
6: Validity & Reliability
- Nailing down what we mean by “validity” and “reliability” of measurement
- Highlighting some of the key types of construct validity and how they are assessed
- Providing a diagrammatic framework for reliability of measurement and then introduce how we estimate this quantity in different scenarios
Bad measurement is sometimes a bit like the rotten apple that spoils the entire barrel.
A huge amount of research questions are focused on ‘associations between’ , ‘effects on’, ‘differences in’, ‘change in’ some construct or other. For any of these research studies to be successful we need to be able to actually measure that construct, and measure it well.
Consider the idea that we might have some research question that is concerned with how some intervention might reduce “anxiety”. While “anxiety” is quite an abstract concept, on the face of it, the idea that we all have different “levels of anxiety” feels okay. The problems come as soon as we attempt to quantify it.
When we talk with friends we might tell them that we are feeling “a bit more anxious today”, but our friends will probably never respond with “how much more? 3? or 4?”. Contrast this with how we might talk about something like running - we tell our friends that we “went for a really fast run today”, and they may well respond with “oh yeah? what was your pace?” It’s much easier to quantify something concrete and measurable than it is to quantify some abstract psychological construct.
One reason it’s difficult to quantify abstract psychological constructs is because they are multifaceted - “anxiety” is quite a big concept, which we can think of from various angles. We want to be confident that when we ask person A about their anxiety, they are responding about the same thing as when we ask person B. One way to feel more confident about this is to ask a bunch of questions that get at the concept from various angles, and hope that the commonalities between these variables comes through.
So we might end up with 5 questions that we ask them to indicate agreement/disagreement with (Figure 1), and then we’re up and running!
However, it’s not quite a simple as just “to measure X let’s ask a bunch of questions about X”. Very loosely, we can differentiate between two measurement related threats to research.
The first we should think about is termed “construct validity”. Construct validity is concerned with whether people filling out the questionnaire in Figure 1 is actually capturing anything about their levels of “anxiety”. If you take a look at the wordings of the questions, you could argue that they are all statements about behaviours we consider to be a result of anxiety (i.e., avoidance behaviours, excessive worry, reassurance seeking, etc). But switch your perspective and consider how they could be seen as behaviours that represent healthy coping strategies (i.e., proactive stress management, social support utilization etc.). So what do these 5 questionnaire items measure? What does it mean if I indicate “strongly agree” to all 5 items? Does it mean I have more “anxiety”? Or does it mean I have better “coping strategies”? Neither? Both?
The second measurement related threat is the idea of the “consistency” or “reliability” of measurement. Reliability is concerned with what happens if a person fills out the questionnaire in Figure 1 multiple times. Assuming they have not changed in their underlying anxiety, then we would hope that on every occasion, their score would be the same.
- Validity: whether our measurement instrument actually measures the thing we think it measures.
- Reliability: how consistently our measurement instrument measures whatever it is measuring.
Within each of the threats of “validity” and “reliability”, there are various different forms. We will go through a selection of these and how we might try and assess them. It is worth keeping in mind these two broad definitions above, which will underpin everything we discuss here.
Often forgotten
One initial, and incredibly important thing to remember is that these concepts of “reliability” and “validity” can only ever be evaluated in a specific context.
Just because a measurement tool appears to be valid and reliable in one instance, it does not mean that it will continue to be valid or reliable when used for any other persons, or in any other place, or at any other time.
What this means is that when doing research we can’t just say “I used [insert measure here] that has been shown to be valid and reliable”, and simply assume that these properties also hold in our current study.
How are validity and reliability related?
Before we discuss individually the various forms of validity and reliability, it’s worth spending a few words on how the two concepts are related.
The key take-away here is that a measurement tool cannot be more valid than it is reliable. In other words, a tool’s reliability provides an upper bound for how valid the tool can possibly be.
A tool can be reliable without being valid. Think of a broken bathroom scale that shows the exact same weight every time. Highly reliable (it’s very consistent), but not at all valid (it doesn’t do a good job of measuring one’s actual weight).
But a tool cannot be valid without being reliable. Imagine we had a different broken bathroom scale. The way this scale is broken means that it shows a different random number every time. The results that this tool produces are inconsistent, so it can’t be an accurate measure of weight. In other words, the results that the tool produces aren’t reliable, so the tool cannot be valid.
In case you like to think about concepts visually, here’s a graphic representation of the relationship between validity and reliability:

The green “possible” triangle in the bottom right spans all of the combinations of reliability and validity that a measurement tool could possibly have. The “impossible” triangle in the top left is empty because no measurement tool can have big validity while also having small reliability.
Construct Validity

There are various different forms of validity, but broadly speaking they all come down to the idea of “if it walks like a duck and quacks like a duck…”1
- … does it look like a duck? (Face validity)
- … does it have all the key parts of a duck? (Content validity)
- … does the duck look like another duck? Can we tell it apart from a pigeon? (Convergent and discriminant validity)
- … how much does my duck look like “the perfect duck”? If I am a duck, will there be duck eggs in my future? (Criterion/predictive validity)
Face Validity
does it look like a duck?
Face validity is essentially asking whether, “on the face of it”, the measure appears to be measuring the construct. For instance, if we are measuring the construct “anxiety”, then do we have questions that refer to things that are about “anxiety”? These might be questions referring to “anxious”/“worried” feelings, or behaviours that we believe to be indicative of anxiety (fidgetting, trouble sleeping) etc. For a more objective example: a maths test that contains only arithmetic problems has good face validity of measuring math ability.
Face validity: The extent to which a measurement tool appears, on the surface, to measure what it claims to measure.
“Appearing on the surface to measure what it claims to measure” means that face validity can vary a lot, based on what a given community considers reasonable at a given moment in time. As such, face validity is not sufficient for claiming construct validity. For instance, back in the not so distant past, there were many prominent psychologists for whom measuring peoples’ skulls or looking at people’s handwriting were face-valid approaches of assessing personality.
Similarly, face validity is not necessary for construct validity. In fact, a lot of questions are designed to deliberately prevent respondents from figuring out the intended construct and so manipulating their answers. For instance, a question in the Minnesota Multiphasic Personality Inventory (MMPI) asks things like “I think I would like the work of a librarian” as an indicator of paranoia, because a preference for isolated work might indicate a withdrawing from social situations that is associated with paranoia.
Content Validity
does it have all the key parts of a duck?
The term “Content validity” is used to refer to the idea that a measure captures (loosely) ‘all important aspects’ of the construct. For example, if we have a measure of “anxiety”, then we want to ensure that we have items that are representative of the various things that we understand to be “anxiety”. We would hopefully have items that capture feelings of worriedness, but also items that capture behavioural responses (e.g., avoidance behaviours, or fidgetting and distraction behaviours), and some that capture anxious thoughts.
Content validity: The extent to which we have a representative sample of items to cover the content domains that are suggested by our theory.
If we don’t have content validity, then our measure might actually be capturing a much more narrow idea than we want (e.g., a specific type of, or feature of, anxiety).
Convergent & Discriminant Validity
Does the duck look like another duck? Can we tell it apart from a pigeon?
Both “face validity” and “content validity” are not easily assessed, and so ultimately it comes down to just reading the items and thinking about the theory of what we actually mean with some construct like “anxiety”.
However, there are forms of validity for which we can use stats to (albeit indirectly) inform our trust in the measurement: “convergent validity” and “discriminant validity”. Loosely speaking, when we assess convergent validity, we want to see whether the measure correlates with measures of other things that we’d (theoretically) expect it to correlate with. And when we assess discriminant validity, we want to see whether the measure doesn’t correlate with things that we’d expect it not to correlate with.
For example, if the five items in Figure 1 were part of a new measure called “The Edinburgh Anxiety Scale”2, then I would hope that this measure a) correlates highly with other established measures of anxiety (like the GAD-7) and b) correlates only weakly/moderately with something we don’t consider to be highly correlated with anxiety, such as a measure of depression (like the Beck depression inventory).
Optional: Why depression? Why not something really different?
If we want our measure to achieve high discriminant validity, then surely we’d do better if we compared anxiety against something really different from anxiety, like colour perception or spatial reasoning?
It’s true that a measure of anxiety is likely to be unrelated to a measure of colour perception. But they’re so unrelated that the comparison isn’t really that interesting.
We learn a lot more about our measure of anxiety if it’s unrelated from a related but distinct concept such as depression.
The key thing here is that we want to ensure that two measures of the same thing will be highly correlated, but also that measures of different things are not too highly correlated. This latter idea is important because we want to ensure that we’re not accidentally measuring something else! It leads back to the idea of the “jingle-jangle fallacies” - if I create a measure of “anxiety” I would like to be confident that it’s measuring something different from “depression”, say.
