Path Analysis
This week we are temporarily putting aside the idea of latent variables, and looking in more depth at the framework for fitting and testing models as a system of variables connected by arrows (or “paths”).
Next week, we bring this technique together with what we have learned about latent variable modelling (i.e., the idea of a latent “factor”), to enable us to build some really quite sophisticated models.
Motivating Path Analysis
Over the course of USMR and the first block of this course, you have hopefully become pretty comfortable with the regression world, and can see how it is extended to lots of different types of outcome and data structures. So far in MSMR our discussion of regressions have all focused on how this can be extended to multiple levels. This has brought so many more potential study designs that we can now consider modelling - pretty much any study where we are interested in explaining some outcome variable, and where we have sampled clusters of observations (or clusters of clusters of clusters of … etc.).
But we are still restricted to thinking, similar to how we thought in USMR, about one single outcome variable. In fact, if we think about the structure of the fixed effects part of a model (i.e., the bit we’re specifically interested in), then we’re still limited to thinking of the world in terms of “this is my outcome variable, everything else predicts it”.
Regression as a path diagram
- Imagine writing the names of all your variables on a whiteboard
- Specify which one is your dependent (or “outcome” or “response”) variable.
- Sit back and relax, you’re done!
We can visualise our multiple regression model like this:
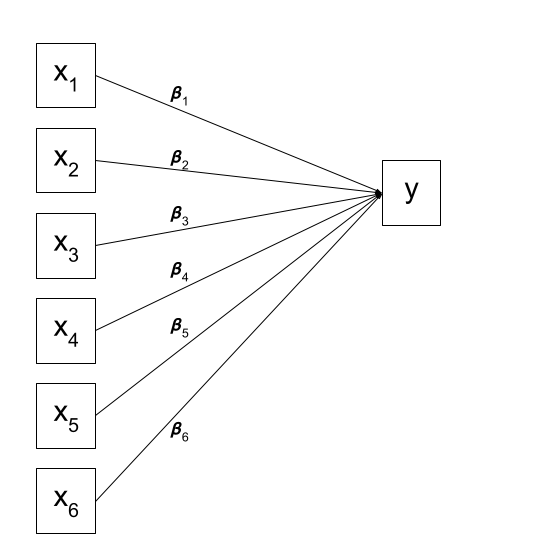
Figure 1: In multiple regression, we decide which variable is our outcome variable, and then everything else is done for us
Of course, there are a few other things that are included (an intercept term, the residual error, and the fact that our predictors can be correlated with one another), but the idea remains pretty much the same:
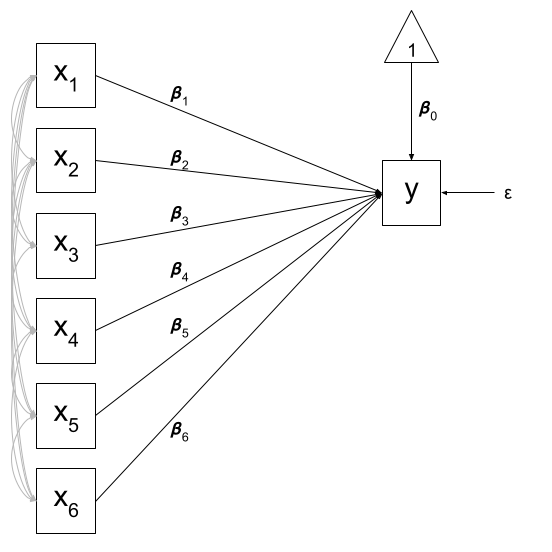
Figure 2: Multiple regression with intercept, error, predictor covariances
Theories and Models
What if I my theoretical model of the world doesn’t fit this structure?
