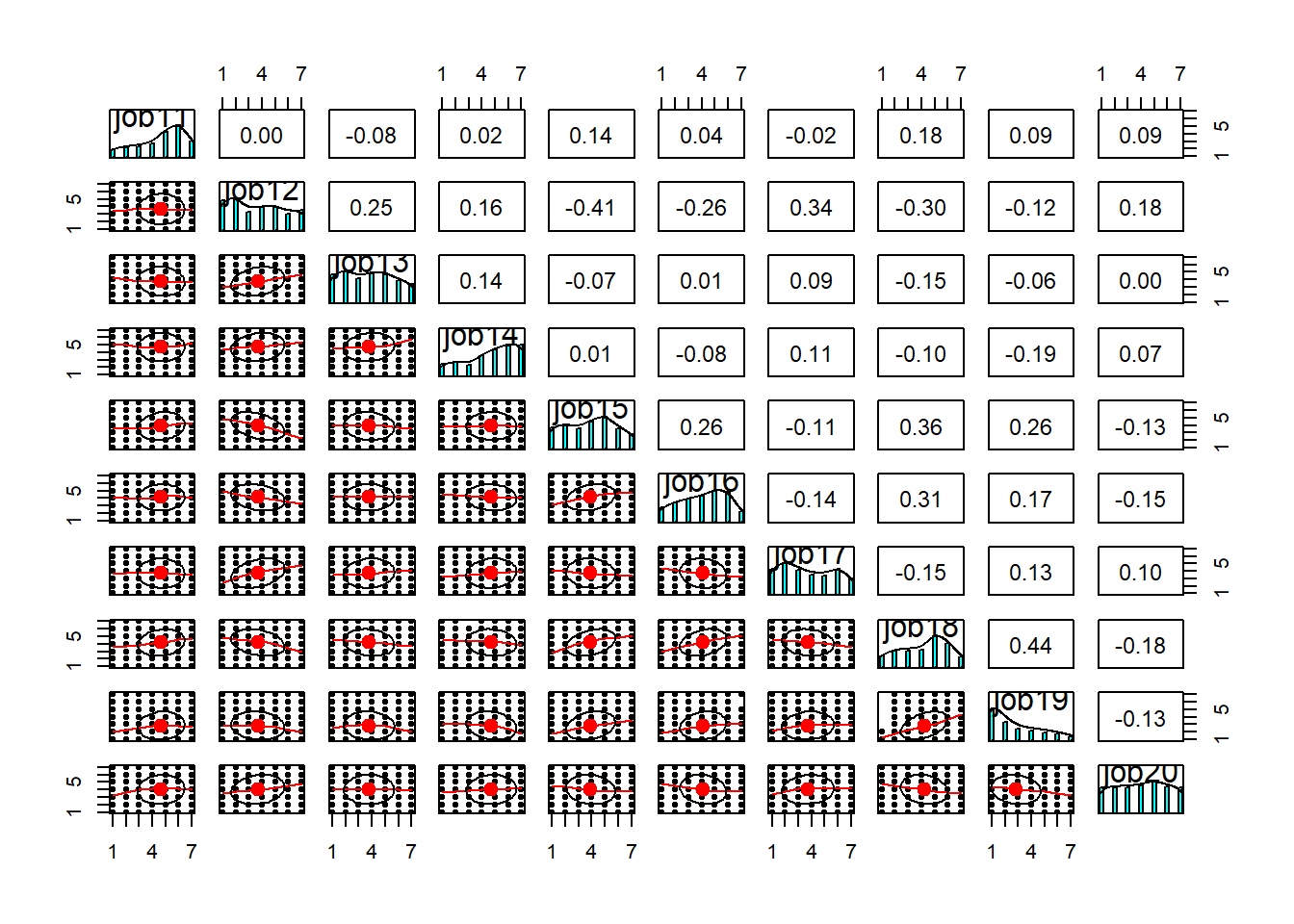
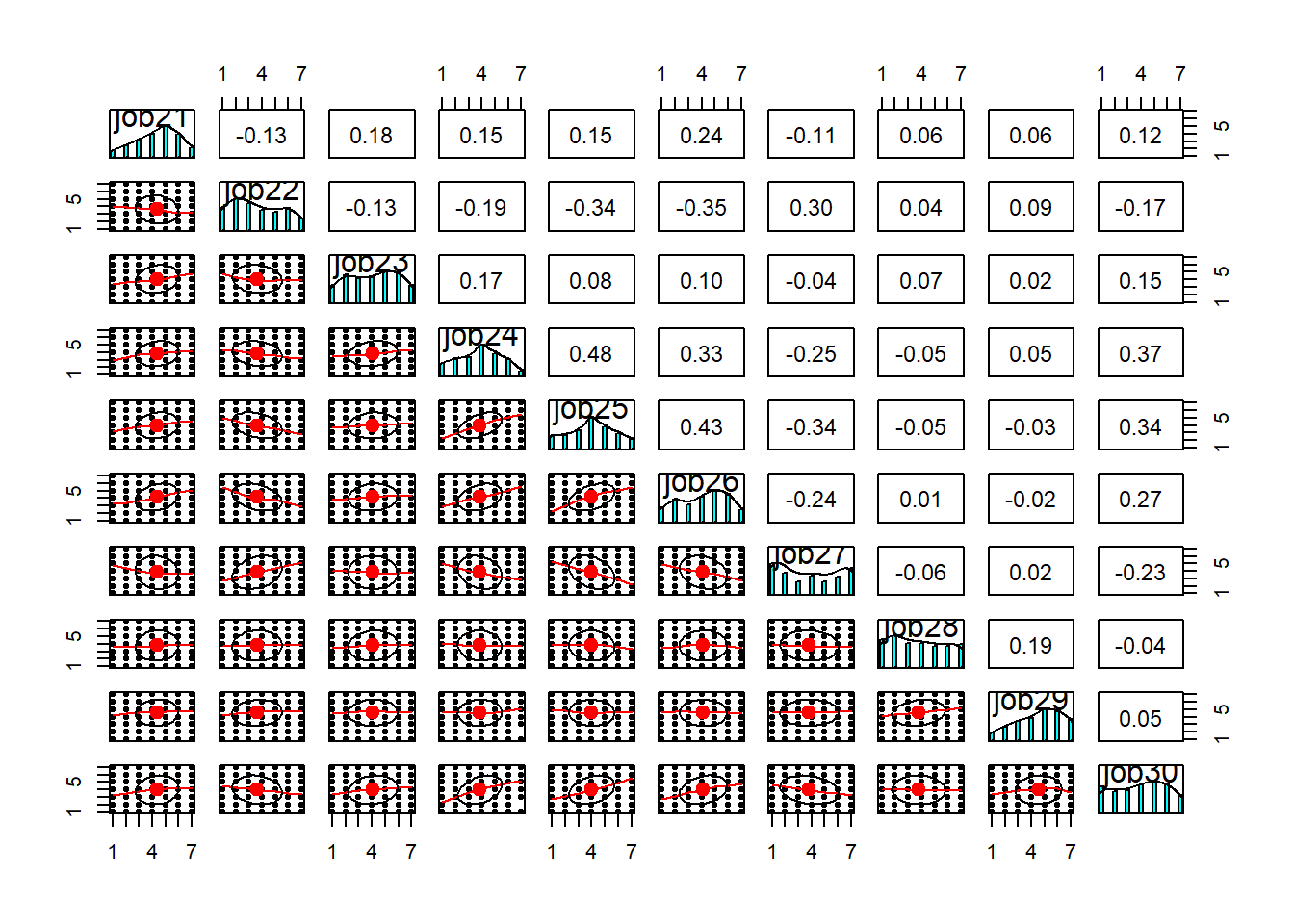
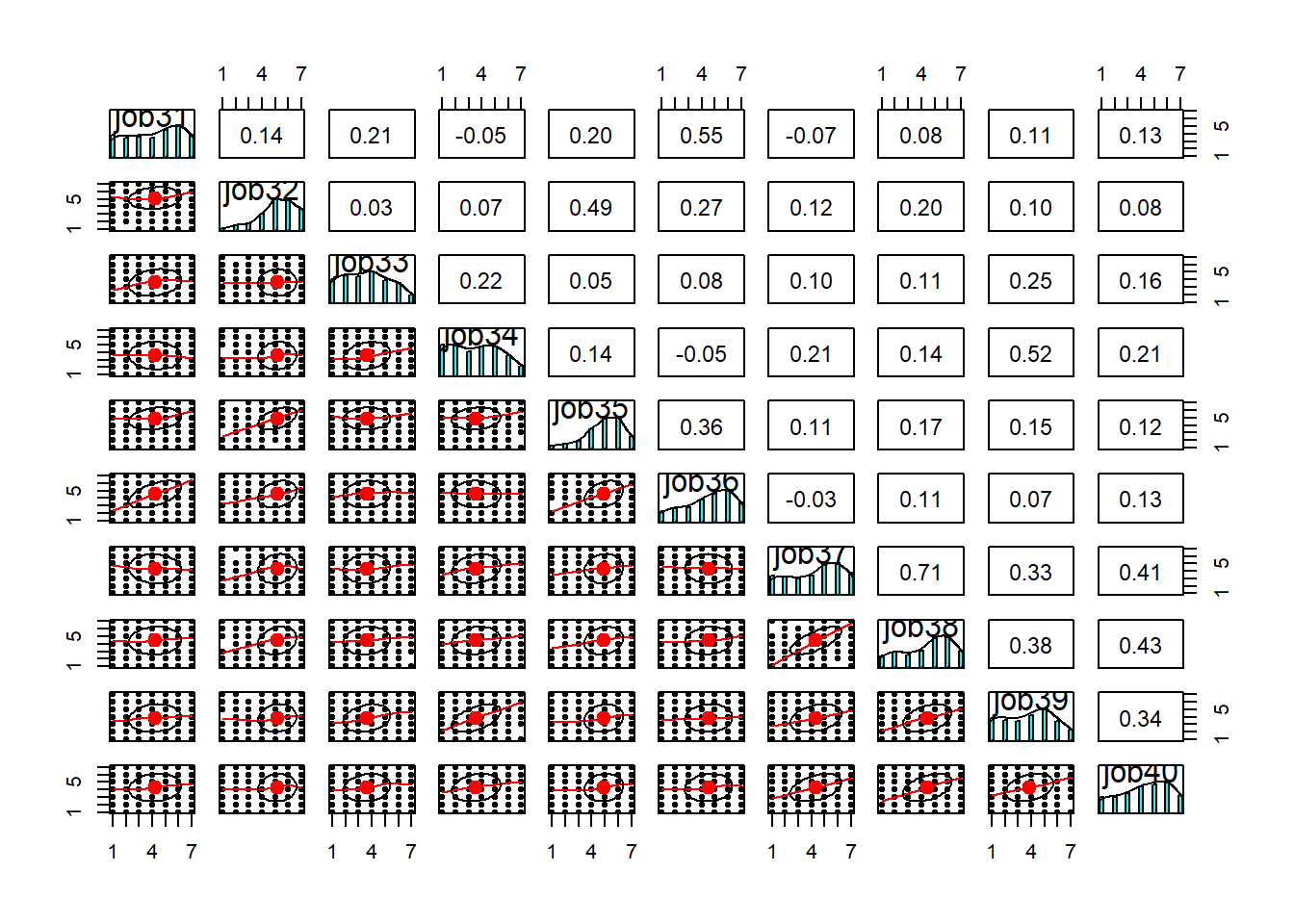
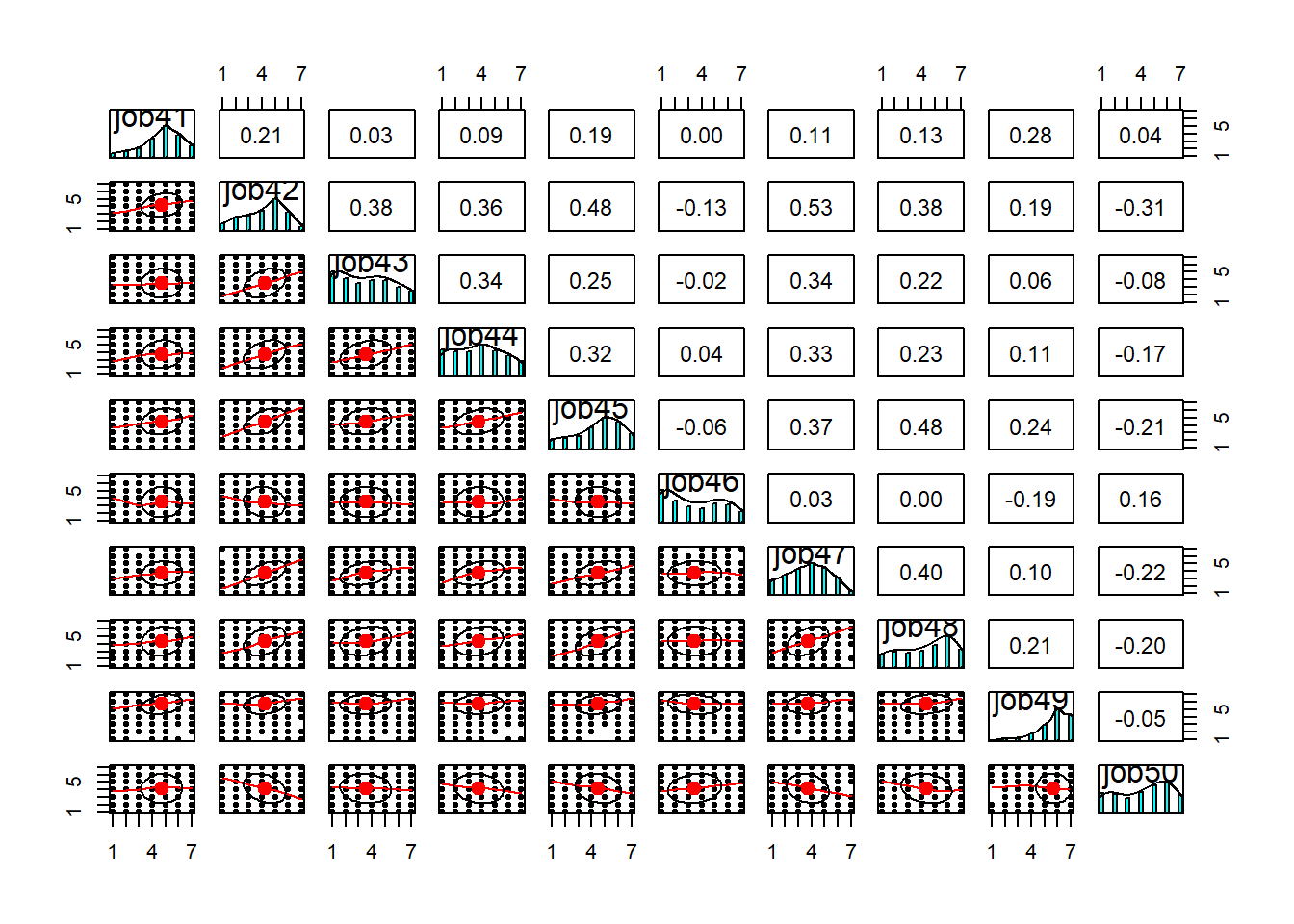
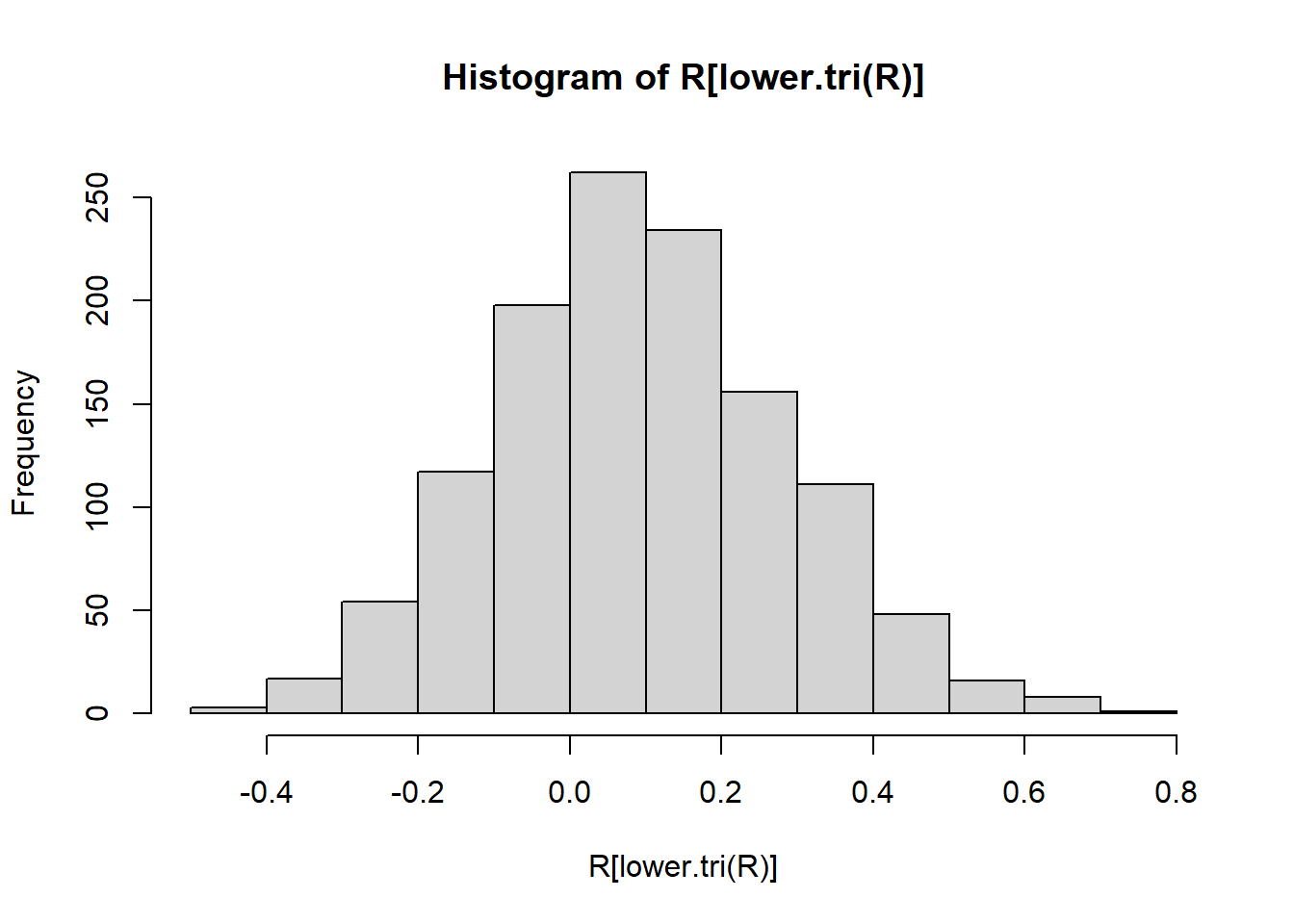
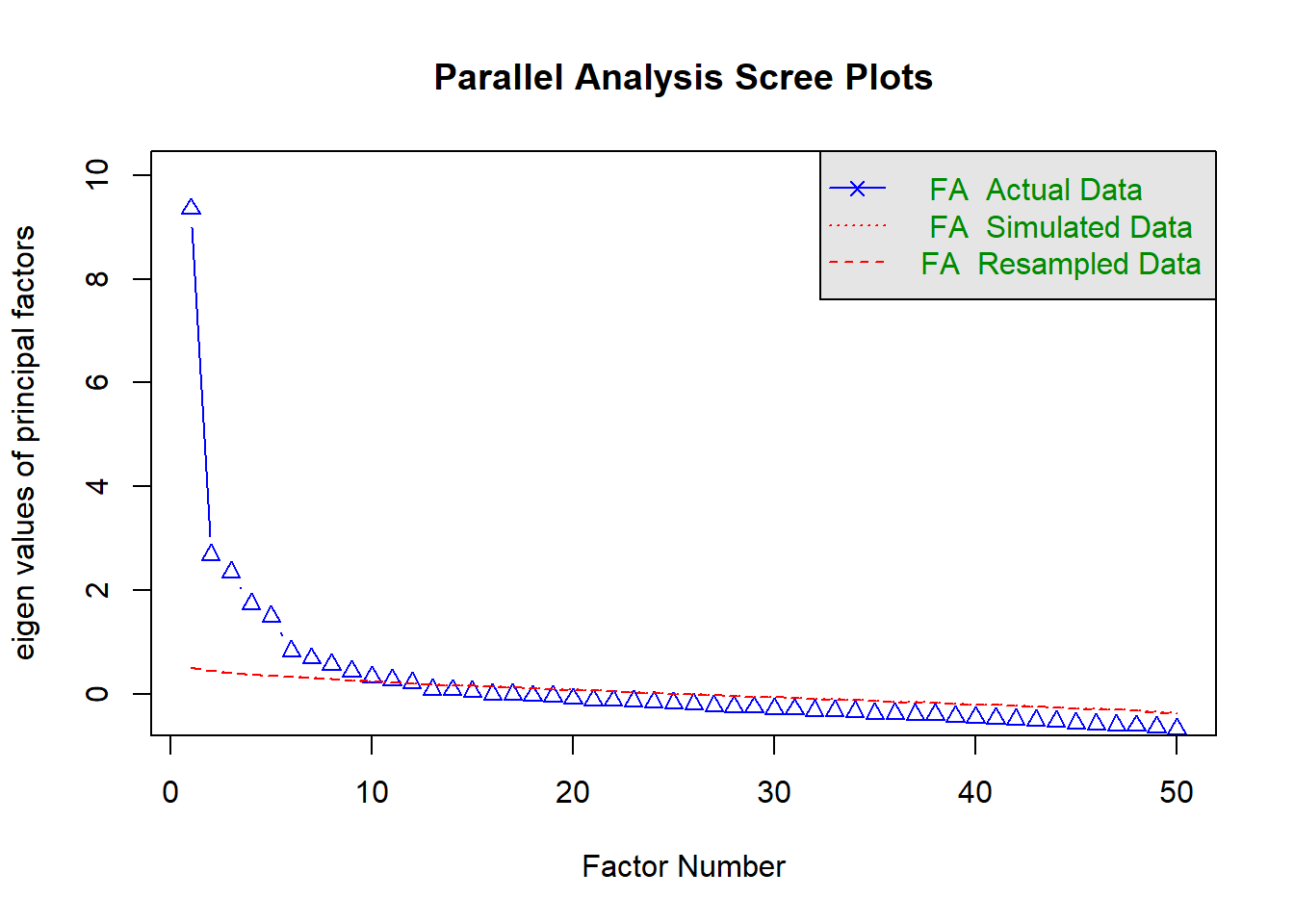
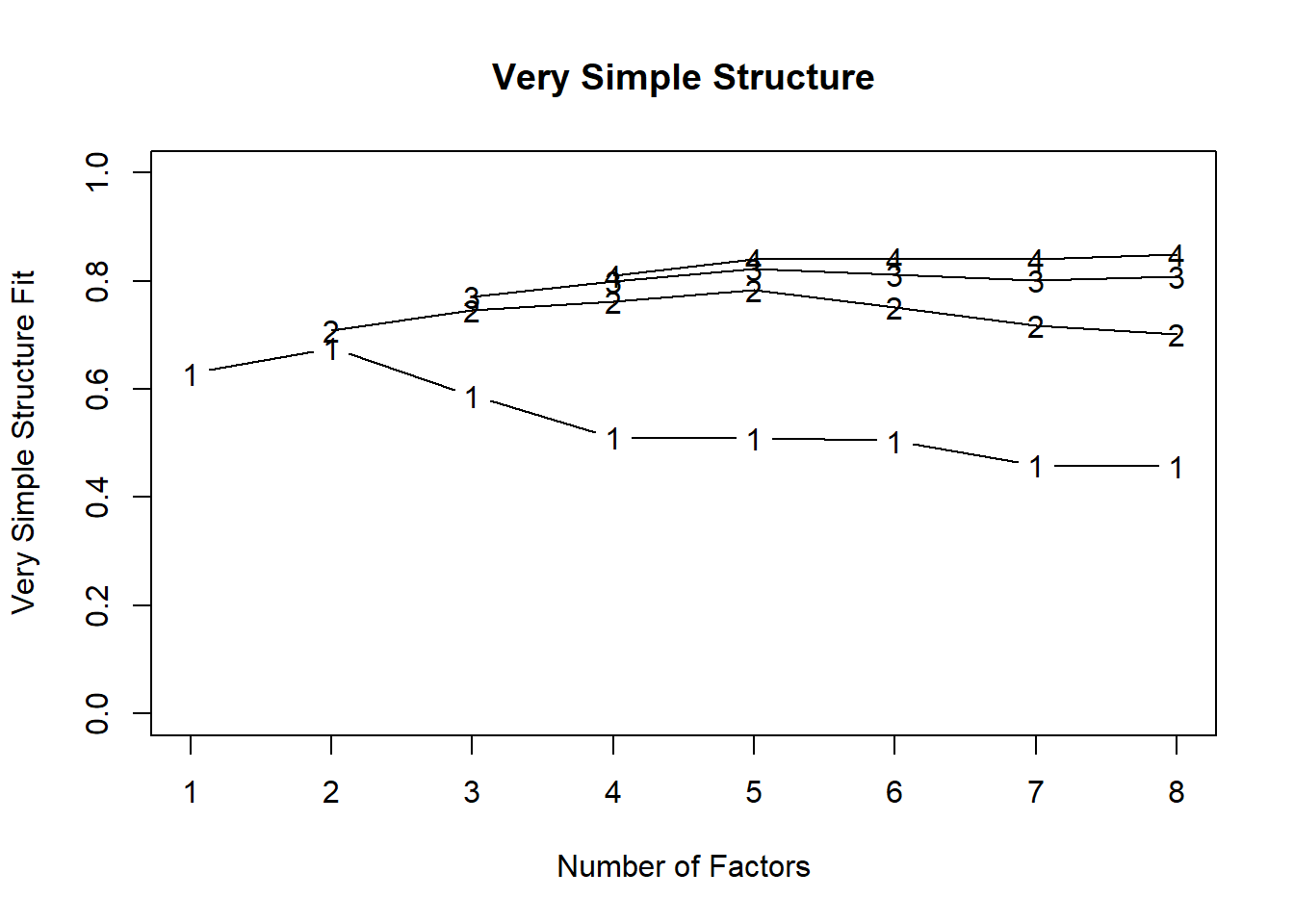
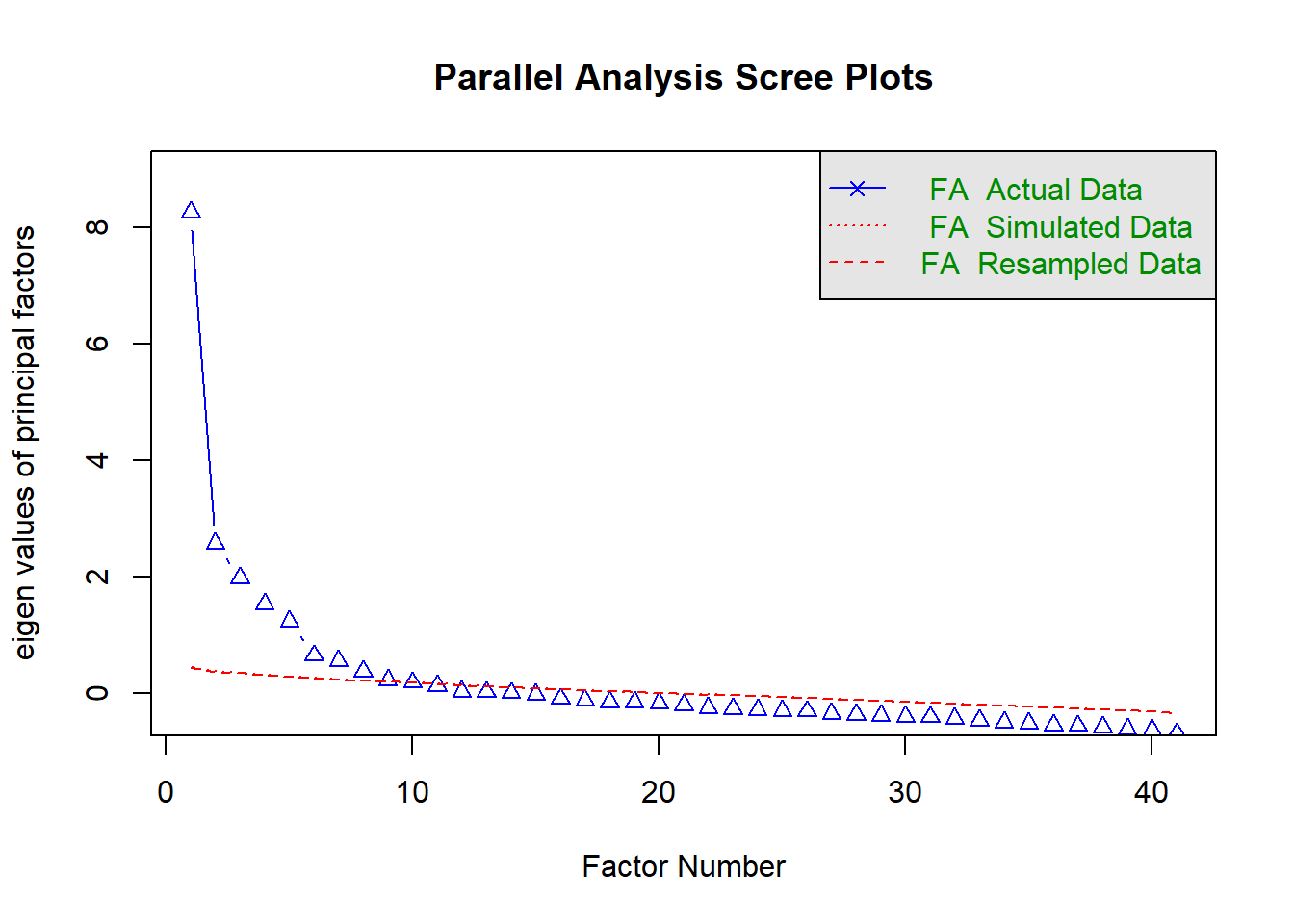
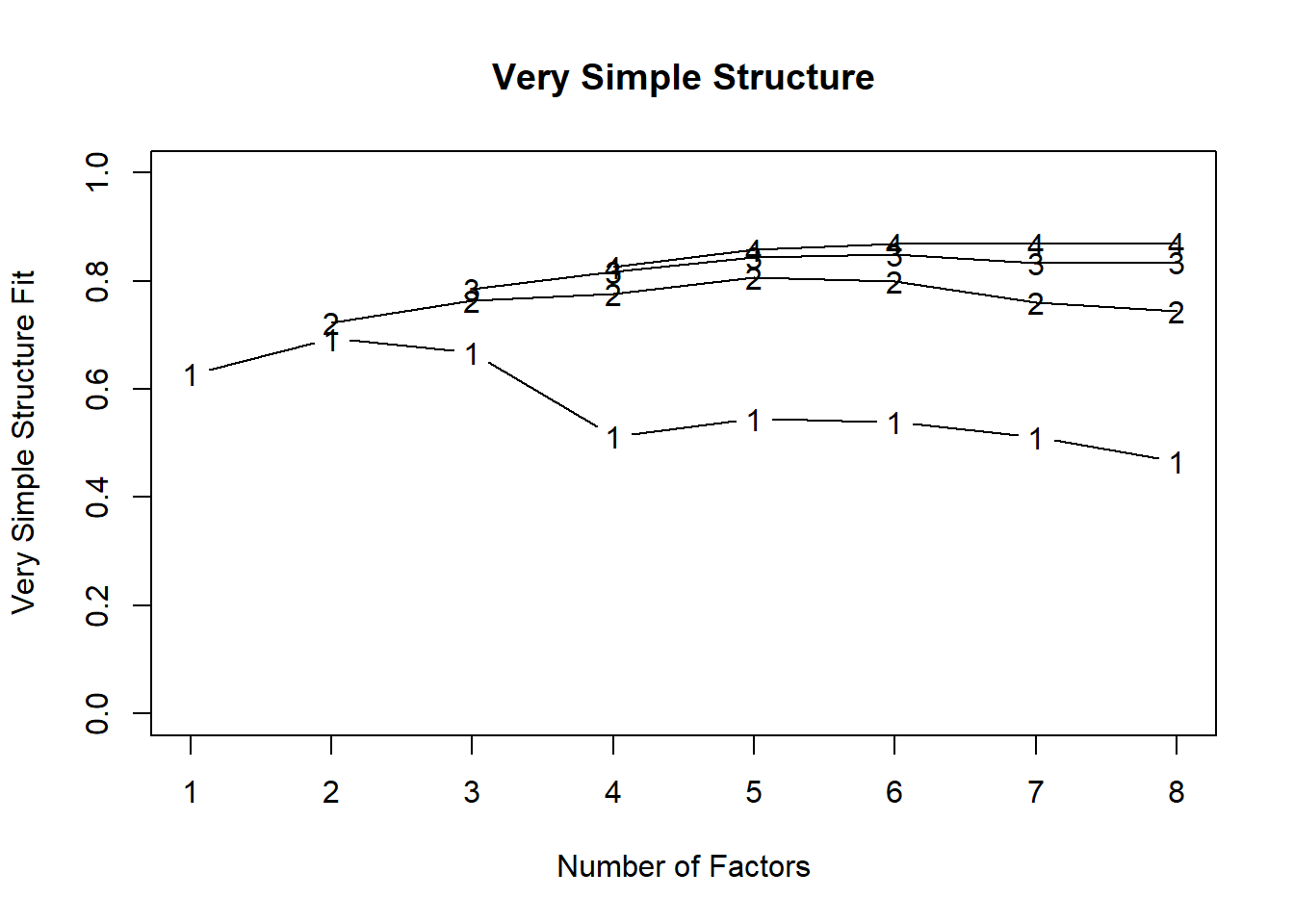
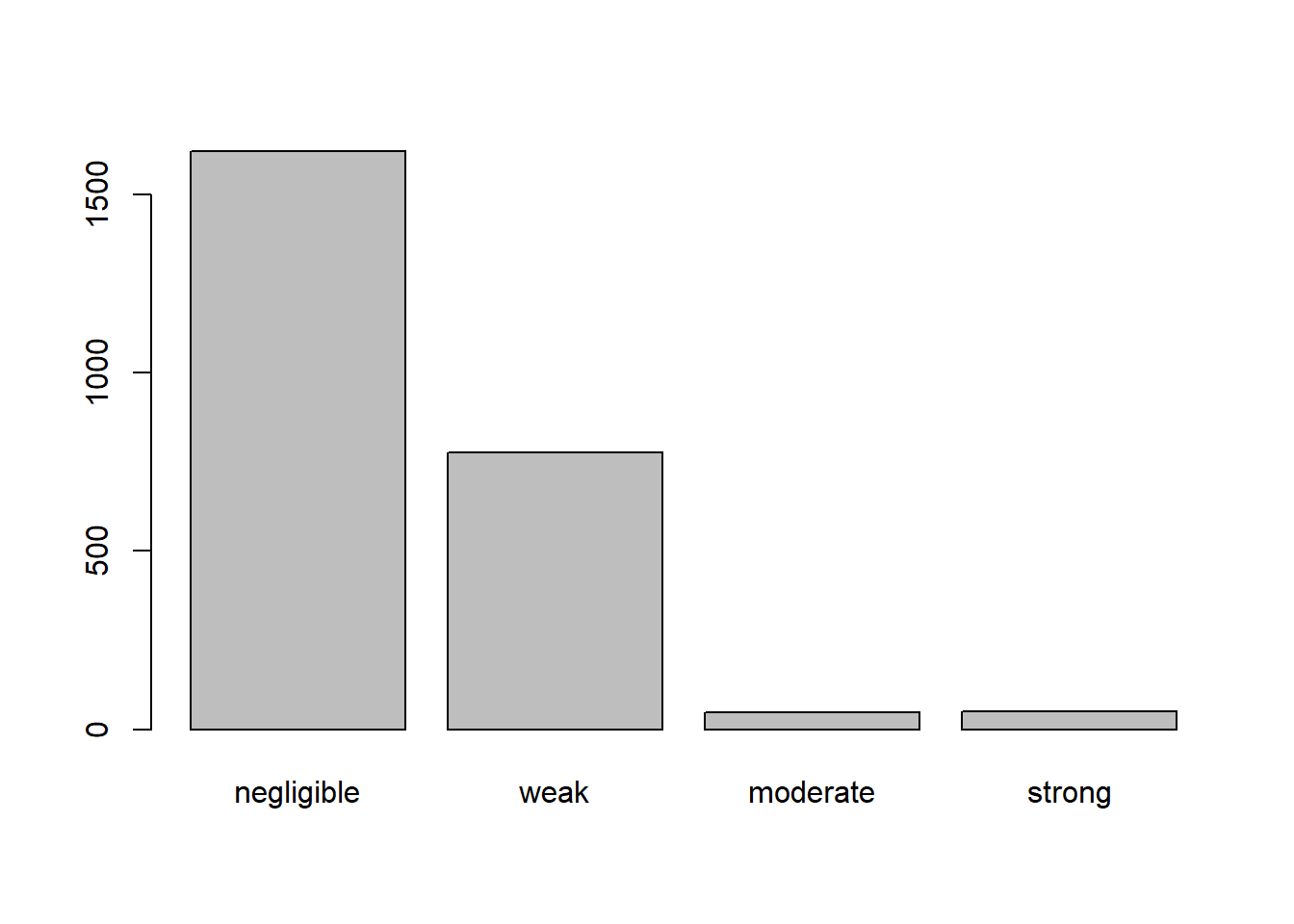Rows: 946
Columns: 67
$ job_yrs <int> 1, 5, 2, 4, 7, 3, 4, 4, 1, 0, 2, 2, 11, 4, 1, 2, 1, 0, 1, 0, …
$ job_mths <dbl> 6, 8, 8, 3, 1, 11, 2, 0, 1, 11, 0, 5, 1, 2, 10, 10, 4, 3, 0, …
$ worktype <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1…
$ cont_hrs <dbl> 45.0, 36.0, 40.0, 35.0, 40.0, 32.0, 30.0, 54.0, 37.0, 37.0, 3…
$ act_hrs <dbl> 45.0, 36.0, 40.0, 35.0, 41.0, 32.0, 30.0, 54.0, 37.0, 37.0, 3…
$ gender <int> 1, 2, 2, 1, 1, 1, 2, 1, 2, 2, 2, 1, 1, 1, 2, 1, 2, 2, 2, 2, 1…
$ dobm <int> 7, 1, 2, 4, 2, 8, 3, 5, 12, 11, 1, 12, 11, 3, 6, 6, 3, 5, 3, …
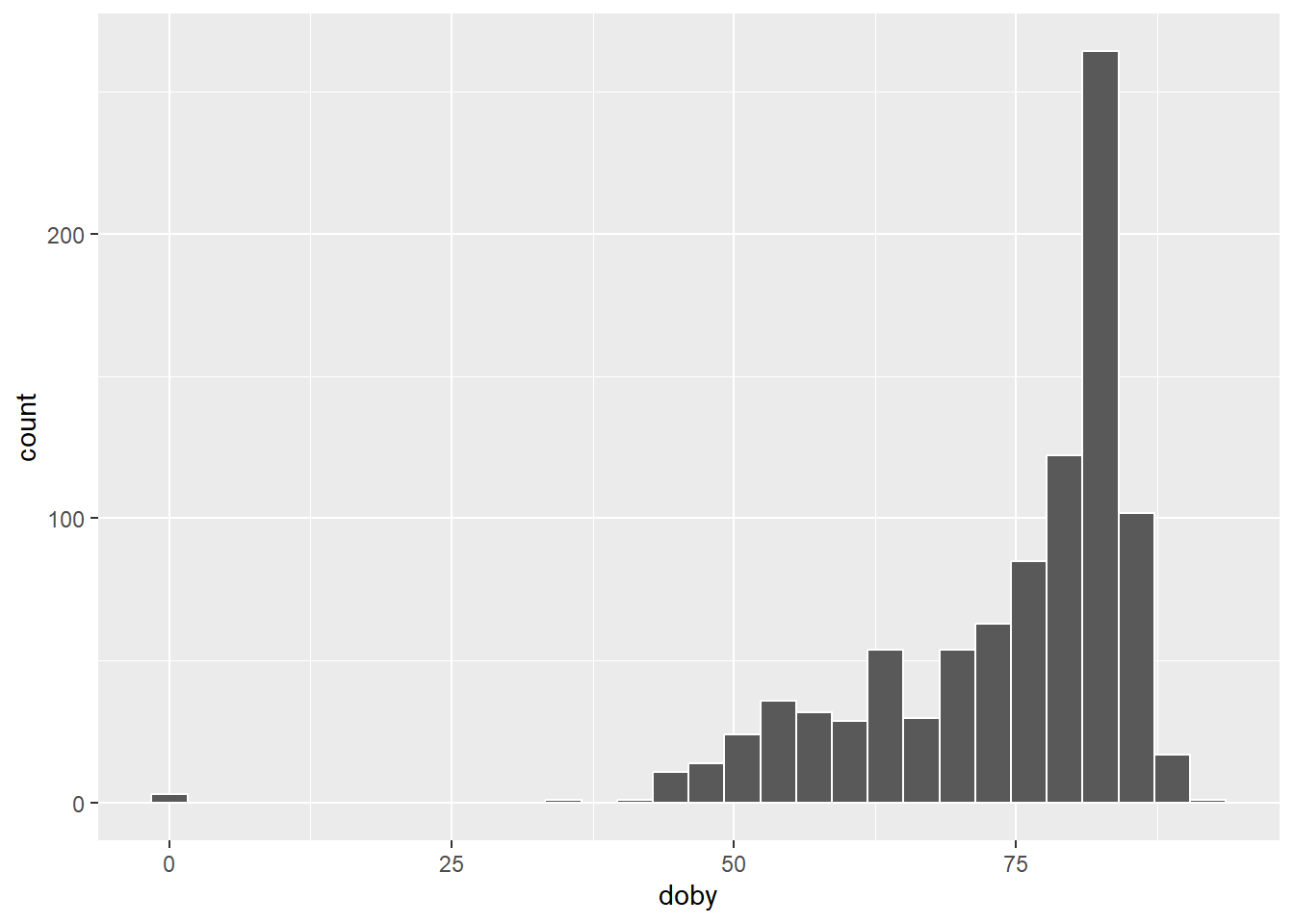
$ doby <int> 83, 58, 82, 78, 73, 75, 72, 85, 70, 70, 77, 77, 74, 68, 88, 8…
$ status <int> 1, 2, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 1, 1, 1, 2, 1, 1, 2…
$ youngdep <int> 1, 2, 1, 1, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2…
$ elderdep <int> 1, 1, 1, 2, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ qualif <int> 5, 5, 4, 5, 4, 5, 4, 5, 2, 2, 2, 3, 2, 5, 2, 1, 1, 2, 3, 5, 2…
