| variable | description |
|---|---|
| q_irritability | Score on irritability questionnaire (0:100) |
| q_hunger | Score on hunger questionnaire (0:100) |
| ppt | Participant |
W4 Exercises: Centering
Hangry
Data: hangry1.csv
The study is interested in evaluating whether levels of hunger are associated with levels of irritability (i.e., “the hangry hypothesis”). 81 participants were recruited into the study. Once a week for 5 consecutive weeks, participants were asked to complete two questionnaires, one assessing their level of hunger, and one assessing their level of irritability. The time and day at which participants were assessed was at a randomly chosen hour between 7am and 7pm each week.
The data are available at: https://uoepsy.github.io/data/hangry1.csv.
Question 1
Remember that what we’re interested in is “whether levels of hunger are associated with levels of irritability (i.e.,”the hangry hypothesis”)“.
Read in the data and fit the model below. How well does it address the research question?
mod1 <- lmer(q_irritability ~ q_hunger +
(1 + q_hunger | ppt),
data = hangry)
Hints
Always plot your data! It’s tempting to just go straight to interpreting coefficients of this model, but in order to understand what a model says we must have a theory about how the data are generated.
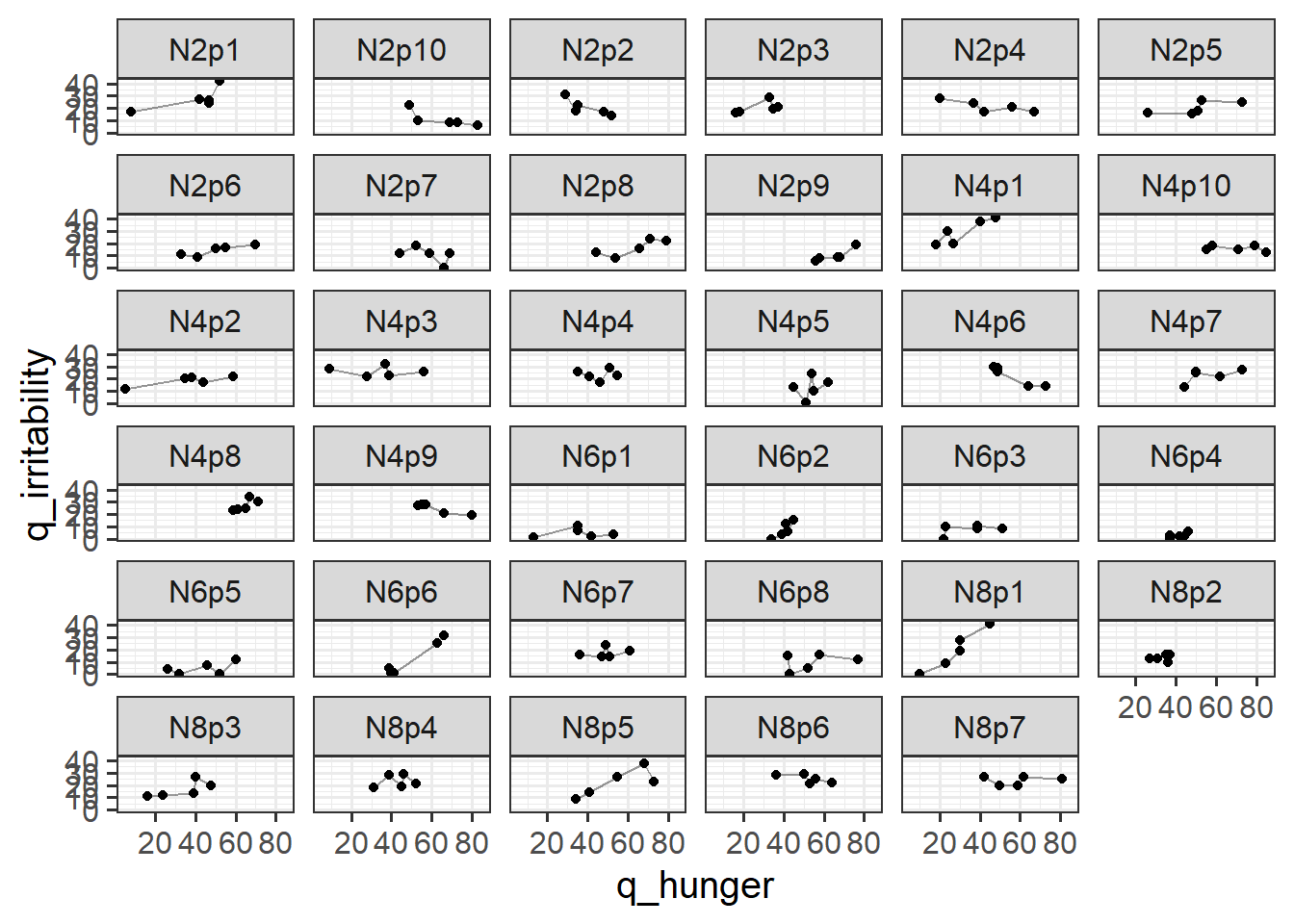
Question 2
within effects, between effects, and smushed effects
Research Question: “whether levels of hunger are associated with levels of irritability (i.e.,”the hangry hypothesis”)“.
Think about the relationship between irritability and hunger. How should we interpret this research aim?
Is it:
- “Are people more irritable if they are, on average, more hungry than other people?”
- “Are people more irritable if they are, for them, more hungry than they usually are?”
- Some combination of both a. and b.