Let’s suppose I have 5 variables: Age, Parental Income, Income, Autonomy, and Job Satisfaction. I draw them up on my whiteboard: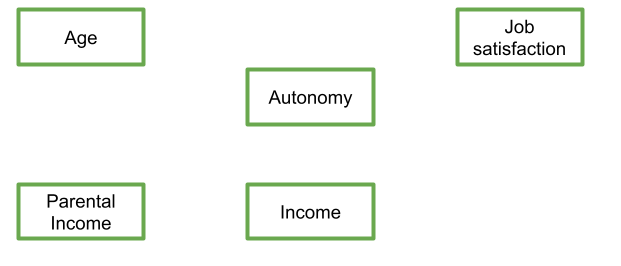
Figure 3: My variables
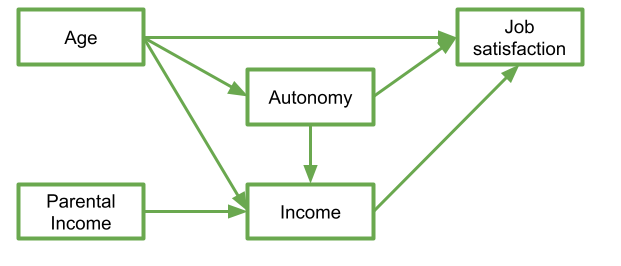
Figure 4: My theory about my system of variables
In this diagram, a persons income is influenced by their age, their parental income, and their level of autonomy, and in turn their income predicts their job satisfaction. Job satisfaction is also predicted by a persons age directly, and by their level of autonomy, which is also predicted by age. It’s complicated to look at, but in isolation each bit of this makes theoretical sense.
Take each arrow in turn and think about what it represents:
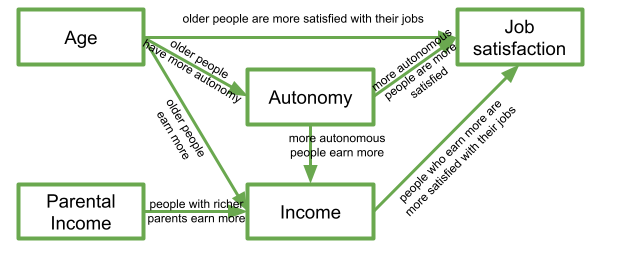
If we think about trying to fit this “model” with the tools that we have, then we might end up wanting to fit three separate regression models, which between them specify all the different arrows in the diagram:
\[ \begin{align} \textrm{Job Satisfaction} & = \beta_0 + \beta_1(\textrm{Age}) + \beta_2(\textrm{Autonomy}) + \beta_3(\textrm{Income}) + \varepsilon \\ \textrm{Income} & = \beta_0 + \beta_1(\textrm{Age}) + \beta_2(\textrm{Autonomy}) + \beta_3(\textrm{Parental Income}) + \varepsilon \\ \textrm{Autonomy} & = \beta_0 + \beta_1(\textrm{Age}) + \varepsilon \\ \end{align} \]
In this case, our theoretical model involves having multiple endogenous (think “outcome”) variables. So what do we do if we want to talk about how well the entire model (Figure 4) fits the data we observed? This is where path analysis techniques come in handy.
New terminology!
- Exogenous variables are a bit like what we have been describing with words like “independent variable” or “predictor”. In a SEM diagram, they have no paths coming from other variables in the system, but have paths going to other variables.
- Endogenous variables are more like the “outcome”/“dependent”/“response” variables we are used to. They have some path coming from another variable in the system (and may also - but not necessarily - have paths going out from them).
Introducing Path Analysis
It might help to think of the starting point of path analysis as drawing the variables on a whiteboard and drawing arrows to reflect your theory about the system of variables that you observed (much like in Figure 3 and 4 above).
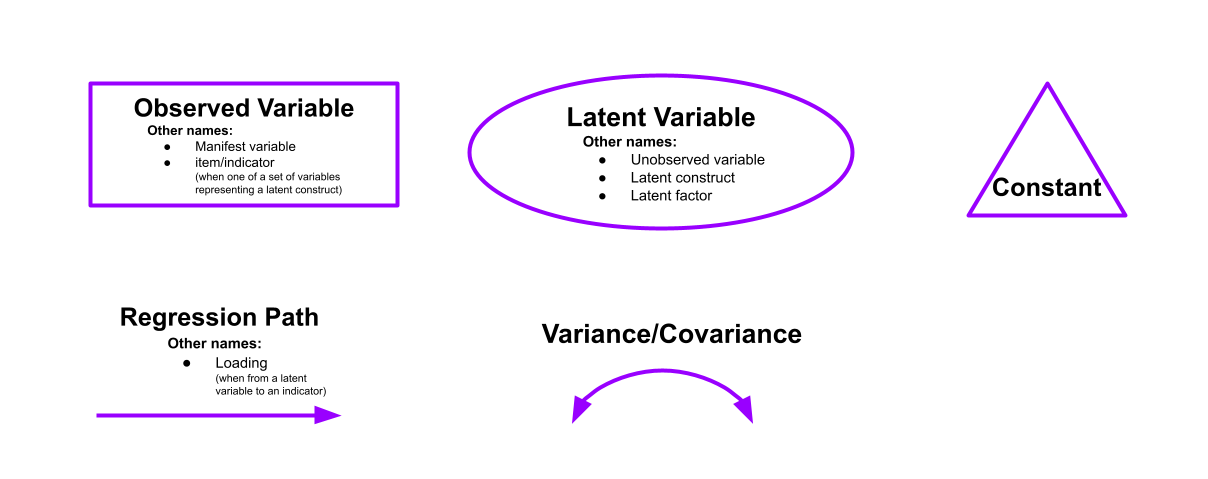
As it happens, we have already seen the conventions for how to depict variables and parameters in these type of diagrams in last week’s lab: by using rectangles (observed variables), ovals (latent variables), single headed arrows (regression paths) and double headed arrows (covariances), we can draw various model structures (as mentioned at the top of this page, we are temporarily putting aside the latent variables today).
