Linear Regression Basics
This lab is a long one! We did cover most of this content to varying degrees in the lectures over the past two weeks.
A note on notation
You will see a variety of different ways of specifying the linear model form in different resources.
Some use \(\beta\), some use \(b\).
In the lectures, you have seen the form \(\color{red}{y} = \color{blue}{b_0 \cdot{} 1 + b_1 \cdot{} x} + \epsilon\).
In the exercises below, we will tend to use \(\color{red}{Y} = \color{blue}{\beta_0 \cdot{} 1 + \beta_1 \cdot{} X} + \epsilon\), to denote our population model, which when fitted on some sample data becomes \(\color{red}{\hat{Y}} = \color{blue}{\hat{\beta}_0 \cdot{} 1 + \hat{\beta_1} \cdot{} X} + \hat{\epsilon}\) (the little hats indicate that they are fitted estimates).
It’s important to take regular breaks. This will help (a bit) with not getting overwhelmed. If you were to sit down and read through this all in one sitting, it would be completely understandable that you might end up shouting at your computer.

These things (both the statistics side and the programming side) take time - and repeated practice - to sink in.
Exercises: Simple regression
Let’s imagine a study into income disparity for workers in a local authority. We might carry out interviews and find that there is a link between the level of education and an employee’s income. Those with more formal education seem to be better paid. Now we wouldn’t have time to interview everyone who works for the local authority so we would have to interview a sample, say 10%.
In this lab we will use the riverview data (available at https://uoepsy.github.io/data/riverview.csv) to examine whether education level is related to income among the employees working for the city of Riverview, a hypothetical midwestern city in the US.
Load the required libraries and import the riverview data into a variable named riverview.
Exploring the data
We first want to visualise and describe the marginal distributions (the distribution of each variable without reference to the values of the other variables) of employee incomes and education levels.
- You could use, for example,
geom_density()for a density plot orgeom_histogram()for a histogram. - Look at the shape, centre and spread of the distribution. Is it symmetric or skewed? Is it unimodal or bimodal?
- Do you notice any extreme observations?
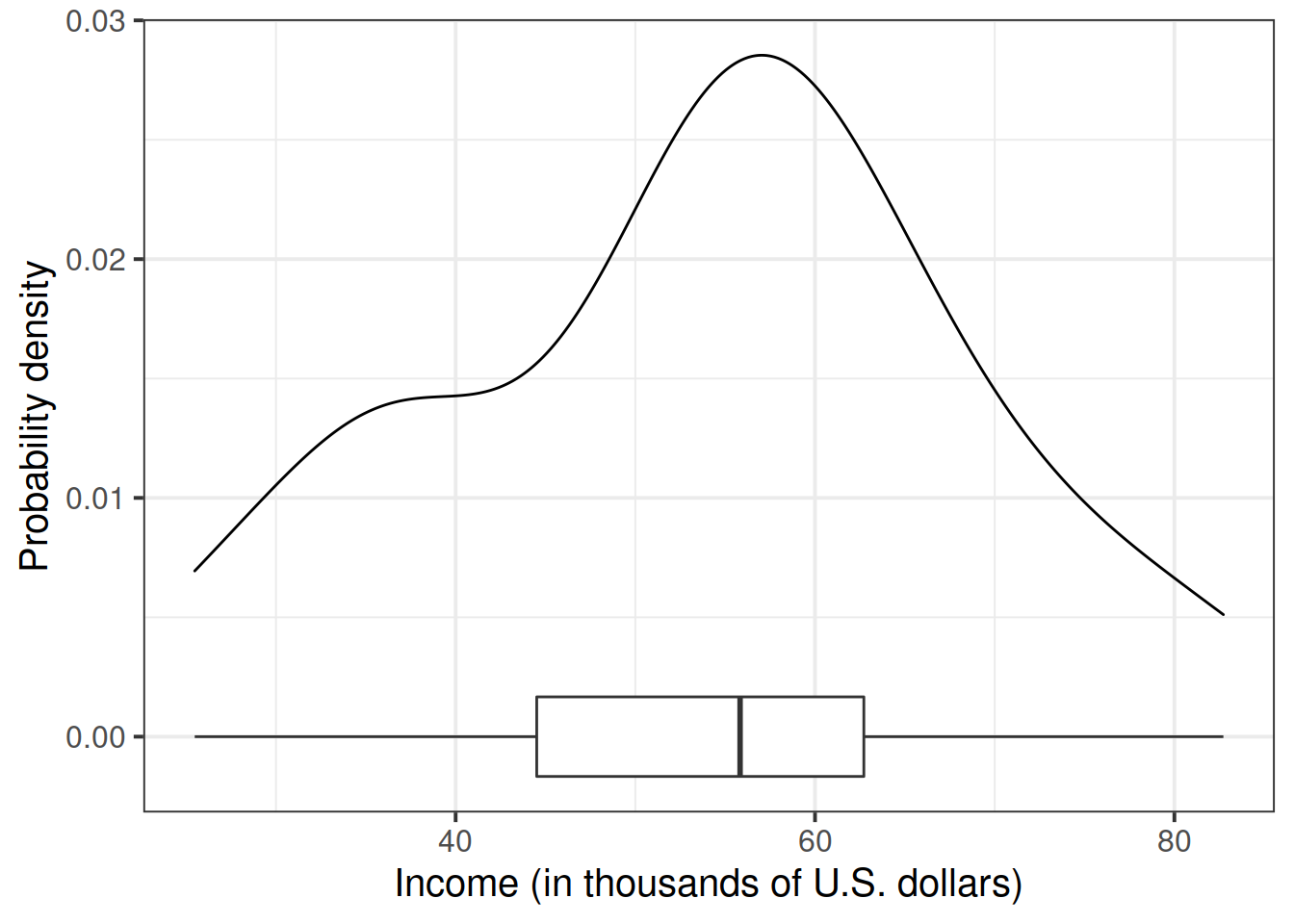
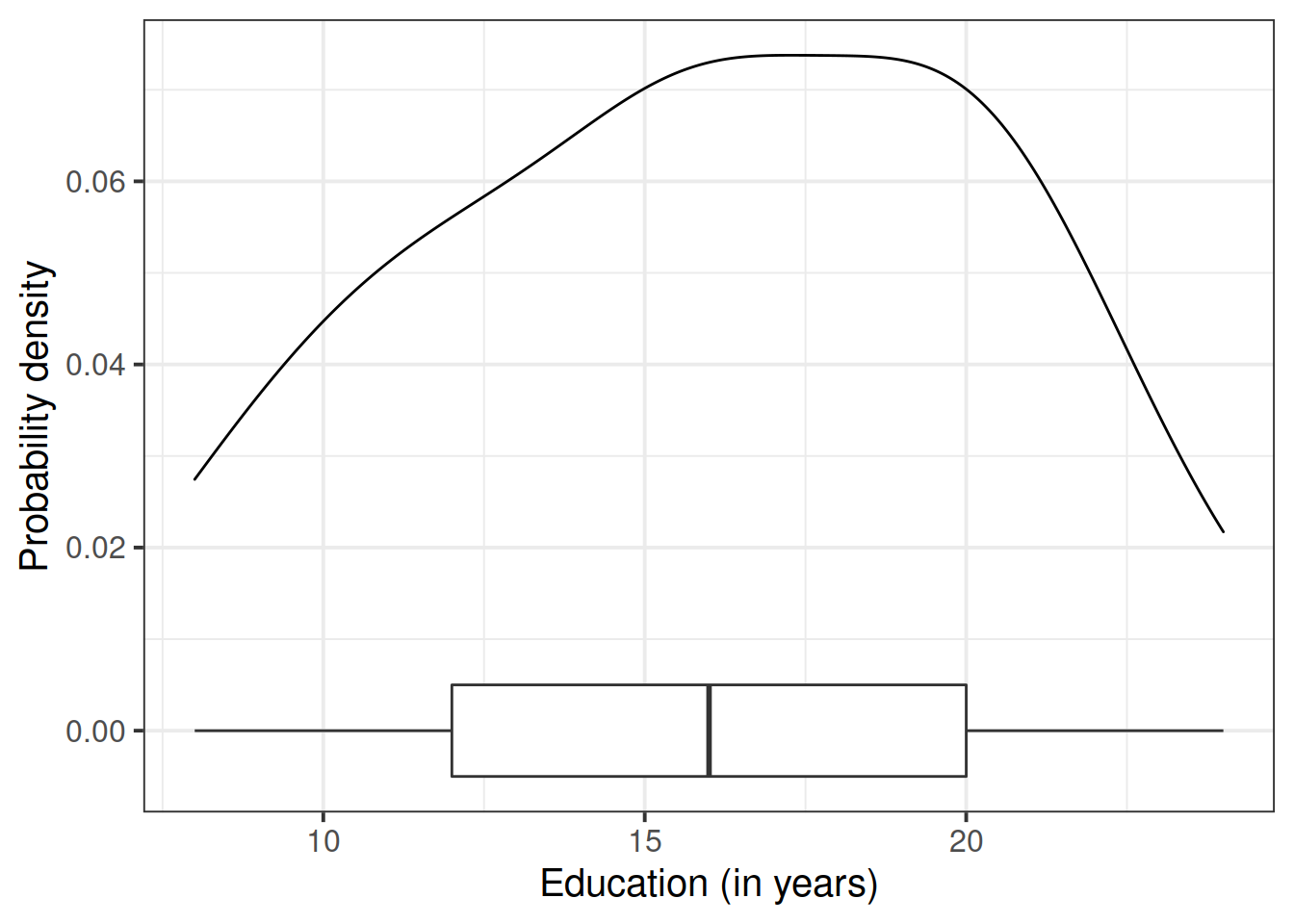
After examining the marginal distributions of the variables of interest in the analysis, we typically move on to examining relationships between the variables.
Visualise and describe the relationship between income and level of education among the employees in the sample.
Think about:
- Direction of association
- Form of association (can it be summarised well with a straight line?)
- Strength of association (how closely do points fall to a recognizable pattern such as a line?)
- Unusual observations that do not fit the pattern of the rest of the observations and which are worth examining in more detail.
