year}_{ij} + \epsilon_{ij} \\
&= (\gamma_{00} + \zeta_{0i}) + (\gamma_{10} + \zeta_{1i}) \ \text{year}_{ij} + \epsilon_{ij}
\end{aligned}
\]
where
\(\beta_{0i}\) is the intercept of the line for child \(i\)
\(\beta_{1i}\) is the slope of the line for child \(i\)
\(\epsilon_{ij}\) are the deviations of each child’s measurement \(\text{math}_{ij}\) from the line of child \(i\)
We can think each child-specific intercept (respectively, slope) as being made up of two components: an “overall” intercept \(\gamma_{00}\) (slope \(\gamma_{10}\)) and a child-specific deviation from the overall intercept \(\zeta_{0i}\) (slope \(\zeta_{1i}\)):
FACT
Deviations from the mean average to zero (and sum to zero too!)
As you know, deviations from the mean average to 0.
This holds for the errors \(\epsilon_{ij}\), as well as the deviations \(\zeta_{0i}\) from the overall intercept, and the deviations \(\zeta_{1i}\) from the overall slope.
Think of data \(y_1, ..., y_n\) and their mean \(\bar y\). The average of the deviations from the mean is
\[
\begin{aligned}
\frac{\sum_i (y_i - \bar y)}{n}
= \frac{\sum_i y_i }{n} - \frac{\sum_i \bar y}{n}
= \bar y - \frac{n * \bar y}{n}
= \bar y - \bar y
= 0
\end{aligned}
\]
The child-specific deviations \(\zeta_{0i}\) from the overall intercept are normally distributed with mean \(0\) and variance \(\sigma_0^2\). Similarly, the deviations \(\zeta_{1i}\) of the slope for child \(i\) from the overall slope come from a normal distribution with mean \(0\) and variance \(\sigma_1^2\). The correlation between random intercepts and slopes is \(\rho = \text{Cor}(\zeta_{0i}, \zeta_{1i}) = \frac{\sigma_{01}}{\sigma_0 \sigma_1}\):
\[
\begin{bmatrix} \zeta_{0i} \\ \zeta_{1i} \end{bmatrix}
\sim N
\left(
\begin{bmatrix} 0 \\ 0 \end{bmatrix},
\begin{bmatrix}
\sigma_0^2 & \rho \sigma_0 \sigma_1 \\
\rho \sigma_0 \sigma_1 & \sigma_1^2
\end{bmatrix}
\right)
\]
The random errors, independently from the random effects, are distributed
\[
\epsilon_{ij} \sim N(0, \sigma_\epsilon^2)
\]
This is fitted using lmer():
library(lme4)
library(lmerTest)
m1 <- lmer(math ~ 1 + year + (1 + year | childid), data = data2020)
summary(m1)
## Linear mixed model fit by REML. t-tests use Satterthwaite's method [
## lmerModLmerTest]
## Formula: math ~ 1 + year + (1 + year | childid)
## Data: data2020
##
## REML criterion at convergence: 166.6
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.3119 -0.6125 -0.0726 0.6002 2.4197
##
## Random effects:
## Groups Name Variance Std.Dev. Corr
## childid (Intercept) 0.50065 0.7076
## year 0.01131 0.1063 0.82
## Residual 0.16345 0.4043
## Number of obs: 97, groups: childid, 21
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) -0.1091 0.1605 19.7831 -0.68 0.505
## year 0.9940 0.0381 13.1895 26.09 9.71e-13 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr)
## year 0.433
The summary of the lmer output returns estimated values for