We could try to fit some of these more complex models by just using lm() many times over and fitting various regression models. Path analysis is a bit like this, but all in one. It involves fitting a set of regression equations simultaneously. One obvious benefit of this is that it can allow us to talk about “model fit” (in the way we discussed in last week’s lab) in relation to our entire theory, rather than to individual regressions that make up only part of the theoretical model.
Refresher on path diagrams
- Observed variables are represented by squares or rectangles. These are the named variables of interest which exist in our dataset - i.e. the ones which we have measured directly.
- Latent variables are represented as ovals/ellipses or circles.
- Covariances are represented by double-headed arrows. In many diagrams these are curved.
- Regressions are shown by single headed arrows (e.g., an arrow from \(x\) to \(y\) for the path \(y \sim x\)). Factor loadings are also regression paths.
Recall that specifying a factor structure is simply to say that some measured variables \(y_i\) are each regressed onto some unmeasured factor(s) - \(y = \lambda \cdot F + u\) looks an awful lot like \(y = \beta \cdot x + \epsilon\)!!).
Mediation
Another benefit is that we are no longer limited to studying only simple relationships between x and y, we can now study how x might change z which in turn might change y.
As an example, let’s imagine we are interested in peoples’ intention to get vaccinated, and we observe the following variables:
- Intention to vaccinate (scored on a range of 0-100)
- Health Locus of Control (HLC) score (average score on a set of items relating to perceived control over ones own health)
- Religiosity (average score on a set of items relating to an individual’s religiosity).
We are assuming here that we do not have the individual items, but only the scale scores (if we had the individual items we might be inclined to model religiosity and HLC as latent variables!).
If we draw out our variables, and think about this in the form of a standard regression model with “Intention to vaccinate” as our outcome variable, then all the lines are filled in for us (see Figure 5)
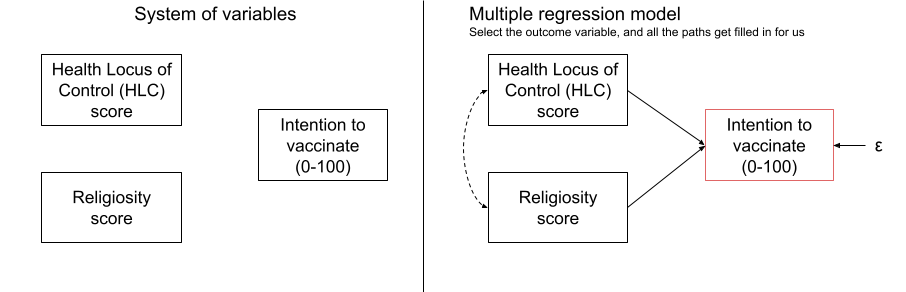
Figure 5: Multiple regression: choose your outcome, sit back and relax
But what if our theory suggests that some other model might be of more relevance? For instance, what if we believe that participants’ religiosity has an effect on their Health Locus of Control score, which in turn affects the intention to vaccinate (see Figure 6)?
In this case, the HLC variable is thought of as a mediator, because is mediates the effect of religiosity on intention to vaccinate. We are specifying presence of a distinct type of effect: direct and indirect.
Direct vs Indirect
In path diagrams:
- Direct effect = one single-headed arrow between the two variables concerned
- Indirect effect = An effect transmitted via some other variables
If we have a variable \(X\) that we take to ‘cause’ variable \(Y\), then our path diagram will look like so:
 In this diagram, path \(c\) is the total effect. This is the unmediated effect of \(X\) on \(Y\).
In this diagram, path \(c\) is the total effect. This is the unmediated effect of \(X\) on \(Y\).