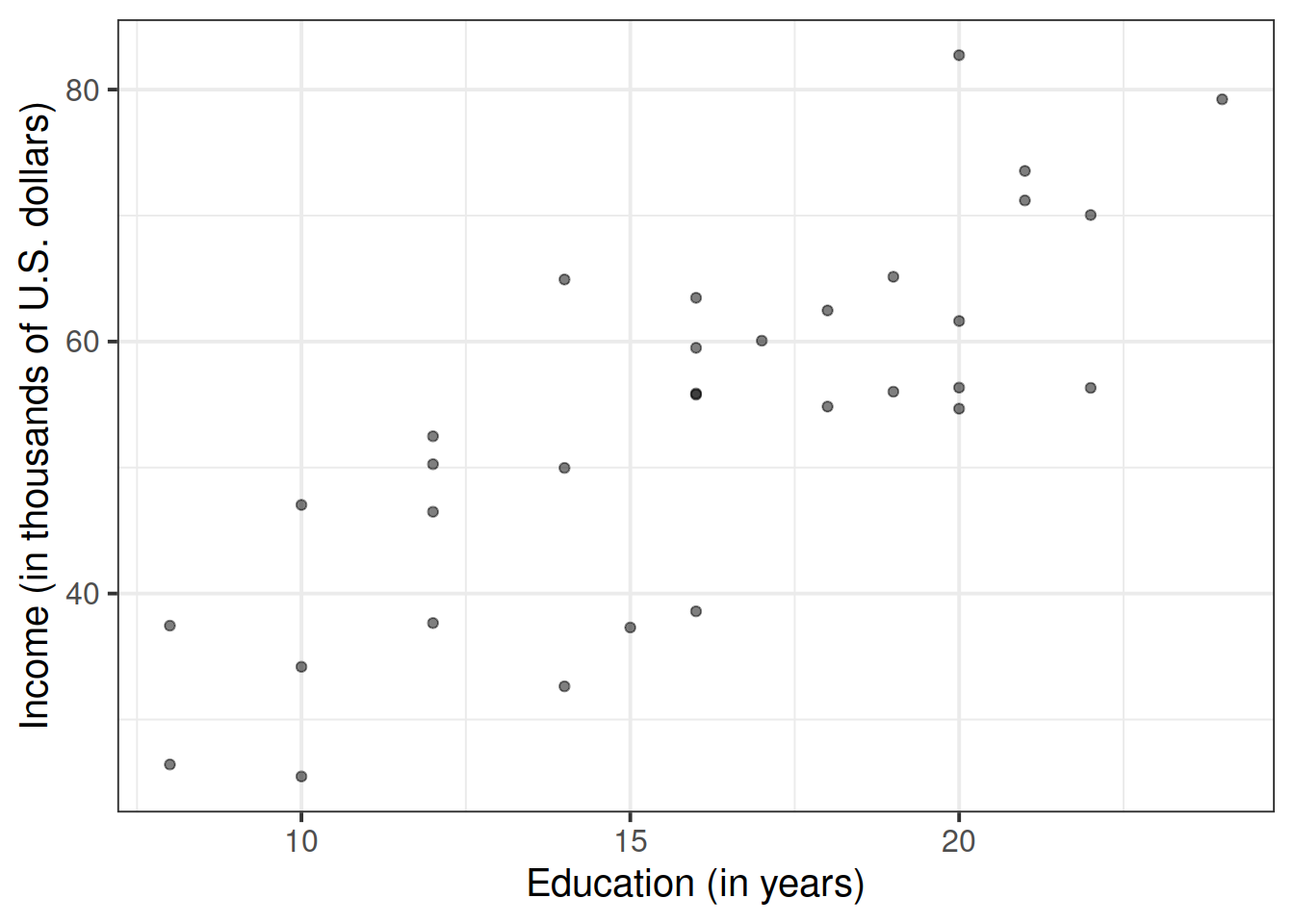
Fitting a model
The scatterplot highlights a linear relationship, where the data points are scattered around an underlying linear pattern with a roughly-constant spread as x varies.
Hence, we will try to fit a simple (one \(x\) variable only) linear regression model:
\[ Income = \beta_0 + \beta_1 \ Education + \epsilon \quad \\ \text{where} \quad \epsilon \sim N(0, \sigma) \text{ independently} \]
where “\(\epsilon \sim N(0, \sigma) \text{ independently}\)” means that the errors around the line have mean zero and constant spread as x varies.
Fit the linear model to the sample data using the lm() function and name the output mdl.
Hint:
The syntax of the lm() function is:
lm(<response variable> ~ 1 + <explanatory variable>, data = <dataframe>)
Interpreting coefficients
Interpret the estimated intercept and slope in the context of the question of interest.
To obtain the estimated regression coefficients you can either:
- type
mdl, i.e. simply invoke the name of the fitted model; - type
mdl$coefficients; - use the
coef(mdl)function; - use the
coefficients(mdl)function; - use the
summary(mdl)function and look under the “Estimate” column.
The estimated parameters returned by the above methods are all equivalent. However, summary() returns more information and you need to look under the column “Estimate”.
The parameter estimates from our simple linear regression model take the form of a line, representing the systemtic part of our model \(\beta_0 + \beta_1 x\), which in our case is \(11.32 + 2.65 \ Education\). Deviations from the line are determined by the random error component \(\hat \epsilon\) (the red lines in Figure 4 below).
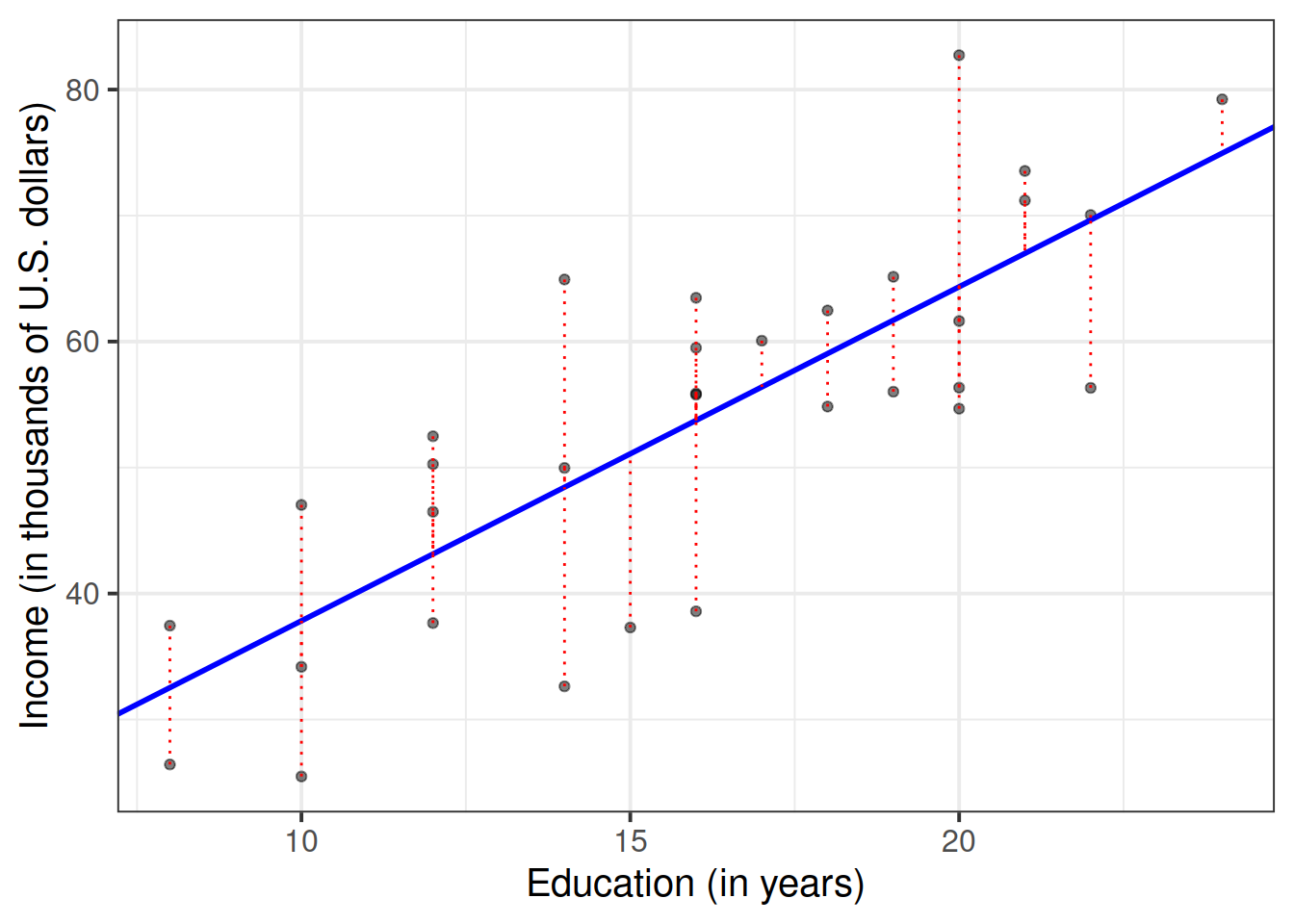
Figure 4: Simple linear regression model, with systematic part of the model in blue and residuals in red
Interpreting \(\sigma\)
Consider the following:
- In fitting a linear regression model, we make the assumption that the errors around the line are normally distributed around zero (this is the \(\epsilon \sim N(0, \sigma)\) bit.)
- About 95% of values from a normal distribution fall within two standard deviations of the centre.
We can obtain the estimated standard deviation of the errors (\(\hat \sigma\)) from the fitted model using sigma(mdl).
What does this tell us?
Inference for regression coefficients
To quantify the amount of uncertainty in each estimated coefficient that is due to sampling variability, we use the standard error (SE) of the coefficient. Recall that a standard error gives a numerical answer to the question of how variable a statistic will be because of random sampling.
The standard errors are found in the column “Std. Error” of the summary() of a model:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 11.321379 6.1232350 1.848921 7.434602e-02
## education 2.651297 0.3696232 7.172972 5.562116e-08In this example the slope, 2.651, has a standard error of 0.37. One way to envision this is as a distribution. Our best guess (mean) for the slope parameter is 2.651. The standard deviation of this distribution is 0.37, which indicates the precision (uncertainty) of our estimate.
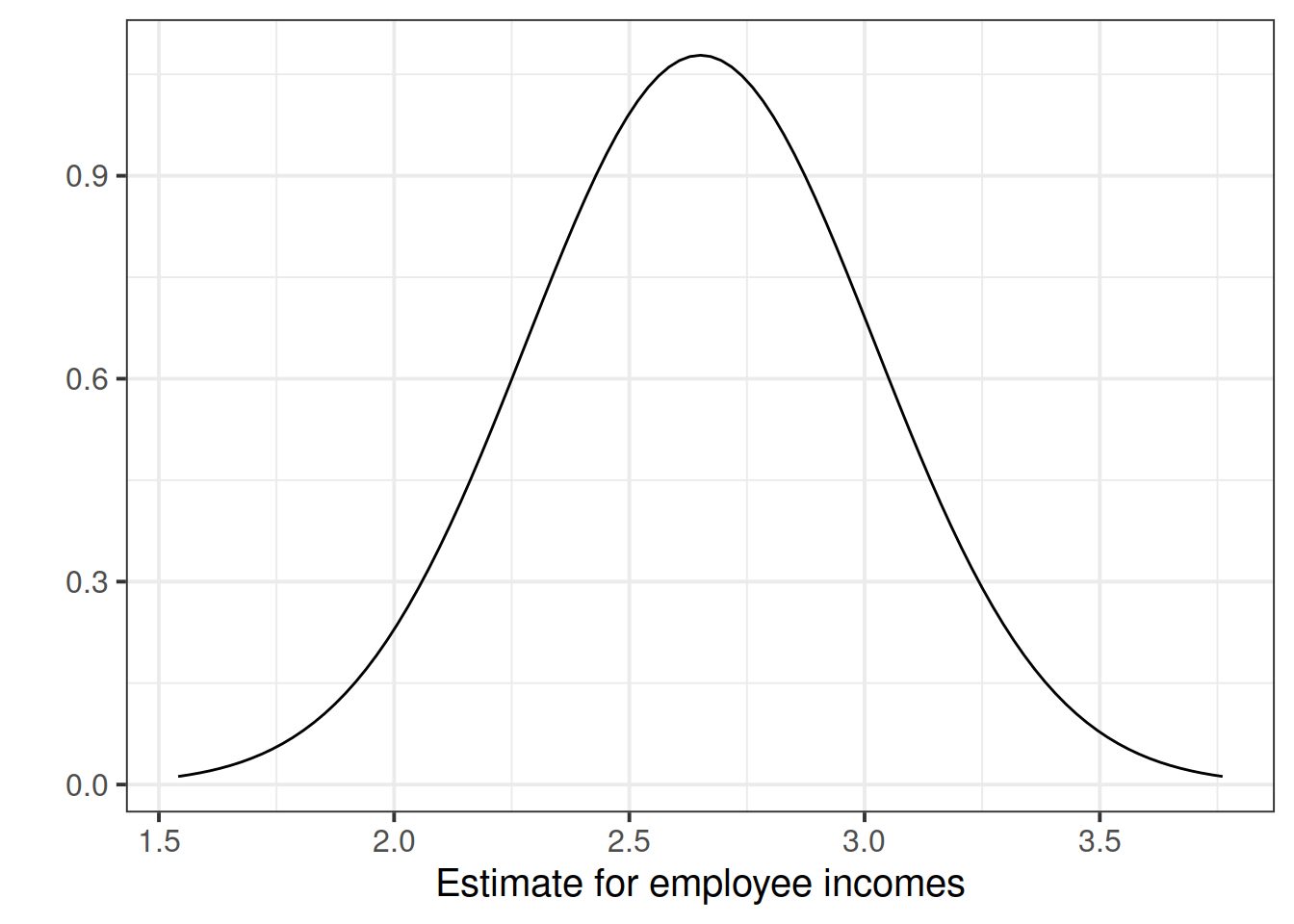
Figure 5: Sampling distribution of the slope coefficient. The distribution is approximately bell-shaped with a mean of 2.651 and a standard error of 0.37.