Fixed effects:
- \(\widehat \gamma_{00} = -0.109\)
- \(\widehat \gamma_{10} = 0.994\)
Variability of random effects:
- \(\widehat \sigma_{0} = 0.708\)
- \(\widehat \sigma_{1} = 0.106\)
Correlation of random effects:
- \(\widehat \rho = 0.816\)
Residuals:
- \(\widehat \sigma_\epsilon = 0.404\)
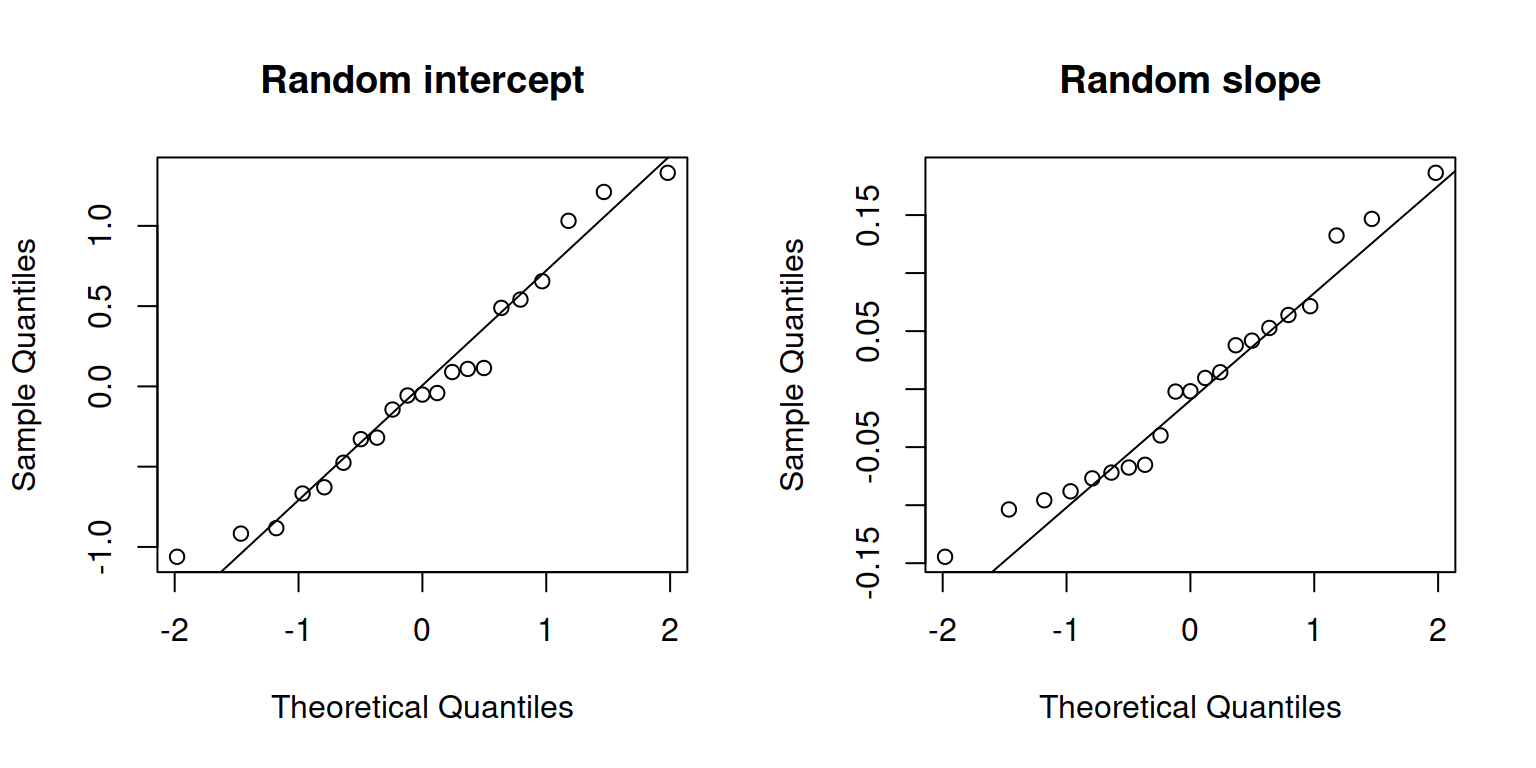
Check normality of random effects:
par(mfrow = c(1,2))
qqnorm(ranef(m1)$childid[, 1], main = "Random intercept")
qqline(ranef(m1)$childid[, 1])
qqnorm(ranef(m1)$childid[, 2], main = "Random slope")
qqline(ranef(m1)$childid[, 2])
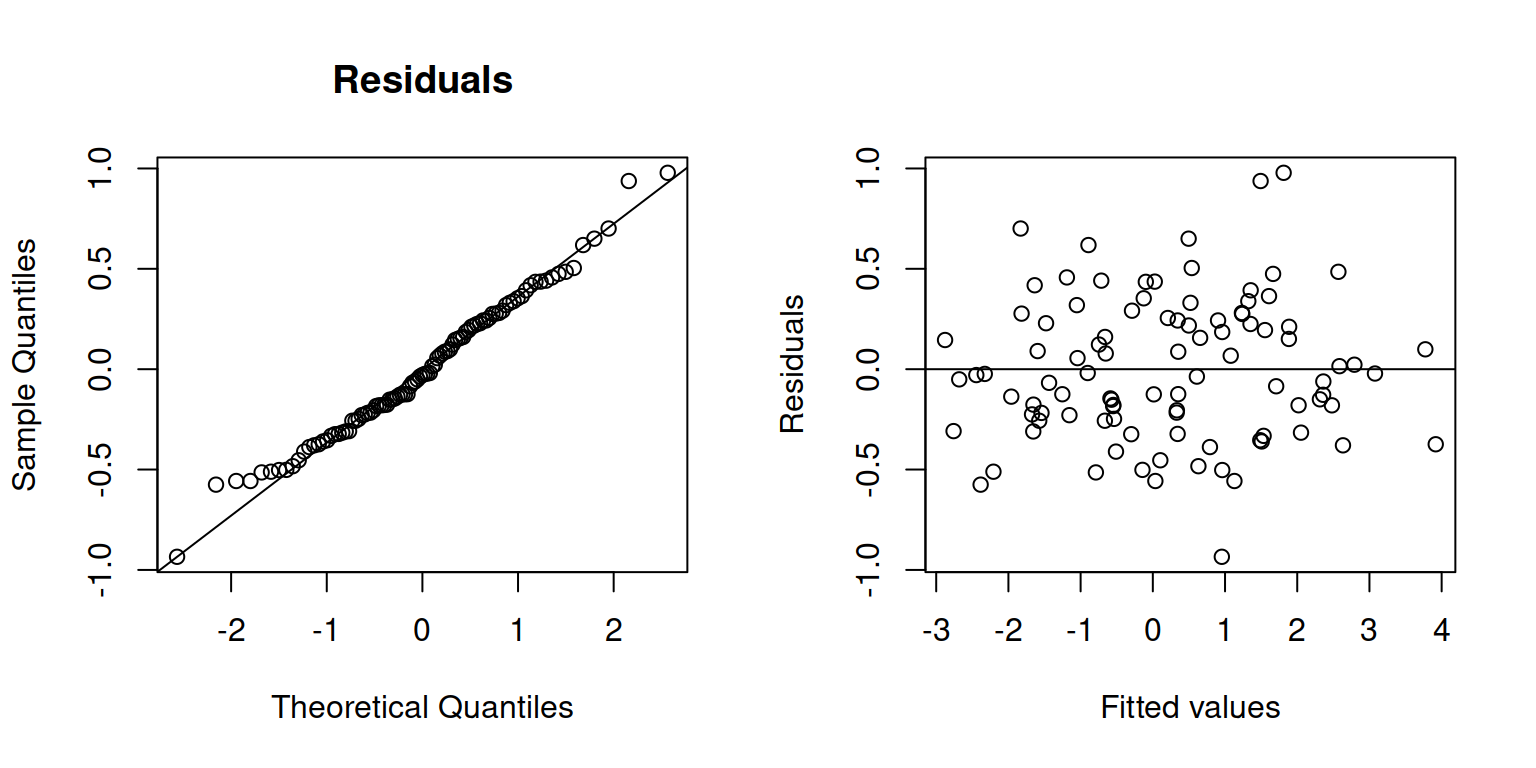
Check normality and independence of errors:
par(mfrow = c(1,2))
qqnorm(resid(m1), main = "Residuals")
qqline(resid(m1))
plot(fitted(m1), resid(m1), ylab = "Residuals", xlab = "Fitted values")
abline(h=0)
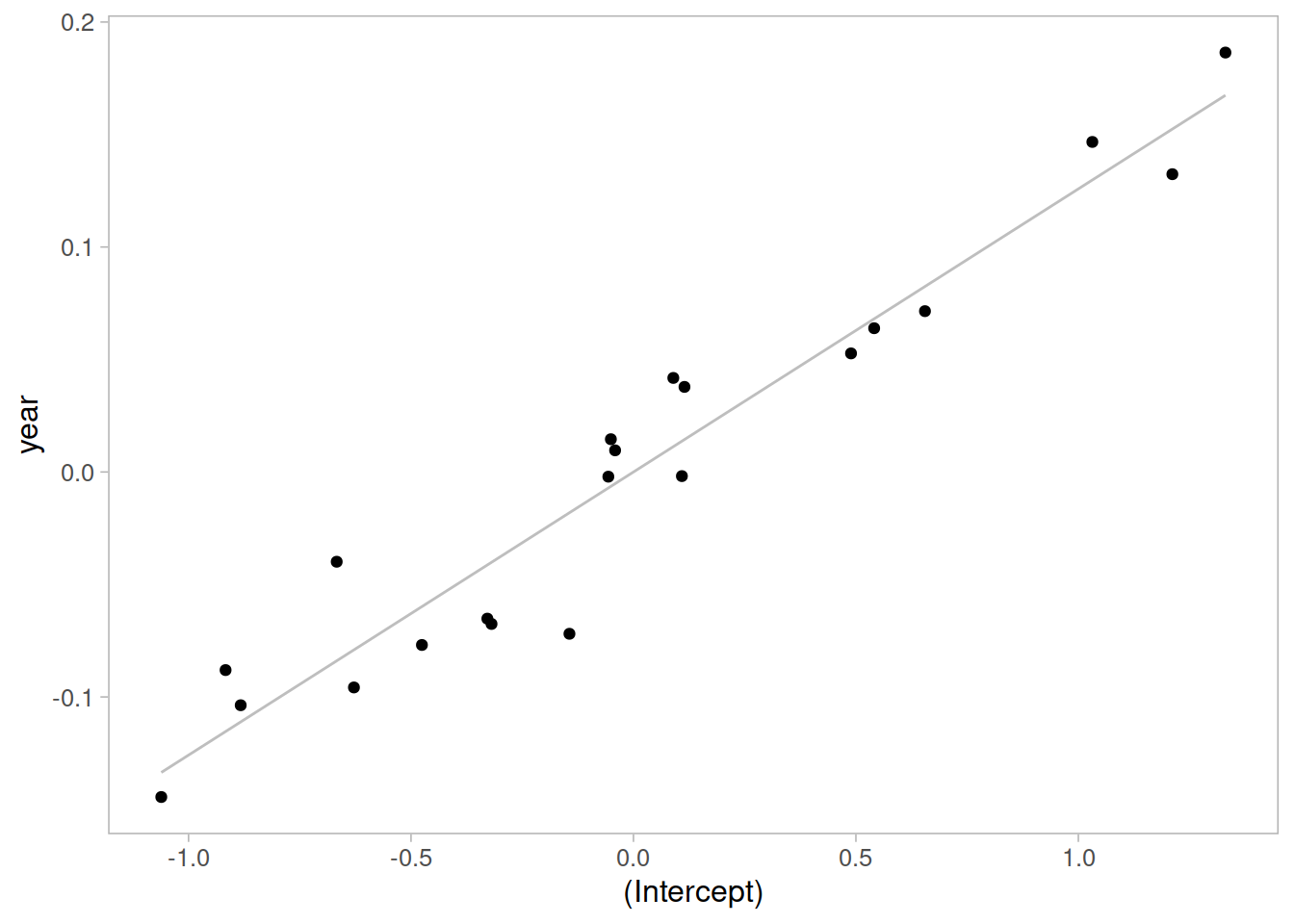
Visually inspect the correlation between the random intercept and slopes:
ggplot(ranef(m1)$childid,
aes(x = `(Intercept)`, y = year)) +
geom_smooth(method = lm, se = FALSE,
color = 'gray', size = 0.5) +
geom_point()
Flashcards: lm to lmer
In a simple linear regression, there is only considered to be one source of random variability: any variability left unexplained by a set of predictors (which are modelled as fixed estimates) is captured in the model residuals.
Multi-level (or ‘mixed-effects’) approaches involve modelling more than one source of random variability - as well as variance resulting from taking a random sample of observations, we can identify random variability across different groups of observations. For example, if we are studying a patient population in a hospital, we would expect there to be variability across the our sample of patients, but also across the doctors who treat them.
We can account for this variability by allowing the outcome to be lower/higher for each group (a random intercept) and by allowing the estimated effect of a predictor vary across groups (random slopes).
Before you expand each of the boxes below, think about how comfortable you feel with each concept.
This content is very cumulative, which means often going back to try to isolate the place which we need to focus efforts in learning.
Simple Linear Regression
Formula:
- \(y_i = \beta_0 + \beta_1 x_i + \epsilon_i\)
R command:
lm(outcome ~ predictor, data = dataframe)
Note: this is the same as lm(outcome ~ 1 + predictor, data = dataframe). The 1 + is always there unless we specify otherwise (e.g., by using 0 +).
Clustered (multi-level) data
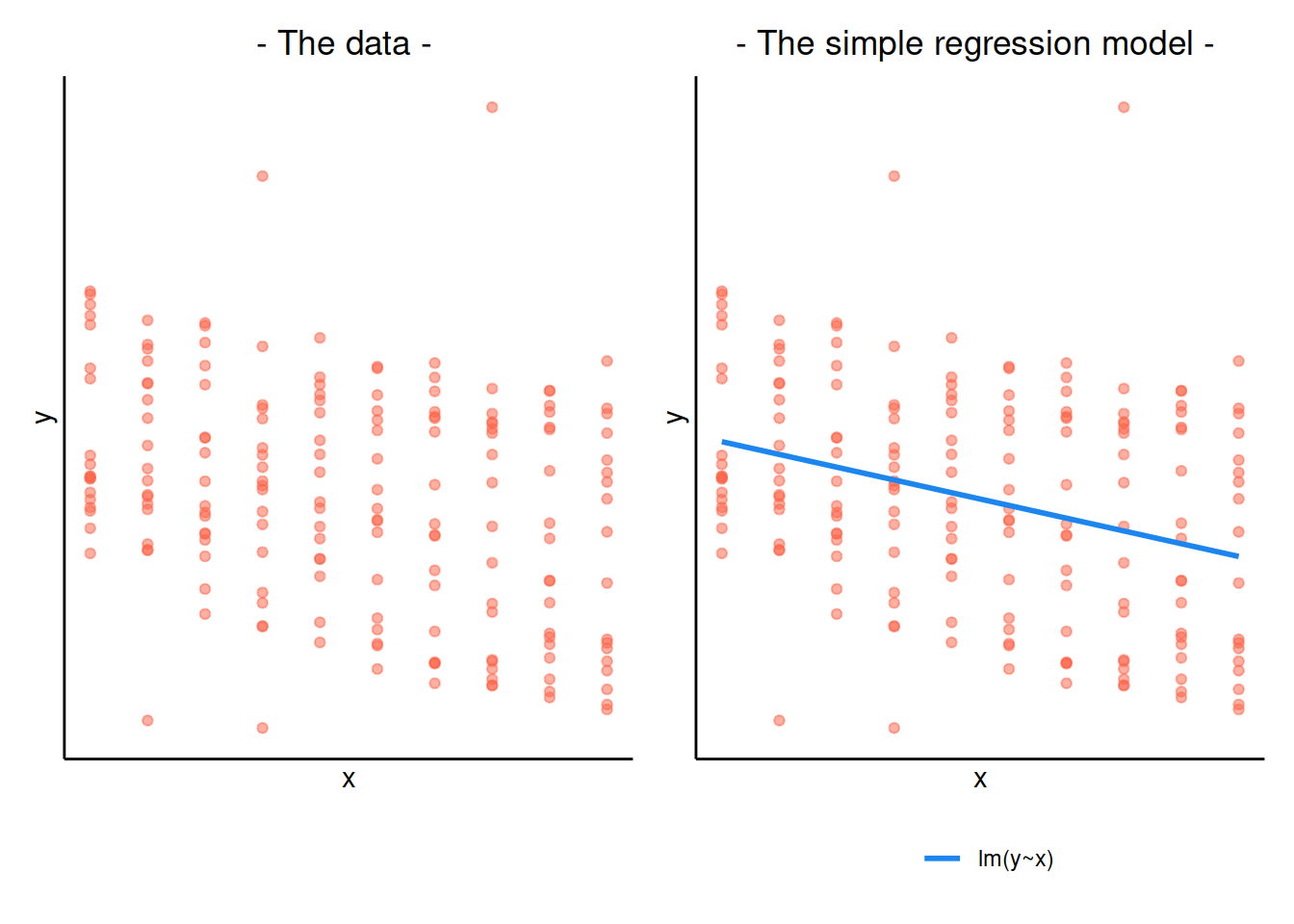
When our data is clustered (or ‘grouped’) such that datapoints are no longer independent, but belong to some grouping such as that of multiple observations from the same subject, we have multiple sources of random variability. A simple regression does not capture this.