However, while the effect of \(X\) on \(Y\) could in part be explained by the process of being mediated by some variable \(M\), the variable \(X\) could still affect \(Y\) directly.
Our mediating model is shown below:
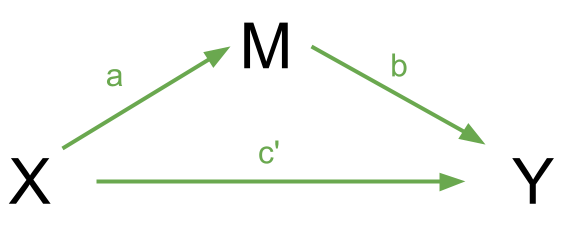
In this case, path \(c'\) is the direct effect, and paths \(a\) and \(b\) make up the indirect effect.
You will find in some areas people talk about the ideas of “complete” vs “partial” mediation. “Complete mediation” is when \(X\) no longer affects \(Y\) after \(M\) has been controlled (so path \(c'\) is not significantly different from zero), and “partial mediation” is when the path from \(X\) to \(Y\) is reduced in magnitude when the mediator \(M\) is introduced, but still different from zero.
. I haven't properly read it though!](images/path/path2.png)
Figure 6: Mediation as a path model. If you’re interested, you can find the inspiration for this data from the paper here. I haven’t properly read it though!
Now that we’ve seen how path analysis works, we can use that same logic to investigate models which have quite different structures, such as those including mediating variables. So if we can’t fit our theoretical model into a regression framework, let’s just fit it into a framework which is lots of regressions smushed together!
Luckily, we can just get the lavaan package to do all of this for us. So let’s look at fitting the model in Figure 6.
First we read in our data:
vax <- read_csv("https://uoepsy.github.io/data/vaxdat.csv")
summary(vax)## religiosity hlc intention
## Min. :-1.0 Min. :0.40 Min. :39.0
## 1st Qu.: 1.8 1st Qu.:2.00 1st Qu.:59.0
## Median : 2.4 Median :3.00 Median :64.0
## Mean : 2.4 Mean :2.99 Mean :65.1
## 3rd Qu.: 3.0 3rd Qu.:3.60 3rd Qu.:74.0
## Max. : 4.6 Max. :5.80 Max. :88.0Then we specify the relevant paths:
med_model <- "
intention ~ religiosity
intention ~ hlc
hlc ~ religiosity
"If we fit this model as it is, we won’t actually be testing the indirect effect, we will simply be fitting a couple of regressions.
To do that, we need to explicitly define the indirect effect in the model, by first creating a label for each of its sub-component paths, and then defining the indirect effect itself as the product of these (click here for a lovely pdf explainer from Aja on why the indirect effect is calculated as the product).
In lavaan, we use a new operator, :=, to create this estimate.
med_model <- "
intention ~ religiosity
intention ~ b*hlc
hlc ~ a*religiosity
indirect := a*b
":=
This operator ‘defines’ new parameters which take on values that are an arbitrary function of the original model parameters. The function, however, must be specified in terms of the parameter labels that are explicitly mentioned in the model syntax.
Note. The labels we use are completely up to us. This would be equivalent:
med_model <- "
intention ~ religiosity
intention ~ peppapig * hlc
hlc ~ kermit * religiosity
indirect := kermit * peppapig
"Finally, we estimate our model.
It is common to estimate the indirect effect using bootstrapping (a method of resampling the data with replacement, thousands of times, in order to empirically generate a sampling distribution). We can do this easily in lavaan, using the sem() function:
mm1.est <- sem(med_model, data=vax, se = "bootstrap") And we can get out estimates for all our parameters, including the one we created called “indirect”.