Convergent validity: The extent to which scores on a measurement tool are related to scores on other measures of the same construct.
Discriminant validity: The extent to which scores on a measurement tool do not correlate strongly with measures of unrelated constructs.
So how do we assess convergent and discriminant validity of our measure? We build what’s called a “nomological net”: a representation of how theoretical constructs are related to one another. To do this, we would measure people on “The Edinburgh Anxiety Scale” and also on the GAD7 and also on Beck’s Depression Inventory. We would then fit a CFA model and examine the correlations between the factors:
EAS =~ e1 + e2 + e3 + ....
GAD =~ g1 + g2 + g3 + ....
BDI =~ b1 + b2 + b3 + ....
EAS ~~ GAD
EAS ~~ BDI
GAD ~~ BDICriterion/Predictive validity
How much does my duck look like ‘the perfect duck’? If I am a duck, will there be duck eggs in my future?
Criterion validity assesses how well our measurements correlate with some other, separate ‘standard’. For example, we might be intersted in how well a short screening tool for cognitive impairment correlates with a full neuropsychological assessment.
Often, the ‘standard’ is some future event, and in this case, this idea gets termed ‘predictive validity’. A common example is that in the USA, many colleges have entrance exams, and so we might reasonably ask if scores on the exam predict their performance in their first year of college. Similarly, we might ask if scores on a driving test predict lower accident risk.
Criterion validity: The degree to which scores on a measurement tool correlate with some independent, external standard (or ‘criterion’). Very often this is the prediction of some future event, in which case we might talk about predictive validity.
Now we’ll move on from the first measurement-related threat to research, construct validity, to the second threat, reliability of measurement.
Reliability of measurement
The very high level idea of reliability can be captured by the various words we could use instead of ‘reliability’. We are talking about how
- reliable
- consistent
- repeatable
- precise
- stable
- dependable
- <insert-your-favourite-synonym-here>
a measurement is. However, because we want to quantify reliability for a given measurement instrument, we need a specific, mathematical definition.
As we hinted at earlier, the easiest way to get into thinking about reliability is probably to think about repeated assessment. If we measure person \(i\) using instrument \(x\) and then we measure person \(i\) using instrument \(x\) a second time (and we assume they haven’t changed on the underlying construct), then a perfectly reliable measure would give us the exact same scores.
For example, a reliable method of weighing a dog is to use the big specialised scales for pets that they have at the vets. A less reliable way is to awkwardly carry your dog onto your cheap bathroom scale and subtract your own weight to get the weight of only the dog. Even less reliable would be to go and do this outside on a bumpy surface like gravel, where the scales don’t work well, and decide to do it standing on one leg…
So one initial way to think about reliability in mathematical terms is to suppose that we do the measurement twice on the same units and see how well their scores correlate.
Let’s make this concrete with an example. Meet my dog Dougal. In reality, Dougal weighs 23.814346… kg.

I will weigh him, along with a bunch of other dogs, using two different measurement tools. I’ll use each measurement tool twice and record the values I get for each dog at time 1 and at time 2.
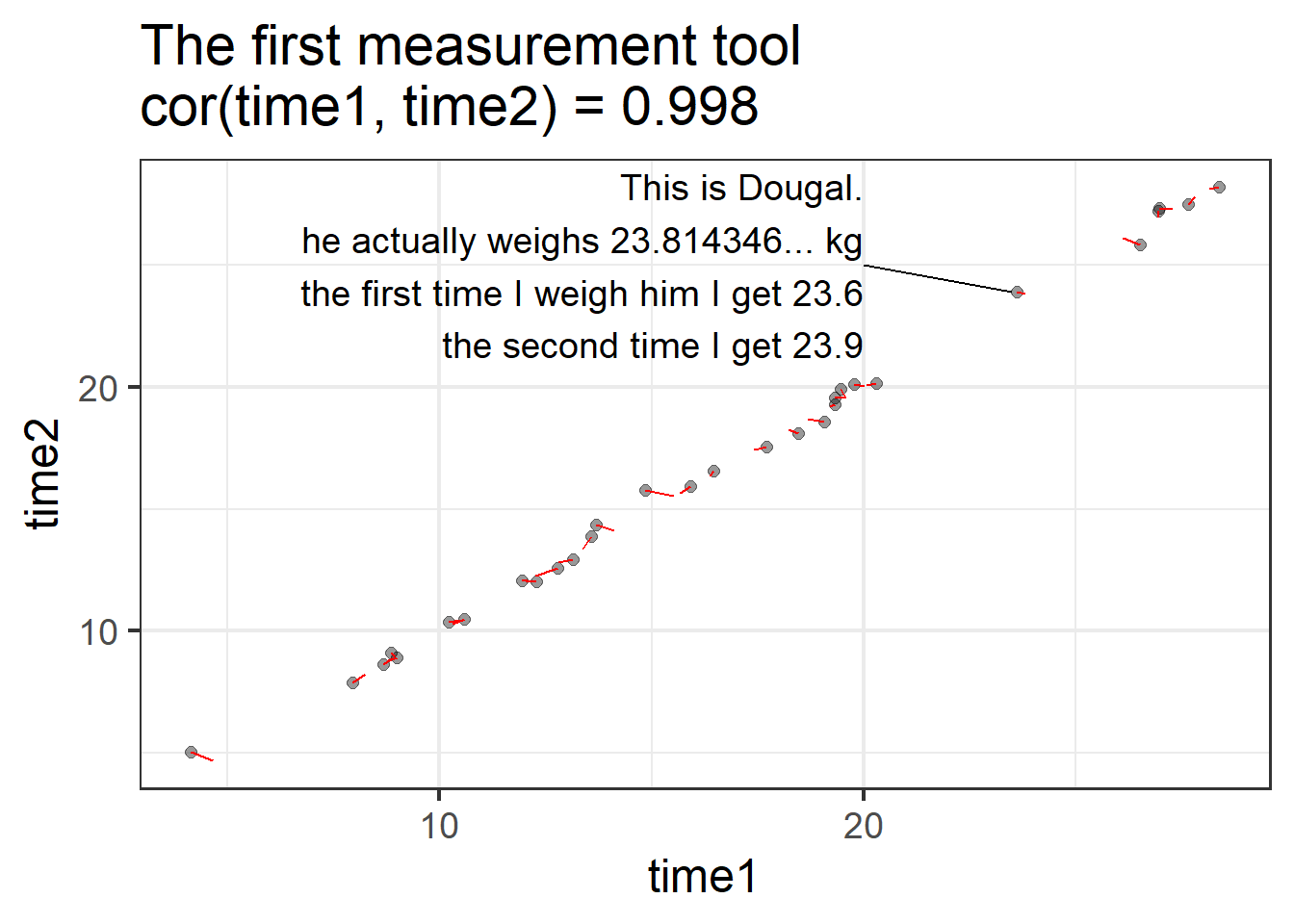
In this plot, each dog is represented by one dot. The dot shows their measured value at time 1 and at time 2. The red line shows how far the measured value is from their true weight (which, if the measure were perfectly reliable, would appear on the plot as a perfect diagonal). So the first measurement tool isn’t perfectly reliable, but the correlation between time 1 and time 2 is very good!
