| Item | Statement |
|---|---|
| Item_1 | I often felt an inability to concentrate |
| Item_2 | I frequently forgot things |
| Item_3 | I found thinking clearly required a lot of effort |
| Item_4 | I often felt happy |
| Item_5 | I had lots of energy |
| Item_6 | I worked efficiently |
| Item_7 | I often felt irritable |
| Item_8 | I often felt stressed |
| Item_9 | I often felt sleepy |
| Item_10 | I often felt fatigued |
Exercises: Covariance, Correlation & Linear Regression
Covariance & Correlation
Question 1
Go to http://guessthecorrelation.com/ and play the “guess the correlation” game for a little while to get an idea of what different strengths and directions of \(r\) can look like.
Sleepy time
Data: Sleep levels and daytime functioning
A researcher is interested in the relationship between hours slept per night and self-rated effects of sleep on daytime functioning. She recruited 50 healthy adults, and collected data on the Total Sleep Time (TST) over the course of a seven day period via sleep-tracking devices.
At the end of the seven day period, participants completed a Daytime Functioning (DTF) questionnaire. This involved participants rating their agreement with ten statements (see Table 1). Agreement was measured on a scale from 1-5. An overall score of daytime functioning can be calculated by:
- reversing the scores for items 4,5 and 6 (because those items reflect agreement with positive statements, whereas the other ones are agreement with negative statement);
- summing the scores on each item; and
- subtracting the sum score from 50 (the max possible score). This will make higher scores reflect better perceived daytime functioning.
The data is available at https://uoepsy.github.io/data/sleepdtf.csv.
Question 2
Load the required libraries (probably just tidyverse for now), and read in the data.
Calculate the overall daytime functioning score, following the criteria outlined above, and make this a new column in your dataset.
Hints
To reverse items 4, 5 and 6, we we need to make all the scores of 1 become 5, scores of 2 become 4, and so on… What number satisfies all of these equations: ? - 5 = 1, ? - 4 = 2, ? - 3 = 3?
To quickly sum across rows, you might find the rowSums() function useful (you don’t have to use it though)
If my items were in columns between 4 to 15:
dataframe$sumscore = rowSums(dataframe[, 4:15])
Question 3
Calculate the correlation between the total sleep time (TST) and the overall daytime functioning score calculated in the previous question.
Conduct a test to establish the probability of observing a correlation this strong in a sample of this size assuming the true correlation to be 0.
Write a sentence or two summarising the results.
Hints
You can do this all with one function, see 5A #correlation-test.
Question 4 (open-ended)
Think about this relationship in terms of causation.
Claim: Less sleep causes poorer daytime functioning.
Why might it be inappropriate to make the claim above based on these data alone? Think about what sort of study could provide stronger evidence for such a claim.
Things to think about:
- comparison groups.
- random allocation.
- measures of daytime functioning.
- measures of sleep time.
- other (unmeasured) explanatory variables.
Attendance and Attainment
Data: Education SIMD Indicators
The Scottish Government regularly collates data across a wide range of societal, geographic, and health indicators for every “datazone” (small area) in Scotland.
The dataset at https://uoepsy.github.io/data/simd20_educ.csv contains some of the education indicators (see Table 2).