summary(mm1.est, ci = TRUE)## lavaan 0.6.15 ended normally after 1 iteration
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 5
##
## Number of observations 100
##
## Model Test User Model:
##
## Test statistic 0.000
## Degrees of freedom 0
##
## Parameter Estimates:
##
## Standard errors Bootstrap
## Number of requested bootstrap draws 1000
## Number of successful bootstrap draws 1000
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) ci.lower ci.upper
## intention ~
## religiosty 0.270 1.022 0.265 0.791 -1.583 2.382
## hlc (b) 5.971 0.933 6.397 0.000 4.044 7.747
## hlc ~
## religiosty (a) 0.508 0.086 5.916 0.000 0.348 0.680
##
## Variances:
## Estimate Std.Err z-value P(>|z|) ci.lower ci.upper
## .intention 62.090 7.926 7.834 0.000 45.650 77.632
## .hlc 0.753 0.100 7.572 0.000 0.552 0.927
##
## Defined Parameters:
## Estimate Std.Err z-value P(>|z|) ci.lower ci.upper
## indirect 3.033 0.655 4.633 0.000 1.825 4.344Mediation Exercises
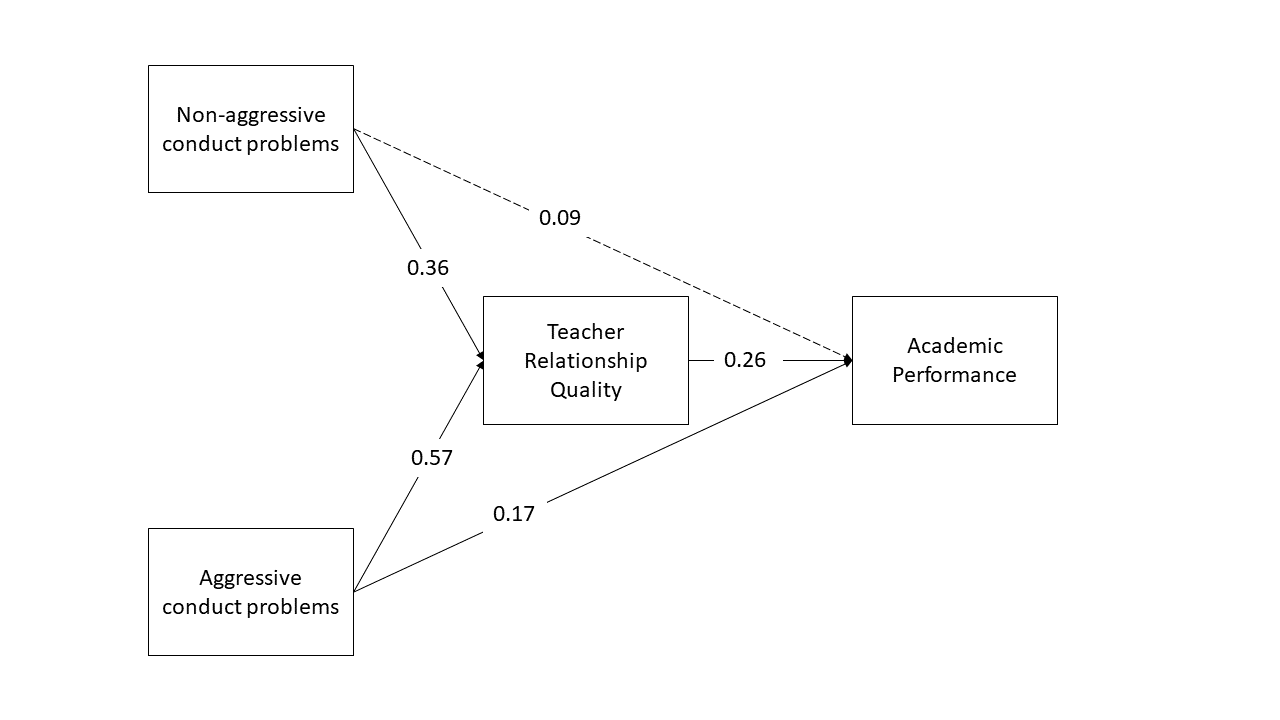
This week’s lab focuses on the technique of path analysis using the same context as previous weeks: conduct problems in adolescence. In this week’s example, a researcher has collected data on n=557 adolescents and would like to know whether there are associations between conduct problems (both aggressive and non-aggressive) and academic performance and whether the relations are mediated by the quality of relationships with teachers.
The data is available at https://uoepsy.github.io/data/cp_teachacad.csv
First, read in the dataset.
Use the sem() function in lavaan to specify and estimate a straightforward linear regression model to test whether aggressive and non-aggressive conduct problems significantly predict academic performance.
How do your results compare to those you obtain using the lm() function?
Now specify a model in which non-aggressive conduct problems have both a direct and indirect effect (via teacher relationships) on academic performance.
Sketch the path diagram using the website suggested in the lecture, https://www.diagrams.net/. To export the diagram to PNG, click File -> Export As -> PNG.