This is just one demonstration of how the statistical methods we use can constitute an integral part of our development of a research project, and part of the reason that data analysis for scientific cannot be so easily outsourced after designing the study and collecting the data.
As our data currently is currently stored, the relationship between irritability and the raw scores on the hunger questionnaire q_hunger represents some ‘total effect’ of hunger on irritability. This is a bit like interpretation c. above - it’s a composite of both the ‘within’ ( b. ) and ‘between’ ( a. ) effects. The problem with this is that this isn’t necessarily all that meaningful. It may tell us that ‘being higher on the hunger questionnaire is associated with being more irritable’, but how can we apply this information? It is not specifically about the comparison between hungry people and less hungry people, and nor is it a good estimation of how person \(i\) changes when they are more hungry than usual. It is both these things smushed together.
To disaggregate the ‘within’ and ‘between’ effects of hunger on irritability, we can group-mean center. For ‘between’, we are interested in how irritability is related to the average hunger levels of a participant, and for ‘within’, we are asking how irritability is related to a participants’ relative levels of hunger (i.e., how far above/below their average hunger level they are.).
Add to the data these two columns:
- a column which contains the average hungriness score for each participant.
- a column which contains the deviation from each person’s hunger score to that person’s average hunger score.
Hints
You’ll find group_by() |> mutate() very useful here, as seen in Chapter 10 #group-mean-centering.
Question 3
For each of the new variables you just added, plot the irritability scores against those variables.
- Does it look like hungry people are more irritable than less hungry people?
- Does it look like when people are more hungry than normal, they are more irritable?