We can perform a test against the null hypothesis that the estimate is zero. Our test statistic:
The reference distribution in this case is a t-distribution with \(n-2\) degrees of freedom, where \(n\) is the sample size, and our test statistic is:
\[
t = \frac{\hat \beta_1 - 0}{SE(\hat \beta_1)}
\]
Test the hypothesis that the population slope is zero — that is, that there is no linear association between income and education level in the population.
(Hint: you can find all the necessary information in summary(mdl))
Fitted and predicted values
To compute the model-predicted values for the data in the sample:
predict(<fitted model>)fitted(<fitted model>)fitted.values(<fitted model>)mdl$fitted.values
predict(mdl)## 1 2 3 4 5 6 7 8
## 32.53175 32.53175 37.83435 37.83435 37.83435 43.13694 43.13694 43.13694
## 9 10 11 12 13 14 15 16
## 43.13694 48.43953 48.43953 48.43953 51.09083 53.74212 53.74212 53.74212
## 17 18 19 20 21 22 23 24
## 53.74212 53.74212 56.39342 59.04472 59.04472 61.69601 61.69601 64.34731
## 25 26 27 28 29 30 31 32
## 64.34731 64.34731 64.34731 66.99861 66.99861 69.64990 69.64990 74.95250To compute model-predicted values for other data:
predict(<fitted model>, newdata = <dataframe>)
# make a tibble/dataframe with values for the predictor:
education_query <- tibble(education = c(11, 18))
# model predicted values of income, for the values of education
# inside the "education_query" data
predict(mdl, newdata = education_query)## 1 2
## 40.48564 59.04472Compute the model-predicted income for someone with 1 year of education.
Partitioning variation
We might ask ourselves if the model is useful. To quantify and assess model utility, we split the total variability of the response into two terms: the variability explained by the model plus the variability left unexplained in the residuals.
\[ \text{total variability in response = variability explained by model + unexplained variability in residuals} \]
Each term is quantified by a sum of squares:
\[ \begin{aligned} SS_{Total} &= SS_{Model} + SS_{Residual} \\ \sum_{i=1}^n (y_i - \bar y)^2 &= \sum_{i=1}^n (\hat y_i - \bar y)^2 + \sum_{i=1}^n (y_i - \hat y_i)^2 \\ \quad \\ \text{Where:} \\ y_i = \text{observed value} \\ \bar{y} = \text{mean} \\ \hat{y}_i = \text{model predicted value} \\ \end{aligned} \]
The R-squared coefficient is defined as the proportion of the total variability in the outcome variable which is explained by our model:
\[
R^2 = \frac{SS_{Model}}{SS_{Total}} = 1 - \frac{SS_{Residual}}{SS_{Total}}
\]
What is the proportion of the total variability in incomes explained by the linear relationship with education level?
Hint: The question asks to compute the value of \(R^2\), but you might be able to find it already computed somewhere.
Testing Model Utility
To test if the model is useful — that is, if the explanatory variable is a useful predictor of the response — we test the following hypotheses:
\[ \begin{aligned} H_0 &: \text{the model is ineffective, } \beta_1 = 0 \\ H_1 &: \text{the model is effective, } \beta_1 \neq 0 \end{aligned} \] The relevant test-statistic is the F-statistic:
\[ \begin{split} F = \frac{MS_{Model}}{MS_{Residual}} = \frac{SS_{Model} / 1}{SS_{Residual} / (n-2)} \end{split} \]
which compares the amount of variation in the response explained by the model to the amount of variation left unexplained in the residuals.
The sample F-statistic is compared to an F-distribution with \(df_{1} = 1\) and \(df_{2} = n - 2\) degrees of freedom.1
Look at the output of summary(mdl). Identify the relevant information to conduct an F-test against the null hypothesis that the model is ineffective at predicting income using education level.
Take a breather
As we are about to move on to multiple regression, why not go and make a cup of tea/coffee and go for a walk, listen to some music. Anything but thinking about statistics for at least 20 minutes!

Exercises: Multiple Regression
In this next block of exercises, we move from the simple linear regression model (one outcome variable, one explanatory variable) to the multiple regression model (one outcome variable, multiple explanatory variables).
Everything we just learned about simple linear regression can be extended (with minor modification) to the multiple regression model. The key conceptual difference is that for simple linear regression we think of the distribution of errors at some fixed value of the explanatory variable, and for multiple linear regression, we think about the distribution of errors at fixed set of values for all our explanatory variables.
~ Numeric + Numeric
Research question
Reseachers are interested in the relationship between psychological wellbeing and time spent outdoors.
The researchers know that other aspects of peoples’ lifestyles such as how much social interaction they have can influence their mental well-being. They would like to study whether there is a relationship between well-being and time spent outdoors after taking into account the relationship between well-being and social interactions.
Create a new section heading in your RMarkdown document for the multiple regression exercises.
Import the wellbeing data into R. Assign them to a object called mwdata.
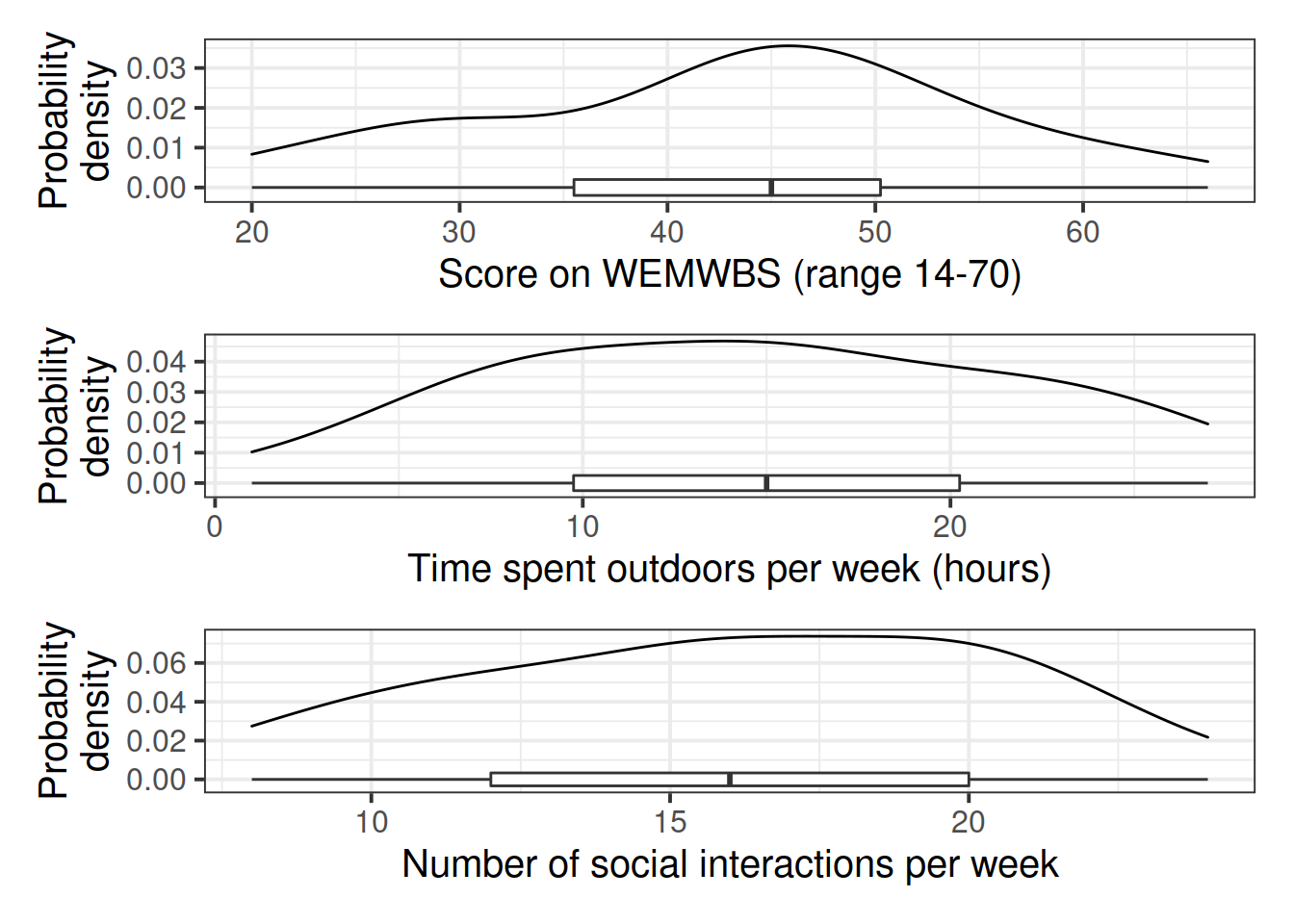
Produce plots of the marginal distributions (the distributions of each variable in the analysis without reference to the other variables) of the wellbeing, outdoor_time, and social_int variables.
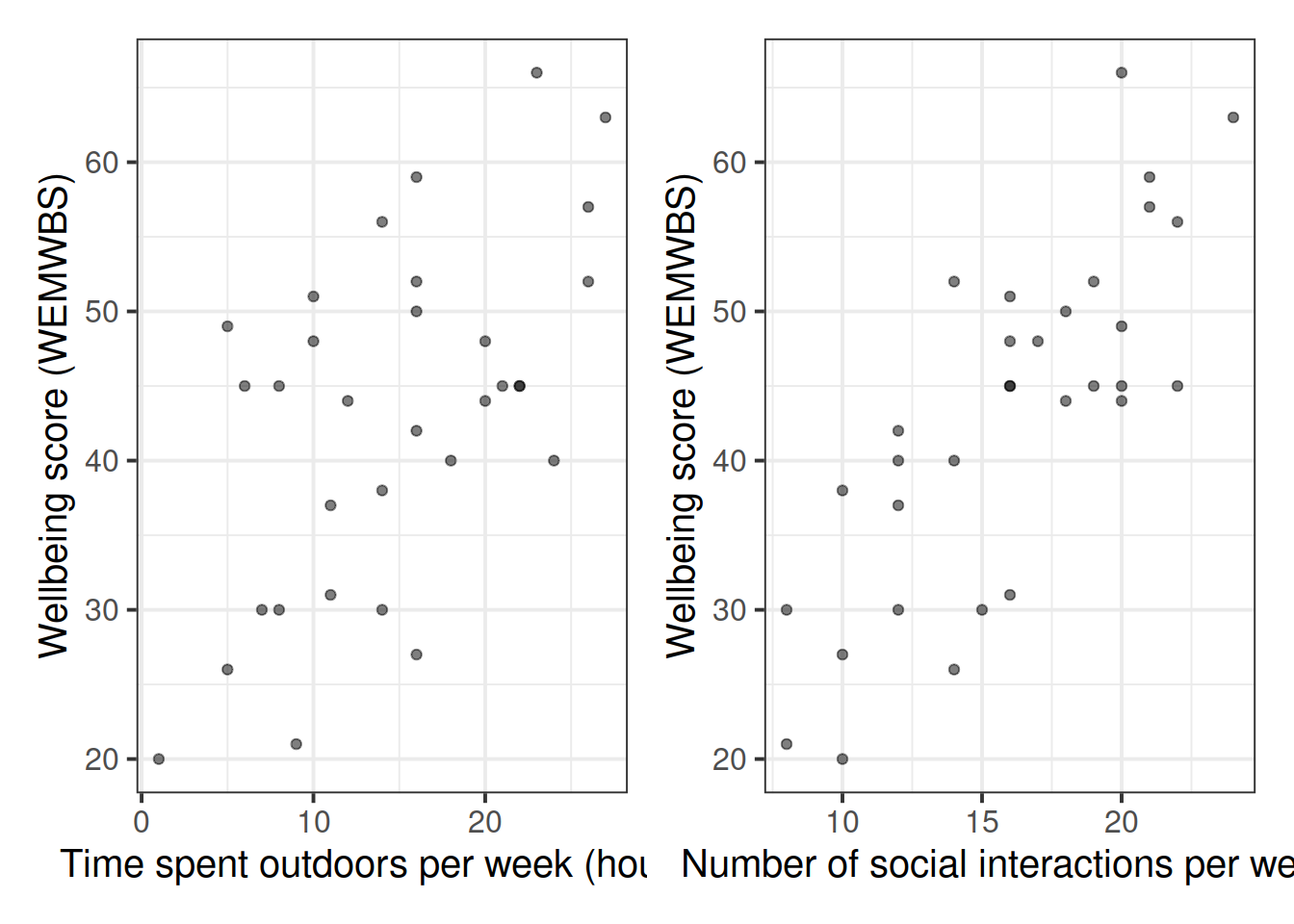
Produce plots of the marginal relationships between the outcome variable (wellbeing) and each of the explanatory variables.