Now let’s look at the values produced by the second measurement tool at time 1 and at time 2:
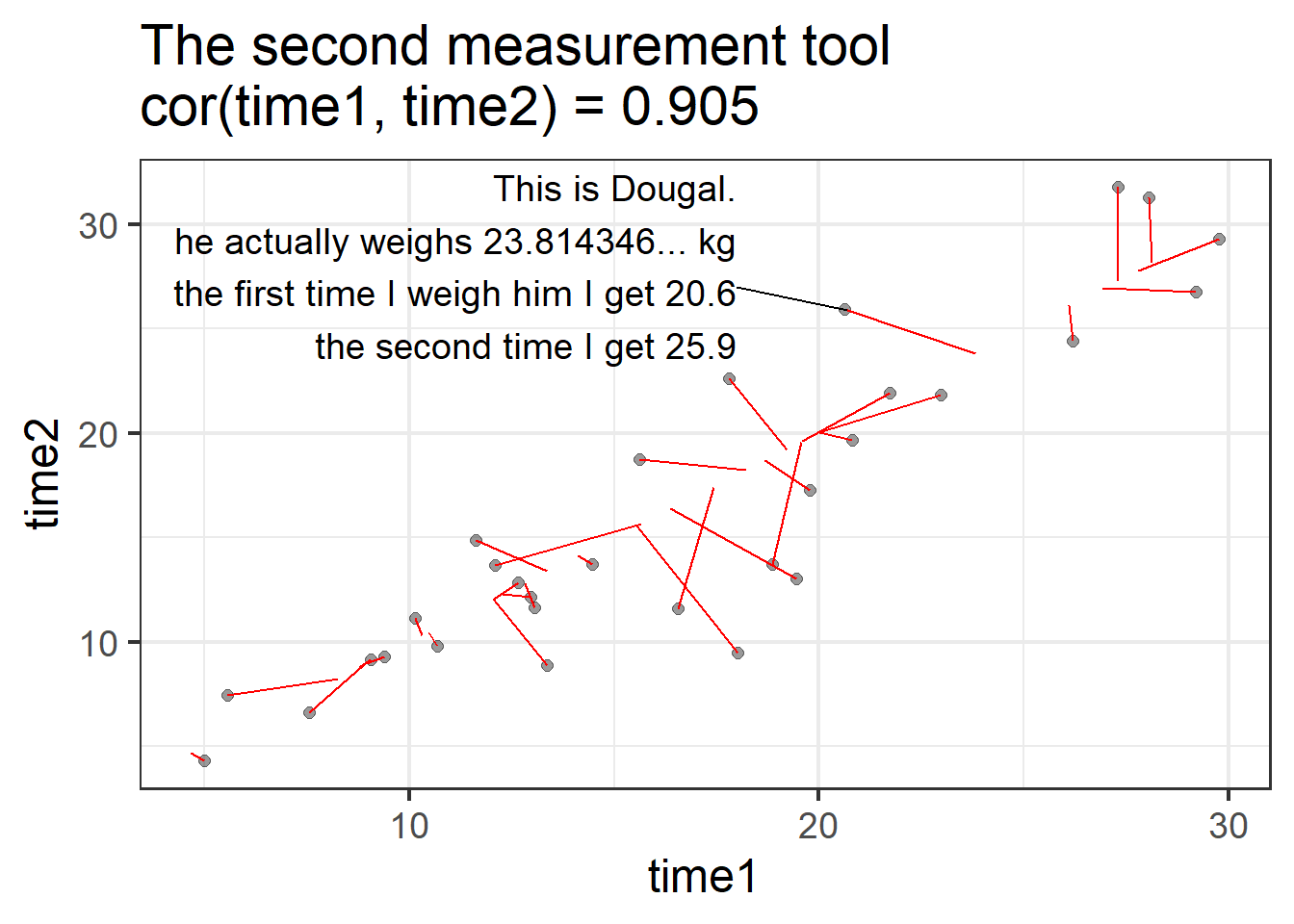
The second measurement tool is a bit less reliable: there’s more distance between the true value and the measured values, and the measurement tool produces values that change quite a bit from one time to the next.
Thinking about validity in terms of how well scores correlate if we apply the measure several different times is a good way to start. But it is hard to think about in situations where we haven’t measured the same units twice. A more generalisable way to conceive of reliability can be got at by thinking about measurement in a diagrammatic way. Which is great, because I love diagrams!
Truth and Error
love truth but pardon error (Voltaire)
So let’s go back to basics. Whenever we measure something, we get a number3. But there are almost always two things that make that number what it is: there is the “true” value of the construct that we’re measuring, and then there is error. This error might come from different things - it could be rounding error (our scales only display to the 10th of a kg), it could be random error due to a poor instrument (e.g., using our bathroom scales on some bumpy cobbles that happen to make it weigh higher/lower depending on where we position the scales), or it could be other stray causes that are unrelated to the construct we’re trying to measure (e.g., measurements of anxiety often include a question about sleep habits, but there are lots of other things that influence sleep!).
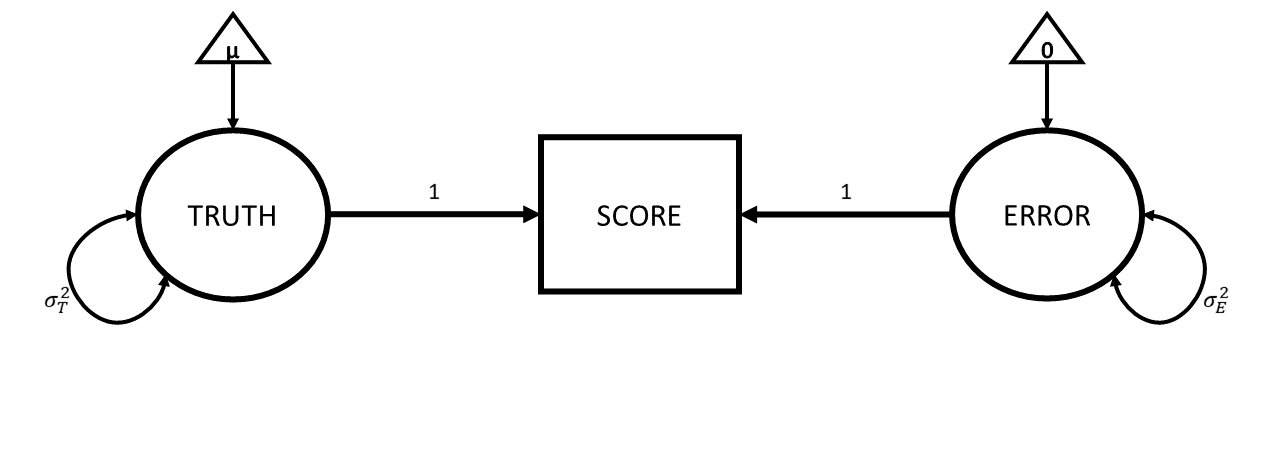
Drawing our diagram then, when we measure something, we observe one thing (the score), but this is caused by two unobserved things (the truth and some error). Following the conventions for drawing these sorts of diagram, things we observe are in squares, and unobservables are in circles.

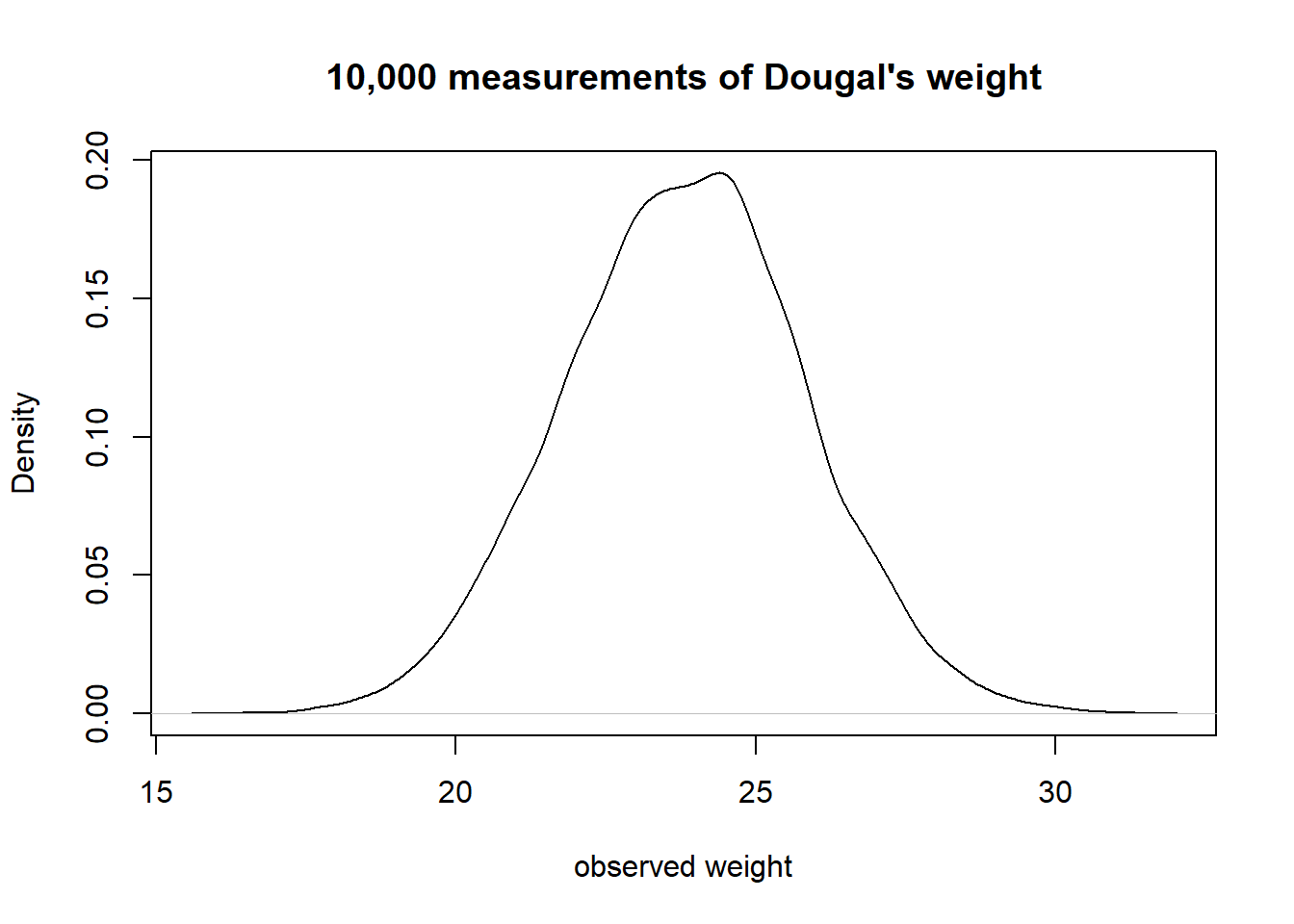
One way to make the idea of “truth” here a little more concrete: let’s suppose that I took my shoddy bathroom scales and weighed Dougal over and over and over and over again (ad infinitum). The numbers I get out will follow a normal distribution, the center of which we can think of as Dougal’s “true” weight (assuming the scales aren’t systematically biased). We often see weights a little higher, often a little lower, less often do we see things a lot higher or lower, etc. So “Truth” here refers to the idea of the ‘long run’ measurement.