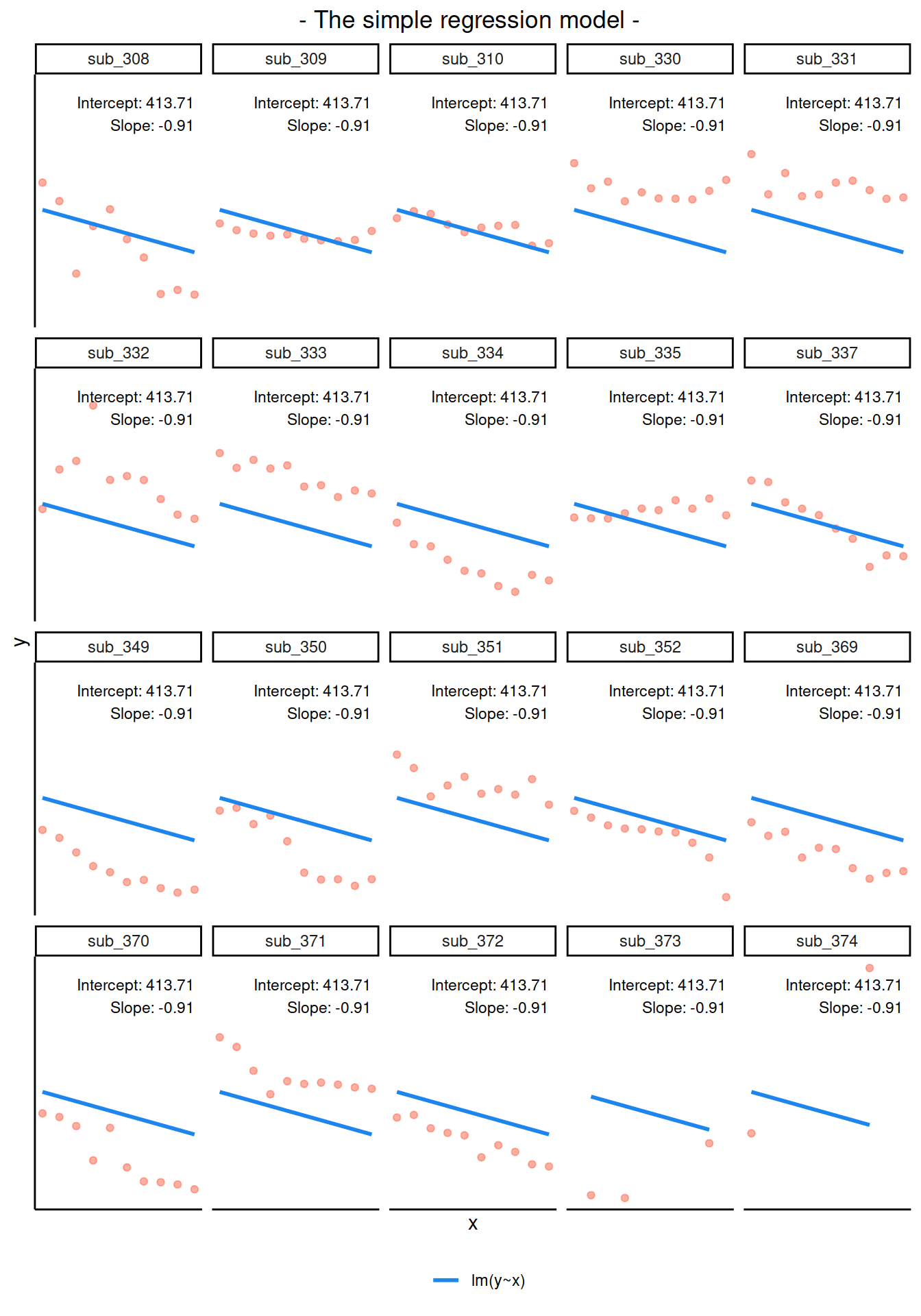
If we separate out our data to show an individual plot for each subject, we can see how the fitted regression line from lm() is assumed to be the same for each subject.
Random intercepts
By including a random-intercept term, we are letting our model estimate random variability around an average parameter (represented by the fixed effects) for the clusters.
Formula:
Level 1:
- \(y_{ij} = \beta_{0i} + \beta_{1i} x_{ij} + \epsilon_{ij}\)
Level 2:
- \(\beta_{0i} = \gamma_{00} + \zeta_{0i}\)
Where the expected values of \(\zeta_{0}\), and \(\epsilon\) are 0, and their variances are \(\sigma_{0}^2\) and \(\sigma_\epsilon^2\) respectively. We will further assume that these are normally distributed.
We can now see that the intercept estimate \(\beta_{0i}\) for a particular group \(i\) is represented by the combination of a mean estimate for the parameter (\(\gamma_{00}\)) and a random effect for that group (\(\zeta_{0i}\)).
R command:
lmer(outcome ~ predictor + (1 | grouping), data = dataframe)
Notice how the fitted line of the random intercept model has an adjustment for each subject.
Each subject’s line has been moved up or down accordingly.
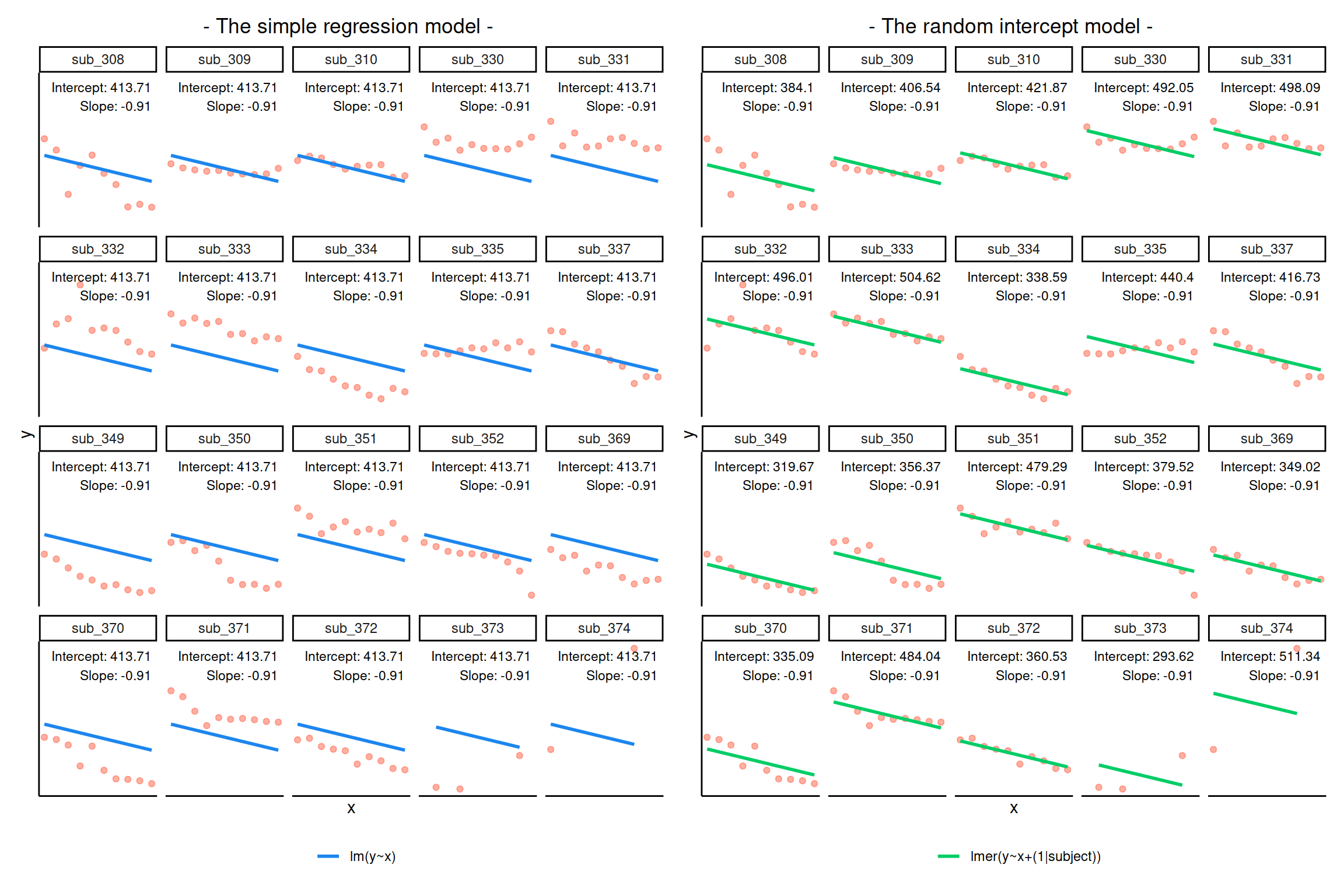
Shrinkage
If you think about it, we might have done a similar thing with the tools we already had at our disposal, by using lm(y~x+subject).
This would give us a coefficient for the difference between each subject and the reference level intercept, or we could extend this to lm(y~x*subject) to give us an adjustment to the slope for each subject.