Produce a correlation matrix of the variables which are to be used in the analysis, and write a short paragraph describing the relationships.
Correlation matrix
A table showing the correlation coefficients - \(r_{(x,y)}=\frac{\mathrm{cov}(x,y)}{s_xs_y}\) - between variables. Each cell in the table shows the relationship between two variables. The diagonals show the correlation of a variable with itself (and are therefore always equal to 1).
Hint: We can create a correlation matrix easily by giving the cor() function a dataframe. However, we only want to give it 3 columns here. Think about how we select specific columns, either using select(), or giving the column numbers inside [].
Model formula
For multiple linear regression, the model formula is an extension of the one predictor (“simple”) regression model, to include any number of predictors:
\[
y = \beta_0 \ + \ \beta_1 x_1 \ + \ \beta_2 x_2 \ + \ ... \ + \beta_k x_k \ + \ \epsilon \\
\quad \\
\text{where} \quad \epsilon \sim N(0, \sigma) \text{ independently}
\]
In the model specified above,
- \(\mu_{y|x_1, x_2, ..., x_k} = \beta_0 + \beta_1 x + \beta_2 x_2 + ... \beta_k x_k\) represents the systematic part of the model giving the mean of \(y\) at each combination of values of variables \(x_1\)-\(x_k\);
- \(\epsilon\) represents the error (deviation) from that mean, and the errors are independent from one another.
Visual
Note that for simple linear regression we talked about our model as a line in 2 dimensions: the systematic part \(\beta_0 + \beta_1 x\) defined a line for \(\mu_y\) across the possible values of \(x\), with \(\epsilon\) as the random deviations from that line. But in multiple regression we have more than two variables making up our model.
In this particular case of three variables (one outcome + two explanatory), we can think of our model as a regression surface (See Figure 8). The systematic part of our model defines the surface across a range of possible values of both \(x_1\) and \(x_2\). Deviations from the surface are determined by the random error component, \(\hat \epsilon\).
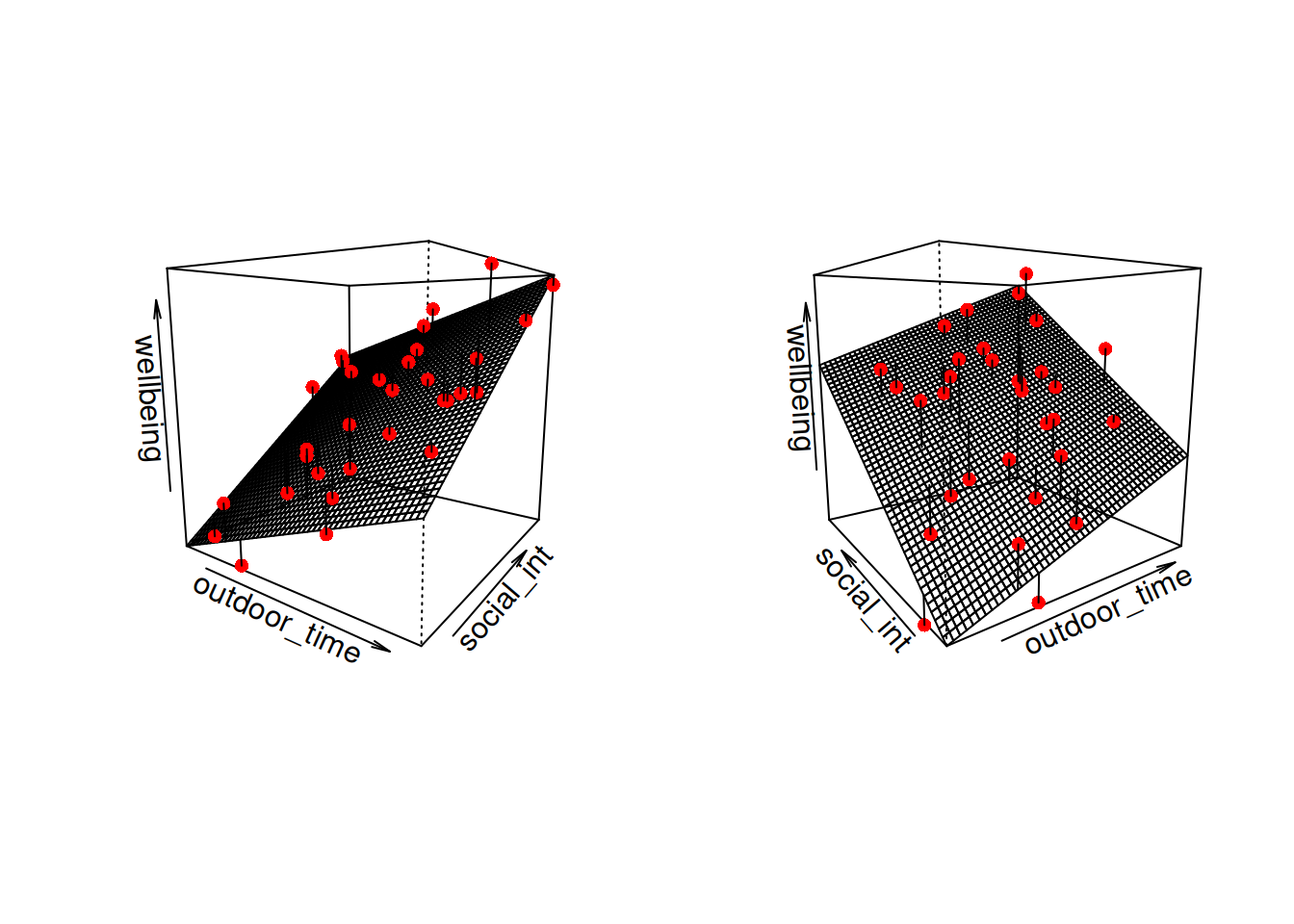
Figure 8: Regression surface for wellbeing ~ outdoor_time + social_int, from two different angles
Don’t worry about trying to figure out how to visualise it if we had any more explanatory variables! We can only concieve of 3 spatial dimensions. One could imagine this surface changing over time, which would bring in a 4th dimension, but beyond that, it’s not worth trying!.
The scatterplots we created in an earlier exercise show moderate, positive, and linear relationships both between outdoor time and wellbeing, and between numbers of social interactions and wellbeing.
In R, using lm(), fit the linear model specified by the formula below, assigning the output to an object called wb_mdl1.
\[ Wellbeing = \beta_0 \ + \ \beta_1 \cdot Outdoor Time \ + \ \beta_2 \cdot Social Interactions \ + \ \epsilon \]
Tip:
As we did for simple linear regression, we can fit our multiple regression model using the lm() function. We can add as many explanatory variables as we like, separating them with a +.
lm( <response variable> ~ 1 + <explanatory variable 1> + <explanatory variable 2> + ... , data = <dataframe>)
Interpretation of Muliple Regression Coefficients
The parameters of a multiple regression model are:
- \(\beta_0\) (The intercept);
- \(\beta_1\) (The slope across values of \(x_1\));
- …
- …
- \(\beta_k\) (The slope across values of \(x_k\));
- \(\sigma\) (The standard deviation of the errors).
You’ll hear a lot of different ways that people explain multiple regression coefficients.
For the model \(y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \epsilon\), the estimate \(\hat \beta_1\) will often be reported as:
the increase in \(y\) for a one unit increase in \(x_1\) when…
- holding the effect of \(x_2\) constant.
- controlling for differences in \(x_2\).
- partialling out the effects of \(x_2\).
- holding \(x_2\) equal.
- accounting for effects of \(x_2\).
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 5.3703775 4.3205141 1.242995 2.238259e-01
## outdoor_time 0.5923673 0.1689445 3.506284 1.499467e-03
## social_int 1.8034489 0.2690982 6.701825 2.369845e-07The coefficient 0.59 of weekly outdoor time for predicting wellbeing score says that among those with the same number of social interactions per week, those who have one additional hour of outdoor time tend to, on average, score 0.59 higher on the WEMWBS wellbeing scale. The multiple regression coefficient measures that average conditional relationship.
Just like the simple linear regression, when we estimate parameters from the available data, we have:
- A fitted model (recall that the h\(\hat{\textrm{a}}\)ts are used to distinguish our estimates from the true unknown parameters): \[ \widehat{Wellbeing} = \hat \beta_0 + \hat \beta_1 \cdot Outdoor Time + \hat \beta_2 \cdot Social Interactions \]
- And we have the residuals \(\hat \epsilon = y - \hat y\) which are the deviations from the observed values and our model-predicted responses.
- Extract and interpret the parameter estimates (the “coefficients”) from your model.
(summary(),coef(),$coefficientsetc will be useful here)
- Within what distance from the model predicted values (the regression surface) would we expect 95% of WEMWBS wellbeing scores to be?
(Either
sigma()or part of the output fromsummary()will help you for this)
Obtain 95% confidence intervals for the regression coefficients, and write a sentence describing each.
Pause

Before we go too far
So far, we have been fitting and interpreting our regression models. In each case, we first specified the model, then visually explored the marginal distributions and relationships of variables which would be used in the analysis. Then, once we fitted the model, we began to examine the fit by studying what the various parameter estimates represented, and the spread of the residuals. We saw these in the output of summary() of a model - they were shown in the parts of the output inside the red boxes in Figure 9).
