| item | direction | dimension | question |
|---|---|---|---|
| 1 | + | Executive | I need a bit of encouragement to get things started |
| 2 | - | Initiation | I contact my friends |
| 3 | - | Emotional | I express my emotions |
| 4 | - | Initiation | I think of new things to do during the day |
| 5 | - | Emotional | I am concerned about how my family feel |
| 6 | + | Executive | I find myself staring in to space |
| 7 | - | Emotional | Before I do something I think about how others would feel about it |
| 8 | - | Initiation | I plan my days activities in advance |
| 9 | - | Emotional | When I receive bad news I feel bad about it |
| 10 | - | Executive | I am unable to focus on a task until it is finished |
| 11 | + | Executive | I lack motivation |
| 12 | + | Emotional | I struggle to empathise with other people |
| 13 | - | Initiation | I set goals for myself |
| 14 | - | Initiation | I try new things |
| 15 | + | Emotional | I am unconcerned about how others feel about my behaviour |
| 16 | - | Initiation | I act on things I have thought about during the day |
| 17 | + | Executive | When doing a demanding task, I have difficulty working out what I have to do |
| 18 | - | Initiation | I keep myself busy |
| 19 | + | Executive | I get easily confused when doing several things at once |
| 20 | - | Emotional | I become emotional easily when watching something happy or sad on TV |
| 21 | + | Executive | I find it difficult to keep my mind on things |
| 22 | - | Initiation | I am spontaneous |
| 23 | + | Executive | I am easily distracted |
| 24 | + | Emotional | I feel indifferent to what is going on around me |
Week 8 Exercises: CFA
New packages
Make sure you have these packages installed:
- lavaan
- semPlot
Exercises for the Enthusiastic
Dataset: radakovic_das.csv
Apathy is lack of motivation towards goal-directed behaviours. It is pervasive in a majority of psychiatric and neurological diseases, and impacts everyday life. Traditionally, apathy has been measured as a one-dimensional construct but is in fact composed of different types of demotivation.
The Dimensional Apathy Scale (DAS) is a multidimensional assessment for demotivation, in which 3 subtypes of apathy are assessed:
- Executive: lack of motivation for planning, attention or organisation
- Emotional: lack of emotional motivation (indifference, affective or emotional neutrality, flatness or blunting)
- Initiation: lack of motivation for self-generation of thoughts and/or actions
The DAS measures these subtypes of apathy and allows for quick and easy assessment, through self-assessment, observations by informants/carers or administration by researchers or healthcare professionals.
You can find data for the DAS when administered to 250 healthy adults at https://uoepsy.github.io/data/radakovic_das.csv, and information on the items is below.
DAS Dictionary
All items are measured on a 6-point Likert scale of Always (0), Almost Always (1), Often (2), Occasionally (3), Hardly Ever (4), and Never (5). Certain items (indicated in the table below with a - direction) are reverse scored to ensure that higher scores indicate greater levels of apathy.
Here are the item numbers that correspond to each dimension.
- Executive: 1, 6, 10, 11, 17, 19, 21, 23
- Emotional: 3, 5, 7, 9, 12, 15, 20, 24
- Initiation: 2, 4, 8, 13, 14, 16, 18, 22
Question 1
Read in the data. It will need a little bit of tidying before we can get to fitting a CFA.
Remember that most of the actions needed for working with those sort of data are described in the Chapter on Data Wrangling for Questionnaires.
Hints
By the looks of things, this is what I would consider doing:
- Rename the variables to easy-to-read strings like
q1,q2,q3, etc. - Set up a data dictionary that records the text of the item
q1corresponds to, the text thatq2corresponds to, etc. - Recode the Likert scale labels to numbers.
- Reverse-code the questions with a negative direction. Note, you don’t need to this, as they’ll just end up with loadings in the opposite direction, but I would strongly recommend it for interpretation purposes.
- Check if there is missing data and if there is, removing those observations.
Question 2
Specify the theoretical model proposed by Radakovic et al.
For reference, check out the example in the readings.
dasmod <- "
"Challenge: Before you estimate the model, how many degrees of freedom do you think the model will have? (The readings will help here!)
Hints
You’ll have to use the data dictionary to see which items are associated with which dimensions.