However, the estimate of these models will be slightly different:
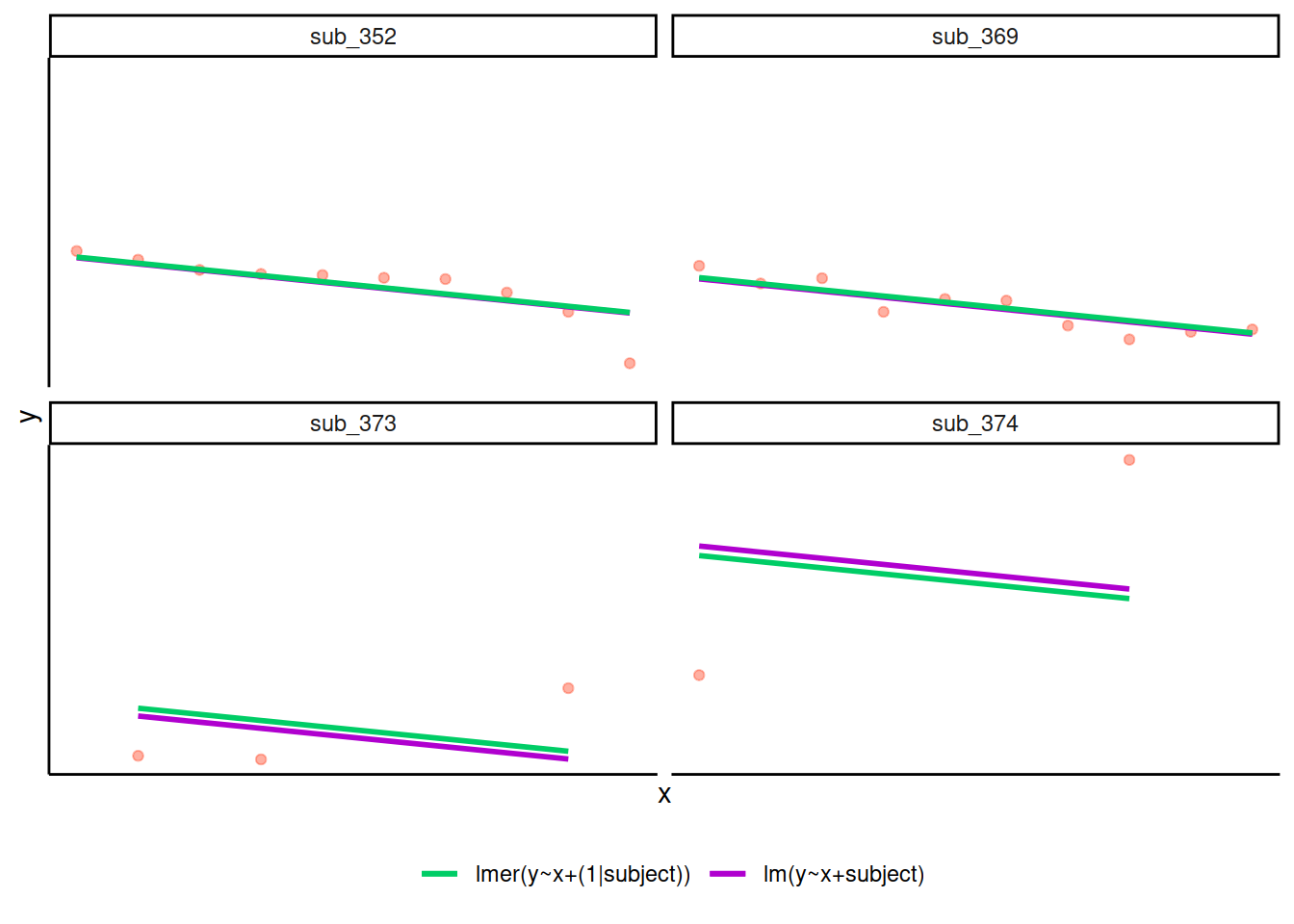
Why? One of the benefits of multi-level models is that our cluster-level estimates are shrunk towards the average depending on a) the level of across-cluster variation and b) the number of datapoints in clusters.
Random slopes
Formula:
Level 1:
- \(y_{ij} = \beta_{0i} + \beta_{1i} x_{ij} + \epsilon_{ij}\)
Level 2:
- \(\beta_{0i} = \gamma_{00} + \zeta_{0i}\)
- \(\beta_{1i} = \gamma_{10} + \zeta_{1i}\)
Where the expected values of \(\zeta_0\), \(\zeta_1\), and \(\epsilon\) are 0, and their variances are \(\sigma_{0}^2\), \(\sigma_{1}^2\), \(\sigma_\epsilon^2\) respectively. We will further assume that these are normally distributed.
As with the intercept \(\beta_{0i}\), the slope of the predictor \(\beta_{1i}\) is now modelled by a mean \(\gamma_{10}\) and a random effect for each group (\(\zeta_{1i}\)).
R command:
lmer(outcome ~ predictor + (1 + predictor | grouping), data = dataframe)
Note: this is the same as lmer(outcome ~ predictor + (predictor | grouping), data = dataframe) . Like in the fixed-effects part, the 1 + is assumed in the random-effects part.
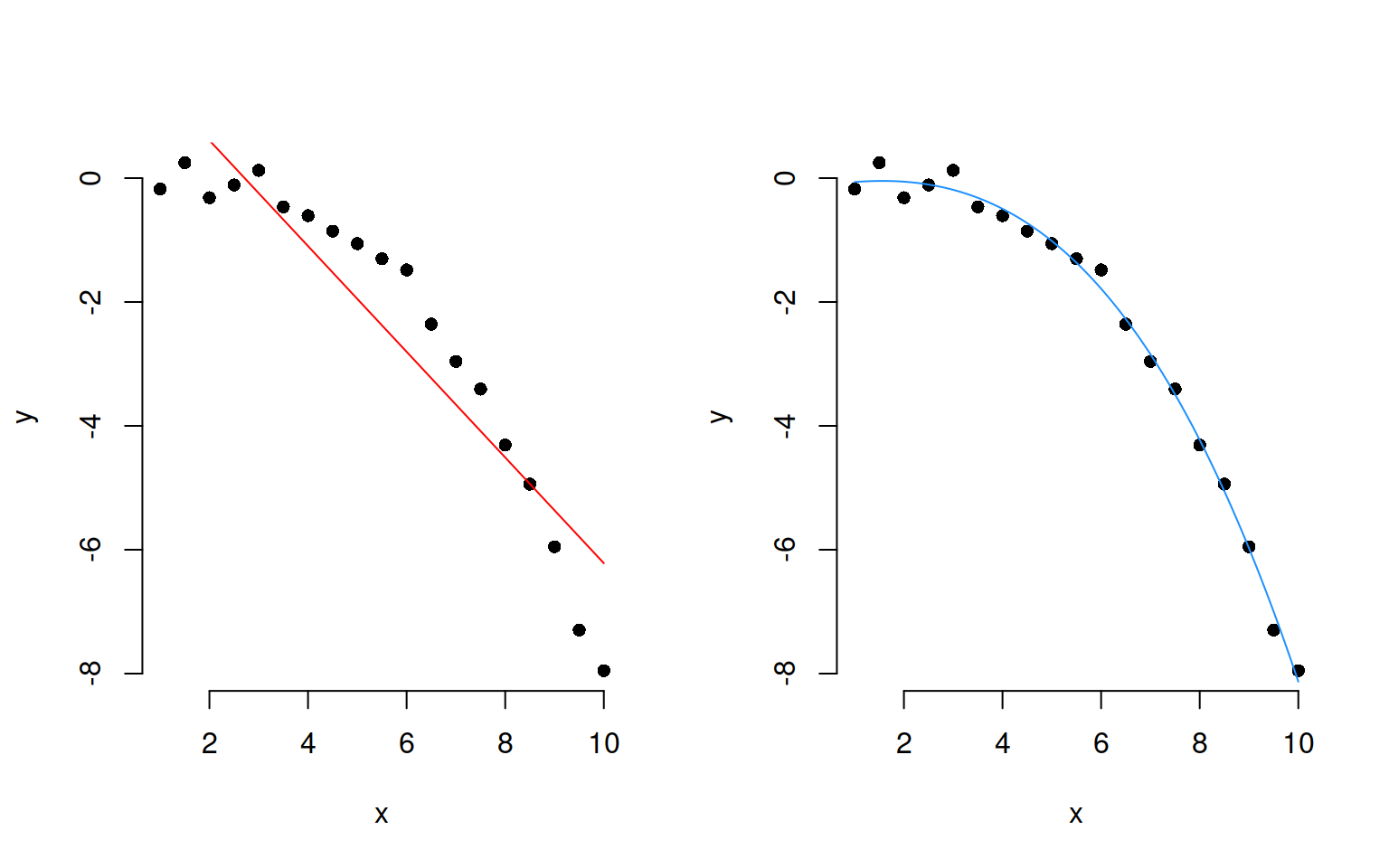
Polynomials!
Sometimes, data have a clear non-linear pattern, such as a curvilinear trend. In such case, it is reasonable to try modelling the outcome not as a linear function of the variable, but as a curvilinear function of it.
The following plots show data (as black dots) where the outcome \(y\) has a nonlinear and decreasing dependence on \(x\). That is, as \(x\) varies from 1 to 10, the outcome \(y\) decreases in a non-linear fashion.
Superimposed to the same data, you can see a linear fit (red line) and a cubic fit (blue).