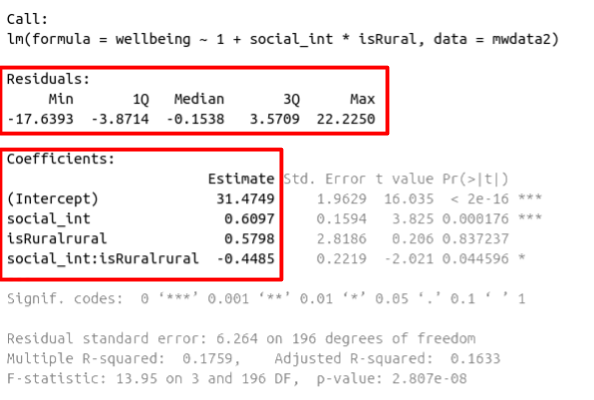
Figure 9: Multiple regression output in R, summary.lm(). Residuals and Coefficients highlighted
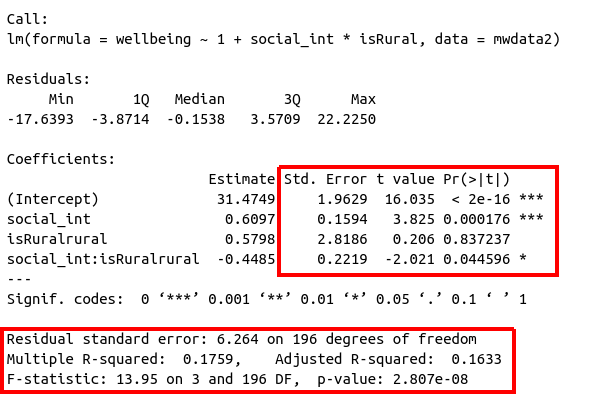
Figure 10: Multiple regression output in R, summary.lm(). Hypothesis tests highlighted
Choose > Fit > Assess > Use
IMPORTANT!
It may help to think of the sequence of steps involved in statistical modeling as:
\[
\text{Choose} \rightarrow \text{Fit} \rightarrow \text{Assess} \rightarrow \text{Use}
\]
- We explore/visualise our data and Choose our model specification.
- Then we Fit the model in R.
- Next, we Assess the fit, to ensure that it meets all the underlying assumptions?
- Finally, we Use our model to draw statistical inferences about the world, or to make predictions.
The LINE Mnemonic
The assumptions of the linear model can be committed to memory using the LINE mnemonic:
- Linearity: The relationship between \(y\) and \(x\) is linear.
- Independence of errors: The error terms should be independent from one another.
- Normality: The errors \(\epsilon\) are normally distributed
- Equal variances (“Homoscedasticity”): The scale of the variability of the errors \(\epsilon\) is constant at all values of \(x\).
When we fit a model, we evaluate many of these assumptions by looking at the residuals
(the deviations from the observed values \(y_i\) and the model estimated value \(\hat y_i\)).
The residuals, \(\hat \epsilon\) are our estimates of the actual unknown true error term \(\epsilon\). These assumptions hold both for a regression model with a single predictor and for one with multiple predictors.
Exercises: Assumptions & Diagnostics
Create a new section heading for “Assumptions”.
Recall our the form of our model which we fitted and stored as wb_mdl1:
\[ \text{Wellbeing} = \beta_0 + \beta_1 \cdot \text{Outdoor Time} + \beta_2 \cdot \text{Social Interactions} + \epsilon \]
Wich we fitted in R using:
wb_mdl1 <- lm(wellbeing ~ outdoor_time + social_int, data = mwdata)Note: We have have forgone writing the 1 in lm(y ~ 1 + x.... The 1 just tells R that we want to estimate the Intercept, and it will do this by default even if we leave it out.
Linearity
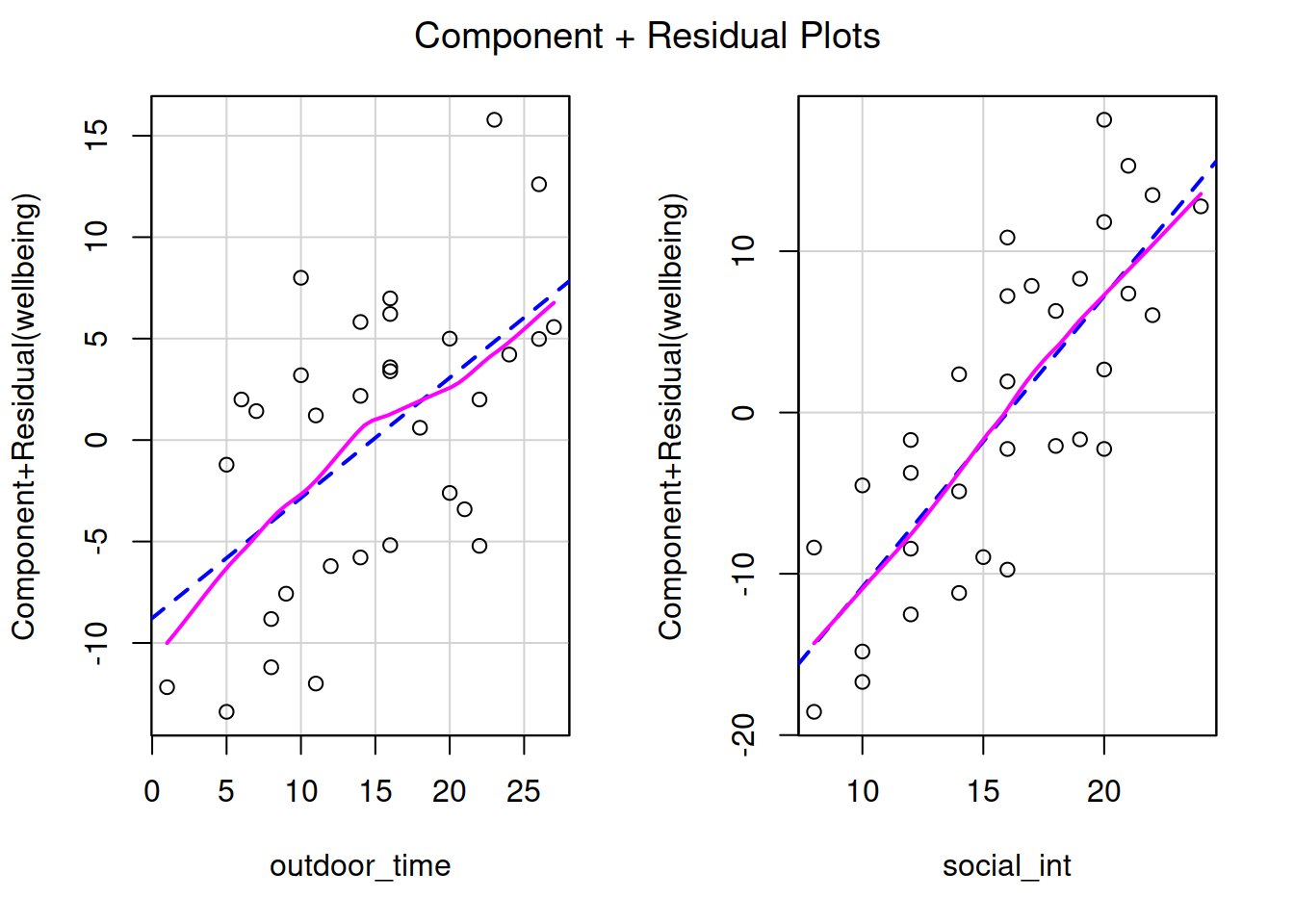
In simple linear regression with only one explanatory variable, we can assess linearity through a simple scatterplot of the outcome variable against the explanatory. In multiple regression, however, it becomes more necessary to rely on diagnostic plots of the model residuals. This is because we need to know whether the relations are linear between the outcome and each predictor after accounting for the other predictors in the model.
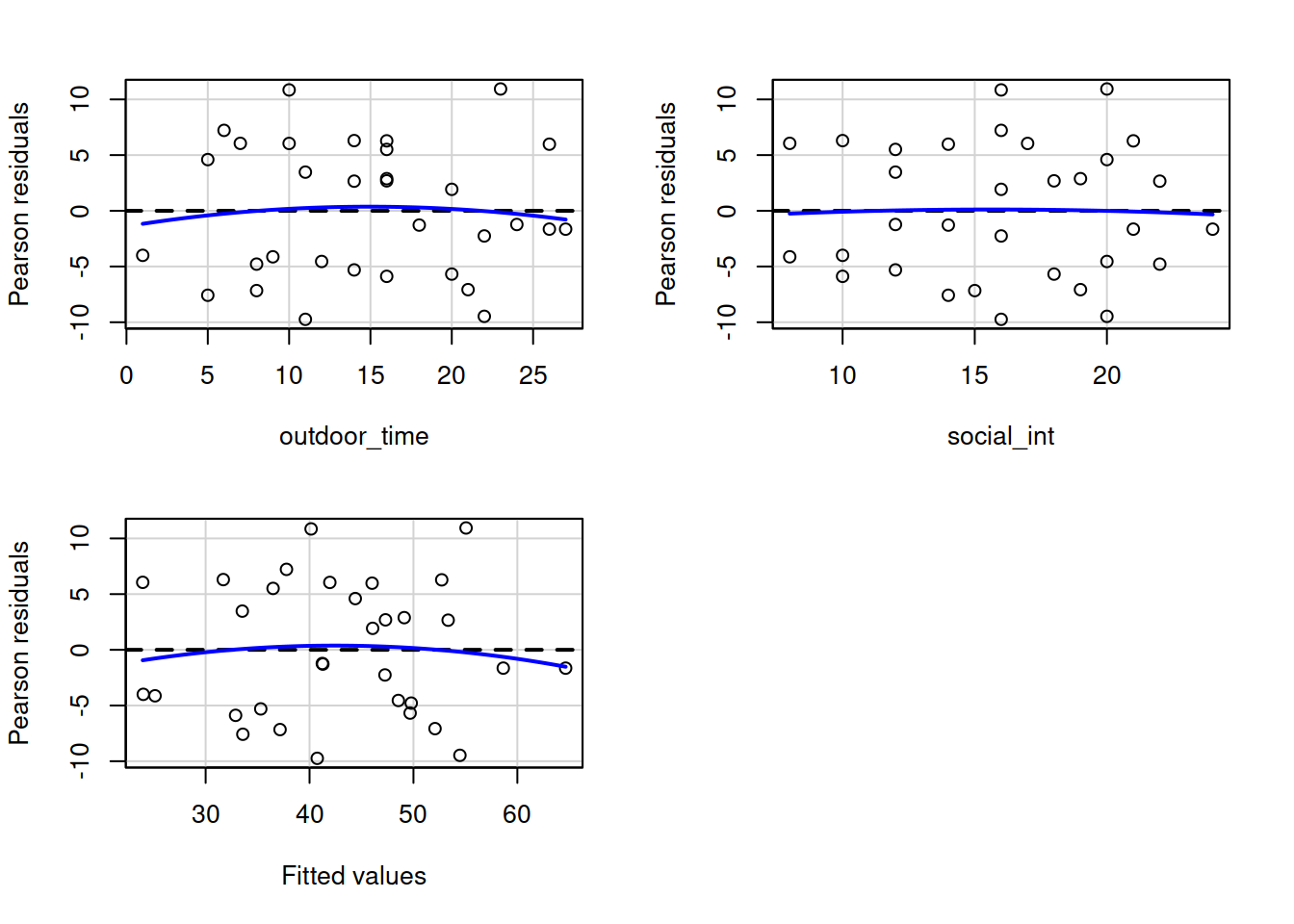
In order to assess this, we use partial-residual plots (also known as ‘component-residual plots’). This is a plot with each explanatory variable \(x_j\) on the x-axis, and partial residuals on the y-axis.
Partial residuals for a predictor \(x_j\) are calculated as: \[ \hat \epsilon + \hat \beta_j x_j \]
In R we can easily create these plots for all predictors in the model by using the crPlots() function from the car package.
Create partial-residual plots for the wb_mdl1 model.
Remember to load the car package first. If it does not load correctly, it might mean that you have need to install it.
Write a sentence summarising whether or not you consider the assumption to have been met. Justify your answer with reference to the plots.
Equal variances (Homoscedasticity)
The equal variances assumption is that the error variance \(\sigma^2\) is constant across values of the predictors \(x_1\), … \(x_k\), and across values of the fitted values \(\hat y\). This sometimes gets termed “Constant” vs “Non-constant” variance. Figures 11 & 12 shows what these look like visually.