Question 3
Estimate the model using cfa().
You can choose whether you want to standardise the latent factors or fix the first loading of each factor to be 1 (it’s the same model, just scaled differently).
Examine the model fit - does it fit well?
What modifications do the modification indices suggest? Are the top three suggestions theoretically reasonable, in your opinion?
Remember, we don’t really want to have to make modifications to our models. If you don’t need to (if the model fits well) then don’t bother! (It’s still worth looking at the modification indices though).
Hints
There’s a whole section on “model fit” in the CFA chapter!
And there’s also a whole section on model modifications.
Question 4
Are the (standardised) loadings all “big enough”?
There’s no clear threshold that people use here - it depends a lot on the field, and on the wordings of specific items. Ideally, the same value we used in EFA (\(\geq|0.3|\)) would be nice, but not crucial.
Hints
To get out standardised loadings, we can do:
mod.est <- cfa(model_syntax, data = ...)
summary(mod.est, std=TRUE)And you’ll get out an extra 2 columns in the summary output.
Pay attention to the Estimate, Std.lv and Std.all columns in your output. The way I think of these columns is just to think of how we scale things in regression models:
Estimatecolumn :item ~ Factor
Std.lvcolumn :item ~ scale(Factor)
Std.allcolumn:scale(item) ~ scale(Factor)