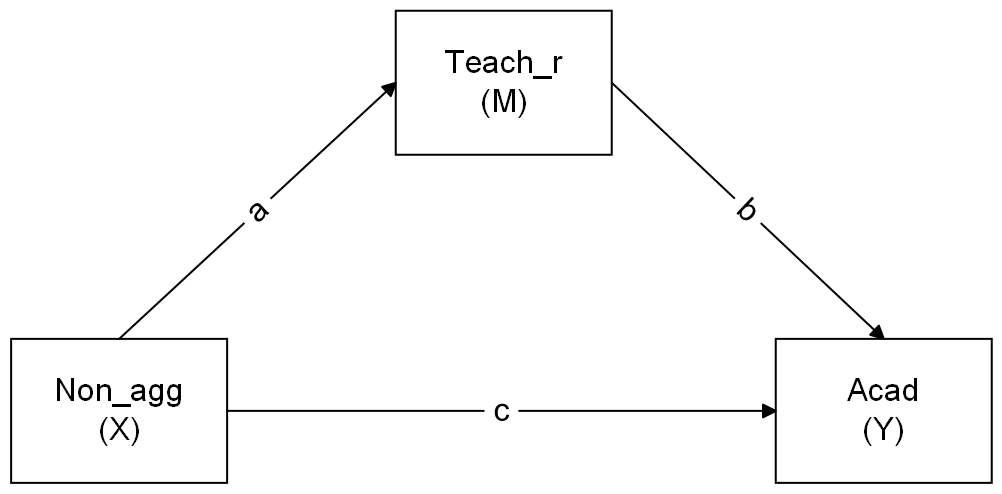
Now define the indirect effect in order to test the hypothesis that non-aggressive conduct problems have both a direct and an indirect effect (via teacher relationships) on academic performance.
Fit the model and examine the 95% CI.
Specify a new parameter which is the total (direct+indirect) effect of non-aggressive conduct problems on academic performance