| variable | description |
|---|---|
| intermediate_zone | Areas of scotland containing populations of between 2.5k-6k household residents |
| attendance | Average School pupil attendance |
| attainment | Average attainment score of School leavers (based on Scottish Credit and Qualifications Framework (SCQF)) |
| university | Proportion of 17-21 year olds entering university |
Question 5
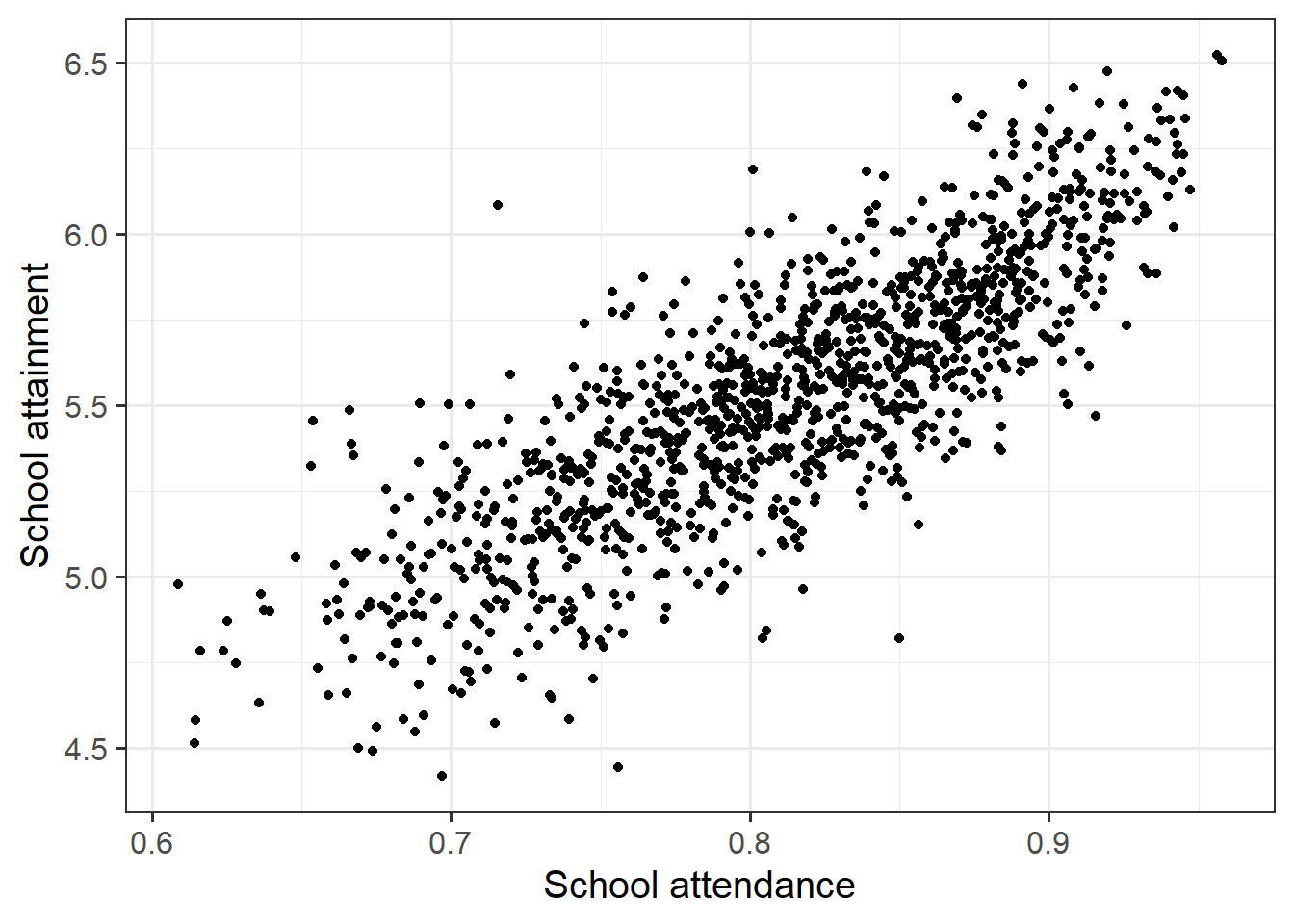
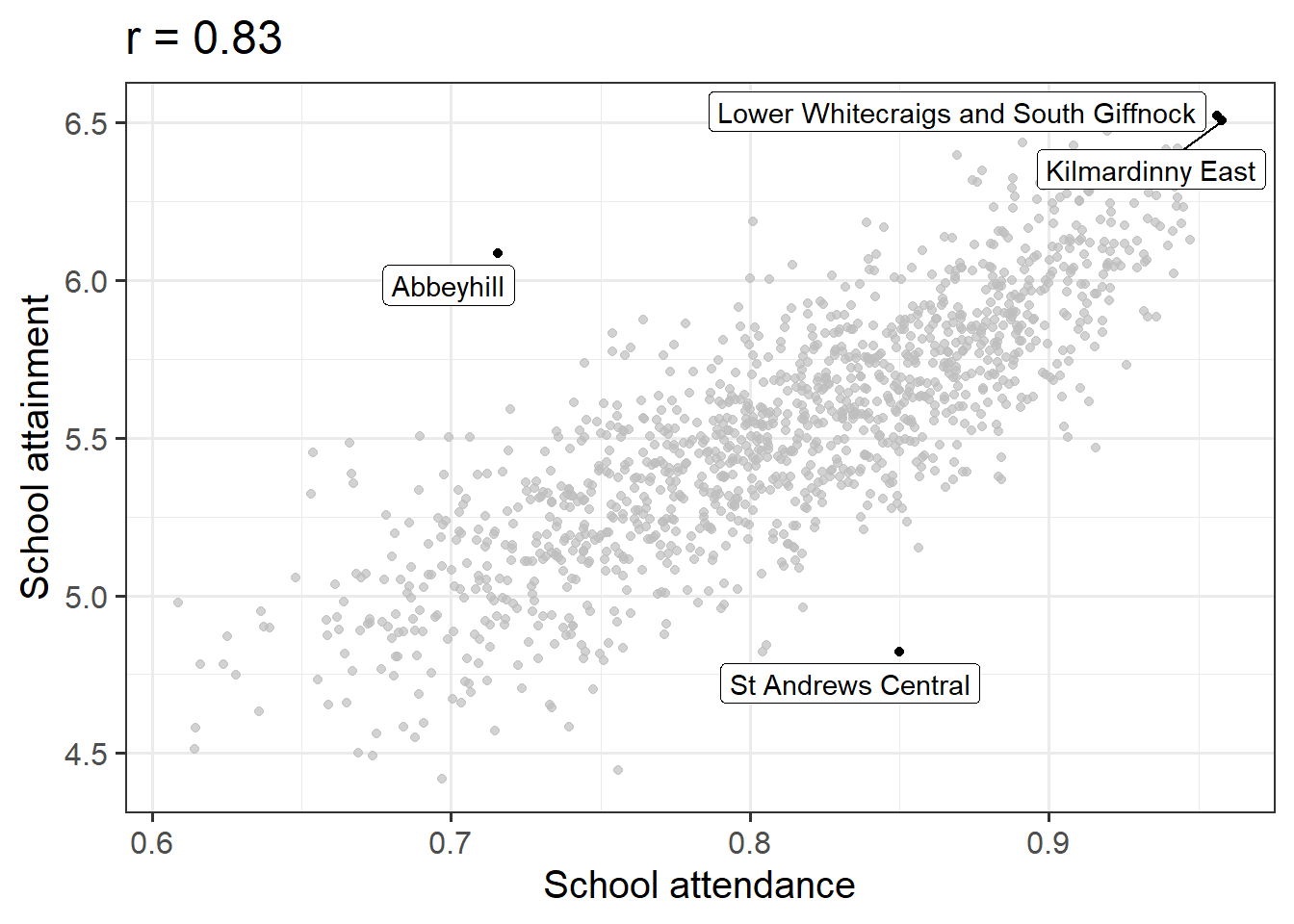
Conduct a test of whether there is a correlation between school attendance and school attainment in Scotland.
Present and write up the results.
Hints
The readings have not included an example write-up for you to follow. Try to follow the logic of those for t-tests and \(\chi^2\)-tests.
- describe the relevant data
- explain what test was conducted and why
- present the relevant statistic, degrees of freedom (if applicable), statement on p-value, etc.
- state the conclusion.
Be careful figuring out how many observations your test is conducted on. cor.test() includes only the complete observations.
Simple Linear Regression
Monkey Exploration
Data: monkeyexplorers.csv
Archer, Winther & Gandolfi (2024)1 have conducted a study on monkeys! They were interested in whether younger monkeys tend to be more inquisitive about new things than older monkeys do. They sampled 108 monkeys ranging from 1 to 24 years old. Each monkey was given a novel object, the researchers recorded the time (in minutes) that each monkey spent exploring the object.
For this week, we’re going to be investigating the research question:
Do older monkeys spend more/less time exploring novel objects?
The data is available at https://uoepsy.github.io/data/monkeyexplorers.csv and contains the variables described in Table 3
| variable | description |
|---|---|
| name | Monkey Name |
| age | Age of monkey in years |
| exploration_time | Time (in minutes) spent exploring the object |
Question 6
For this week, we’re going to be investigating the following research question:
Do older monkeys spend more/less time exploring novel objects?
Read in the data to your R session, then visualise and describe the marginal distributions of those variables which are of interest to us. These are the distribution of each variable (time spent exploring, and monkey age) without reference to the values of the other variables.
Hints
- You could use, for example,
geom_density()for a density plot orgeom_histogram()for a histogram. - Look at the shape, center and spread of the distribution. Is it symmetric or skewed? Is it unimodal or bimodal?
- Do you notice any extreme observations?

Question 7
After we’ve looked at the marginal distributions of the variables of interest in the analysis, we typically move on to examining relationships between the variables.
Visualise and describe the relationship between age and exploration-time among the monkeys in the sample.