So if, when we fitted the model, we had specified cfa(model, data, std.lv = TRUE), then the factor already has a variance of 1, so Scale(Factor) doesn’t do anything.
Question 5
Do the factors correlate in the way you would expect?
Is more emotional apathy associated with more executive apathy? and with more initiation apathy?
Hints
If you didn’t reverse code the appropriate items, then this might get confusing, because we’d have to look at factor loadings to know in which direction the factor is going (i.e., are higher numbers “more apathy” or “less apathy”?).
If you did reverse code the appropriate items, then you’re golden, because you made them all point towards “more” apathy.
Question 6
Make a diagram of the model.
Hints
For a quick look at the structure of the model, try the semPaths() function from the semPlot package Chapter 4 CFA#making diagrams.
If you were going to use this sort of diagram in a proper write-up, though, it’d be better to make a nicer graphic manually (e.g., in Powerpoint, your favourite graphics software, or semdiag).
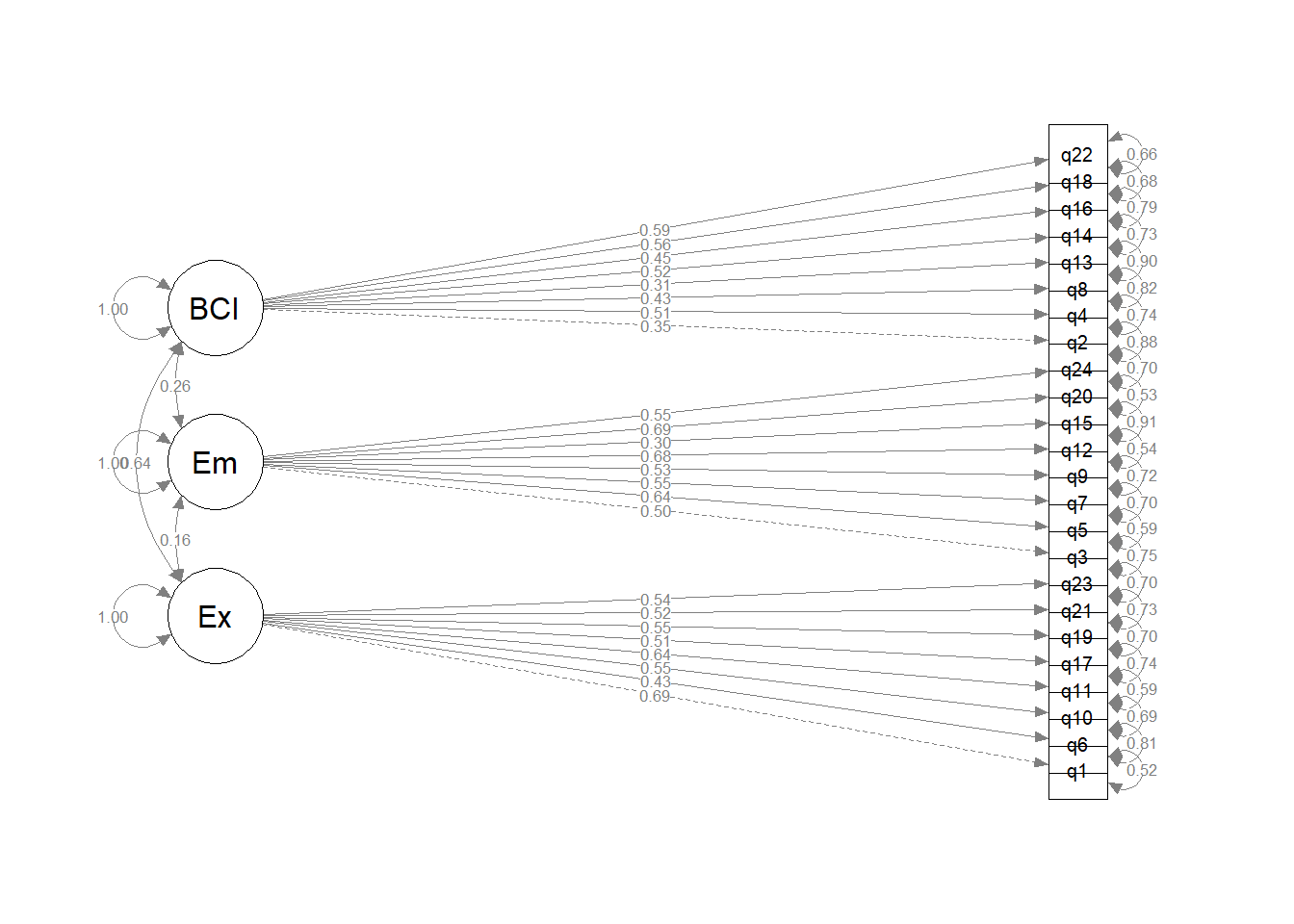
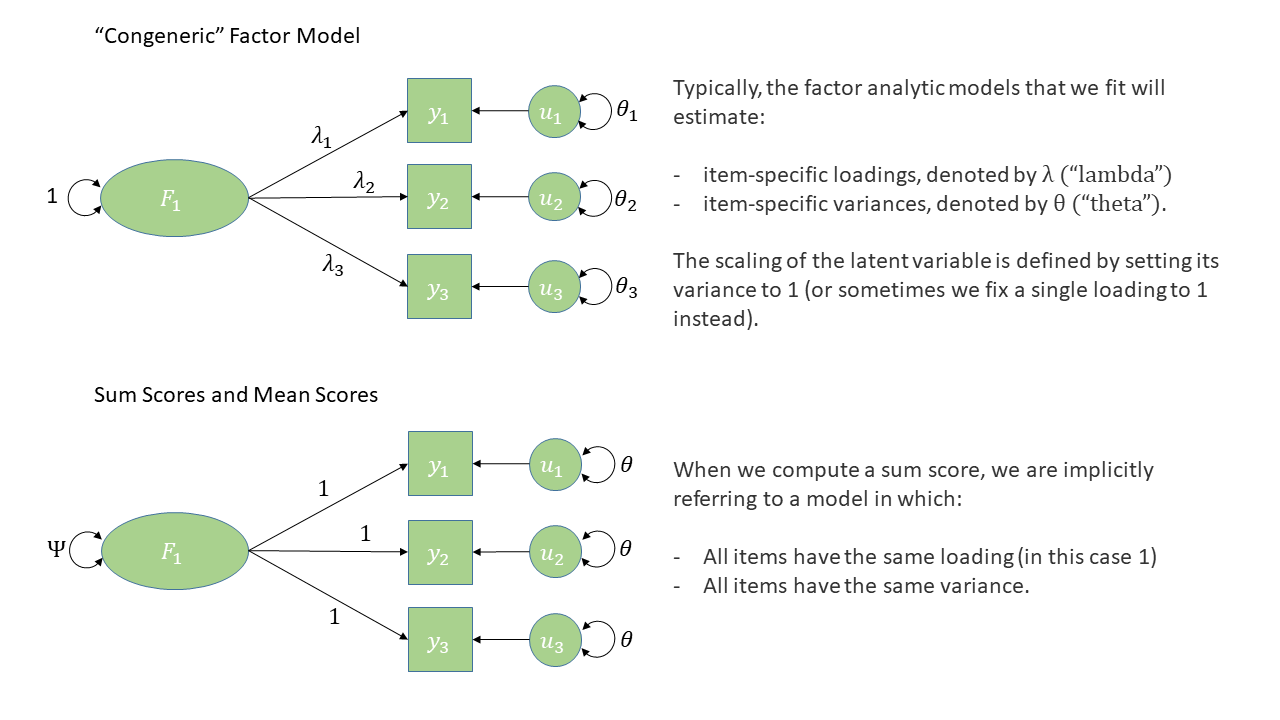
Optional Question 7
Imagine that you’re a clinician administering the DAS to a patient. In clinical settings, it’s common practice to skip the complex factor analysis we’ve been doing here and just create a sum score or a mean score that describe a patient’s responses. Then clinicians can check whether the score is above some threshold to see whether there’s cause for concern.