Now visualise the estimated model and its parameters using the semPaths() function from the semPlot package.
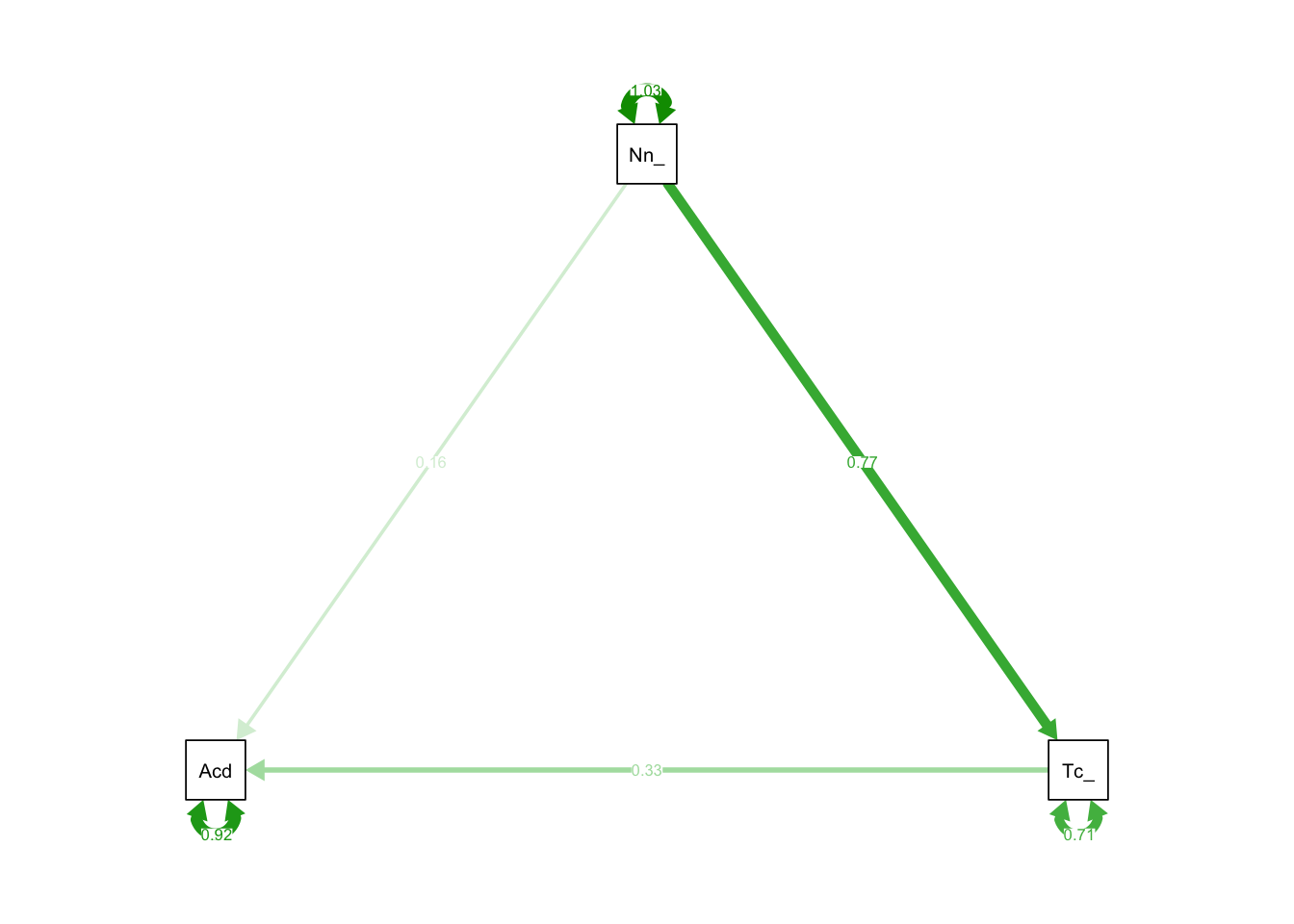
A more complex model
Using the website website suggested in the lecture, https://www.diagrams.net/, sketch the path diagram for a model in which both aggressive and non-aggressive conduct problems have both direct and indirect effects (via teacher relationships) on academic performance. To export the diagram to PNG, click File -> Export As -> PNG.