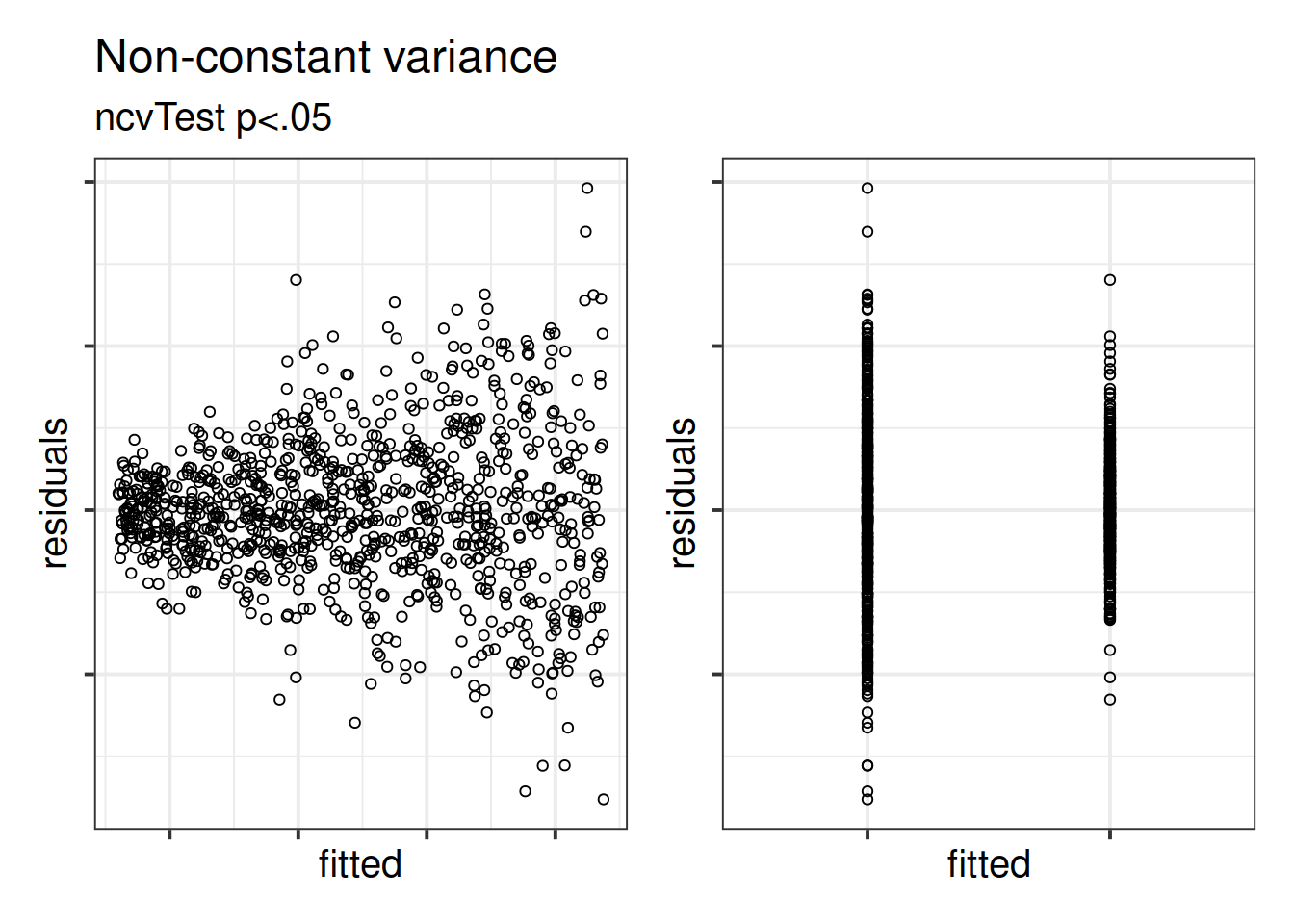
Figure 11: Non-constant variance for numeric and categorical x
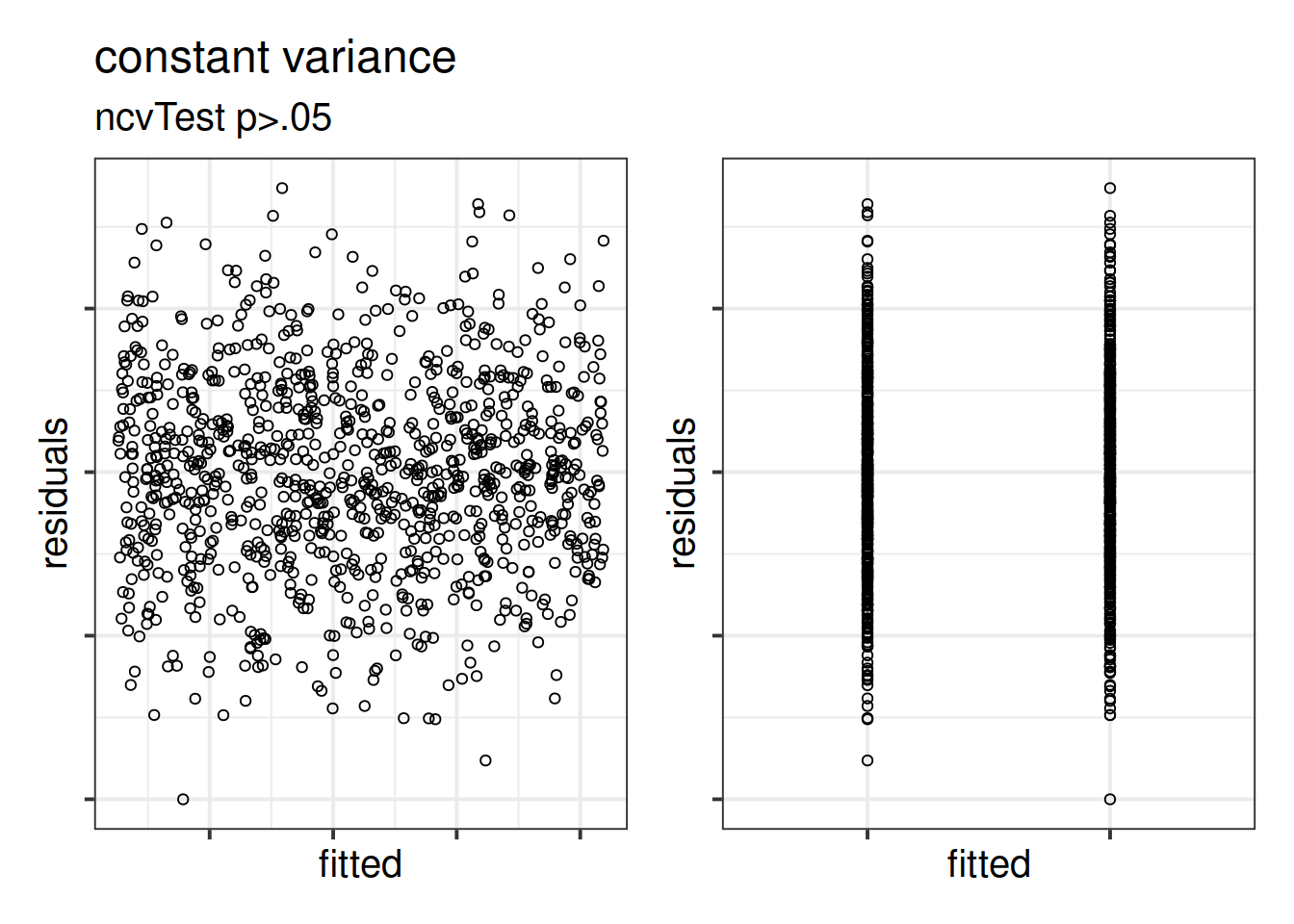
Figure 12: Constant variance for numeric and categorical x
In R we can create plots of the Pearson residuals against the predicted values \(\hat y\) and against the predictors \(x_1\), … \(x_k\) by using the residualPlots() function from the car package. This function also provides the results of a lack-of-fit test for each of these relationships (note when it is the fitted values \(\hat y\) it gets called “Tukey’s test”).
ncvTest(model) (also from the car package) performs a test against the alternative hypothesis that the error variance changes with the level of the fitted value (also known as the “Breusch-Pagan test”). \(p >.05\) indicates that we do not have evidence that the assumption has been violated.
Use residualPlots() to plot residuals against each predictor, and use ncvTest() to perform a test against the alternative hypothesis that the error variance changes with the level of the fitted value.
Write a sentence summarising whether or not you consider the assumption to have been met. Justify your answer with reference to plots and/or formal tests where available.
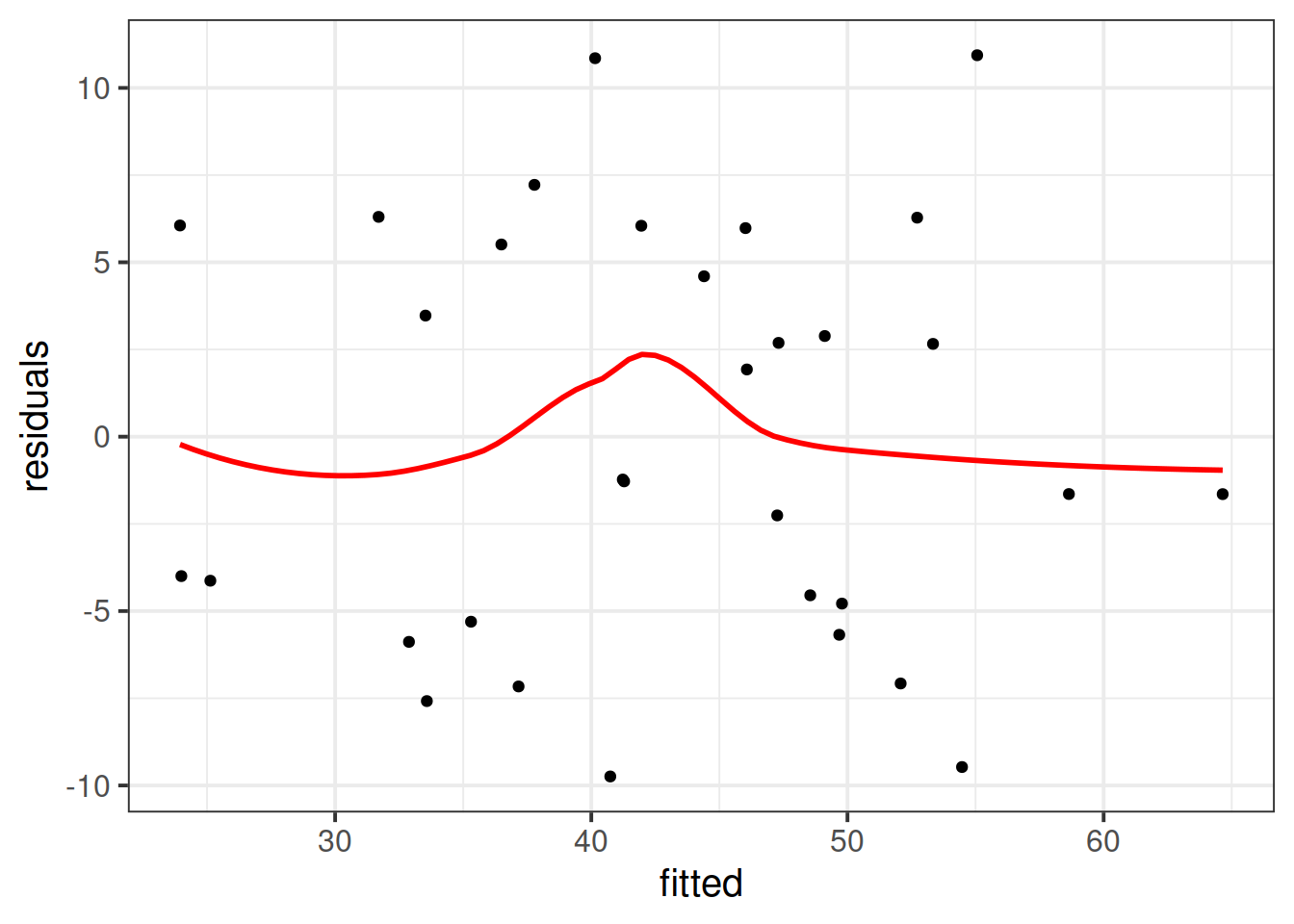
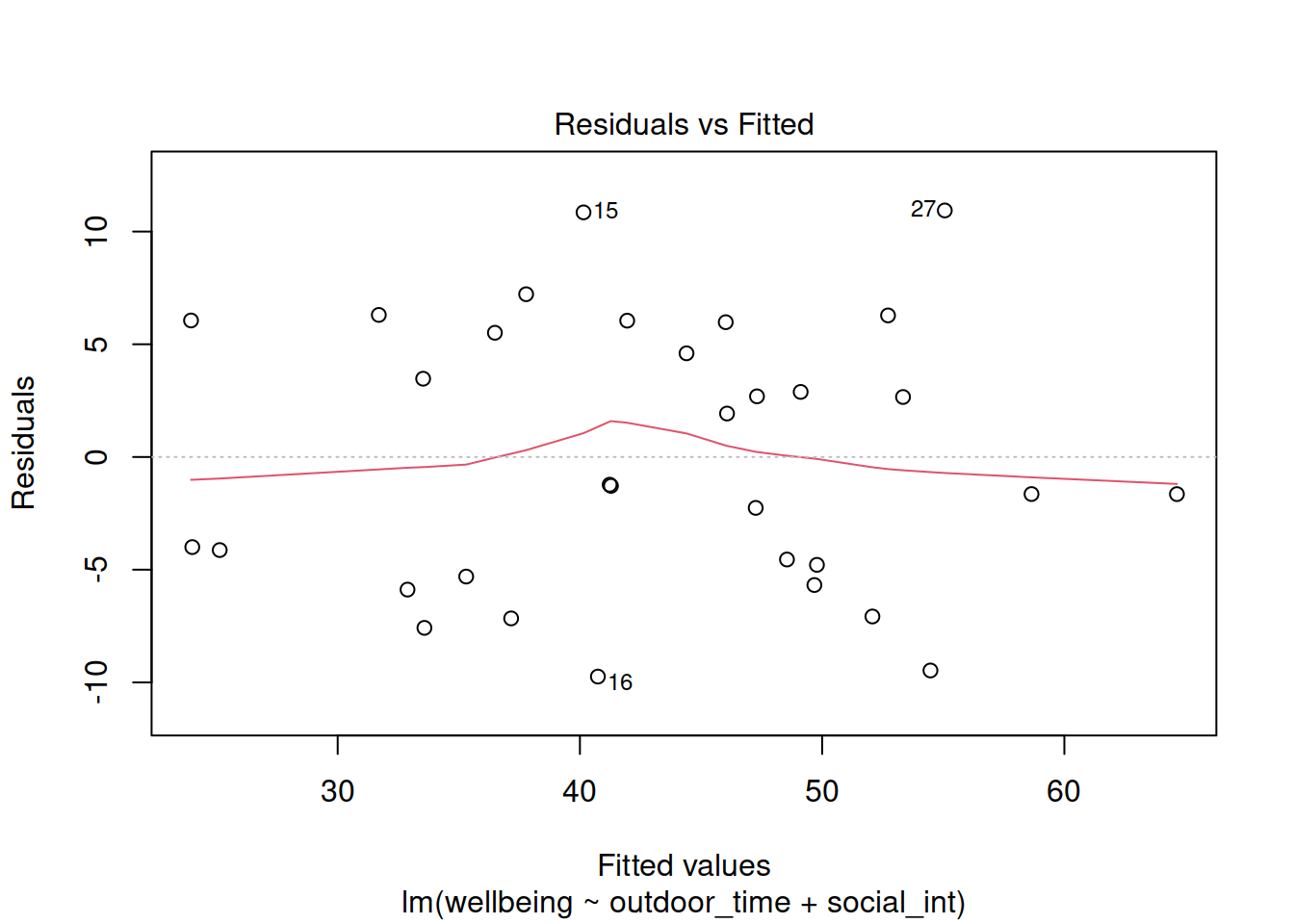
Create the “residuals vs. fitted plot” - a scatterplot with the residuals \(\hat \epsilon\) on the y-axis and the fitted values \(\hat y\) on the x-axis.
You can either do this:
- manually, using the functions
residuals()andfitted(), or - quickly by giving the
plot()function your model. This will actually give you lots of plots, so we can specify which plot we want to return - e.g.,plot(wb_mdl1, which = 1)
You can use this plot to visually assess:
- Linearity: Does the average of the residuals \(\hat \epsilon\) remain close to 0 across the plot?
- Equal Variance: does the spread of the residuals \(\hat \epsilon\) remain constant across the predicted values \(\hat y\)?
Independence
The “independence of errors” assumption is the condition that the errors do not have some underlying relationship which is causing them to influence one another.
There are many sources of possible dependence, and often these are issues of study design. For example, we may have groups of observations in our data which we would expect to be related (e.g., multiple trials from the same participant). Our modelling strategy would need to take this into account.
One form of dependence is autocorrelation - this is when observations influence those adjacent to them. It is common in data for which time is a variable of interest (e.g, the humidity today is dependent upon the rainfall yesterday).
In R we can test against the alternative hypothesis that there is autocorrelation in our errors using the durbinWatsonTest() (an abbreviated function dwt() is also available) in the car package.
Perform a test against the alternative hypothesis that there is autocorrelation in the error terms.
Write a sentence summarising whether or not you consider the assumption of independence to have been met (you may have to assume certain aspects of the study design).
Normality of errors
The normality assumption is the condition that the errors \(\epsilon\) are normally distributed.
We can visually assess this condition through histograms, density plots, and quantile-quantile plots (QQplots) of our residuals \(\hat \epsilon\).
We can also perform a Shapiro-Wilk test against the alternative hypothesis that the residuals were not sampled from a normally distributed population. The shapiro.test() function in R.
Assess the normality assumption by producing a qqplot of the residuals (either manually or using plot(model, which = ???)), and conducting a Shapiro-Wilk test.
Write a sentence summarising whether or not you consider the assumption to have been met. Justify your answer with reference to plots and/or formal tests where available.
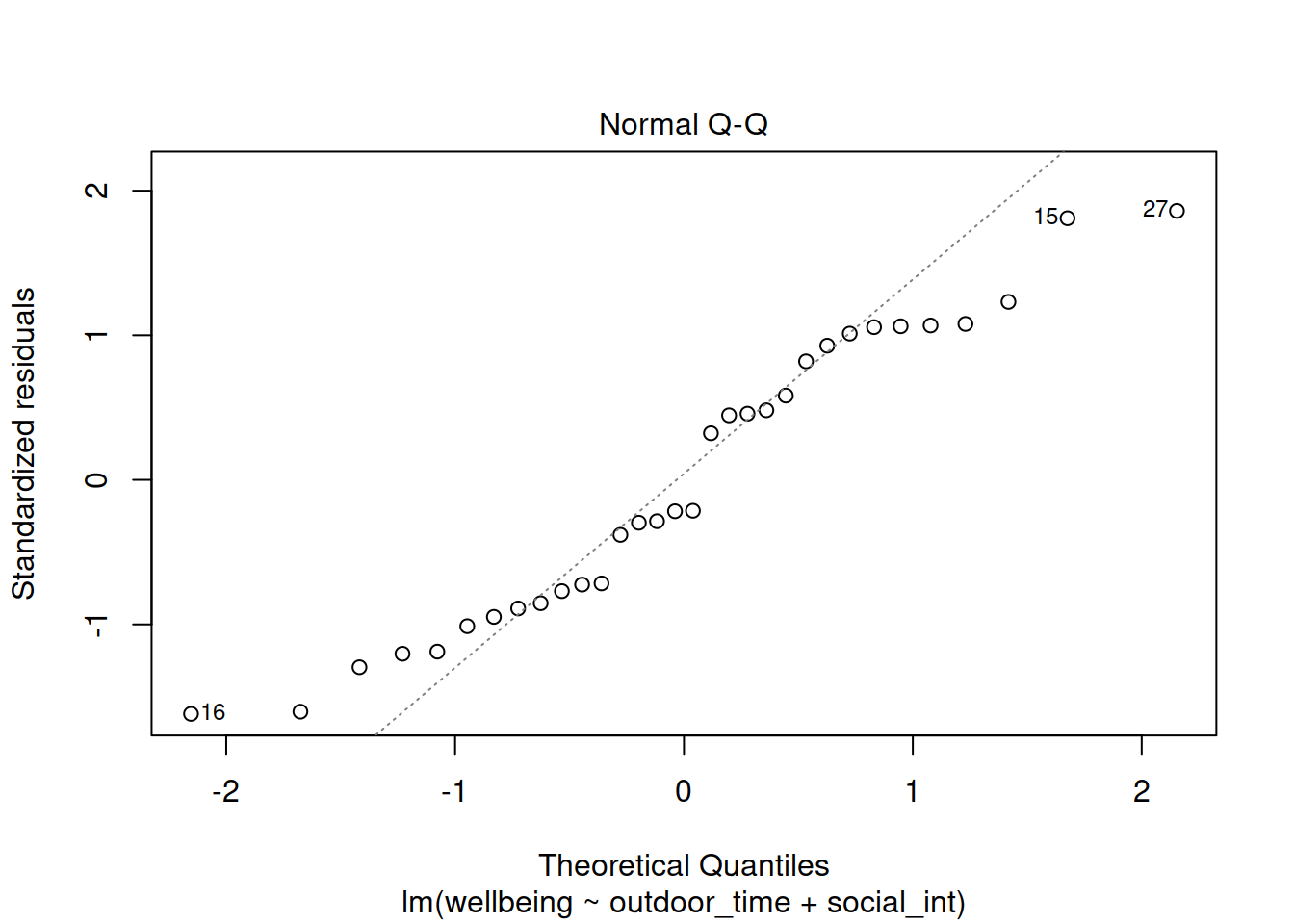 Or we can make our own:
Or we can make our own: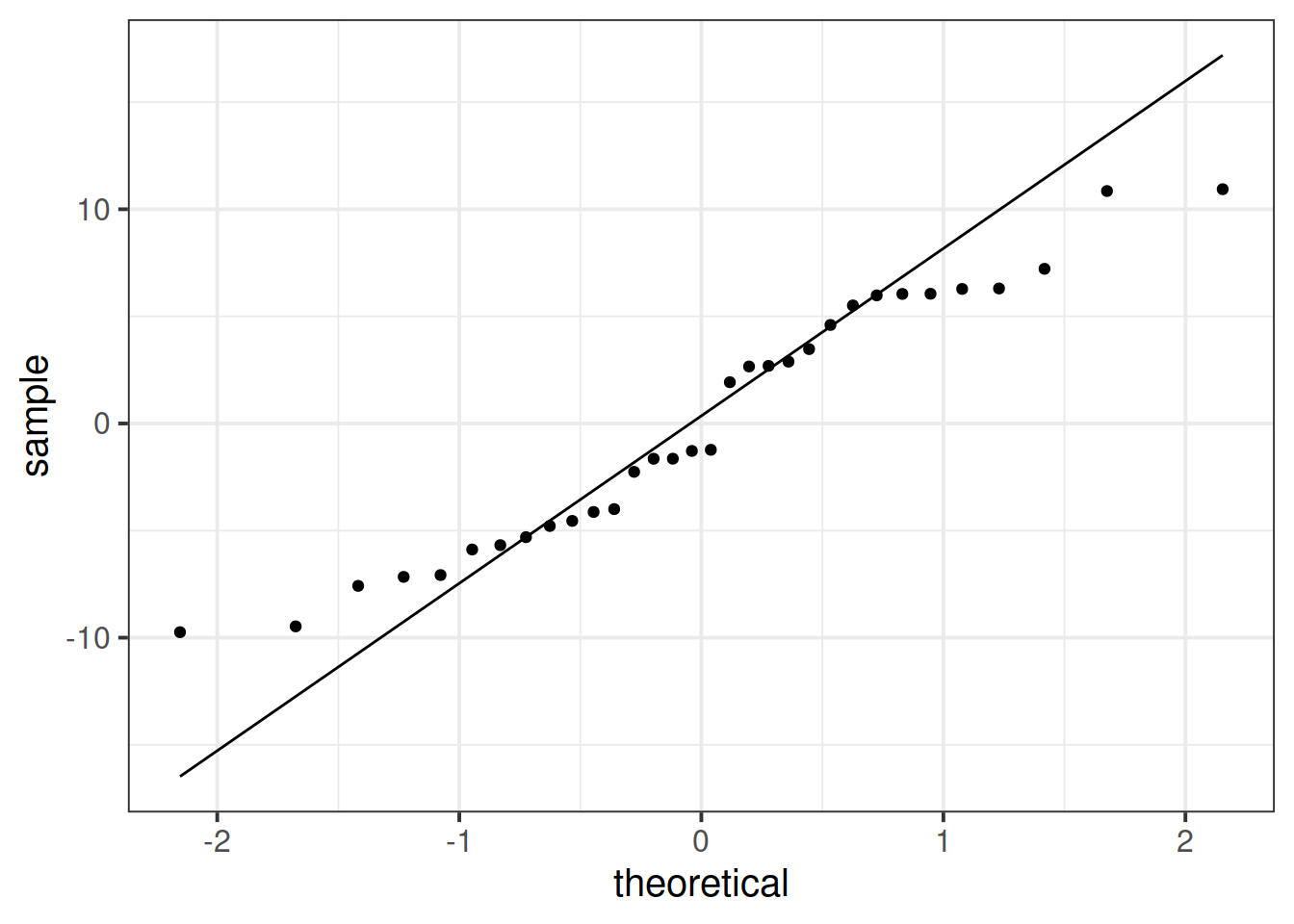
Multicollinearity
Recall our interpretation of multiple regression coefficients as
This interpretation falls down if predictors are highly correlated because if, e.g., predictors \(x_1\) and \(x_2\) are highly correlated, then changing the value of \(x_1\) necessarily entails a change the value of \(x_2\) meaning that it no longer makes sense to talk about holding \(x_2\) constant.