$ exercise <int> 4, 2, 6, 3, 2, 6, 4, 3, 1, 3, 3, 2, 4, 1, 4, 3, 3, 4, 5, 2, 4…
$ cigs <int> 1, 2, 2, 1, 1, 1, 2, 2, 1, 1, 1, 2, 1, 2, 1, 2, 2, 2, 2, 2, 4…
$ alcohol <dbl> 1, 0, 0, 2, 3, 4, 0, 0, 1, 4, 0, 10, 40, 30, 10, 0, 15, 0, 15…
$ time_rel <int> 2, 2, 1, 2, 2, 5, 1, 3, 1, 2, 3, 2, 2, 1, 2, 4, 2, 3, 1, 2, 3…
$ when_rel <int> 1, 2, 1, 1, 1, 2, 1, 2, 2, 2, 2, 2, 1, 1, 2, 4, 2, 1, 2, 1, 1…
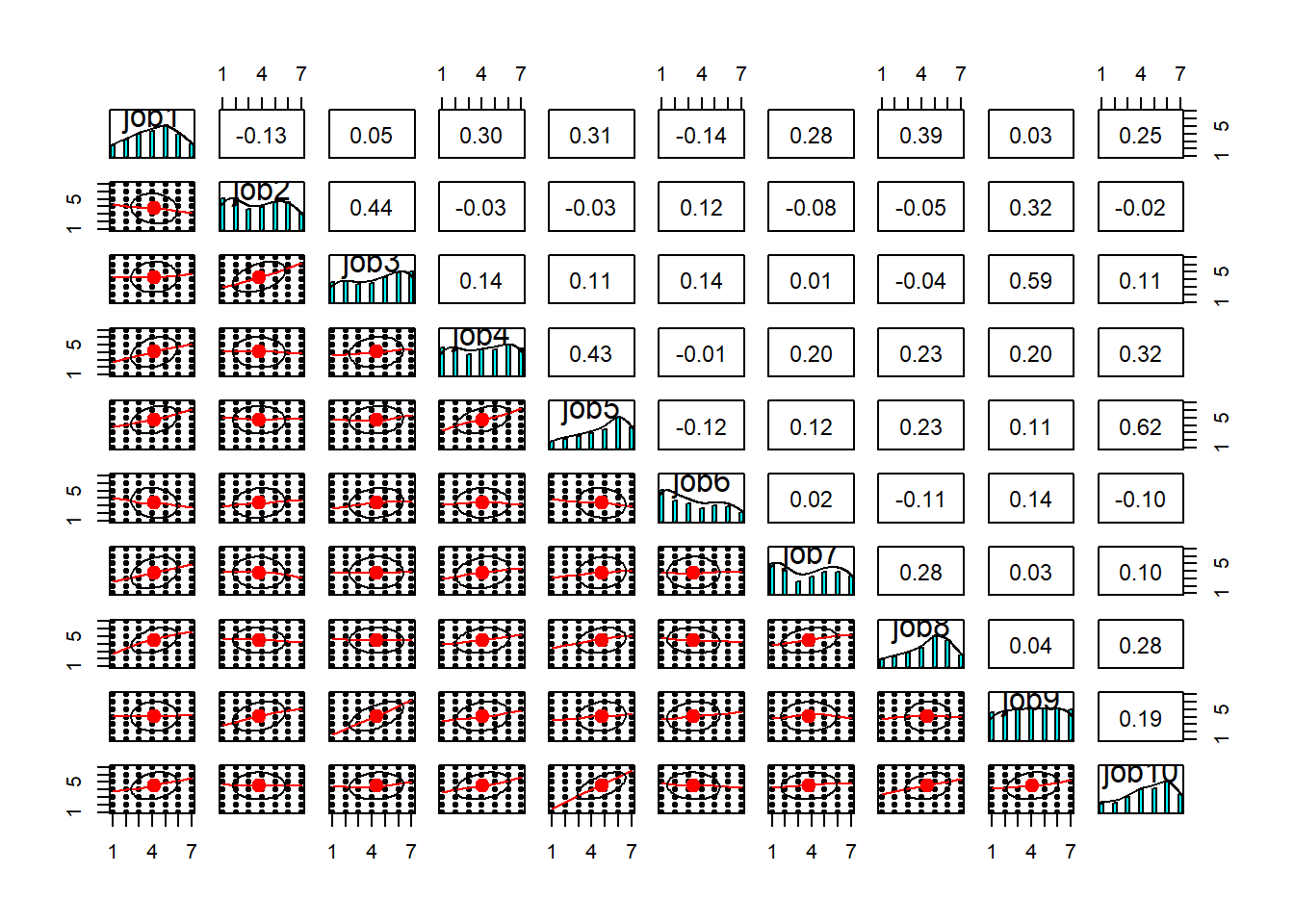
$ job1 <int> 5, 5, 1, 6, 1, 3, 5, 4, 6, 6, 5, 5, 4, 6, 4, 5, 5, 5, 4, 5, 5…
$ job2 <int> 4, 7, 4, 4, 1, 4, 4, 1, 2, 6, 3, 2, 3, 2, 1, 2, 4, 6, 4, 5, 3…
$ job3 <int> 5, 4, 7, 5, 5, 5, 6, 7, 4, 7, 1, 4, 3, 2, 4, 3, 1, 6, 3, 5, 6…
$ job4 <int> 4, 3, 1, 5, 5, 3, 7, 7, 5, 6, 7, 7, 3, 6, 6, 6, 6, 6, 4, 3, 2…