For each of the dimensions of apathy in the data, calculate sum scores for each of the 250 participants.
Hints
Good ol’ rowSums() to the rescue!
Optional Question 8
How might you think about a sum/mean score in terms of a diagram?
Hints
What does a sum or mean score imply about how each item is weighted compared to the others? How is this different from what a more sophisticated method like EFA or CFA can do?
“DOOM” Scrolling
Dataset: doom.csv
The “Domains of Online Obsession Measure” (DOOM) is a fictitious scale that aims to assess the sub types of addictions to online content. It was developed to measure 2 separate domains of online obsession: items 1 to 9 are representative of the “emotional” relationships people have with their internet usage (i.e. how it makes them feel), and items 10 to 15 reflect “practical” relationship (i.e., how it connects or interferes with their day-to-day life). Each item is measured on a 7-point likert scale from “strongly disagree” to “strongly agree”.
We administered this scale to 476 participants in order to assess the validity of the 2 domain structure of the online obsession measure that we obtained during scale development.
The data are available at https://uoepsy.github.io/data/doom.csv, and the table below shows the individual item wordings.
| variable | question |
|---|---|
| item_1 | i just can't stop watching videos of animals |
| item_2 | i spend hours scrolling through tutorials but never actually attempt any projects. |
| item_3 | cats are my main source of entertainment. |
| item_4 | life without the internet would be boring, empty, and joyless |
| item_5 | i try to hide how long i’ve been online |
| item_6 | i avoid thinking about things by scrolling on the internet |
| item_7 | everything i see online is either sad or terrifying |
| item_8 | all the negative stuff online makes me feel better about my own life |
| item_9 | i feel better the more 'likes' i receive |
| item_10 | most of my time online is spent communicating with others |
| item_11 | my work suffers because of the amount of time i spend online |
| item_12 | i spend a lot of time online for work |
| item_13 | i check my emails very regularly |
| item_14 | others in my life complain about the amount of time i spend online |
| item_15 | i neglect household chores to spend more time online |
Question 9
Assess whether the 2 domain model of online obsession provides a good fit to the validation sample of 476 participants.
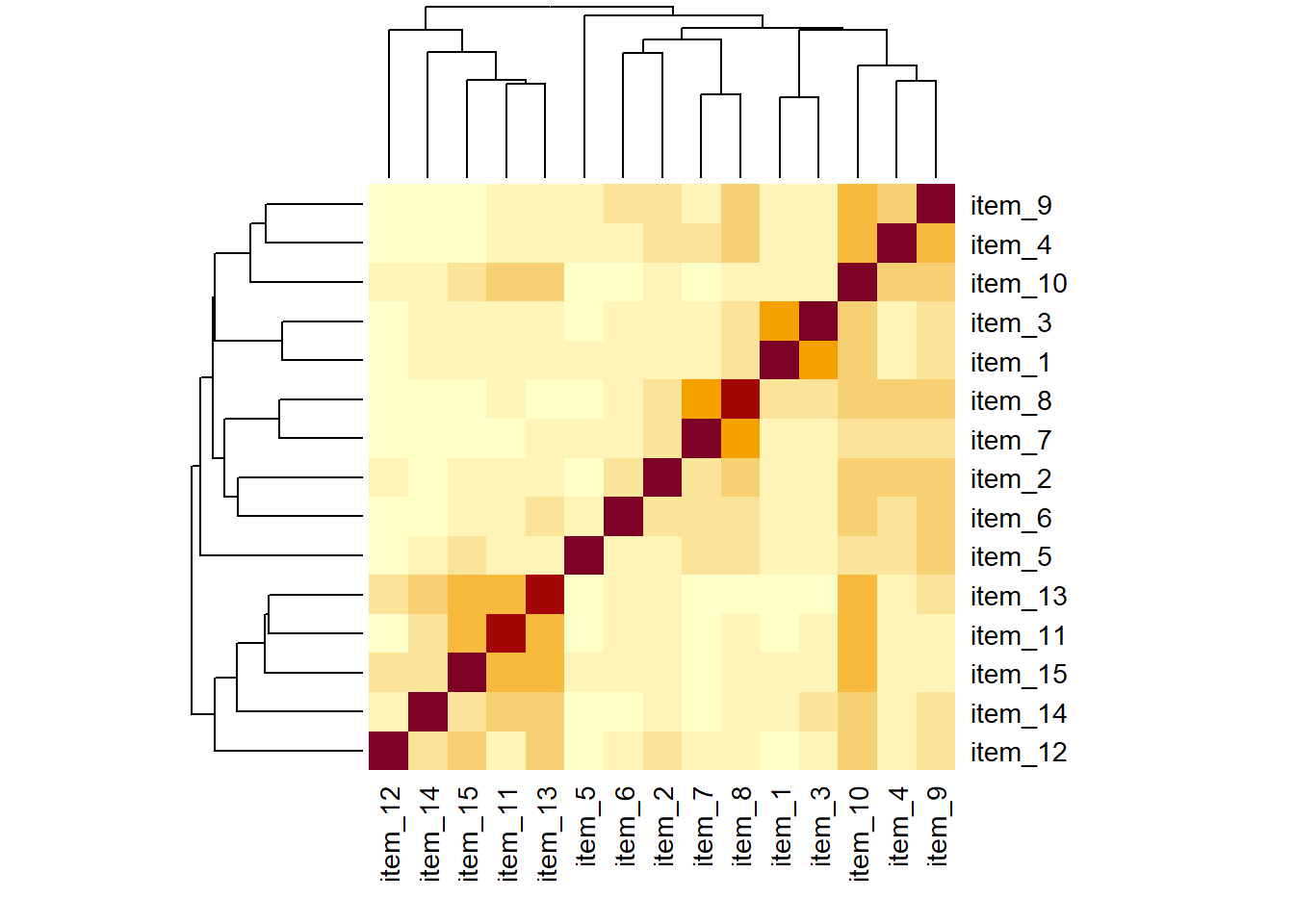
Question 10
Are there any areas of local misfit (certain parameters that are not in the model (and are therefore fixed to zero) but that could improve model fit if they were estimated?).
Question 11
Beware: there’s a slightly blurred line here that we’re about to step over, and move from confirmatory back to ‘exploratory’.
Look carefully at the item wordings,do any of the suggested modifications make theoretical sense? Add them to the model and re-fit it. Does this new model fit well?
As a general heuristics:
Less contentious use of modification indices:
- residual covariances for items within a factor (essentially asserts that the two observed variables share some of their specific variance)
More contentious uses of modification indices:
- adding cross-loadings (could argue that an item loading on two factors is not a clean indicator, and so should be removed)
- residual covariances for items on different factors - often harder to defend
- changing paths between the latent variables - very definitely changing your theory!
Question 12
Based on our analysis of the DOOM measure, which of the following statements accurately reflect our current position? (you can choose multiple!)
- A The theoretical measurement model is now confirmed. Because our final fit indices (CFI/RMSEA) meet the thresholds, the initial theory of DOOM scrolling is validated.
- B We have confirmed our theoretical measurement model, but with some caveats
- C Our analysis has shifted from confirmatory to exploratory; while the model now fits the data, it requires validation on an independent sample.