Now let’s expand from thinking about Dougal specifically to thinking about our proposed measurement process for weighing dogs in general. We have our “instrument” for measuring a dog’s weights (our bathroom scales), and we can imagine all the measurements we might use this instrument for. For any dog we might use these scales to weigh, the observed number we see on the scales is going to be driven by 1) that dog’s true weight, and 2) a little bit of error. Just like all the true weights of all dogs have a variance (some are big dogs that weigh a lot, some are little dogs that weigh less etc.), the errors that contribute to our measurements also have a variance (some readings will be a bit higher than truth, some will be a bit lower).
If we add these variances to our diagram, we simply add curved lines to our “Truth” and “Error” variables:
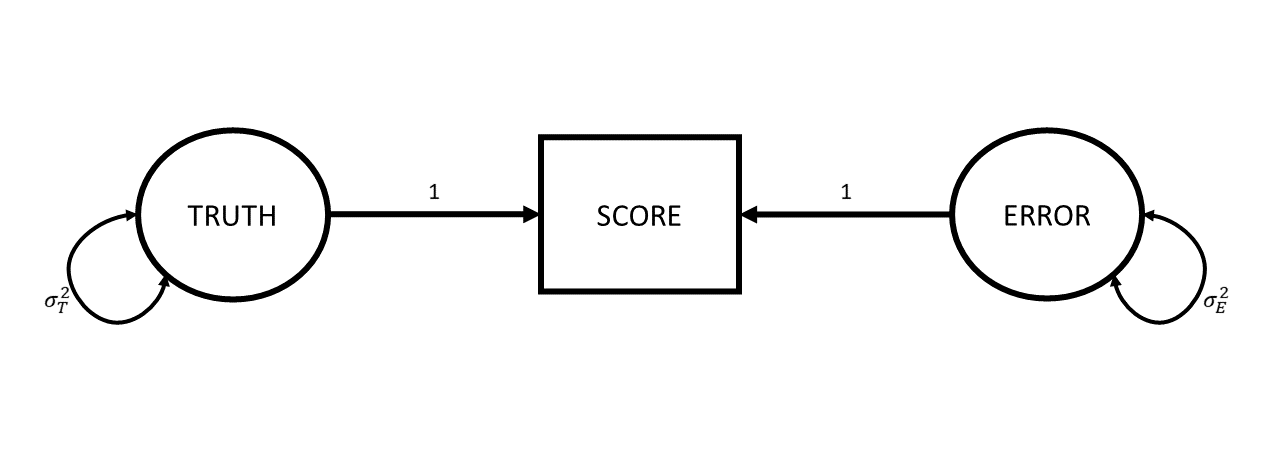
The really useful thing about diagrams like these is that they represent theoretical models that can be used to imply what we would expect to see in our observed variables (we saw this idea in CFA). One crucial thing that this specific diagrammatic model of measurement implies is that the variance we would see in our observed scores is going to be the variance in the true scores plus the variance in the errors.
\[ Var(\text{Observed Scores}) = Var(\text{True Scores}) + Var(\text{Errors}) \]
As it turns out, we can actually find an intuitive way of thinking about this equation. Let’s take it to the extreme: If my measurement instrument is incredibly good at weighing dogs, then the variance in the errors is much much smaller (i.e., all measurements are within 0.1kg of the true score). If my measurement instrument is incredibly bad at weighing dogs, then the variance in errors is much bigger (sometimes when I weigh a dog that is ‘in truth’ 23.814346….kg, I will get a score of 15kg, sometimes I will get a score of 28kg etc).
So a really generalisable way of thinking about reliability of measurement is to view it as “how much of the variance in our observed scores is due to true variance?”.
For example, how much of the variance in observed weights of dogs is due to how different the actual weights of our measured dogs are?
\[ \begin{align} \text{reliability} &= \frac{Var(\text{true scores})}{Var(\text{observed scores})} \\ & \quad \\ &= \frac{Var(\text{true scores})}{Var(\text{true scores}) + Var(\text{errors})} \end{align} \]
Why is it not just “how much error variance is there?”
We can’t simply use the variance of measurement error on its own to quantify ‘reliability’ here, because what counts as “small” or “large” amounts of error depends entirely on the quantity we are measuring.
For example, consider the following three scenarios:
- I am measuring the weight of dogs, and my scales are a bit off each time - there is a little bit of error. The errors have a variance of 1kg
- I am measuring the weight of dogs, and my scales are wayy off each time - there is a massive amount of error. The errors have a variance of 100kg
- I am measuring the weight of elephants, and my scales are a little bit off each time - there is a little bit of error. The errors have a variance of 100kg
The size of the error variance (1kg or 100kg) by itself doesn’t determine how much “off” (a little bit off vs waayy off) we consider the measurements to be. What is important is how big this error variance is relative to the true variance of the things being measured.
Elephants’ weights vary between 1800 and 4500kg, so mis-measuring by 100kg isn’t really that bad in the grand scheme of things. But dogs’ weights vary between about 5kg and 50kg, so mis-measuring by 100kg is ridiculous.
Optional: other implied assumptions of this model of measurement
These diagrams are a great way to also see the assumptions that are underpinning our theories.
There are two further implications that arise when we think of our measurements the way we drew in Figure 3.
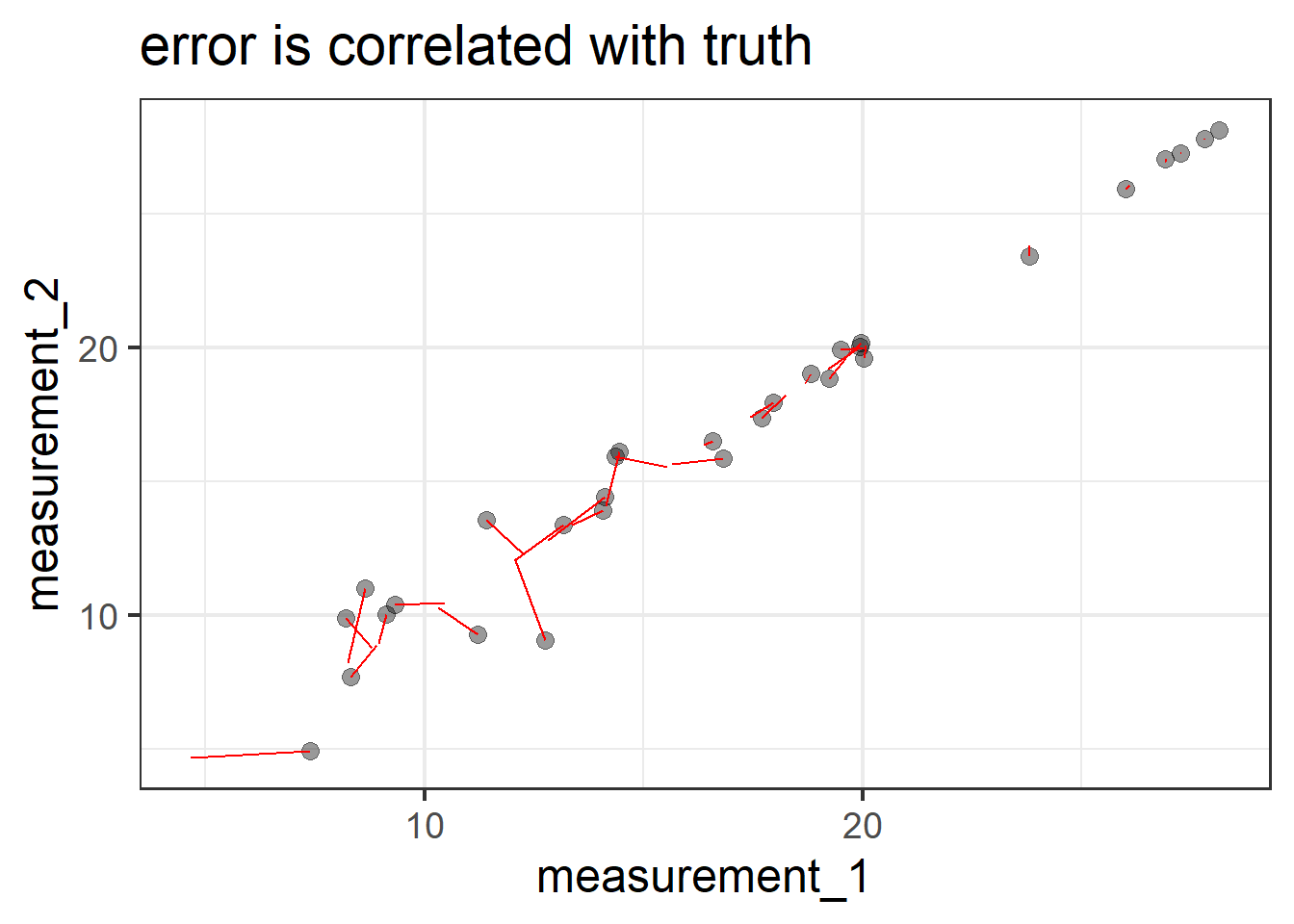
Errors are not correlated with the truth. In the diagram, this is represented by the fact that there is no arrow between the Truth and Error variables. What this means in an applied setting is that we assume that the amount of measurement error isn’t less/more for someone who has a low true value than it is for someone with a high one. Continuing with the act of weighing dogs, this is the assumption that if my scales are showing a value that is \(\pm1kg\), then it is \(\pm1kg\) for a dog that actually weighs 5kg and for one that actually weighs 50kg. You could imagine this not being the case if, e.g., the 50kg dog squashed the scales down so much that the scales always showed \(50 \pm 0.1kg\), and the scales didn’t work as well for the little 5kg dog where we see scores of \(5 \pm 3kg\). If we wanted to include this assumption in the model diagram, we would need to draw an arrow from the Truth variable to the Error variable.