The residuals corresponding to each fit are:
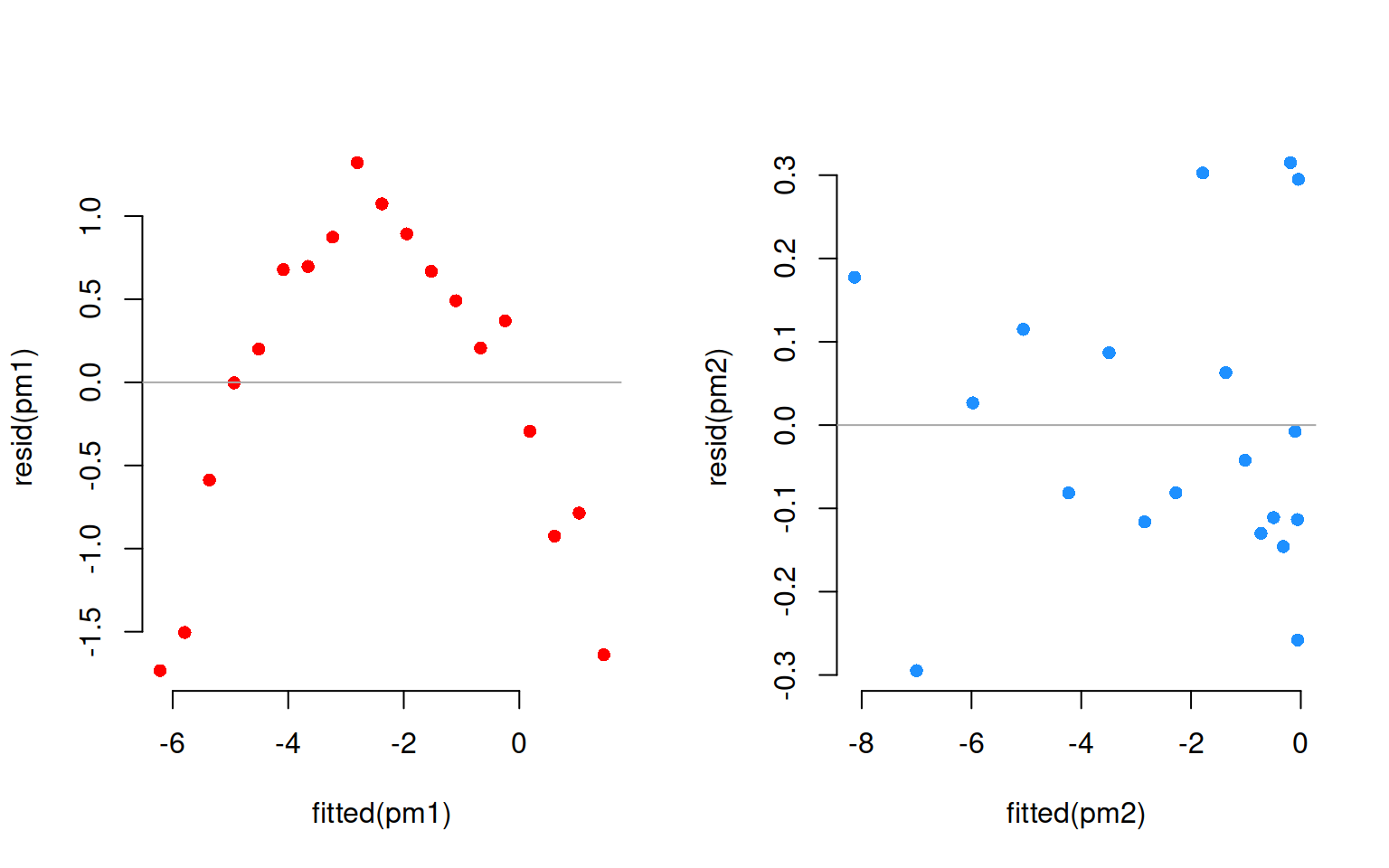
Clearly, a linear fit doesn’t capture the real trend in the data, and any leftover systematic pattern that the model doesn’t explicity account for always ends up in the residuals as the red points show.
On the other hand, once we account for the nonlinear trend, that systematic pattern in the residuals disappears.
The secret is to use instead of \(x\) as a predictor, the corresponding polynomial up to a specific order:
\[
y = \beta_0 + \beta_1 x + \beta_2 x^2 + \beta_3 x^3 + \epsilon
\]
Consider the following example data. You can add polynomials up to order 3, for example, of a predictor “time” by saying:
## # A tibble: 5 x 3
## subject reaction time
## <dbl> <dbl> <int>
## 1 1 0.428 1
## 2 1 0.427 2
## 3 1 0.211 3
## 4 1 0.585 4
## 5 1 0.127 5
source("https://uoepsy.github.io/msmr/functions/code_poly.R")
code_poly(df, predictor = 'time', poly.order = 3, draw.poly = FALSE)
## # A tibble: 5 x 7
## subject reaction time time.Index poly1 poly2 poly3
## <dbl> <dbl> <int> <dbl> <dbl> <dbl> <dbl>
## 1 1 0.428 1 1 -0.632 0.535 -3.16e- 1
## 2 1 0.427 2 2 -0.316 -0.267 6.32e- 1
## 3 1 0.211 3 3 0 -0.535 -4.10e-16
## 4 1 0.585 4 4 0.316 -0.267 -6.32e- 1
## 5 1 0.127 5 5 0.632 0.535 3.16e- 1
and use those terms when specifying your linear model, for example:
lmer(reaction ~ poly1 + poly2 + poly3 + (1 | subject))
Fixed effects
We can extract the fixed effects using the fixef() function:
These are the overall intercept and slope.
fixef(random_slopes_model)
## (Intercept) x1
## 405.7897675 -0.6722654
Random effects
The plots below show the fitted values for each subject from each model that we have gone through in these expandable boxes (simple linear regression, random intercept, and random intercept & slope):
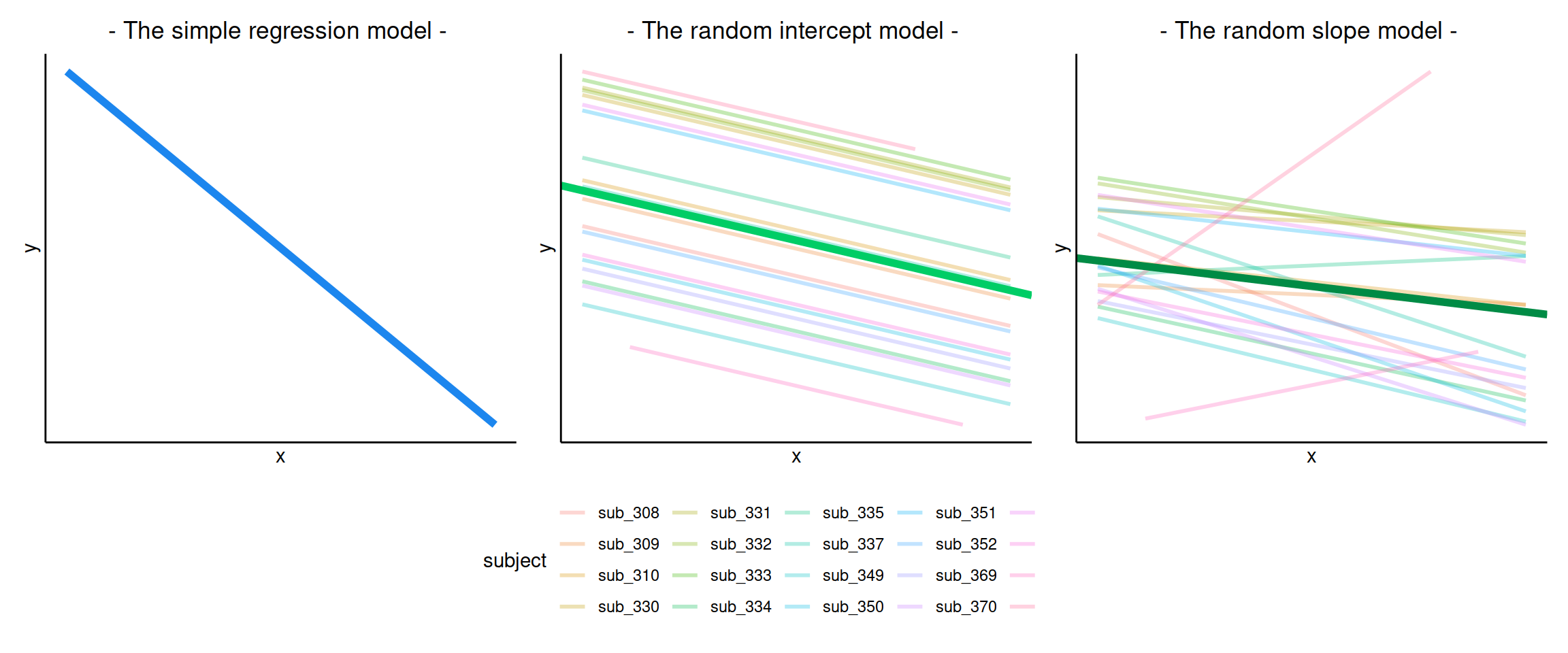
In the random-intercept model (center panel), the differences from each of the subjects’ intercepts to the fixed intercept (thick green line) have mean 0 and standard deviation \(\sigma_0\). The standard deviation (and variance, which is \(\sigma_0^2\)) is what we see in the random effects part of our model summary (or using the VarCorr() function).

In the random-slope model (right panel), the same is true for the differences from each subjects’ slope to the fixed slope.
We can extract the deviations for each group from the fixed effect estimates using the ranef() function.
These are the deviations from the overall intercept (\(\widehat \gamma_{00} = 405.79\)) and slope (\(\widehat \gamma_{10} = -0.672\)) for each subject \(i\).
