Researchers are interested in different methods for reducing stress. They recruit 522 participants. All participants first filled out a 6-question measure of stress that is aimed to capture feelings of immediate stress and panic. All questions were scored on a 5-point likert scale from “Strongly Disagree” (1) to “Strongly Agree” (5). To obtain an overall measure of stress, participants’ scores on the 6 questions are added together.
After completing the initial stress measure, participants then completed one of three 5 minute tasks. One third of participants sat in silence for 5 minutes, one third played a picture-matching game on their phone for 5 minutes, and the remaining third completed 5 minutes of “box breathing” (inhale for 6, hold for 4, exhale for 6, hold for 4). After the 5 minutes, all participants filled out the same 6-item measure of stress.
Researchers would like to know whether the different tasks are associated with differences in reduction in stress.
Each row is a participant, and we have their stress measured at two time points. We can see that for each person there are 6 columns all measuring the construct of “stress” at each time point.
And for each of those columns, there’s a whole load of words in there!
Question 2
First things first, our questionnaire software has given us the responses all in the descriptors used for each point of the likert scale, which is a bit annoying.
Convert them all to numbers, which we can then work with.
We want to turn all of the variables from t1_q1 to t1_q6and from t2_q1 to t2_q6, into numbers.
To do it with one variable:
bbdat |>mutate(t1_q1 =case_match(t1_q1,"Strongly Disagree"~1,"Disagree"~2,"Neither Disagree nor Agree"~3,"Agree"~4,"Strongly Agree"~5 ))
And we can do it to all at once with across().
Note we have to specify two sets of columns because there’s a column in the middle (the task column) that we don’t want to do anything to.
Just looking at the data at time 1, create a correlation matrix of the various items that measure stress.
What do you notice? Does it make sense given the wording of the questions?
Correlations are all positive except for those with Q4 and Q5. Q4 and Q5 are positively related, but they are negatively related to the other questions.
This makes sense given the way the questions are worded - if people are feeling stressed, they will be more likely to disagree to Q4 and Q5, but agree with the others:
qitems
[1] "I feel a bit on edge right now."
[2] "I find it hard to focus because of how I'm feeling."
[3] "I feel like things are getting a little out of control."
[4] "I feel calm and steady in this moment."
[5] "I feel capable of managing the situation right now."
[6] "I feel somewhat restless or unsettled at the moment."
Question 4
Reverse score questions 4 and 5.
We’ll need to do this for both the data at time 1 and at time 2.
Be careful!! if you have some code that reverse scores a question, and you run it twice, you will essentially reverse-reverse score the question, and it goes back to the original ordering!
There’s only 4, so let’s do this individually for each question:
vars n mean sd median trimmed mad min max range skew
t1_stress 1 522 17.84 4.61 18 17.88 4.45 7 30 23 -0.06
t2_stress 2 522 17.77 4.55 18 17.78 4.45 6 30 24 -0.03
stress_change 3 522 -0.07 1.02 0 -0.04 1.48 -3 3 6 -0.11
kurtosis se
t1_stress -0.32 0.20
t2_stress -0.40 0.20
stress_change -0.08 0.04
Question 9
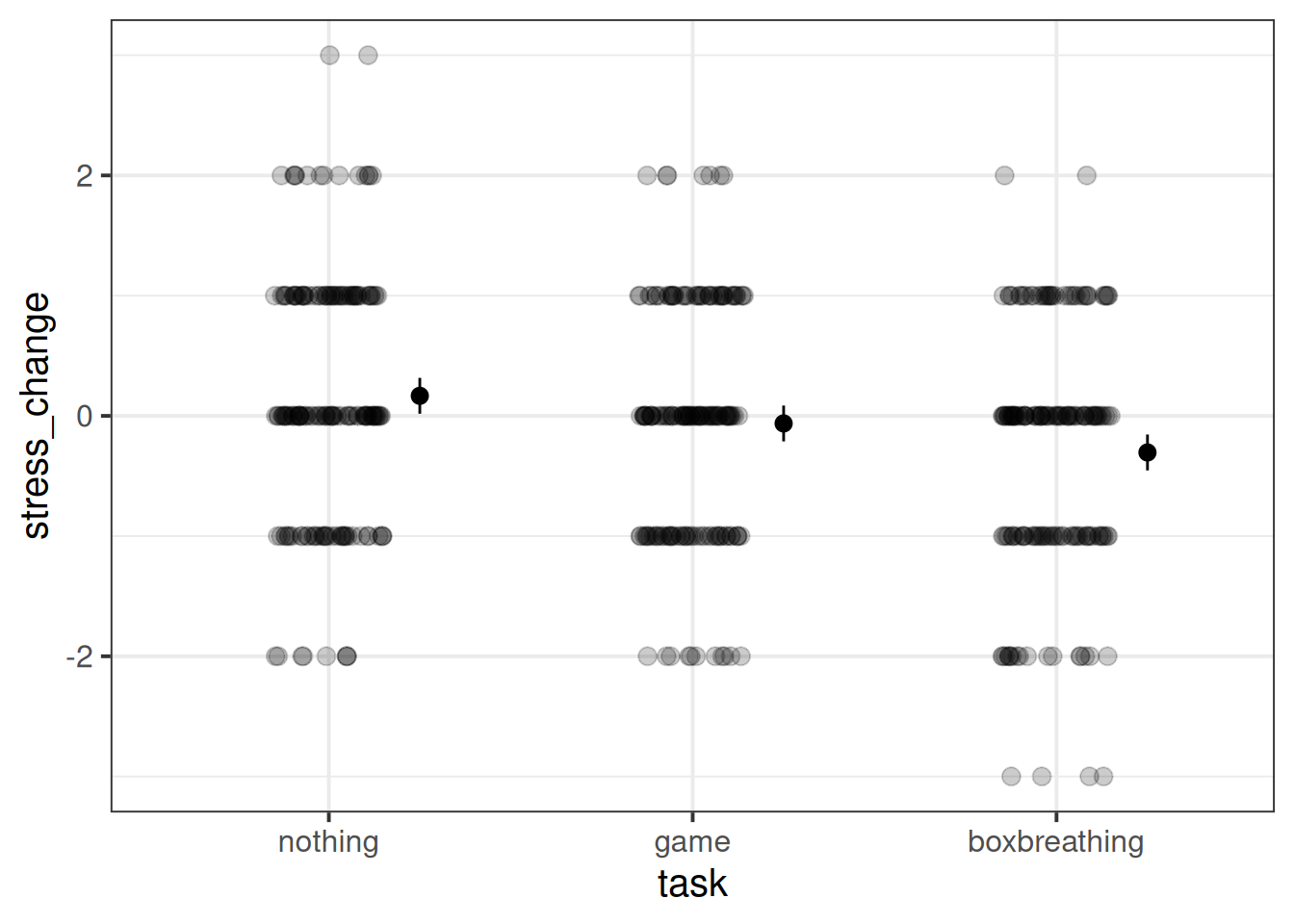
Plot the stress-change for each group of participants.
Fit a linear model to investigate whether the different techniques (the timer game and the box-breathing) are associated with differences in stress change.
It makes more sense to think of “nothing” as the reference level, so let’s make that happen: