SEM
Measurement Error and the need for SEM
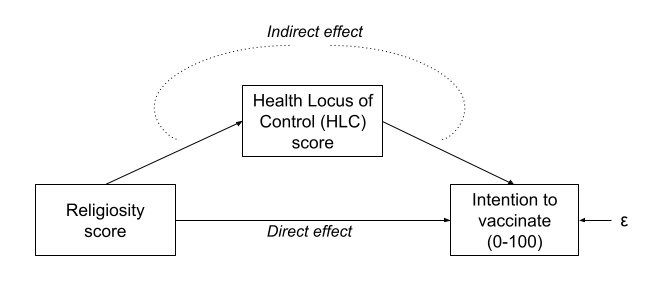
We have been mentioning Structural Equation Modelling (SEM) for a few weeks now, but we haven’t been very clear on what exactly it is. Is it CFA? Is it Path Analysis? In fact it is both - it is the overarching framework of which CFA and Path Analysis are just particular cases. The beauty comes in when we put the CFA and Path Analysis approaches together.
Path analysis, as we saw last week, offers a way of specifying and evaluating a structural model, in which variables relate to one another in various ways, via different (sometimes indirect) paths. Common models like our old friend multiple regression can be expressed in a Path Analysis framework.
Factor Analysis, on the other hand, brings something absolutely crucial to the table - it allows us to mitigate some of the problems which are associated with measurement error by specifying the existence of some latent variable which is measured via some observed variables.
Combine them and we can reap the rewards of having both a structural model and a measurement model. The measurement model is our specification between the items we directly observed, and the latent variables of which we consider these items to be manifestations. The structural model is our specified model of the relationships between the latent variables.
Scale Scores
You will often find research that foregoes the measurement model by taking a scale score (i.e., the sum or mean of a set of likert-type questions). This is what we did in the example in last week’s exercises, e.g.:
- Intention to vaccinate (scored on a range of 0-100).
- Health Locus of Control (HLC) score (average score on a set of items relating to perceived control over ones own health).
- Religiosity (average score on a set of items relating to an individual’s religiosity).
In doing so, we make the assumption that these variables provide measurements of the underlying latent construct without error. Furthermore, when taking the average score, we also make the assumption that each item is equally representative of our construct.
If you think about it, using a scale score (e.g. just calculating the mean, or sum of a set of items) still has the sense of being a ‘factor structure’ in that we think of the items as being manifestations of some underlying latent construct. However, it is a very restricted model, in which all the factor loadings are equal, and there is no residual variance. So it doesn’t really have the benefits of a factor model (it assumes all items are equally reflective or the construct, and it doesn’t separate out measurement error).
Let’s demonstrate this, using a dataset from the CFA week exercises. It doesn’t matter what it is for this example, so I’m just going to keep the first 4 items (it will save me typing out all the others!)
df <- read_csv("https://uoepsy.github.io/data/conduct_problems_2.csv")[,1:4]
head(df)## # A tibble: 6 × 4
## item1 item2 item3 item4
## <dbl> <dbl> <dbl> <dbl>
## 1 -0.968 -0.686 -0.342 0.600
## 2 0.275 -0.327 -0.0166 -1.08
## 3 0.255 0.826 -0.308 -1.15
## 4 1.73 1.67 -0.381 1.13
## 5 -0.464 -0.584 -0.507 -1.34
## 6 -0.501 -1.11 -0.310 -1.39Now suppose that we are just going to take the mean of each persons score on the items, and use that as our measure of “conduct problems”.
We can achieve this easily with rowMeans()
# column bind the data with a column of the row means.
# only print the head of the data for now
cbind(df, mean = rowMeans(df)) %>% head## item1 item2 item3 item4 mean
## 1 -0.968 -0.686 -0.3418 0.60 -0.349
## 2 0.275 -0.327 -0.0166 -1.08 -0.286
## 3 0.255 0.826 -0.3077 -1.15 -0.094
## 4 1.725 1.667 -0.3810 1.13 1.034
## 5 -0.464 -0.584 -0.5072 -1.34 -0.724
## 6 -0.501 -1.108 -0.3097 -1.39 -0.826Expressed as a factor model, what we are specifying is the below. Notice how we make it so that certain paths are identical by using a label i (for all factor loadings) and j (for all item variances).
mean_model <- '
CP =~ i*item1 + i*item2 + i*item3 + i*item4
item1 ~~ j*item1
item2 ~~ j*item2
item3 ~~ j*item3
item4 ~~ j*item4
'
fitmean <- sem(mean_model, data = df)We can obtain our factor scores using predict(). Let’s put them side-by-side with our rowMeans(), and we need to standardise them to get them in the same units:
factor_scores = scale(predict(fitmean))
rowmeans = scale(rowMeans(df))
cbind(factor_scores, rowmeans) %>% head## CP
## [1,] -0.3790 -0.3790
## [2,] -0.3035 -0.3035
## [3,] -0.0697 -0.0697
## [4,] 1.3001 1.3001
## [5,] -0.8343 -0.8343
## [6,] -0.9589 -0.9589An alternative option would be to conduct a factor analysis where we allow our loadings to be estimated freely (without the equality constraint that is created by using a row-mean or a row-sum). We could then extract the factor scores, and then conduct a path analysis with those scores. This avoids the problem of equally weighting of items to construct, but does not solve our issue of the fact that these variables are imperfect measures of the latent construct.
Reliability
The accuracy and inconsistency with which an observed variable reflects the underlying construct that we consider it to be measuring is termed the reliability.
A silly example
Suppose we are trying to weigh a dog. We have a set of scales, and we put him on the scales. He weighs in at 13.53kg. We immediately do it again, and the scales this time say 13.41kg. We do it again, 13.51kg. Once more, 13.60kg.
What is happening? Is Dougal’s weight (Dougal is the dog, by the way) randomly fluctuating by 100g? Or are my scales just a bit inconsistent, and my observations contain measurement error?
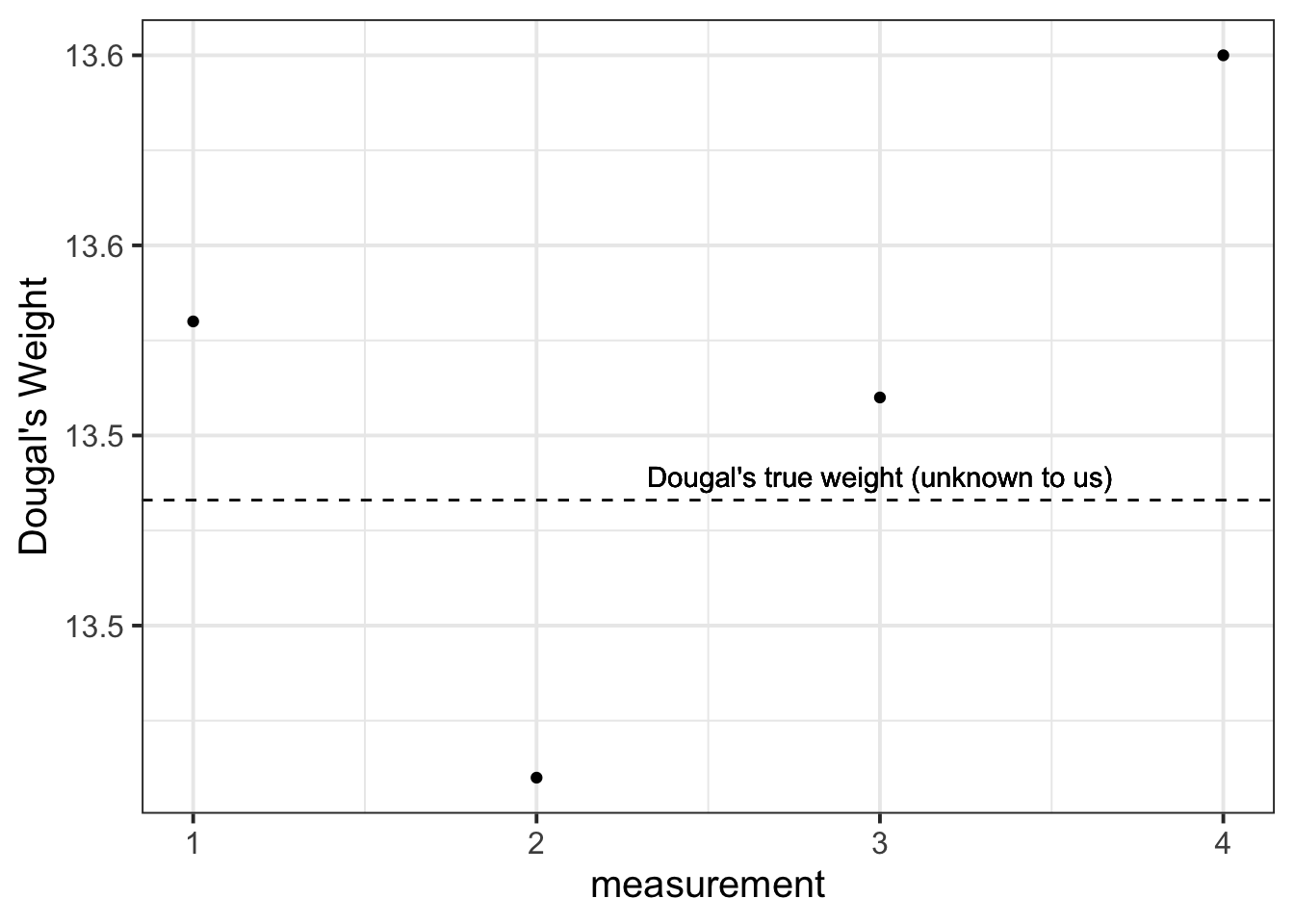
We take him to the vets, where they have a much better set of weighing scales, and we do the same thing (measure him 4 times). The weights are 13.47, 13.49, 13.48, 13.48.
The scales at the vets are clearly more reliable. We still don’t know Dougal’s true weight, but we are better informed to estimate it if we go on the measurements from the scales at the vet.1
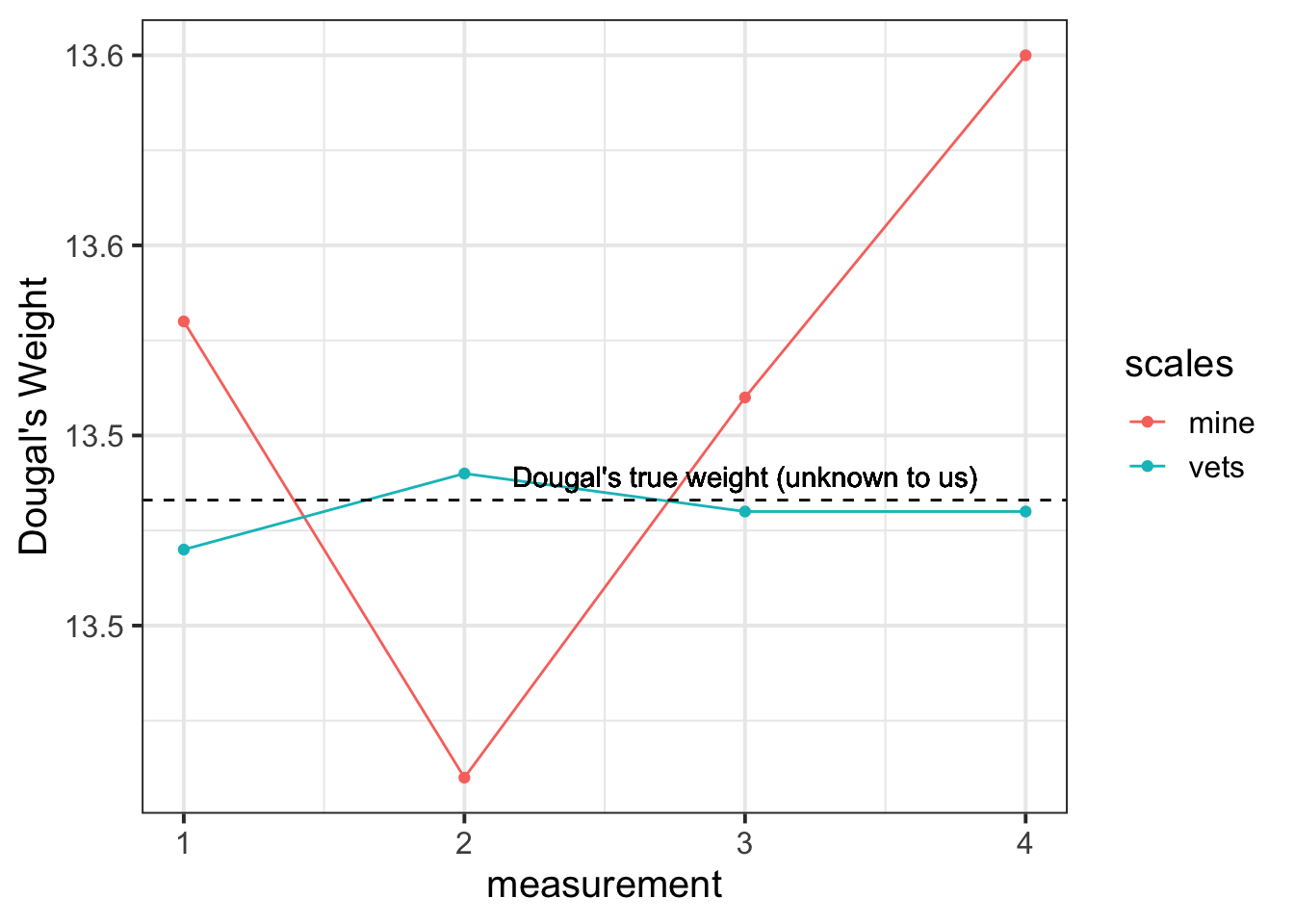
Another way to think about reliability is to take the view that \(\text{"observations = truth + error"}\), and more error = less reliable.
There are different types of reliability:
- test re-test reliability: correlation between values over repeated measurements.
- alternate-form reliability: correlation between scores on different forms/versions of a test (we might want different versions to avoid practice effects).
- Inter-rater reliability: correlation between values obtained from different raters.
The form of reliability we are going to be most concerned with here is known as Internal Consistency. This is the extent to which items within a scale are correlated with one another. There are two main measures of this:
alpha and omega
\[
\begin{align}
& \text{Cronbach's }\alpha = \frac{ n \cdot \overline{cov(ij)} }{\overline{\sigma^2_i} + (n-1) \cdot \overline{cov(ij)}} & \\
\text{where} &: \\
n &= \text{number of items} \\
\overline{cov(ij)} &= \text{average covariance between item-pairs} \\
\overline{\sigma^2_i} &= \text{average item variance} \\
\end{align}
\]
Ranges from 0 to 1 (higher is better).
You can get this using the alpha() function from the psych package. You just give it your items, and it will give you a value. In doing so, it just assumes that all items are of equal importance.
McDonald’s Omega \(\omega\) is substantially more complicated, but avoids the limitation that Cronbach’s alpha which assumes that all items are equally related to the construct. You can get it using the omega() function from the psych package. If you want more info about it then the help docs (?omega()) are a good place to start.
(Re)introducing SEM
After spending much of our time in the regression framework, the move to SEM can feel mind-boggling. Give two researchers the same whiteboard on which your variables are drawn, and they may connect them in completely different ways. This flexibility can at first make SEM feel like a free-for-all (i.e., just do whatever you like, get a p-value out of it, and off we go!). However, to some people this is one of the main benefits: it forces you to be explicit in specifying your theory, and allows you to test your theory and examine how well it fits with the data you observed.
We have actually already got to grips with the starting point of how structural equation models work in the previous weeks.
- begin with an observed covariance matrix
- specify our our theoretical model
- fit our model to the data, with our estimation method (e.g. maximum likelihood) providing us with the set of parameter estimates for our model which best reproduce the observed covariance matrix.
- The estimated parameters for our model will not perfectly reproduce the covariance matrix, but they will give us a model implied covariance matrix. We can compare this to the observed covariance matrix in order to assess the fit of our theoretical model.
SEM allows us to account for measurement error by directly including it as part of the model - the residual variances of our indicator variables (the bits we have been labelling \(u\) our diagrams such as Figure 1) represent the measurement error (and other stray causes) associated with each observed variable. If we had a latent variable which we considered to be measured without error by a number of items, then we would expect the covariances between the items measuring the latent variable to be exactly 1. However, we always have measurement error, meaning our correlations between items are attenuated (i.e, closer to zero). Modelling this attenuation of between-item correlations as error in measuring some underlying latent variable, allows us to estimate associations between latent variables (which aren’t directly measured, and so do not have measurement error associated with them).
Perhaps the easiest way to think of SEM is as a combination of the CFA approach (latent variables giving rise to our observed variables), and path analysis (where we test a model defined as a collection of paths between variables). In SEM we typically have two somewhat distinct parts: a measurement model (the CFA-like bits from latent variables to their indicators), and the structural model (the paths we are interested in, often between the latent variables). You can see an example below:
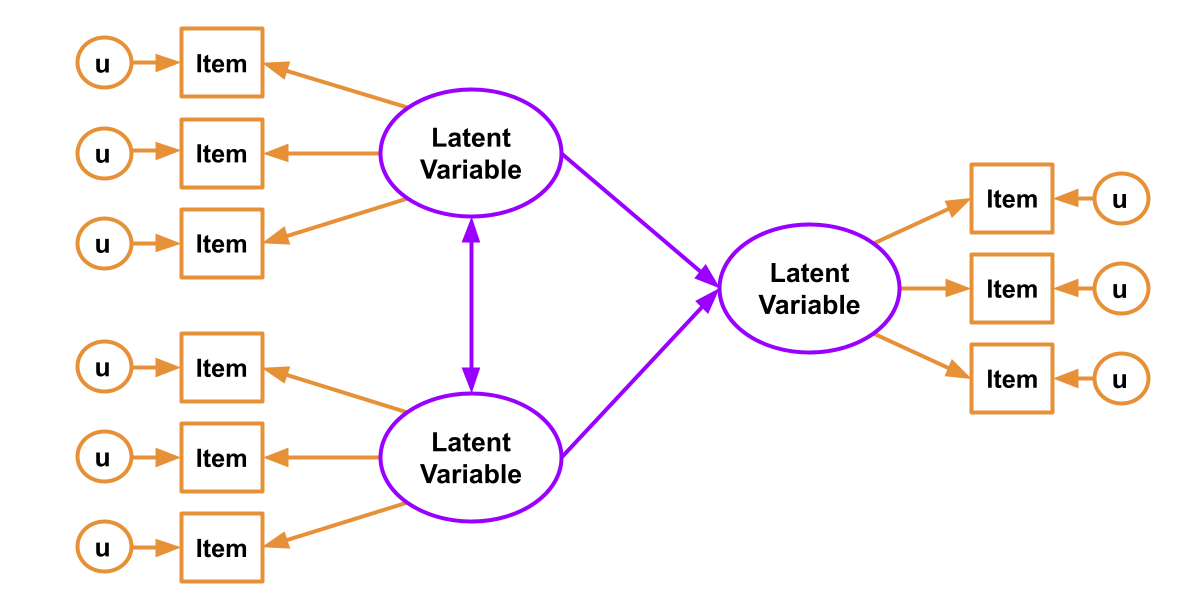
Figure 1: SEM diagram. Measurement model in orange, Structural model in purple
You can’t test the structural model if the measurement model is bad
If you test the relationships between a set of latent factors, and they are not reliably measured by the observed items, then this error propagates up to influence the fit of the structural model.
To test the measurement model, it is typical to saturate the structural model (i.e., allow all the latent variables to correlate with one another). This way any misfit is due to the measurement model only.
Fit Indices
Chi-Square - \(\chi^2\)
For structural equation models, a chi-square value can be obtained which reflects the discrepancy between the model-implied covariance matrix and the observed covariance matrix. We can then calculate a p-value for this chi-square statistic by using the chi-square distribution with the degrees of freedom equivalent to that of the model.
If we denote the population covariance matrix as \(\Sigma\) and the model-implied covariance matrix as \(\Sigma(\Theta)\), then we can think of the null hypothesis here as \(H_0: \Sigma - \Sigma(\Theta) = 0\). In this way our null hypothesis is that our theoretical model is correct (and can therefore perfectly reproduce the covariance matrix).
It is very sensitive to departures from normality, as well as sample size (for models with \(n>400\), the \(\chi^2\) is almost always significant), and can often lead to rejecting otherwise adequate models.
Absolute fit indices
“Absolute” measures of fit are based on comparing our model to a (hypothetical) perfectly fitted model. So we get an indication of “how far from perfect fit” our model is. Bigger values on these measures tend to indicate worse fit.
Standardised Root Mean Square Residual - SRMR
Standardised root mean square residual (SRMR) summarises the average covariance residuals (discrepancies between observed and model-implied covariance matrices). Smaller SRMR equates to better fit.
Common cut-offs for SRMR:
- \(<0.08\) : Good fit
Root Mean Square Error of Approximation - RMSEA
The RMSEA is another measure of absolute fit, but it penalises for the complexity of the model. Based on the \(\chi^2/df\) ratio, this measure of fit is intended to take into account for the fact the model might hold approximately (rather than exactly) in the population.
Typical cut-offs for RMSEA:
- \(<0.05\) : Close fit
- \(>0.1\) : Poor fit
Incremental fit
“Incremental” fit indices are more similar to how we think about \(R^2\). A value of 0 is the worst possible fitting model, and values of 1 is the best possible fitting model. These fit indices compare the fit of the model to the that of a baseline model. In most cases, this is the null model, in which there are no relationships between latent variables (i.e., covariances among latent variables are all assumed to be zero).
Tucker Lewis Index (TLI) and Comparative Fit Index (CFI)
Both of these (TLI & CFI) are somewhat sensitive to the average size of correlations in the data. If the average correlation between variables is low, then these indices will not be very high.
Apparently (not sure where this comes from), TLI and CFI shouldn’t be considered if the RMSEA for the null model is \(<.158\) (you can quickly get the RMSEA for the null model by using nullRMSEA(my_fitted_model) from the semTools package).
Common cut-offs for TLI:
- \(<0.9\) : Poor fit
- \(1\) : Very good fit
- \(>1\) : Possible overfitting
Common cut-offs for CFI:
- \(\sim 1\) : Good fit
To compare multiple models
Akaike Information Criterion - AIC
Baysian Information Criterion - BIC
Sample Size Adjusted BIC - SSBIC
We have already been introduced to AIC and BIC in the regression world, but we now add to that the sample size adjusted BIC (SSBIC). These indices are only meaningful when making comparisons, meaning that two different models must be estimated. Lower values indicate better fit. comparing mode The AIC is a comparative measure of fit and so it is meaningful only when two different models are estimated. Lower values indicate a better fit and so the model with the lowest AIC is the best fitting model. There are somewhat different formulas given for the AIC in the literature, but those differences are not really meaningful as it is the difference in AIC that really matters:
Local Fit (Modification Indices)
In addition to the overall fit of our model, we can look at specific parameters, the inclusion of which may improve model fit. These are known as modification indices, and you can get them from passing a SEM object to modindices() or modificationindices(). They provide the estimated value for each additional parameter, and the improvement in the \(\chi^2\) value that would be obtained with its addition to the model. Note that it will be tempting to look at modification indices and start adding to your model to improve fit, but this should be strongly guided by whether the additional paths make theoretical sense. Additionally, once a path is added, and modification indices are computed on the new model, you may find some completely different paths are suggested as possibly modification indices!
Exercises
A researcher wants to apply the theory of planned behaviour to understand engagement in physical activity. The theory of planned behaviour is summarised in Figure 2 (only the latent variables and not the items are shown). Attitudes refer to the extent to which a person had a favourable view of exercising; subjective norms refer to whether they believe others whose opinions they care about believe exercise to be a good thing; and perceived behavioural control refers to the extent to which they believe exercising is under their control. Intentions refer to whether a person intends to exercise and ‘behaviour’ is a measure of the extent to which they exercised. Each construct is measured using four items.
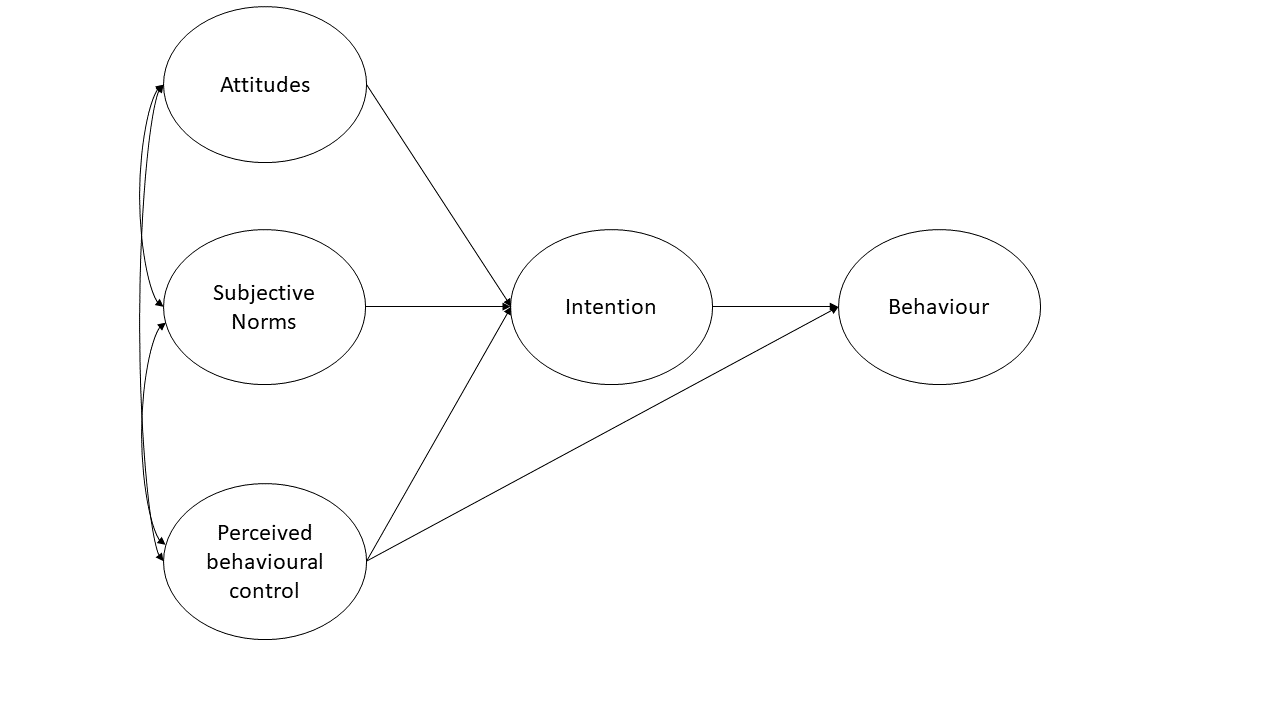
Figure 2: Theory of planned behaviour (latent variables only)
The data is available either:
- as a .RData file: https://uoepsy.github.io/data/TPB_data.Rdata
- as a .txt file: https://uoepsy.github.io/data/TPB_data.txt
Read in the data using the appropriate function. We’ve given you .csv files for a long time now, but it’s good to be prepared to encounter all sorts of weird filetypes.
Can you successfully read in from both types of data?
Test separate one-factor models for each construct.
Are the measurement models satisfactory? (check their fit measures).