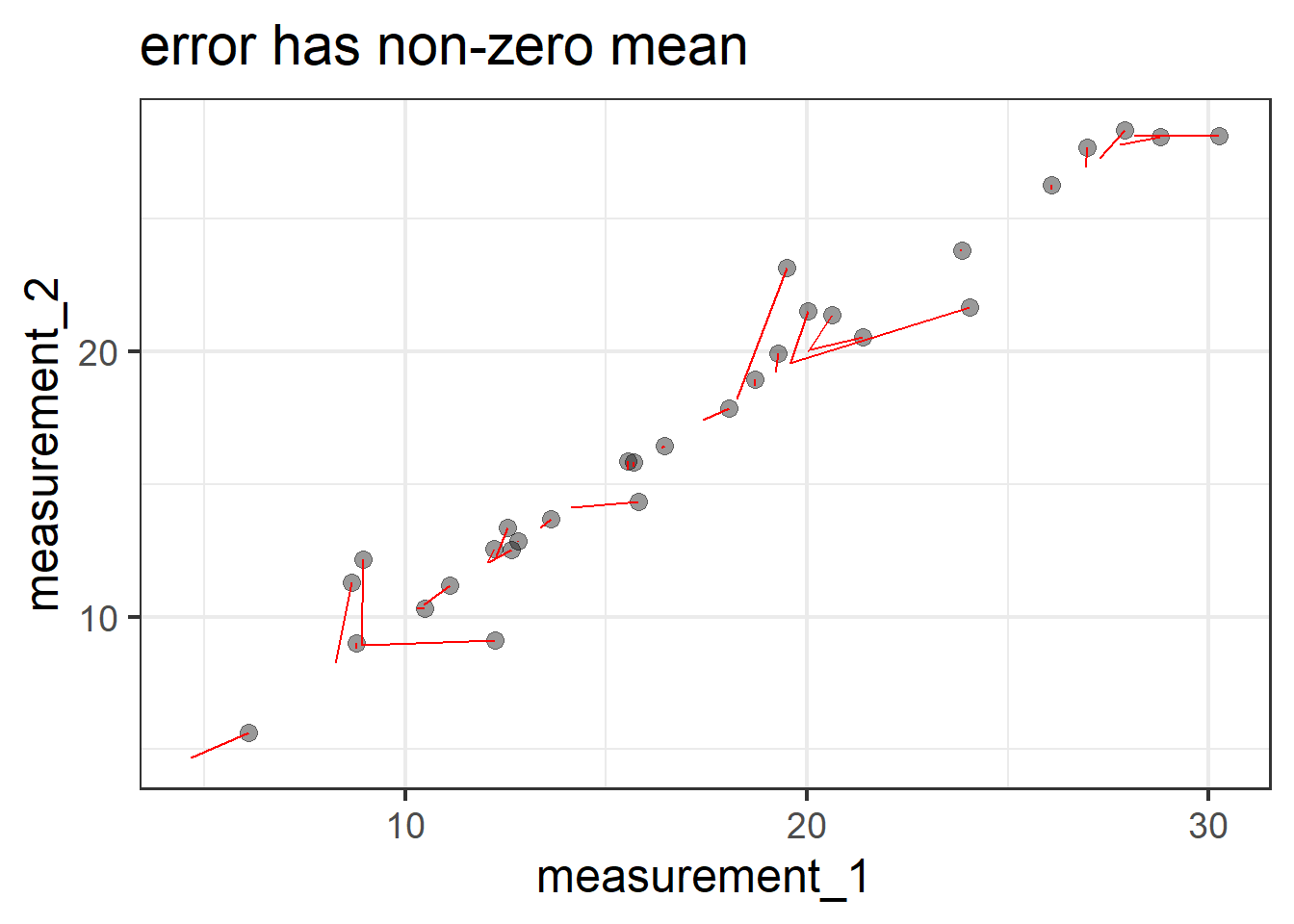
Error has mean zero. This is just like we often assume with errors - they are just random deviations, meaning they average out at zero. When it gets to diagrams and covariance-based models (like CFA etc), we don’t really talk much about the means anymore. But if we did want to represent them, then we could show them in these diagrams as a constant fixed number, in triangles (if squares are for observed variables, circles are unobserved/latent variables, then we need a new shape). So more explicitly our diagram would look like Figure 4. The triangle connected to “Truth” represents the average true value, \(\mu\). The triangle connected to “Error” contains zero, representing that the errors have a mean of zero. The lack of a triangle going into the observed score is telling us that there is no systematic bias (i.e., in our weighing scales example, if they always weight 5kg heavier, we would have a triangle in the 5 going into the score).
If the first implication doesn’t actually hold for our measurement tool, then we end up with the measurement tool having different levels of reliability for different levels of truth - e.g., a reliable means of weighing dogs between 15-30kg but not a reliable means of weighing dogs between 5-10kg. If the second implication doesn’t hold (that is, if the errors do not have mean zero), then this could be systematic bias, or could be due to something skewing our errors, meaning we might have some measurements being much further off than others (in the right hand plot below, if we took all the errors - the red lines - and plotted them, it would look very skewed, and have a mean of ~0.8).
If reliability is a proportion, this means it can range from 0 (all of the variance in scores is error) to 1 (none of it is). There is no defined cut-off for what is “reliable enough”, though in a lot of social science, people seem to want at reliability to be >0.7.
However, while this way of thinking about reliability might seem nice and intuitive, how on earth do we actually quantify it? With just a single score, we don’t have enough information… We are essentially saying “observed score = unobserved true values + unobserved errors”. This is a bit like being given a math problem of “23.5 = T + E, please solve” — it’s impossible! So while we might know that \(Var(\text{Observed Scores})\)=\(Var(\text{True Scores})\)+\(Var(\text{Errors})\), with just one score we can’t figure out how much of the observed variance is true variance vs error variance.
Things get a lot better when we have more than one score. This is because we have two scores, say, and two errors, but only one truth. Now it’s a bit like getting a math problem of “23.5 = T + E, and E is equal to 10”.
And we have a certain set of assumptions (some of which we can see in the diagram):
- the true value hasn’t changed between assessments (it’s the same thing “truth” that leads to both).
- the true value contributes the same to each assessment (the arrows from truth are both 1).
- there is the same amount of error at each assessment. i.e,. it’s not the case that the 2nd assessment involves much bigger or smaller errors than the first (this is indicated by both Error 1 and Error 2 having the same variance \(\sigma^2_{E}\)).