ranef(random_slopes_model)
## $subject
## (Intercept) x1
## sub_308 31.327291 -1.43995253
## sub_309 -28.832219 0.41839420
## sub_310 2.711822 0.05993766
## sub_330 59.398971 0.38526670
## sub_331 74.958481 0.17391602
## sub_332 91.086535 -0.23461836
## sub_333 97.852988 -0.19057838
## sub_334 -54.185688 -0.55846794
## sub_335 -16.902018 0.92071637
## sub_337 52.217859 -1.16602280
## sub_349 -67.760246 -0.68438960
## sub_350 -5.821271 -1.23788002
## sub_351 61.198823 0.05499816
## sub_352 -7.905596 -0.66495059
## sub_369 -47.636645 -0.46810258
## sub_370 -33.121093 -1.11001234
## sub_371 77.576205 -0.20402571
## sub_372 -36.389281 -0.45829505
## sub_373 -197.579562 1.79897904
## sub_374 -52.195357 4.60508775
##
## with conditional variances for "subject"
Group-level coefficients
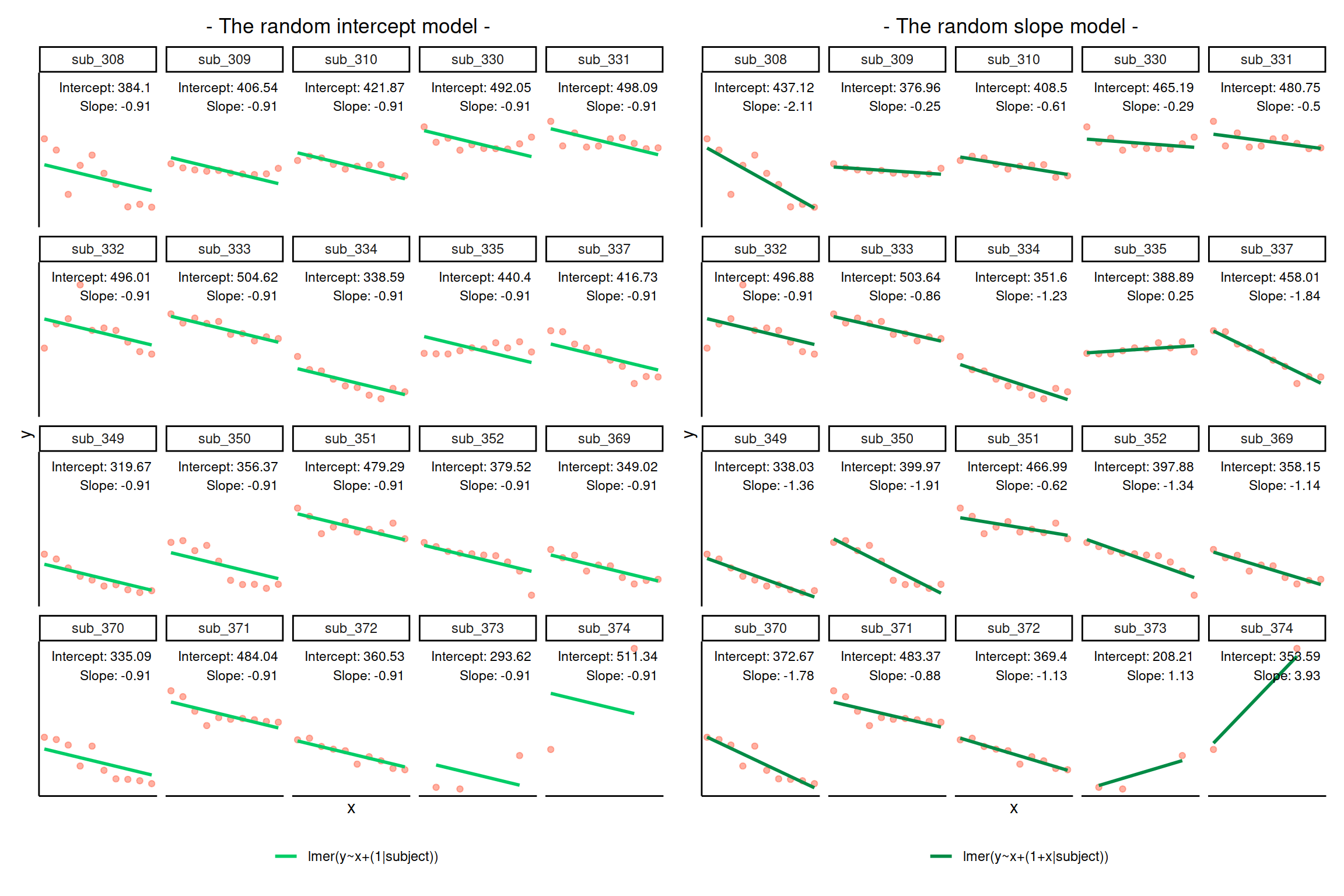
We can also see the actual intercept and slope for each subject \(i\) directly, using the coef() function.
coef(random_slopes_model)
## $subject
## (Intercept) x1
## sub_308 437.1171 -2.1122179
## sub_309 376.9575 -0.2538712
## sub_310 408.5016 -0.6123277
## sub_330 465.1887 -0.2869987
## sub_331 480.7482 -0.4983494
## sub_332 496.8763 -0.9068837
## sub_333 503.6428 -0.8628438
## sub_334 351.6041 -1.2307333
## sub_335 388.8877 0.2484510
## sub_337 458.0076 -1.8382882
## sub_349 338.0295 -1.3566550
## sub_350 399.9685 -1.9101454
## sub_351 466.9886 -0.6172672
## sub_352 397.8842 -1.3372160
## sub_369 358.1531 -1.1403680
## sub_370 372.6687 -1.7822777
## sub_371 483.3660 -0.8762911
## sub_372 369.4005 -1.1305604
## sub_373 208.2102 1.1267137
## sub_374 353.5944 3.9328224
##
## attr(,"class")
## [1] "coef.mer"
Notice that the above are the fixed effects + random effects estimates, i.e. the overall intercept and slope + deviations for each subject.
coef(random_intercept_model)
## $subject
## (Intercept) x1
## sub_308 384.0955 -0.9135829
## sub_309 406.5426 -0.9135829
## sub_310 421.8658 -0.9135829
## sub_330 492.0476 -0.9135829
## sub_331 498.0868 -0.9135829
## sub_332 496.0130 -0.9135829
## sub_333 504.6193 -0.9135829
## sub_334 338.5855 -0.9135829
## sub_335 440.3964 -0.9135829
## sub_337 416.7346 -0.9135829
## sub_349 319.6674 -0.9135829
## sub_350 356.3696 -0.9135829
## sub_351 479.2943 -0.9135829
## sub_352 379.5162 -0.9135829
## sub_369 349.0152 -0.9135829
## sub_370 335.0869 -0.9135829
## sub_371 484.0427 -0.9135829
## sub_372 360.5322 -0.9135829
## sub_373 293.6168 -0.9135829
## sub_374 511.3440 -0.9135829
##
## attr(,"class")
## [1] "coef.mer"
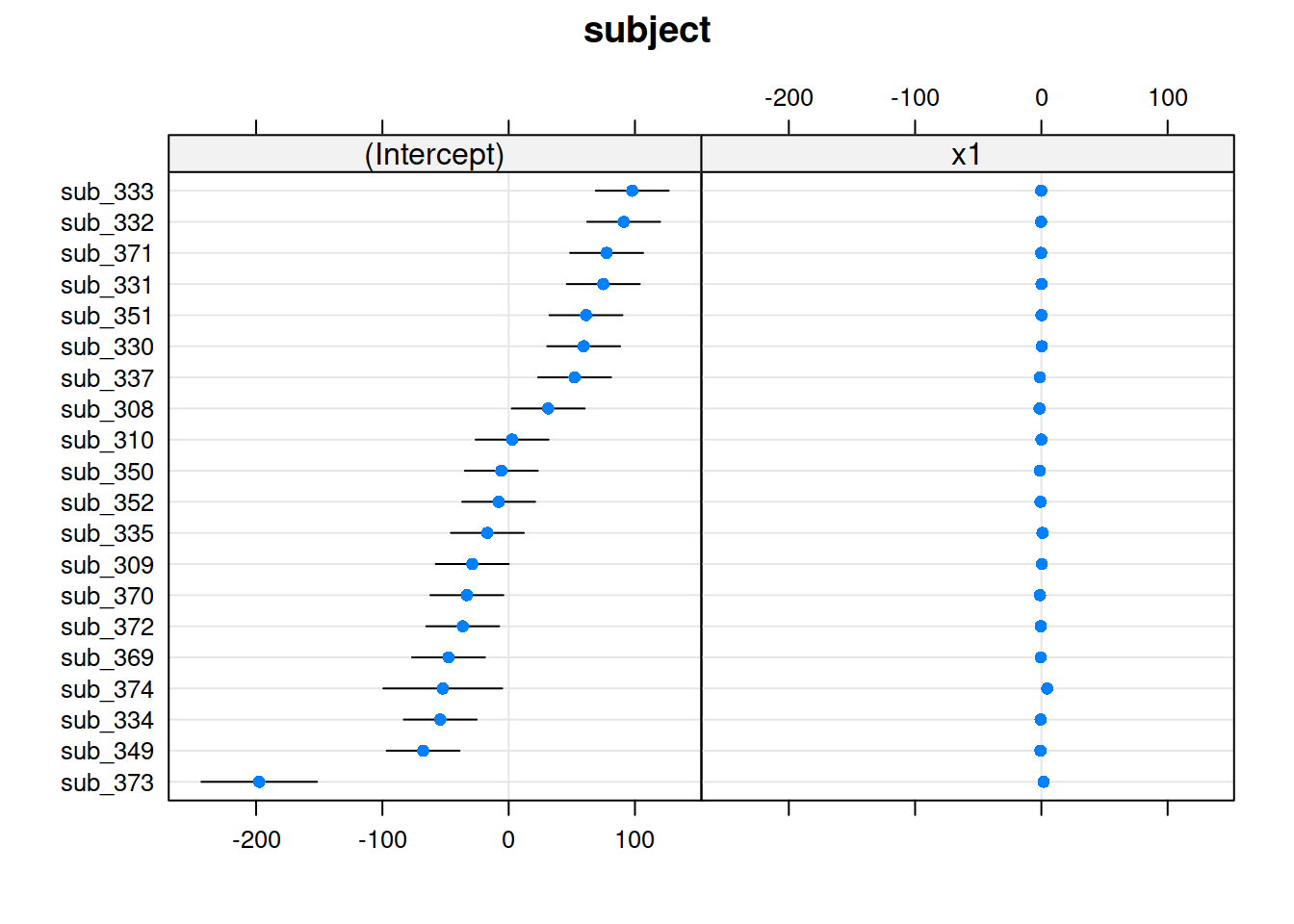
Plotting random effects
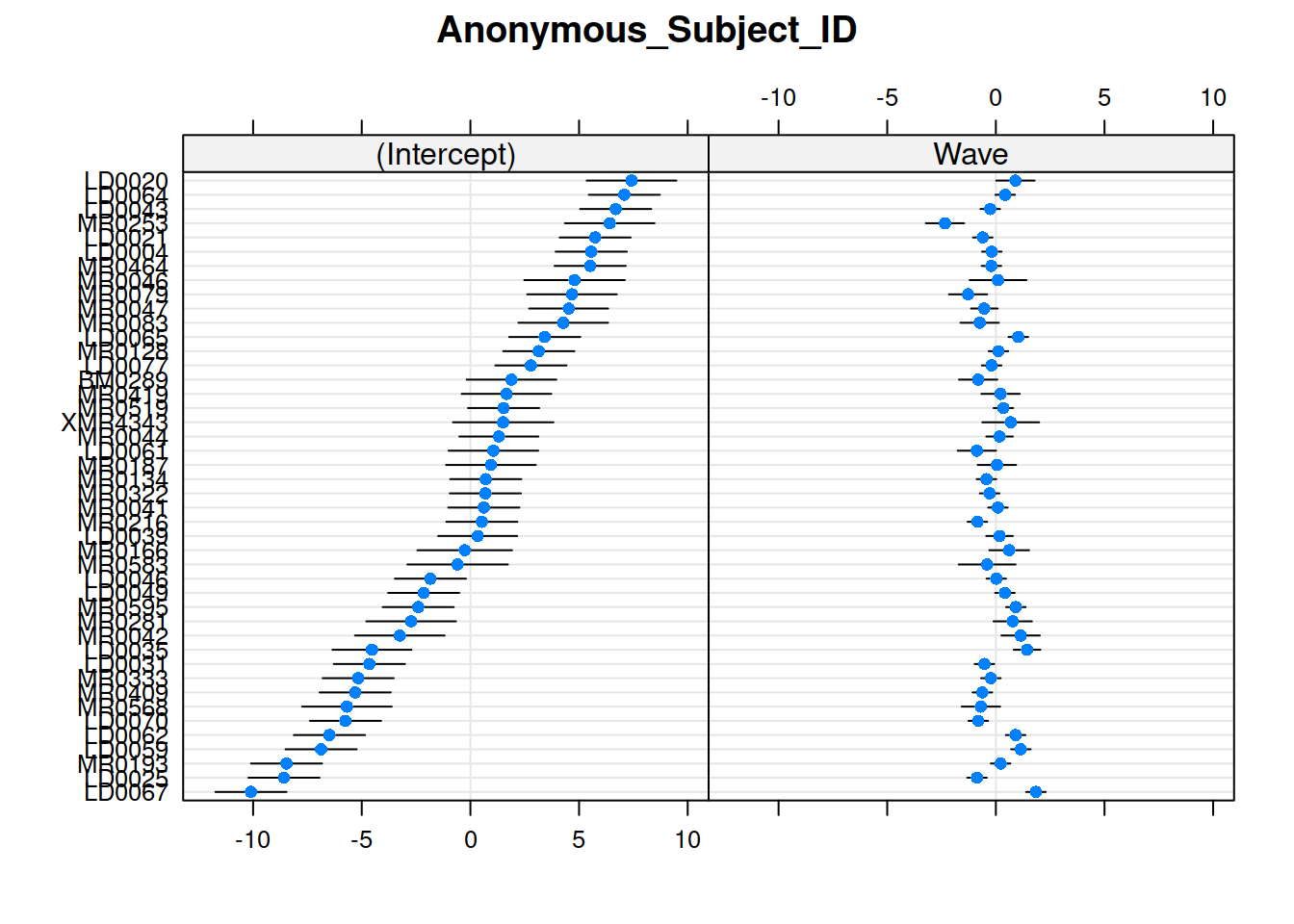
The quick and easy way to plot your random effects is to use the dotplot.ranef.mer() function in lme4.