Hints
You might find stat_summary() useful here for plotting the between effect (see Chapter 10 #group-mean-centering)
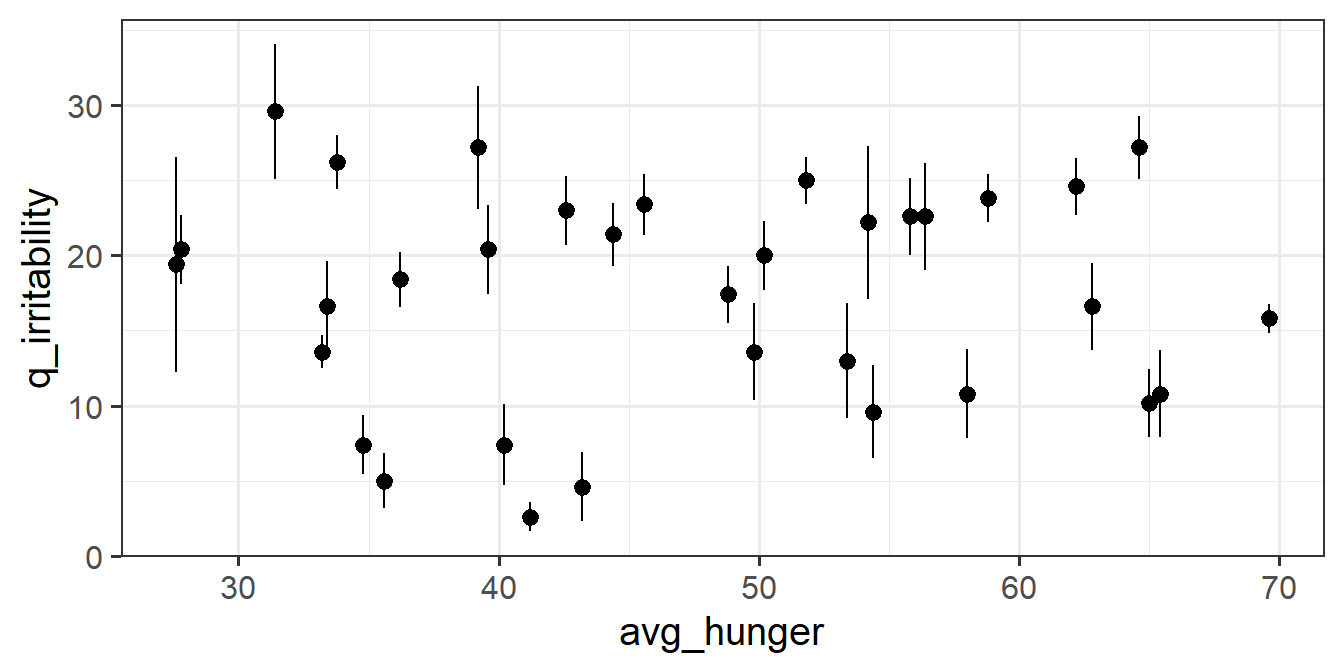
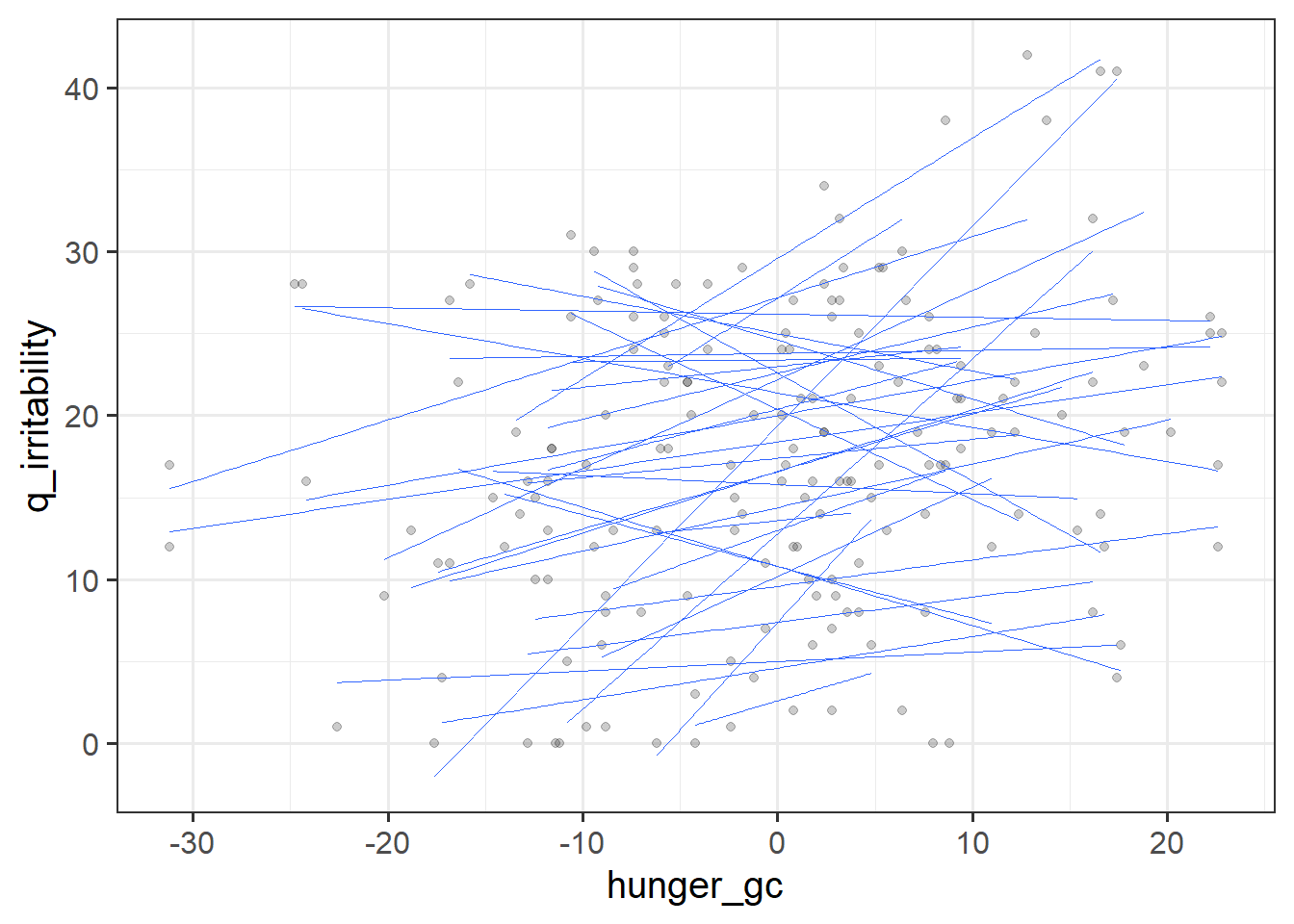
Question 4
We have taken the raw hunger scores and separated them into two parts (raw hunger scores = participants’ average hunger score + observation level deviations from those averages), that represent two different aspects of the relationship between hunger and irritability.
Adjust your model specification to include these two separate variables as predictors, instead of the raw hunger scores.
Hints
- We can only put one of these variables in the random effects
(1 + hunger | participant). Think about the fact that each participant has only one value for their average hungriness.
- If the model fails to converge, and it’s a fairly simple model (i.e one or two random slopes), then often you can switch optimizer (see Chapter 2 #convergence-warnings-singular-fits). For instance, try adding
control = lmerControl(optimizer = "bobyqa")to the model.
Question 5
Write down an interpretation of each of the fixed effects
Question 6
Have a go at also writing an explanation for yourself of the random effects part of the output.
There’s no formulaic way to interpret these, but have a go at describing in words what they represent, and how that adds to the picture your model describes.
Don’t worry about making it read like a report - just write yourself an explanation!
Hangry 2
Question 7
A second dataset on the same variables is available at: https://uoepsy.github.io/data/hangry2.csv.
These data are from people who were following a five-two diet, while the original dataset were from people who were not folling any diet.
Combine the datasets together so we can fit a model to see if the hangry effect differs between people on diets vs those who aren’t.
Hints
- Something like
bind_rows()might help here. If you’ve not seen it before, remember that you can look up the help documentation in the bottom-right panel of RStudio - Be sure to keep an indicator of which group the data are in!!
Question 8
Does the relationship between hunger and irritability depend on whether or not people are following the five-two diet?
Hints
Which relationship between hunger and irritability are we talking about? The between effect or the within effect? It could be both!
We’re going to need to create those two variables again for this combined dataset.
Question 9
Construct two plots showing the two model estimated interactions. This model is a bit of a confusing one, so plotting may help a bit with understanding what those interactions represent.