- the errors are uncorrelated - happening to have the score at assessment 1 be a little bit above your true value tells us nothing about how above/below our score will be at assessment 2. This is indicated by the lack of an arrow between Error 1 and Error 2.
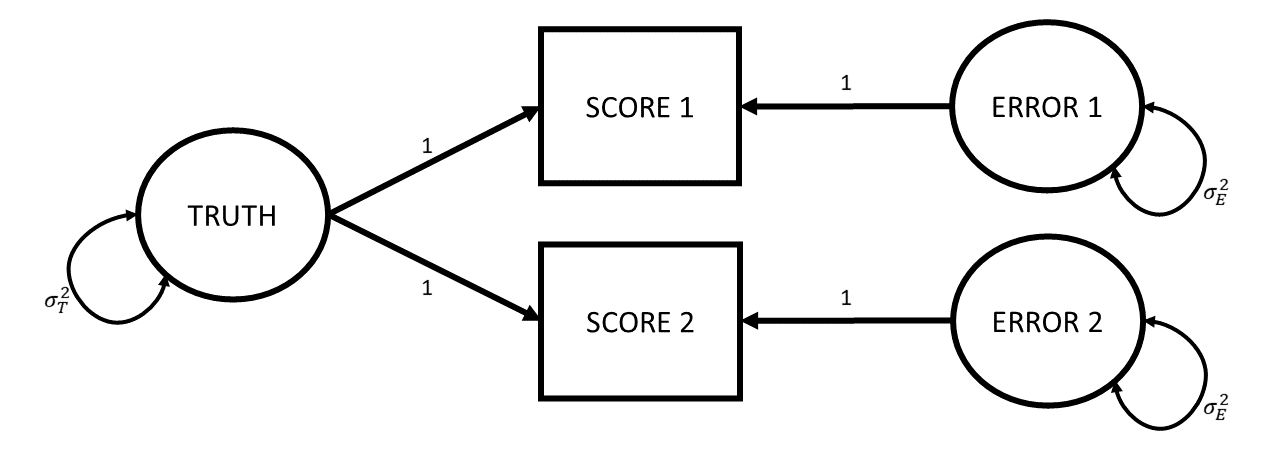
So where do these repeated assessments come from? How do we end up with multiple scores? There are lots of ways in which we can think of having these sort of “parallel tests” (having multiple instances of measurements of the same construct).
We could:
- take a measurement, wait a bit, and then take another measurement
- take a measurement with version-A of the measurement instrument and then take a measurement with version-B
- get two (or more) people to measure the same units
For each of these situations there are specific calculations that tend to get used to quantify the reliability. They tend to differ because of how they are partitioning variance into “true variance” and “error variance”.
Optional - where did the correlation between repeated measurements go?
We’ve just been talking about reliability as the ratio of true variance to observed score variance. But we started somewhere else: thinking about reliability as consistency across repeated assessment. This box shows that, mathematically, both ideas work out to the same thing!
To turn covariance into a correlation, we must divide it by the standard deviations of the two variables - \(cor_{xy} = \frac{cov_{xy}}{sd_x \cdot sd_y}\).
So let’s take the correlation between scores and express it as the covariance divided by the standard deviations. Remember that standard deviation \(\sigma\) is the square root of variance, which is \(\sigma^2\). So let’s write the standard deviations as \(\sqrt{\sigma^2}\) (the reason will become clear in a second).
\[ \begin{align} cor_{score_1,score_2} &= \frac{cov_{score1,score2}}{\sigma_{score1} \cdot \sigma_{score2}} \\ \, \qquad \\ &= \frac{cov_{score1,score2}}{\sqrt{\sigma^2_{score1}} \cdot \sqrt{\sigma^2_{score2}}} \\ \end{align} \]
As we saw in CFA, these diagrams imply covariances between observed variables. In this case, the observed variables are the two scores, and according to this diagram, the only way that Score 1 and Score 2 co-vary is via the true values. So \(cov_{score_1, score_2}\) is going to be \(\sigma^2_T\).4
And we have just talked about how the variance in observed scores is equal to the variance in the true values plus the variance in the errors, and so the variance of Score 1 is going to be \(\sigma^2_T + \sigma^2_{E1}\).
We can substitute all these in to the above, and we would get:
\[ \begin{align} &= \frac{\sigma^2_T}{\sqrt{(\sigma^2_T + \sigma^2_E)} \cdot \sqrt{(\sigma_T^2 + \sigma^2_E)}} \\ \end{align} \] The bottom part then simplifies to:
\[ \begin{align} & = \frac{\sigma^2_T}{\sigma^2_T + \sigma^2_E} \end{align} \]
And we’re right back at the “proportion of true variance out of total variance (true variance + error variance)”.
Different Administrations, Assessment-versions, and Judges/Raters
Three forms of reliability frequently arise when we have a measure being used several times (either at different times, or in different versions, or by different administrators of the test).
A little note - the word ‘test’ in this world tends to be used to refer to a ‘psychometric test’ - i.e, a thing that gives us a numeric score. Kind of like the term ‘measurement tool’ we have been using so far. This could be a single thing (like weighing a dog on a scale), or it could be a score across a set of items (like the multi-item measures we have been dealing with in PCA/EFA/CFA).
Test-retest reliability: Consistency of test scores when the same test is administered to the same group on two different occasions.
Alternate forms reliability: Consistency of scores between two equivalent versions of a test that measure the same construct.
Inter-rater reliability: Degree of agreement or consistency between two or more raters/observers scoring the same behaviour or responses.
Our first instinct might be to measure reliability using correlations between two sets of scores. But just because two things are linearly associated doesn’t mean the measurement is reliable. (Imagine if you used an electronic weighing scale to weigh twenty dogs. And imagine that every time you turned this scale on, it would randomly multiply the values it measures by 3, or 2, or –4. The next time you turn the scale on and weigh the twenty dogs again, you’ll get a very different set of twenty scores. Those scores will be linearly associated with the first set, so the correlation will be high, but the measurement tool—the scale—is not reliable at all.)
To measure reliability in psychometrics, we commonly use the Intraclass Correlation Coefficient (ICC). Because this works on partitioning up variance between and within the observed units, this is more like assessing agreement between tests. Variance in average scores between the units in our sample can be taken as an estimate of “how much units truly vary”, and the variance in scores within the units can be seen as the error variance.
So in our example where we got 30 dogs and weighed them, and then weighed them again, we might have data like the below. We are wanting to separate out the variance within each dog’s observed weights and attribute it to measurement error. The variance between dogs is taken as the true variance. So Dougal first got 20.6, and then 25.9, so if we take his average of 23.25 we can think of ‘within-dougal-variance’ as how his measurements vary around his average (due to measurement error). And Dougal’s average 23.25 differs from Rufus’s average of 29.7, and so on - these values have a variance which we take to reflect Dougal truly varying from Rufus and Daisy etc.
dogdata dog measurement_1 measurement_2
<chr> <dbl> <dbl>
1 dougal 20.6 25.9
2 rufus 28.1 31.3
3 daisy 10.7 9.79
4 bella 19.8 17.2
5 shell 13.4 8.88
6 coco 20.8 19.6
. ... ... ...
. ... ... ...The ICC() function from the psych package will calculate the ICC for us.
library(psych)
ICC(dogdata[,2:3])Call: ICC(x = dogdata[, 2:3])
Intraclass correlation coefficients
type ICC F df1 df2 p lower bound upper bound
Single_raters_absolute ICC1 0.90 19 29 30 1.0e-12 0.81 0.95
Single_random_raters ICC2 0.90 19 29 29 2.1e-12 0.81 0.95
Single_fixed_raters ICC3 0.90 19 29 29 2.1e-12 0.80 0.95
Average_raters_absolute ICC1k 0.95 19 29 30 1.0e-12 0.89 0.98
Average_random_raters ICC2k 0.95 19 29 29 2.1e-12 0.89 0.98
Average_fixed_raters ICC3k 0.95 19 29 29 2.1e-12 0.89 0.98
Number of subjects = 30 Number of Judges = 2
See the help file for a discussion of the other 4 McGraw and Wong estimates,The ICC function doesn’t know what kind of reliability we want to measure, because it doesn’t know how exactly we got our measurement multiple times. So to cover all its bases, the ICC function spits out a whole bunch of different types of ICC. Here’s what each type of ICC means:
- ICC1: Each dog is measured at a different time point and the time points are selected at random.
- ICC2: Dogs are all measured at a random sample of k time points.
- ICC3: Dogs are all measured at a specific fixed set of k time points.
Then for each of these, we also get the equivalent for if there’s more than one rating for each dog at each time point.