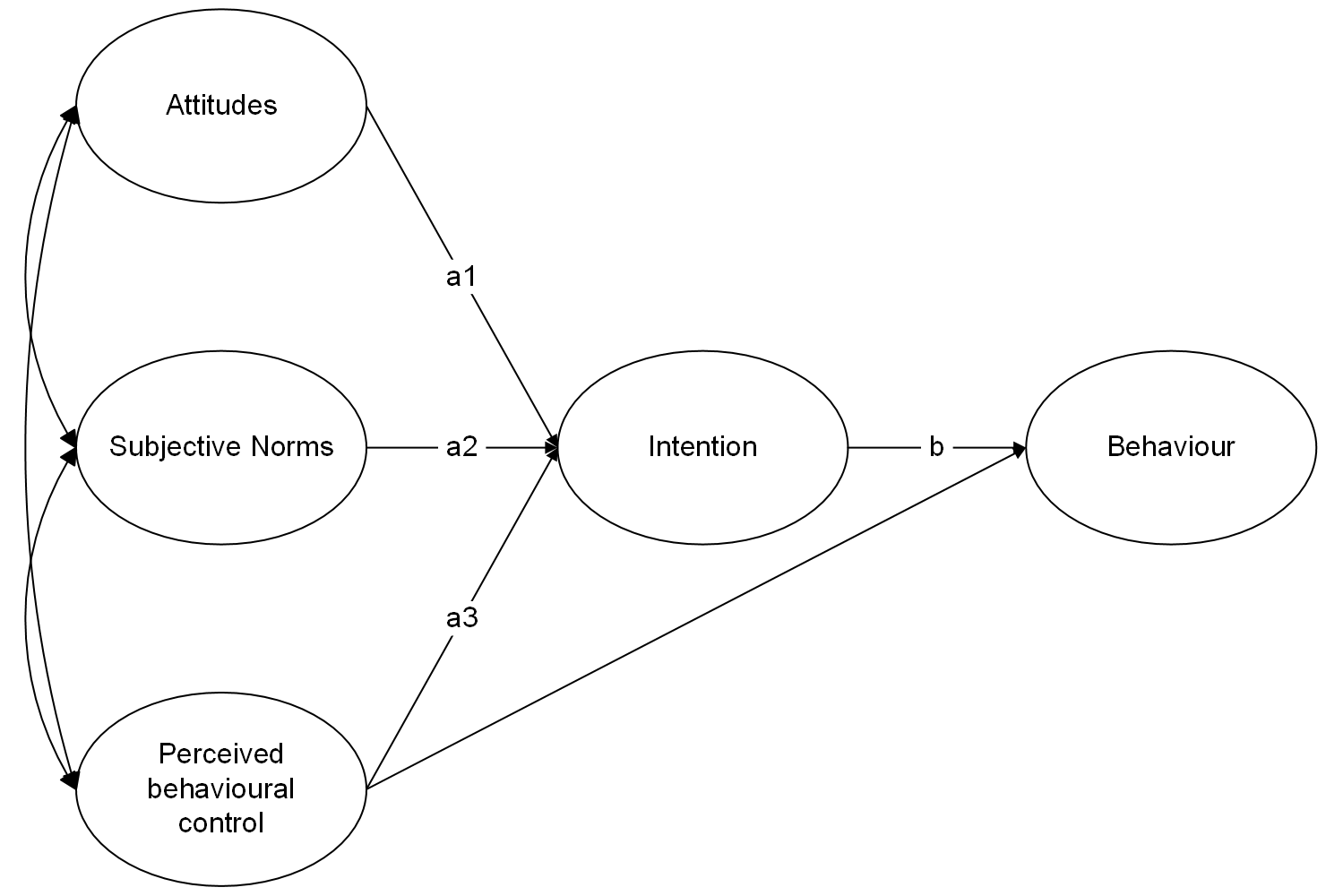
Using lavaan syntax, specify a structural equation model that corresponds to the model in Figure 2. For each construct use a latent variable measured by the corresponding items in the dataset.
Estimate the model from Question A4 and evaluate the model
- Does the model fit well?
- Are the hypothesised paths significant?
Examine the modification indices and expected parameter changes - are there any additional parameters you would consider including?
Test the indirect effect of attitudes, subjective norms, and perceived behavioural control on behaviour via intentions.
Remember, when you fit the model with sem(), use se='bootstrap' to get boostrapped standard errors (it may take a few minutes). When you inspect the model using summary(), get the 95% confidence intervals for parameters with ci = TRUE.
Write up your analysis as if you were presenting the work in academic paper, with brief separate ‘Method’ and ‘Results’ sections

{kind=link}
Of course this all assuming that the scales aren’t completely miscalibrated↩︎