Hints
Think about:
- Direction of association
- Form of association (can it be summarised well with a straight line?)
- Strength of association (how closely do points fall to a recognizable pattern such as a line?)
- Unusual observations that do not fit the pattern of the rest of the observations and which are worth examining in more detail.
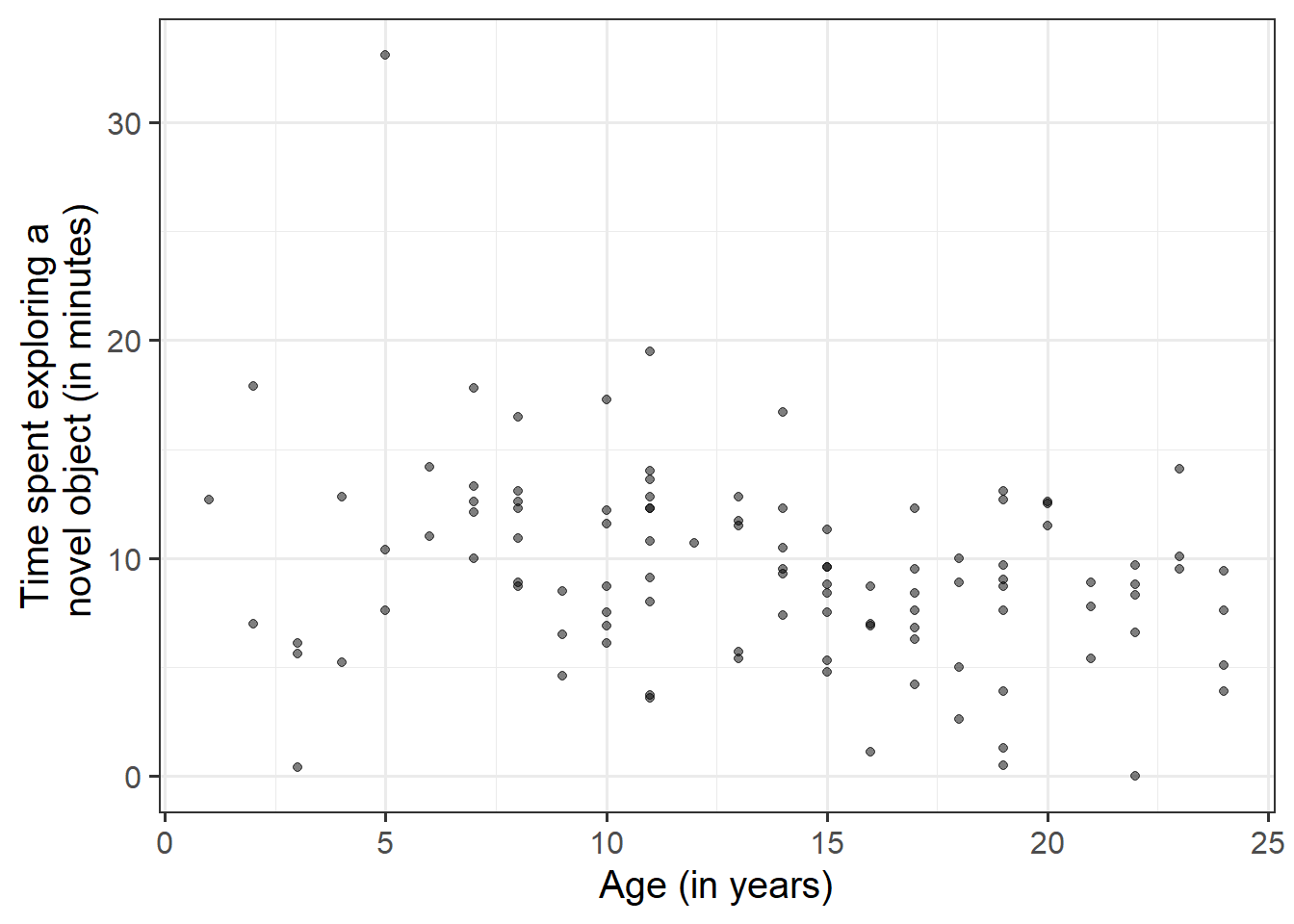
Question 8
Using the lm() function, fit a linear model to the sample data, in which time that monkeys spend exploring novel objects is explained by age. Assign it to a name to store it in your environment.