$ job5 <int> 6, 6, 1, 6, 1, 4, 5, 7, 4, 7, 6, 6, 6, 6, 6, 6, 4, 6, 4, 6, 5…
$ job6 <int> 4, 2, 1, 4, 2, 3, 5, 1, 2, 7, 2, 2, 1, 1, 1, 2, 1, 2, 1, 2, 1…
$ job7 <int> 7, 1, 7, 5, 2, 4, 4, 5, 4, 6, 5, 6, 5, 7, 4, 4, 7, 5, 6, 7, 7…
$ job8 <int> 7, 4, 7, 5, 2, 3, 5, 5, 6, 7, 7, 6, 4, 6, 5, 4, 6, 6, 5, 3, 6…
$ job9 <int> 4, 5, 3, 5, 5, 5, 6, 7, 2, 7, 3, 4, 6, 2, 1, 2, 1, 5, 2, 6, 3…
$ job10 <int> 7, 6, 1, 6, 2, 4, 5, 7, 4, 7, 6, 6, 6, 6, 6, 4, 4, 5, 5, 6, 4…
$ job11 <int> 4, 1, 7, 5, 3, 3, 6, 1, 5, 7, 3, 5, 5, 6, 6, 4, 5, 5, 6, 4, 6…
$ job12 <int> 4, 5, 4, 3, 3, 3, 3, 1, 4, 7, 4, 2, 1, 4, 2, 2, 2, 2, 2, 2, 2…
$ job13 <int> 1, 4, 1, 4, 4, 4, 4, 1, 5, 7, 3, 4, 2, 7, 1, 4, 2, 4, 4, 6, 4…
$ job14 <int> 4, 5, 7, 2, 6, 1, 2, 1, 1, 7, 7, 6, 4, 6, 4, 4, 7, 4, 6, 6, 4…
$ job15 <int> 4, 7, 3, 7, 2, 6, 6, 7, 5, 5, 4, 4, 7, 6, 3, 5, 5, 4, 4, 3, 5…
$ job16 <int> 6, 5, 1, 2, 2, 3, 3, 7, 4, 5, 6, 6, 6, 6, 5, 4, 4, 6, 5, 6, 3…
$ job17 <int> 4, 1, 1, 4, 2, 5, 3, 7, 3, 7, 2, 2, 3, 2, 1, 2, 2, 2, 1, 2, 3…
$ job18 <int> 7, 7, 7, 6, 3, 5, 5, 3, 6, 2, 3, 5, 5, 6, 5, 5, 6, 6, 4, 5, 3…
$ job19 <int> 7, 1, 7, 7, 2, 6, 7, 3, 6, 2, 1, 2, 2, 6, 1, 5, 5, 6, 2, 2, 2…
$ job20 <int> 3, 5, 7, 5, 1, 3, 7, 6, 3, 3, 4, 3, 3, 4, 3, 6, 1, 5, 3, 6, 5…
$ job21 <int> 4, 1, 7, 5, 1, 3, 3, 1, 5, 6, 3, 5, 5, 6, 4, 4, 3, 5, 4, 2, 5…
$ job22 <int> 3, 1, 1, 2, 4, 1, 2, 1, 2, 6, 2, 5, 2, 2, 1, 6, 1, 5, 3, 5, 3…
$ job23 <int> 5, 1, 2, 4, 6, 3, 6, 1, 5, 7, 2, 5, 6, 4, 4, 2, 4, 5, 5, 6, 6…
$ job24 <int> 4, 4, 5, 4, 2, 4, 4, 4, 5, 6, 4, 6, 4, 2, 3, 6, 5, 6, 5, 4, 2…
$ job25 <int> 4, 5, 6, 5, 3, 2, 3, 7, 5, 4, 5, 5, 5, 3, 4, 6, 4, 6, 4, 6, 3…
$ job26 <int> 7, 6, 7, 3, 6, 5, 6, 7, 6, 4, 1, 5, 6, 6, 4, 6, 4, 4, 5, 4, 4…
$ job27 <int> 2, 4, 1, 2, 6, 5, 1, 1, 3, 7, 6, 3, 1, 1, 1, 2, 2, 4, 6, 6, 2…
$ job28 <int> 3, 6, 7, 5, 2, 5, 6, 1, 4, 7, 3, 3, 5, 1, 3, 4, 1, 3, 2, 6, 5…
$ job29 <int> 3, 3, 5, 7, 5, 6, 5, 1, 3, 7, 4, 4, 3, 2, 2, 4, 3, 3, 5, 5, 3…
$ job30 <int> 4, 3, 6, 5, 1, 2, 3, 6, 6, 4, 7, 6, 4, 4, 3, 4, 4, 6, 4, 2, 3…
$ job31 <int> 5, 1, 5, 3, 4, 5, 4, 1, 5, 5, 5, 3, 4, 6, 5, 6, 6, 6, 5, 4, 2…