We can assess multicollinearity using the variance inflation factor (VIF), which for a given predictor \(x_j\) is calculated as:
\[
VIF_j = \frac{1}{1-R_j^2} \\
\]
Where \(R_j^2\) is the coefficient of determination (the R-squared) resulting from a regression of \(x_j\) on to all the other predictors in the model (\(x_j = x_1 + ... x_k + \epsilon\)).
The more highly correlated \(x_j\) is with other predictors, the bigger \(R_j^2\) becomes, and thus the bigger \(VIF_j\) becomes.
The square root of VIF indicates how much the SE of the coefficient has been inflated due to multicollinearity. For example, if the VIF of a predictor variable were 4.6 (\(\sqrt{4.6} = 2.1\)), then the standard error of the coefficient of that predictor is 2.1 times larger than if the predictor had zero correlation with the other predictor variables. Suggested cut-offs for VIF are varied. Some suggest 10, others 5. Define what you will consider an acceptable value prior to calculating it.
In R, the vif() function from the car package will provide VIF values for each predictor in your model.
Calculate the variance inflation factor (VIF) for the predictors in the model.
Write a sentence summarising whether or not you consider multicollinearity to be a problem here.
Individual cases
We have seen in the case of the simple linear regression that individual cases in our data can influence our model more than others. We know about:
- Regression outliers: A large residual \(\hat \epsilon_i\) - i.e., a big discrepancy between their predicted y-value and their observed y-value.
- Standardised residuals: For residual \(\hat \epsilon_i\), divide by the estimate of the standard deviation of the residuals. In R, the
rstandard()function will give you these - Studentised residuals: For residual \(\hat \epsilon_i\), divide by the estimate of the standard deviation of the residuals excluding case \(i\). In R, the
rstudent()function will give you these. Values \(>|2|\) (greater in magnitude than two) are considered potential outliers.
- Standardised residuals: For residual \(\hat \epsilon_i\), divide by the estimate of the standard deviation of the residuals. In R, the
- High leverage cases: These are cases which have considerable potential to influence the regression model (e.g., cases with an unusual combination of predictor values).
- Hat values: are used to assess leverage. In R, The
hatvalues()function will retrieve these.
Hat values of more than \(2 \bar{h}\) (2 times the average hat value) are considered high leverage. \(\bar{h}\) is calculated as \(\frac{k + 1}{n}\), where \(k\) is the number of predictors, and \(n\) is the sample size.
- Hat values: are used to assess leverage. In R, The
- High influence cases: When a case has high leverage and is an outlier, it will have a large influence on the regression model.
- Cook’s Distance: combines leverage (hatvalues) with outlying-ness to capture influence. In R, the
cooks.distance()function will provide these.
A suggested Cook’s Distance cut-off is \(\frac{4}{n-k-1}\), where \(k\) is the number of predictors, and \(n\) is the sample size.
- Cook’s Distance: combines leverage (hatvalues) with outlying-ness to capture influence. In R, the
Create a new tibble which contains:
- The original variables from the model (Hint, what does
wb_mdl1$modelgive you?) - The fitted values from the model \(\hat y\)
- The residuals \(\hat epsilon\)
- The studentised residuals
- The hat values
- The Cook’s Distance values.
Looking at the studentised residuals, are there any outliers?
Looking at the hat values, are there any observations with high leverage?
Looking at the Cook’s Distance values, are there any highly influential points?
(You can also display these graphically using plot(model, which = 4) and plot(model, which = 5)).
Other influence.measures()
Alongside Cook’s Distance, we can examine the extent to which model estimates and predictions are affected when an entire case is dropped from the dataset and the model is refitted.
- DFFit: the change in the predicted value at the \(i^{th}\) observation with and without the \(i^{th}\) observation is included in the regression.
- DFbeta: the change in a specific coefficient with and without the \(i^{th}\) observation is included in the regression.
- DFbetas: the change in a specific coefficient divided by the standard error, with and without the \(i^{th}\) observation is included in the regression.
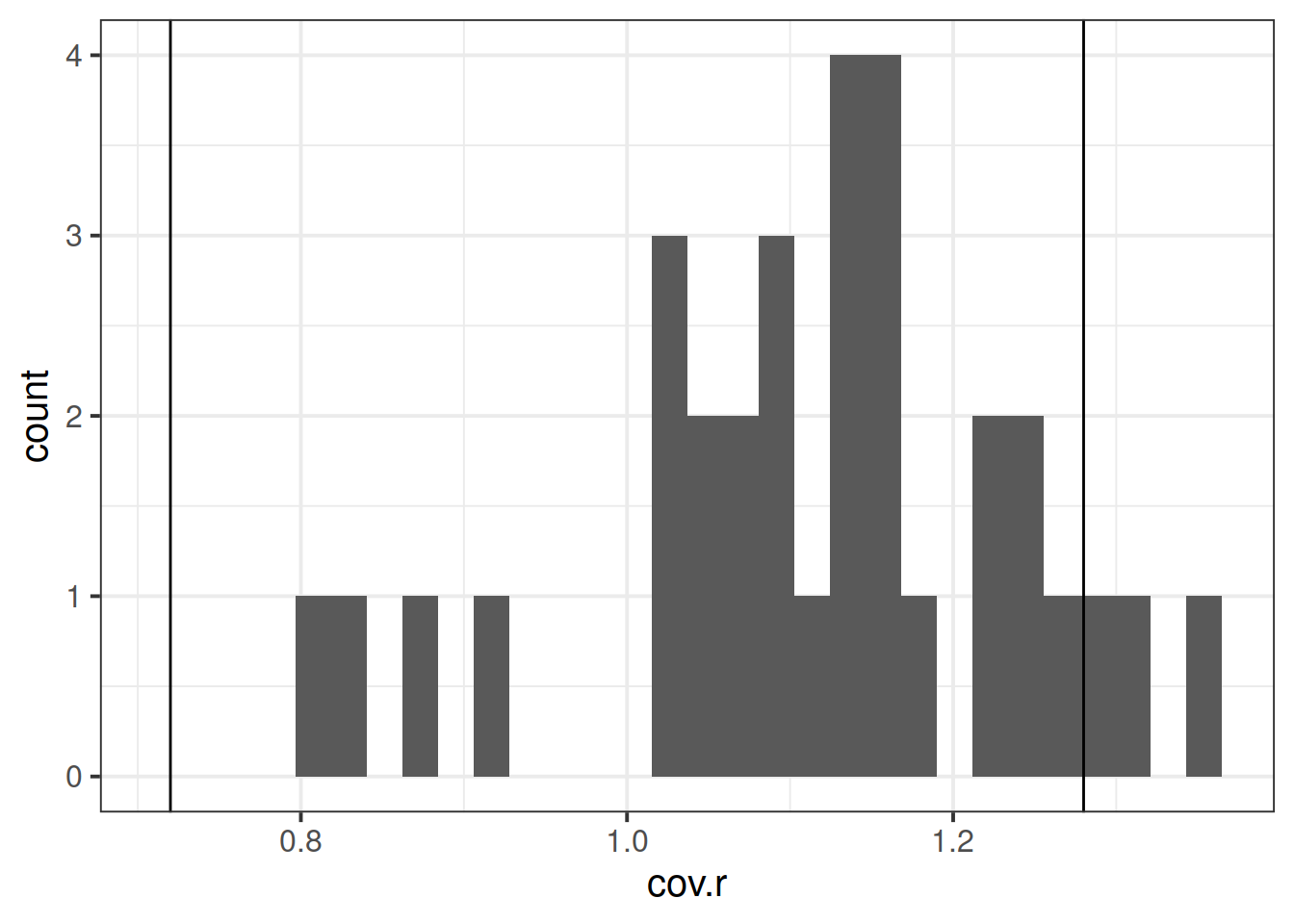
- COVRATIO: measures the effect of an observation on the covariance matrix of the parameter estimates. In simpler terms, it captures an observation’s influence on standard errors. Values which are \(>1+\frac{3(k+1)}{n}\) or \(<1-\frac{3(k+1)}{n}\) are considered as having strong influence.
Use the function influence.measures() to extract these delete-1 measures of influence.
Try plotting the distributions of some of these measures.
Tip: the function influence.measures() returns an infl-type object. To plot this, we need to find a way to extract the actual numbers from it.
What do you think names(influence.measures(wb_mdl1)) shows you? How can we use influence.measures(wb_mdl1)$<insert name here> to extract the matrix of numbers?
Lewis-Beck, Colin, and Michael Lewis-Beck. 2015. Applied Regression: An Introduction. Vol. 22. Sage publications.
\(SS_{Total}\) has \(n - 1\) degrees of freedom as one degree of freedom is lost in estimating the population mean with the sample mean \(\bar{y}\). \(SS_{Residual}\) has \(n - 2\) degrees of freedom. There are \(n\) residuals, but two degrees of freedom are lost in estimating the intercept and slope of the line used to obtain the \(\hat y_i\)s. Hence, by difference, \(SS_{Model}\) has \(n - 1 - (n - 2) = 1\) degree of freedom.↩︎

This workbook was written by Josiah King, Umberto Noe, and Martin Corley, and is licensed under a Creative Commons Attribution 4.0 International License.