Now specify the model in R, taking care to also define the parameters for the indirect effects.
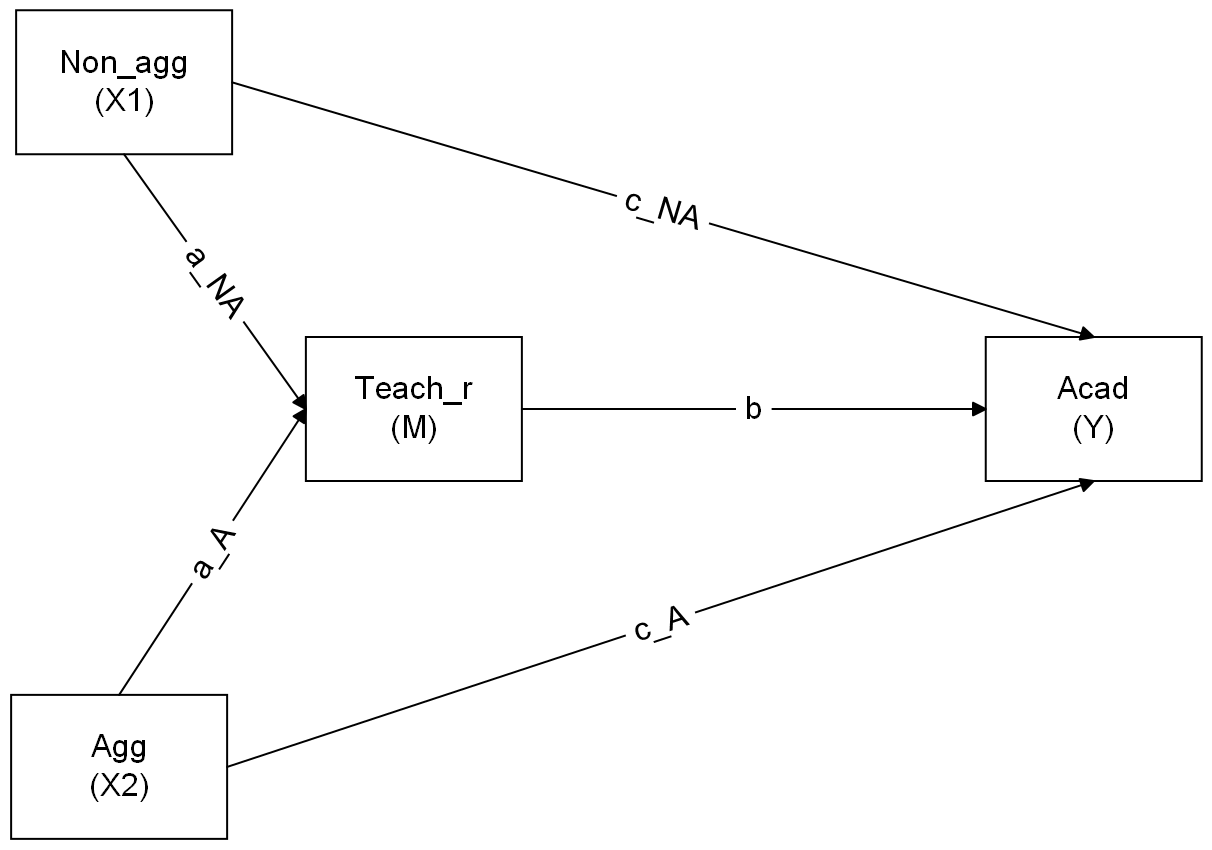
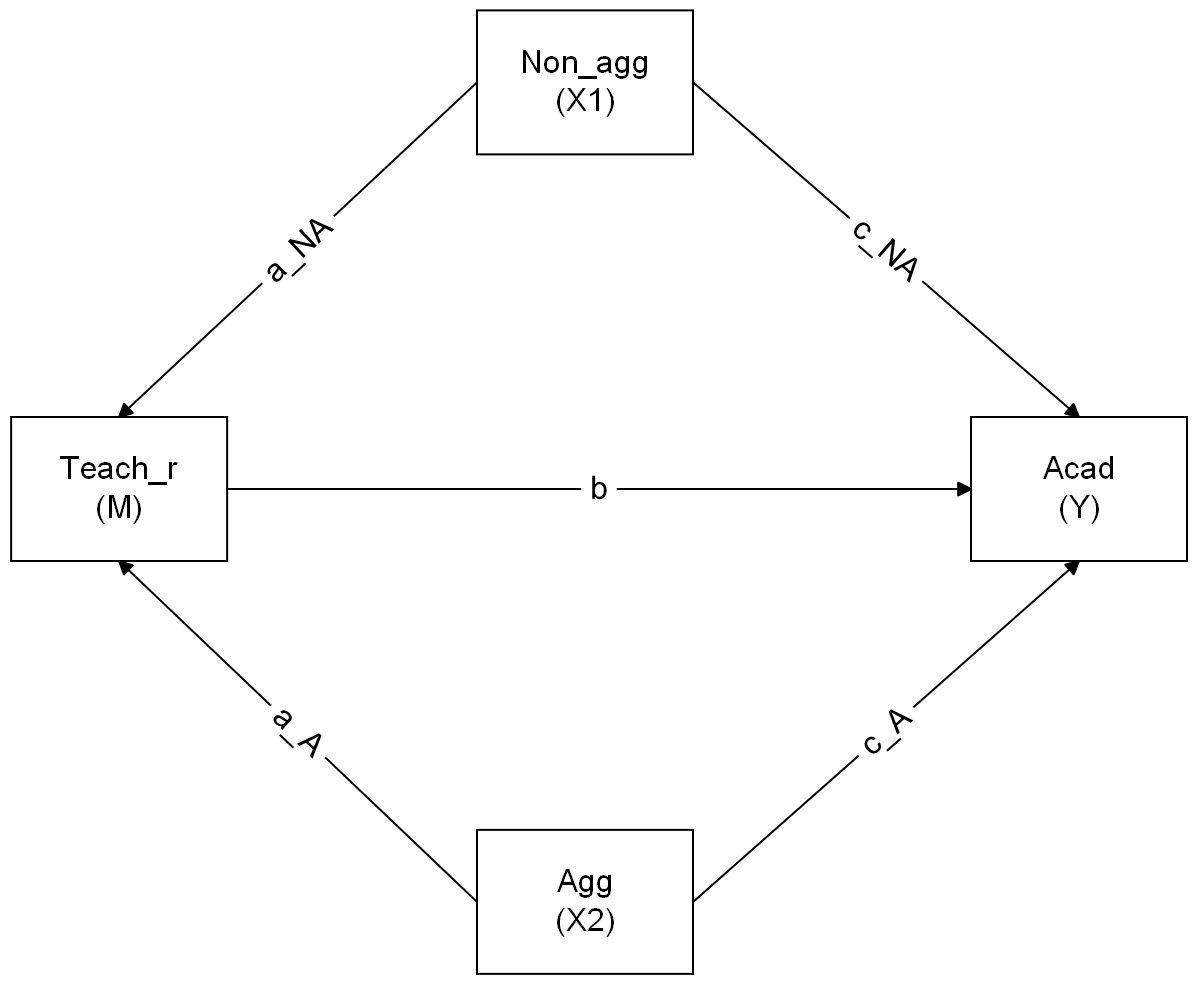
Now estimate the model and test the significance of the indirect effects
Write a brief paragraph reporting on the results of the model estimates in Question B2. Include a Figure or Table to display the parameter estimates.