Hints
effects(terms, mod) |> as.data.frame() |> ggplot(.....)
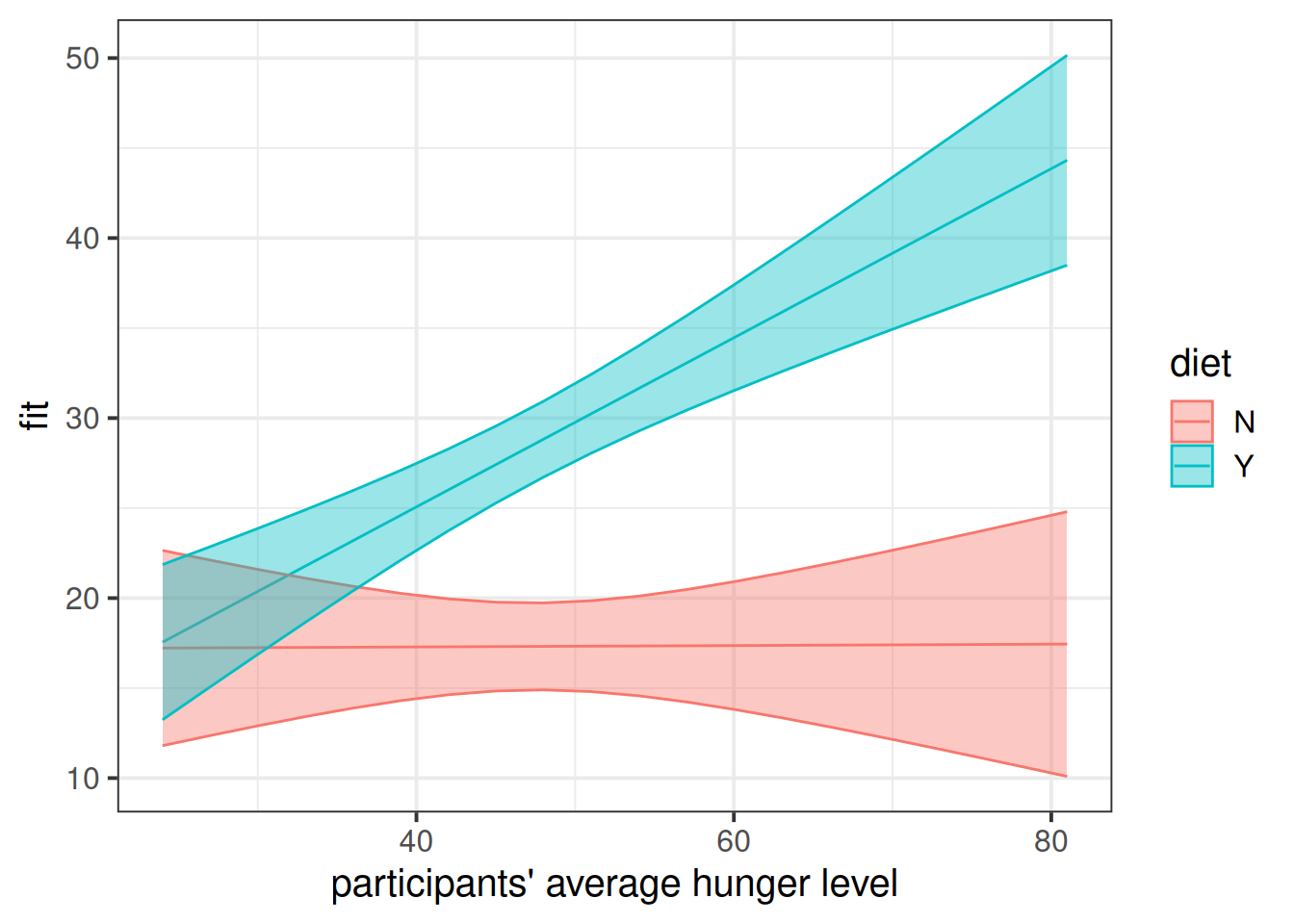