randoms <- ranef(random_slopes_model, condVar=TRUE)
dotplot.ranef.mer(randoms)
## $subject
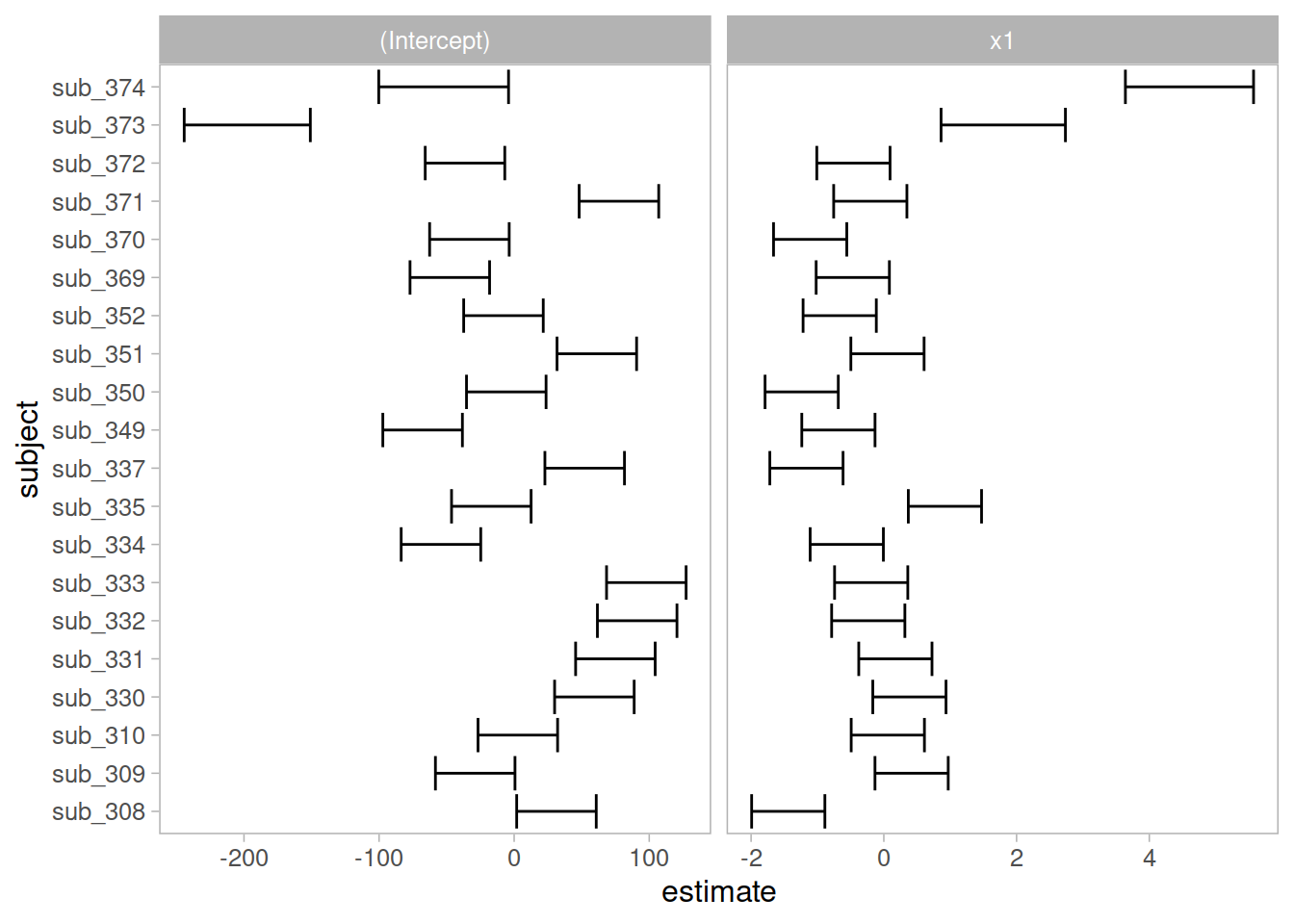
Completely optional - extracting them for plotting in ggplot
Sometimes, however, we might want to have a bit more control over our plotting, we can extract the estimates and correlations for each subject:
#we can get the random effects:
#(note that we use $subject because there might be other groupings, and the ranef() function will give us a list, with one element for each grouping variable)
randoms <-
ranef(random_slopes_model)$subject %>%
mutate(subject = row.names(.)) %>% # the subject IDs are stored in the rownames, so lets add them as a variable
pivot_longer(cols=1:2, names_to="term",values_to="estimate") # finally, let's reshape it for plotting
#and the same for the standard errors (from the arm package):
randoms_se <-
arm::se.ranef(random_slopes_model)$subject %>%
as.data.frame() %>%
mutate(subject = row.names(.)) %>%
pivot_longer(cols=1:2, names_to="term",values_to="se")
# join them together:
ranefs_plotting <- left_join(randoms, randoms_se)
# it's easier for plotting if we
ggplot(ranefs_plotting, aes(y=subject, x=estimate))+
geom_errorbarh(aes(xmin=estimate-2*se, xmax=estimate+2*se))+
facet_wrap(~term, scales="free_x")
Nested and Crossed structures
The same principle we have seen for one level of clustering can be extended to clustering at different levels (for instance, observations are clustered within subjects, which are in turn clustered within groups).
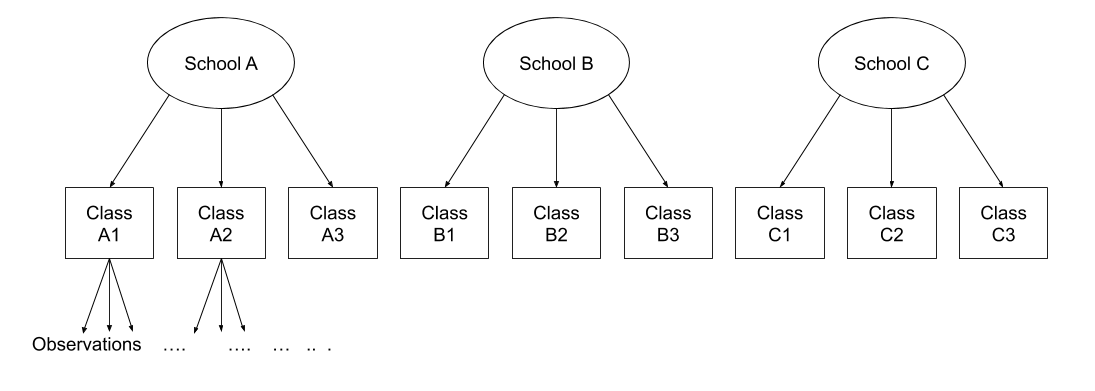
Consider the example where we have observations for each student in every class within a number of schools:
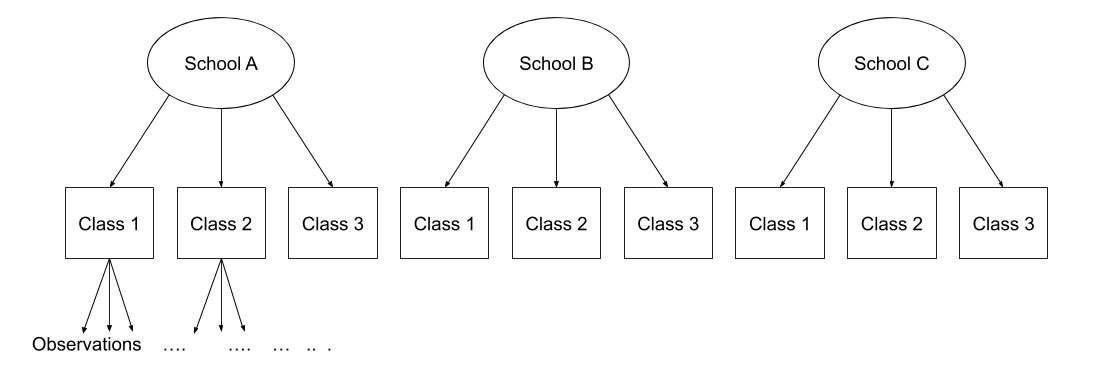
Question: Is “Class 1” in “School 1” the same as “Class 1” in “School 2?”