In the official terminology that you’ll see on the help pages of the ICC function, the same ideas will be phrased more generally as:
- ICC1: Each target is rated by a different judge and the judges are selected at random.
- ICC2: A random sample of k judges rate each target. The measure is one of absolute agreement in the ratings.
- ICC3: A fixed set of k judges rate each target. There is no generalization to a larger population of judges.
This all uses the language of “judges” and “targets”, which in our case corresponds to “timepoints” and “dogs”. There’s a nice paper (Koo & Li 2016) here explaining this in more depth and with some flowcharts to help us think about which one we want. In our case, we have a random sample of timepoints (it’s not like we measured all dogs before and after some event - we don’t expect any systematic differences between timepoints), so ICC2 is probably what we want.
Optional - Didn’t ICC come up in mixed models!?
It did! We already saw ICC! and as it happens, it’s the same thing.
This box shows how we can use the multilevel model machinery to reconstruct the same ICC value computed above.
If we pivot our data to be long:
doglong <- dogdata |>
pivot_longer(measurement_1:measurement_2,
names_to = "time", values_to = "score")
doglong dog time score
<chr> <chr> <dbl>
1 dougal measurement_1 20.6
2 dougal measurement_2 25.9
3 rufus measurement_1 28.1
4 rufus measurement_2 31.3
5 daisy measurement_1 10.7
. ... ... ...
. ... ... ...We can then use a multilevel/mixed effects model to regress the ratings on to a model with just an intercept and by-dog and by-timepoint random intercepts:
doglong$score=ifelse(doglong$time=="measurement_2",doglong$score+4,doglong$score)
mod <- lmer(score ~ 1 + (1 | dog) + (1 | time),
data = doglong)
summary(mod)...
Random effects:
Groups Name Variance Std.Dev.
dog (Intercept) 48.78 6.985
time (Intercept) 2.413e-09 4.912e-5
Residual 5.292 2.300
Number of obs: 60, groups: dog, 30; time, 2
...From the random effect variances, we can work out the ICC! This is because the estimated dog-level variability in intercepts can be taken as an estimate of “true variance”!
48.78 / (48.78 + 2.413e-09 + 5.292)[1] 0.9021305This is the same number that we got for the ICC2 from ICC() above.
Internal Consistency of Multi-Item Measures
The above forms of reliability are concerned with each test administration providing a single numeric score, which is then assessed over different times/versions/raters. But very often we are faced with a single administration of a psychometric test providing multiple numeric scores, such as when we ask a bunch of questions.
In practice, this happens all the time in psychology, and we want to quantify reliability here too. This situation is different because now we’re looking at reliability within a single administration of our measurement tool. For some reason, this kind of reliability doesn’t have “reliability” in the name after all: it’s typically termed “internal consistency”.
Internal consistency: Consistency of one person’s responses across items within the same test
For example, imagine we have administered a ten-item measure of Perceived Stress to a sample of people. We are specifically interested in forming some sort of score on the construct of Perceived Stress for each person. To do this, we’ll quantify their internal consistency.
The idea is similar to before: we want to know what part of a person’s variance in response is due to “true” variance in an underlying construct, vs. what might just be error. Far and away the most famous measure of internal consistency is “coefficient alpha (\(\alpha\))” (often called “Cronbach’s alpha”5), which has a pretty unsightly formula, but conceptually uses covariance between items as a measure of “true variance”, and takes this as a proportion of the variance in total scores across the items.
By using the average covariance to capture “true variance”, what we are implicitly assuming is that each of those covariances are equally important—in other words, that every item contributes equally to the score. Sounds kind of familiar? It’s just the same assumption we had when we calculated a sum score, or a mean score - hence why our denominator is the sum of all the variance!
\[ \begin{align} \alpha&= \frac{\text{average covariance between items}}{\text{total score variance}}\\ \quad \\ &= \frac{\text{true variance}}{\text{total score variance}} \\ \end{align} \]
coefficient alpha - the full formula
\[ \begin{align*} \alpha=\frac{k}{k-1}\left( \frac{\sum\limits_{i\neq}\sum\limits_j\sigma_{ij}}{\sigma^2_X} \right) = \frac{k^2 \,\,\,\overline{\sigma_{ij}}}{\sigma^2_X} \\ k \text{ is the number of items in scale X} \\ \sigma^2_X \text{ is the variance of all items in scale X} \\ \sigma_{ij} \text{ is the covariance between items }i\text{ and }j \\ \end{align*} \]
In R, we can calculate coefficient alpha with the alpha() function from the psych package.
If some of our items are negatively worded, we’ll need to use check.keys=TRUE to ensure that they get reversed by the function.
# load some data from a measure of stress
# stressdata is the dataset of responses
# stress_items shows the wordings of the questions
load(url("https://uoepsy.github.io/data/reliablystressed.rdata"))
library(psych)
alpha(stressdata, check.keys = TRUE)$total raw_alpha std.alpha G6(smc) average_r S/N ase mean sd
0.7495781 0.7527712 0.7661157 0.2334131 3.044836 0.04058069 2.879518 0.5641222
median_r
0.2569744!Important! - if you have multiple dimensions to your measurement, you need to calculate alpha on the set of items for each one separately!
An alternative method to calculate reliability, without having to assume equal weighting of items within a test, is borne out of factor analysis. McDonald’s Omega (\(\omega\)) uses factor loadings and uniqueness estimates to calculate reliability. This (hopefully) makes a bit of sense if we remember from EFA and CFA that standardised factor loadings, when squared, provide “variance in an item explained by a factor”.
\[ \small \begin{align} \omega_{total}&= \frac{\text{factor loadings}^2}{\text{factor loadings}^2 + \text{error}}\\ \quad \\ &= \frac{\text{variance explained by factors}}{\text{variance explained by factors} + \text{error variance}}\\ \quad \\ &= \frac{\text{true variance}}{\text{true variance} + \text{error variance}} \\ \end{align} \]
McDonald’s Omega - the full formula
\[ \begin{align*} \omega_{total} = \frac{ \left( \sum\limits_{i=1}^{k}\lambda_i\right)^2 }{ \left(\sum\limits_{i=1}^{k}\lambda_i \right)^2 + \sum\limits_{i=1}^{k}\theta_{ii} } \\ k \text{ is the number of items in scale X}\\ \lambda_i \text{ is the factor loading for item }i\\ \theta_{ii}\text{ is the error variance for item }i\\ \end{align*} \]
In R, we can calculate McDonald’s Omega with the omega() function or the omegaFromSem() function, both from the psych package.
The omegaFromSem() function requires us to fit the model with cfa() first, so it’s useful if you want to apply it to a CFA model after the fact. But if we just want to compute McDonald’s Omega without fitting a CFA model first, we can use omega(), which only requires us to specify how many factors there are.
# load some data from a measure of stress
# stressdata is the dataset of responses
# stress_items shows the wordings of the questions
load(url("https://uoepsy.github.io/data/reliablystressed.rdata"))
library(psych)
omega(stressdata, nfactors = 1)$omega.tot[1] 0.7626487When we have more factors, omega gets more complicated, and will return us both \(\omega_{total}\), which is the proportion of the variance attributable to all factors, and \(\omega_{hierarchical}\) which posits a “higher order” or “general” factor \(g\) above all the factors in the model, and gives us the variance attributable to \(g\). In any cases where you are using \(\omega\), just think carefully about if you believe what you have to be measure of some single, overarching construct.
All these different ways to estimate the reliability of measures, and for what purpose? At the very fundamental level, it means that whenever we go out into the world and use our measurement tool, we have an idea of “how far off” the observed score is likely to be. It tells us how much faith we should have in our measurements! Once we’ve got a reliability coefficient from one of the measures above, we can figure out the “standard error of measurement”.
standard error of measurement: An estimate of how much an observed score is likely to vary from the “true” value if the test were administered repeatedly under the same conditions.
\[\text{SE}_m = s_x \sqrt{1 - r_{xx}}\]
- \(s_x\) = standard deviation of the observed scores
- \(r_{xx}\) is the reliability coefficient of the test
For example, if we had measured the internal consistency of our dog-weighing tool using coefficient alpha, and if we had the standard deviation of dog weights, then we could use the formula above to estimate the precision of our dog-weighing tool.
Why is this useful? Well, sometimes we’d like to know how precise a measurement tool is likely to be. Think of those “at home saliva tests for hormones”. Different brands vary wildly in their reliability, and generally the tests are not all that reliable. But rather than couching their results in this kind of uncertainty, the tests just give you a single point value, with no indication of how precise that estimate may be.
Attenuation Due to Unreliability
One of the biggest impacts of reliability, however, is that it has knock on effects for all of our research. Not surprisingly, the more unreliable a measure is, the harder it is to see if it correlates with some other measure.