Hints
You can see how to fit linear models in R using lm() in 5B #fitting-linear-models-in-r
Question 9
Interpret the estimated intercept and slope in the context of the question of interest.
Hints
We saw how to extract lots of information on our model using summary() (see 5B #model-summary), but there are lots of other functions too.
If we called our linear model object “model1” in the environment, then we can use:
- type
model1, i.e. simply invoke the name of the fitted model; - type
model1$coefficients; - use the
coef(model1)function; - use the
coefficients(model1)function; - use the
summary(model1)$coefficientsto extract just that part of the summary.
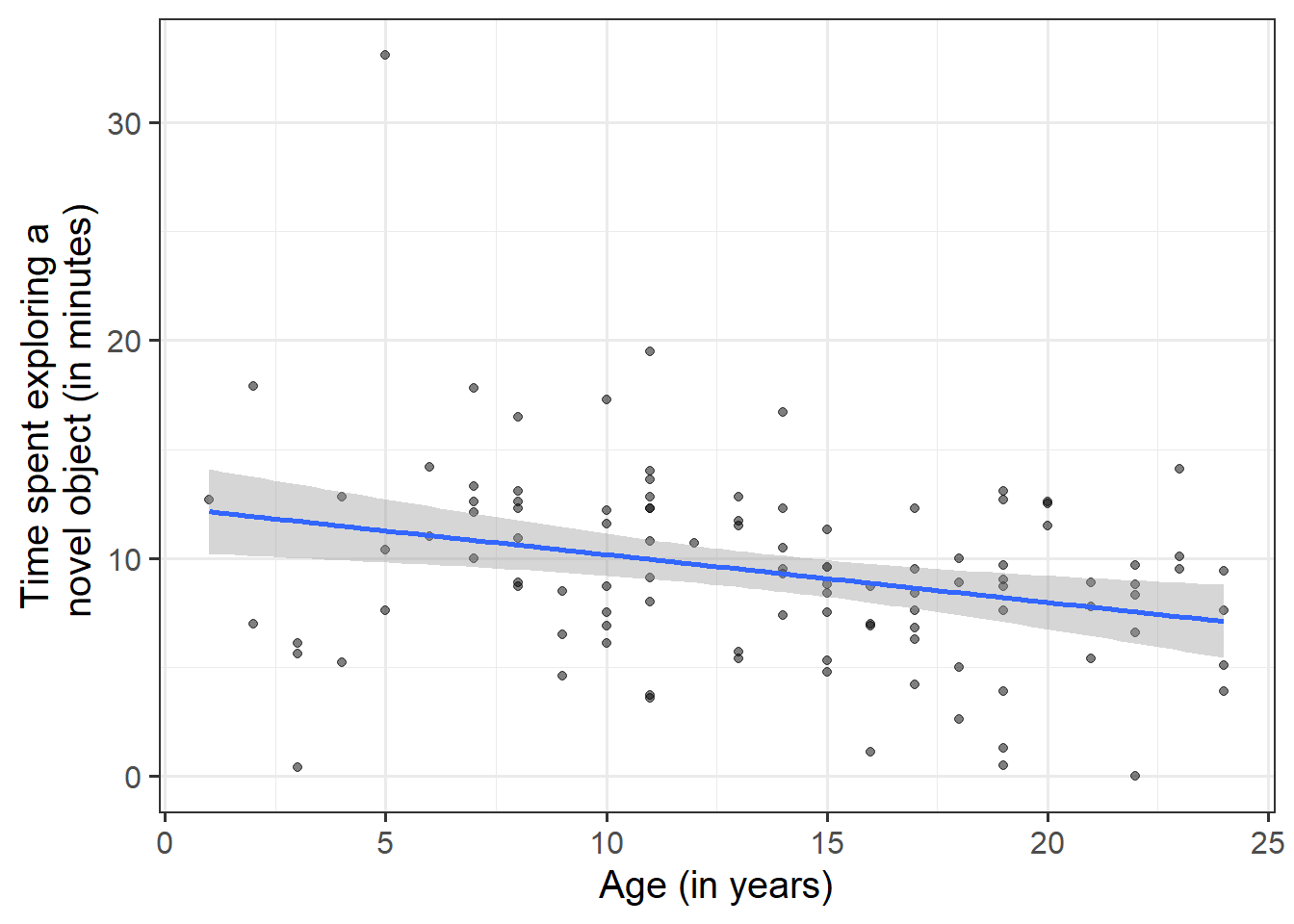


Footnotes
Not a real study!↩︎