$ job32 <int> 5, 7, 3, 2, 2, 1, 3, 2, 6, 5, 5, 5, 4, 7, 5, 5, 5, 6, 5, 5, 5…
$ job33 <int> 6, 4, 6, 5, 4, 3, 7, 4, 6, 4, 6, 3, 4, 2, 3, 6, 6, 6, 4, 2, 2…
$ job34 <int> 4, 6, 5, 7, 4, 5, 6, 1, 5, 5, 2, 2, 2, 2, 3, 5, 5, 5, 1, 2, 4…
$ job35 <int> 4, 6, 3, 5, 4, 1, 3, 1, 5, 6, 5, 5, 4, 6, 5, 4, 5, 5, 7, 5, 6…
$ job36 <int> 4, 1, 2, 3, 2, 5, 2, 1, 5, 6, 5, 3, 4, 6, 5, 6, 6, 5, 7, 5, 5…
$ job37 <int> 4, 5, 1, 3, 2, 3, 3, 7, 3, 6, 7, 4, 6, 7, 4, 5, 6, 5, 6, 5, 5…
$ job38 <int> 4, 5, 5, 2, 2, 1, 3, 1, 3, 7, 7, 5, 6, 7, 3, 6, 6, 5, 6, 5, 5…
$ job39 <int> 5, 7, 5, 7, 2, 5, 6, 7, 6, 5, 4, 5, 6, 7, 3, 5, 5, 5, 2, 1, 4…
$ job40 <int> 4, 3, 5, 3, 4, 3, 3, 7, 3, 6, 3, 5, 6, 7, 4, 4, 6, 6, 4, 6, 1…
$ job41 <int> 6, 5, 3, 5, 1, 1, 3, 1, 5, 7, 3, 5, 5, 6, 4, 5, 7, 6, 5, 6, 5…