For instance, suppose we are trying to estimate the correlation between two things, like “stress” and “anxiety”, and if we could measure them absolutely perfectly, we would see they are correlated 0.5 (Figure 6 Top-Left). We can never actually do this because measurements are never perfect. Depending on how bad our measures are (of either thing), then the random error introduced into our scatterplot results in a weaker correlation.
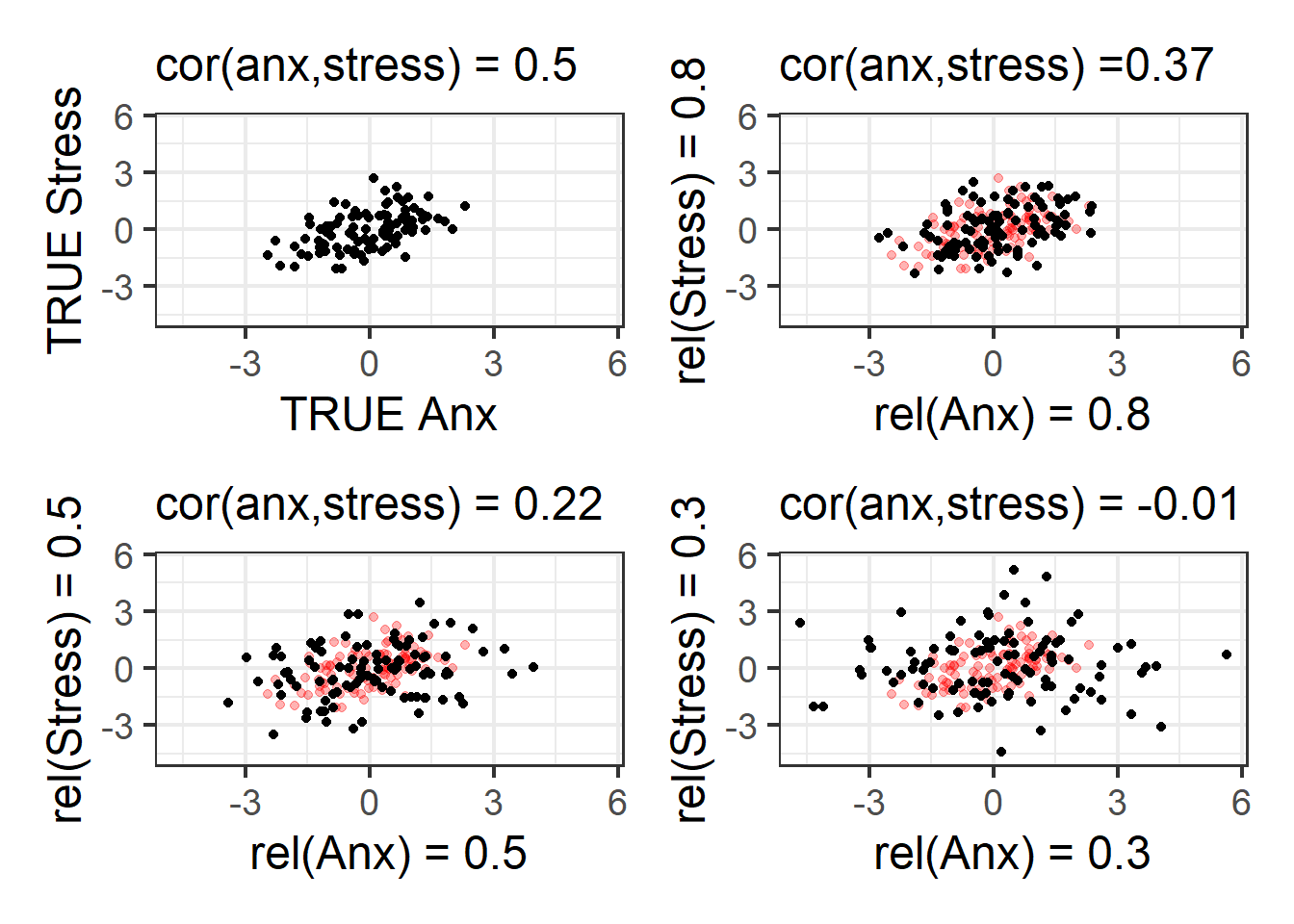
Summary graphic and closing remarks..
For those of you who are less interested in measurement itself and are more focused on it as a means to an end — i.e., to allow you to study things you’re actually interested in — then all of this can feel like a bit of a quagmire to muddle through before you actually get to the stuff that is relevant to your research question. That doesn’t mean that it is not important. It is incredibly important, and too often overlooked.
Here’s a graphical representation of the key ideas covered in this chapter:
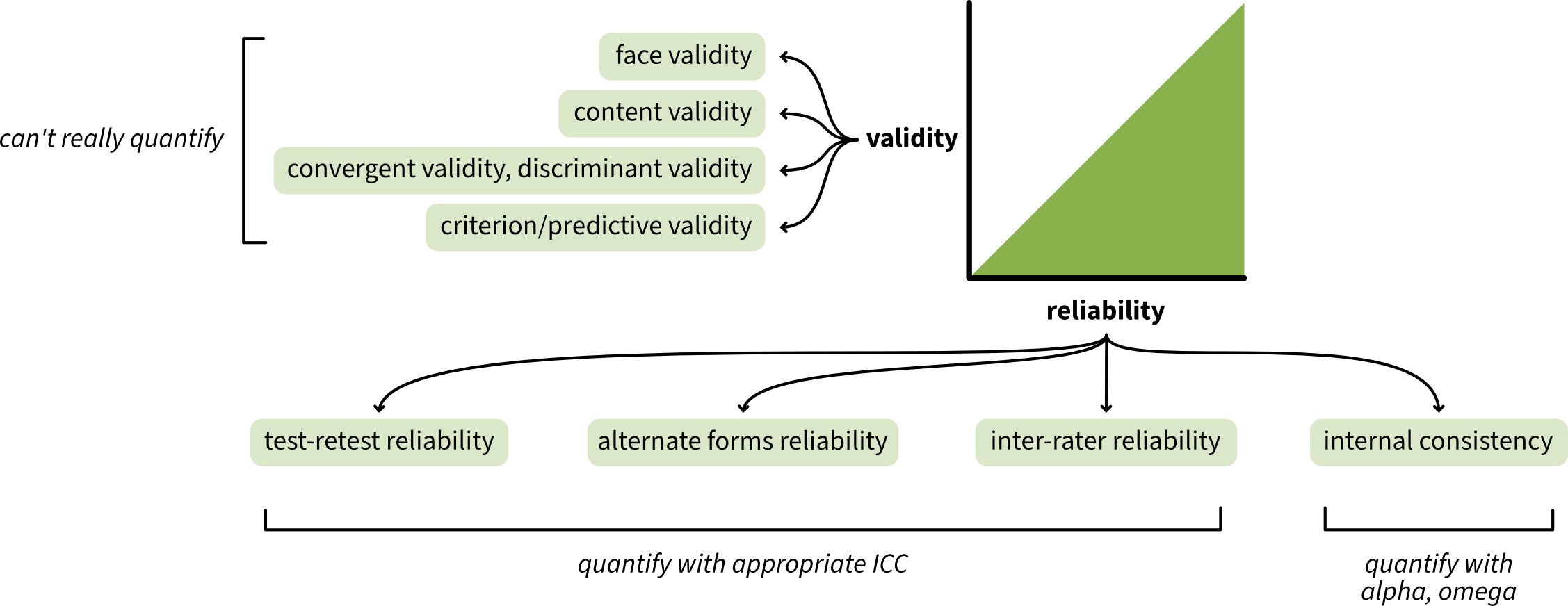
If nothing else, you should take away just these points:
- Measurement is never perfect
- “Reliability” and “Validity” are properties of a sample, not of a measure - everything we do is specific to persons, place and time.
- The pursuit of reliability and validity in measurement is not a destination, but an ongoing, cyclical journey of constant refinement and development.
Footnotes
Amusingly (at least to me), the word “duck” is apparently not a meaningful part of ornithological taxonomy. There are some things that we call “geese” that are more closely related to some things that we call “ducks” than other things that we call “ducks”. And don’t get started on “goosanders”!↩︎
Couldn’t bring myself to call it “the Josiah King Anxiety Scale”! :D↩︎
(hooray, I love numbers almost as much as I love diagrams!↩︎
We can do this by tracing between Score 1 and 2 on the diagram - we go down a path of 1, we pick up the true variance \(\sigma^2_T\), and then we go up a path of 1 - so \(1 \times \sigma^2_T \times 1\)↩︎
Lee Cronbach has said we shouldn’t it call ‘Cronbach’s Alpha’ because he didn’t come up with the idea↩︎