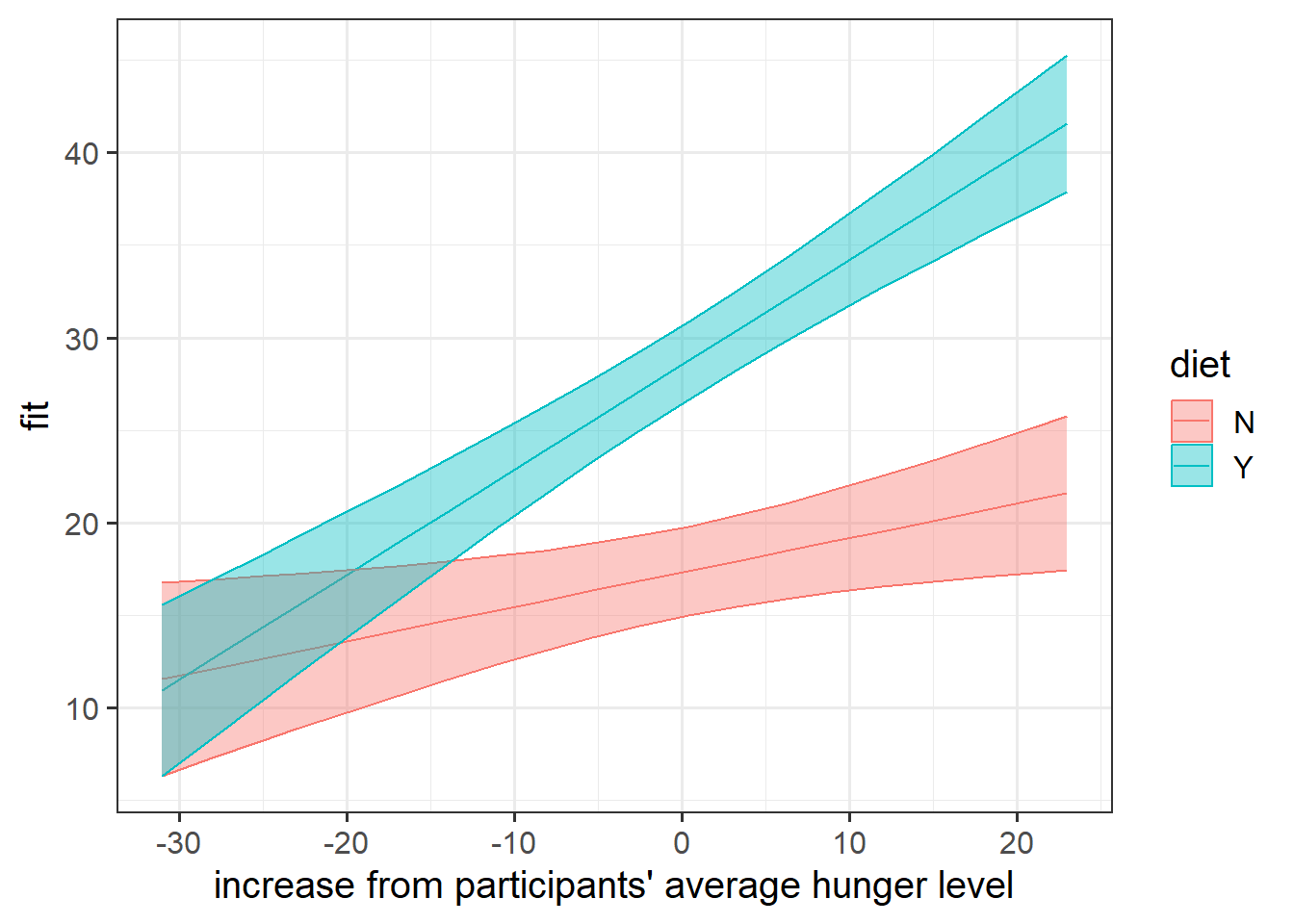
Question 10
Provide tests of the fixed effects and write-up the results.