$ job42 <int> 6, 4, 5, 4, 5, 3, 4, 1, 4, 5, 4, 6, 5, 7, 4, 5, 5, 6, 4, 3, 5…
$ job43 <int> 6, 1, 7, 3, 4, 5, 1, 2, 3, 7, 2, 6, 4, 6, 5, 4, 7, 6, 2, 6, 4…
$ job44 <int> 6, 4, 6, 5, 2, 3, 7, 1, 5, 7, 7, 6, 4, 5, 6, 5, 6, 6, 6, 5, 3…
$ job45 <int> 6, 6, 7, 7, 6, 3, 6, 7, 6, 7, 5, 4, 6, 6, 5, 6, 4, 6, 4, 2, 6…
$ job46 <int> 3, 1, 2, 3, 6, 6, 3, 7, 3, 5, 5, 2, 2, 2, 1, 2, 2, 5, 1, 1, 2…
$ job47 <int> 3, 4, 5, 5, 1, 3, 3, 3, 3, 6, 5, 5, 4, 4, 3, 6, 5, 5, 4, 4, 3…
$ job48 <int> 3, 7, 7, 7, 6, 4, 6, 7, 5, 6, 5, 3, 6, 3, 4, 5, 4, 5, 3, 1, 6…
$ job49 <int> 6, 5, 5, 6, 2, 2, 5, 2, 6, 7, 5, 3, 6, 6, 7, 6, 7, 6, 6, 6, 7…
$ job50 <int> 3, 5, 1, 3, 1, 7, 4, 1, 5, 6, 5, 4, 4, 5, 1, 2, 5, 3, 4, 5, 7…