No.
The classes in one school are distinct from the classes in another even though they are named the same.
The classes-within-schools example is a good case of nested random effects - one factor level (one group in a grouping varible) appears only within a particular level of another grouping variable.
In R, we can specify this using:
(1 | school) + (1 | class:school)
or, more succinctly:
(1 | school/class)
Consider another example, where we administer the same set of tasks at multiple time-points for every participant.
Question: Are tasks nested within participants?
No.
Tasks are seen by multiple participants (and participants see multiple tasks).
We could visualise this as the below:
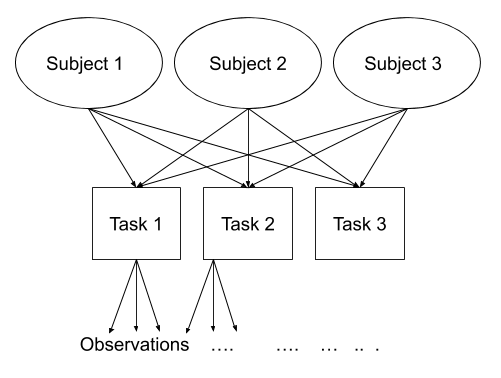
In the sense that these are not nested, they are crossed random effects.
In R, we can specify this using:
(1 | subject) + (1 | task)
Nested vs Crossed
Nested: Each group belongs uniquely to a higher-level group.
Crossed: Not-nested.
Note that in the schools and classes example, had we changed data such that the classes had unique IDs (e.g., see below), then the structures (1 | school) + (1 | class) and (1 | school/class) would give the same results.
Exercise A
Question A1
Research question:
Do children scores in maths improve more in school 2020 vs school 2040?
Load into R the data from the beginning of this lab, on mathematics performance in two schools. These can be found at the following link: https://uoepsy.github.io/data/MathsAchievement.csv
Make sure that variables encoding groups are stored as factors!
Recall that the data represent longitudinal measurements on 42 students from two different schools, with id 2020 and 2040 (21 students from each school). The outcome of interest is mathematics achievement.
The data were collected at the end of first grade and annually thereafter up to sixth grade, but not all students have six observations.
The variable year has been mean-centred to have mean 0 so that results will have as baseline the average.
Solution
library(tidyverse)
schools <- read_csv('https://uoepsy.github.io/data/MathsAchievement.csv')
schools <- schools %>%
mutate(schoolid = factor(schoolid),
childid = factor(childid))
head(schools)
## # A tibble: 6 x 4
## schoolid childid year math
## <fct> <fct> <dbl> <dbl>
## 1 2020 273026452 0.5 1.15
## 2 2020 273026452 1.5 1.13
## 3 2020 273026452 2.5 2.30
## 4 2020 273030991 -1.5 -1.30
## 5 2020 273030991 -0.5 0.439
## 6 2020 273030991 0.5 2.43
Question A2
Fit the appropriate model to answer the research question.
Think carefully - what is the question concerning? Where should you include schoolid? as a grouping level, or as a fixed effect?
Solution
modschools <- lmer(math ~ 1 + year + schoolid + (1 + year | childid), data = data)
summary(modschools)
## Linear mixed model fit by REML. t-tests use Satterthwaite's method [
## lmerModLmerTest]
## Formula: math ~ 1 + year + schoolid + (1 + year | childid)
## Data: data
##
## REML criterion at convergence: 332
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.85909 -0.67031 -0.06586 0.61547 2.34212
##
## Random effects:
## Groups Name Variance Std.Dev. Corr
## childid (Intercept) 0.50671 0.7118
## year 0.01184 0.1088 1.00
## Residual 0.18643 0.4318
## Number of obs: 186, groups: childid, 42
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) -0.21077 0.15101 45.36068 -1.396 0.1696
## year 0.94972 0.02886 24.11700 32.903 <2e-16 ***
## schoolid2040 -0.36306 0.19294 34.82271 -1.882 0.0683 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) year
## year 0.416
## schoold2040 -0.650 -0.008
## optimizer (nloptwrap) convergence code: 0 (OK)
## Model failed to converge with max|grad| = 0.00288304 (tol = 0.002, component 1)
Question A3
- extract the overall intercept and slope.
- extract the deviations from the overall intercept and slope for each child.
- extract the actual intercept and slope for the line of child \(i\)
- how do you compute the intercept and slope for the line of child 273030991 using the output from (1) and (2)? Does it agree with (3)?
Solution
fixef(modschools)
## (Intercept) year schoolid2040
## -0.2107673 0.9497207 -0.3630573
ranef(modschools)
## $childid
## (Intercept) year
## 253404261 0.72336027 0.110392519
## 253413681 -1.74737801 -0.266897951
## 270199271 -0.46293088 -0.070839752
## 273026452 0.21024435 0.032061728
## 273030991 1.13643797 0.173706066
## 273059461 0.63945161 0.097684691
## 278058841 1.28024832 0.195489717
## 285939962 0.43254617 0.066098841
## 288699161 0.57365519 0.087740369
## 289970511 0.09341064 0.014202873
## 292017571 1.40710797 0.215048838
## 292020281 -0.22959172 -0.035153534
## 292020361 -0.37031396 -0.056606784
## 292025081 0.22852401 0.035086662
## 292026211 -0.22032149 -0.033764305
## 292027291 0.24685794 0.037851698
## 292027531 0.06396375 0.009822580
## 292028181 -0.74083925 -0.113102127
## 292028931 -0.07202067 -0.011242204
## 292029071 0.08721703 0.013423313
## 292029901 -0.49863173 -0.075921828
## 292033851 -0.75692101 -0.115459647
## 292772811 -0.70105345 -0.106958259
## 293550291 -0.23040136 -0.035244582
## 295341521 0.06975094 0.010825237
## 298046562 -0.49962987 -0.076393306
## 299680041 -0.04367604 -0.006780972
## 301853741 0.56571795 0.086387594
## 303652591 0.36200112 0.055329846
## 303653561 -0.32092014 -0.049005531
## 303654611 -0.73777527 -0.112808984
## 303658951 0.96735708 0.147887549
## 303660691 -0.71248408 -0.108948838
## 303662391 -0.67733173 -0.103452008
## 303663601 -0.13283943 -0.020263644
## 303668751 0.41668023 0.063369197
## 303671891 -0.52149751 -0.079781383
## 303672001 0.81414597 0.124350637
## 303672861 0.49095808 0.075129264
## 303673321 -0.90990542 -0.139093117
## 307407931 0.73125608 0.111666621
## 307694141 -0.95442964 -0.145837082
##
## with conditional variances for "childid"
coef(modschools)
## $childid
## (Intercept) year schoolid2040
## 253404261 0.5125929533 1.0601132 -0.3630573
## 253413681 -1.9581453272 0.6828228 -0.3630573
## 270199271 -0.6736981926 0.8788810 -0.3630573
## 273026452 -0.0005229579 0.9817824 -0.3630573
## 273030991 0.9256706545 1.1234268 -0.3630573
## 273059461 0.4286842938 1.0474054 -0.3630573
## 278058841 1.0694810056 1.1452104 -0.3630573
## 285939962 0.2217788532 1.0158195 -0.3630573
## 288699161 0.3628878762 1.0374611 -0.3630573
## 289970511 -0.1173566687 0.9639236 -0.3630573
## 292017571 1.1963406577 1.1647695 -0.3630573
## 292020281 -0.4403590352 0.9145672 -0.3630573
## 292020361 -0.5810812731 0.8931139 -0.3630573
## 292025081 0.0177566996 0.9848074 -0.3630573
## 292026211 -0.4310888043 0.9159564 -0.3630573
## 292027291 0.0360906280 0.9875724 -0.3630573
## 292027531 -0.1468035589 0.9595433 -0.3630573
## 292028181 -0.9516065645 0.8366186 -0.3630573
## 292028931 -0.2827879859 0.9384785 -0.3630573
## 292029071 -0.1235502786 0.9631440 -0.3630573
## 292029901 -0.7093990434 0.8737989 -0.3630573
## 292033851 -0.9676883244 0.8342611 -0.3630573
## 292772811 -0.9118207676 0.8427624 -0.3630573
## 293550291 -0.4411686754 0.9144761 -0.3630573
## 295341521 -0.1410163713 0.9605459 -0.3630573
## 298046562 -0.7103971846 0.8733274 -0.3630573
## 299680041 -0.2544433495 0.9429397 -0.3630573
## 301853741 0.3549506383 1.0361083 -0.3630573
## 303652591 0.1512338057 1.0050506 -0.3630573
## 303653561 -0.5316874534 0.9007152 -0.3630573
## 303654611 -0.9485425779 0.8369117 -0.3630573
## 303658951 0.7565897654 1.0976083 -0.3630573
## 303660691 -0.9232513879 0.8407719 -0.3630573
## 303662391 -0.8880990428 0.8462687 -0.3630573
## 303663601 -0.3436067474 0.9294571 -0.3630573
## 303668751 0.2059129127 1.0130899 -0.3630573
## 303671891 -0.7322648190 0.8699393 -0.3630573
## 303672001 0.6033786603 1.0740713 -0.3630573
## 303672861 0.2801907677 1.0248500 -0.3630573
## 303673321 -1.1206727310 0.8106276 -0.3630573
## 307407931 0.5204887711 1.0613873 -0.3630573
## 307694141 -1.1651969571 0.8038836 -0.3630573
##
## attr(,"class")
## [1] "coef.mer"
fixef(modschools) + ranef(modschools)$childid['273030991', ]
## (Intercept) year
## 273030991 0.9256707 1.123427
coef(modschools)$childid['273030991', ]
## (Intercept) year schoolid2040
## 273030991 0.9256707 1.123427 -0.3630573