- D The measure of doom scrolling is fundamentally flawed and should be discarded/updated due to the initial lack of fit.
- E The measure of doom scrolling is likely suffers from poor content validity. The need for correlated errors suggests item wordings are redundant or overlapping, meaning the scale likely needs redesigning.
More Conduct Problems
Data: conduct_problems_2.csv
Last week we conducted an exploratory factor analysis of a dataset to try and identify an optimal factor structure for a new measure of conduct (i.e., antisocial behavioural) problems.
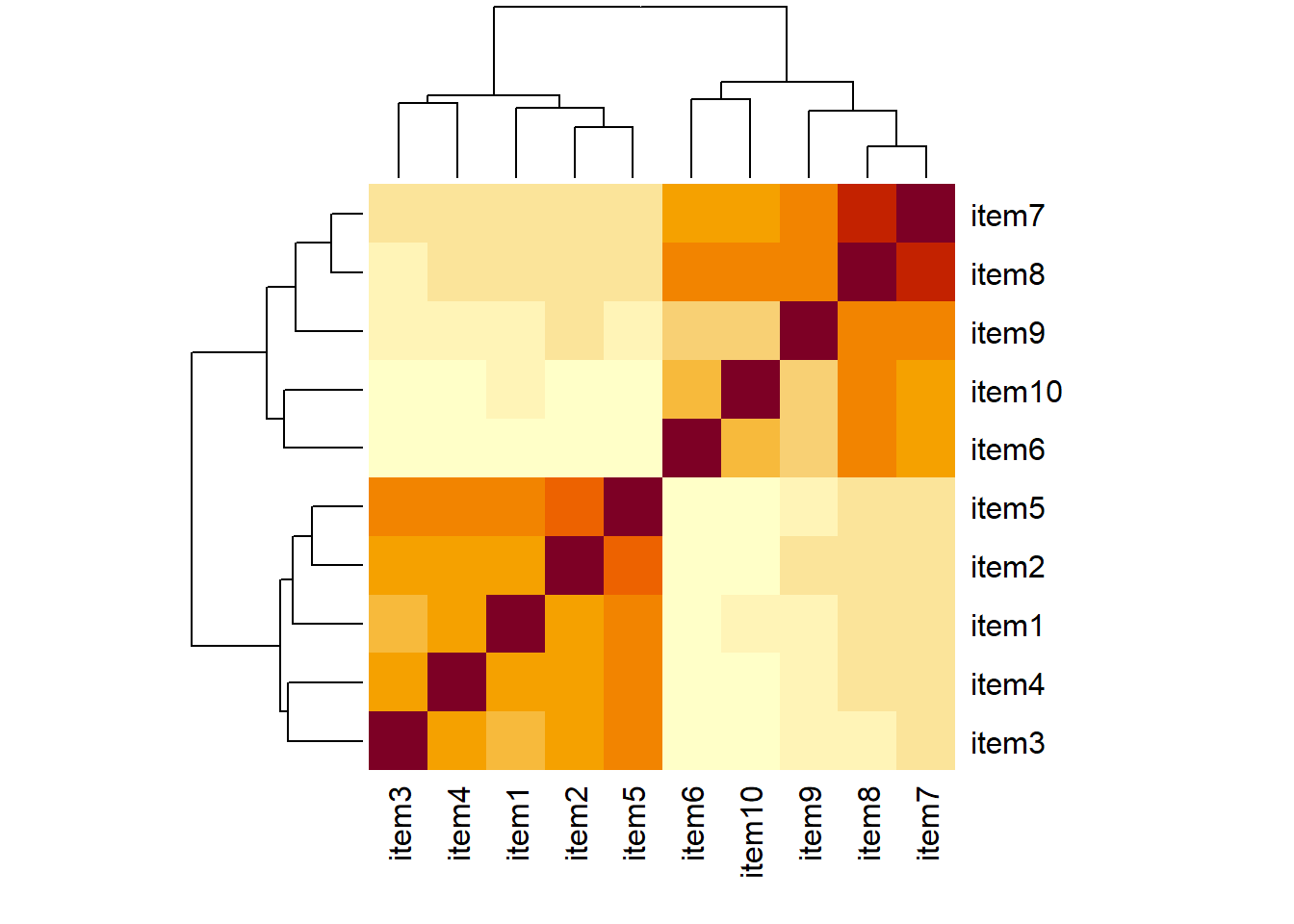
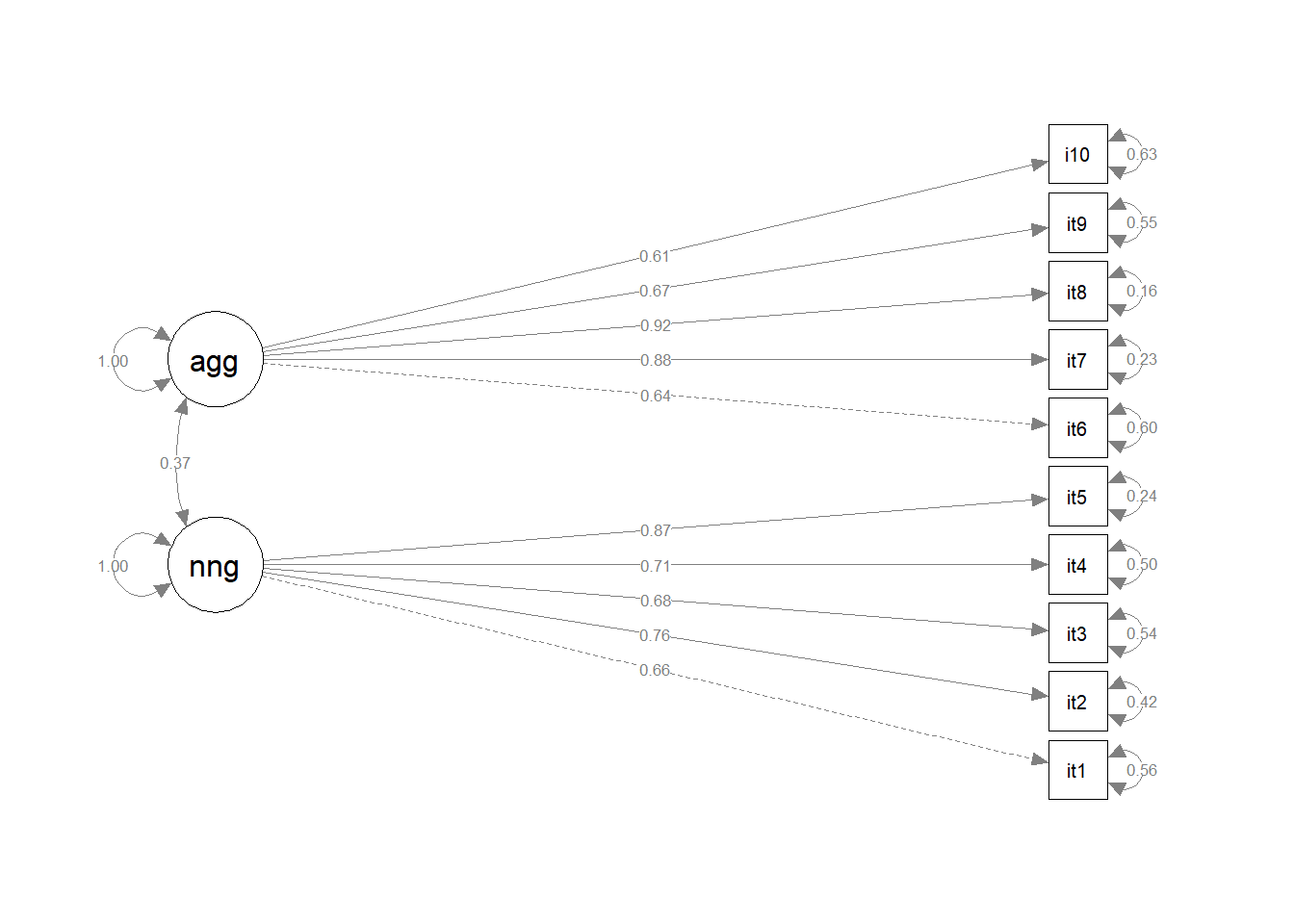
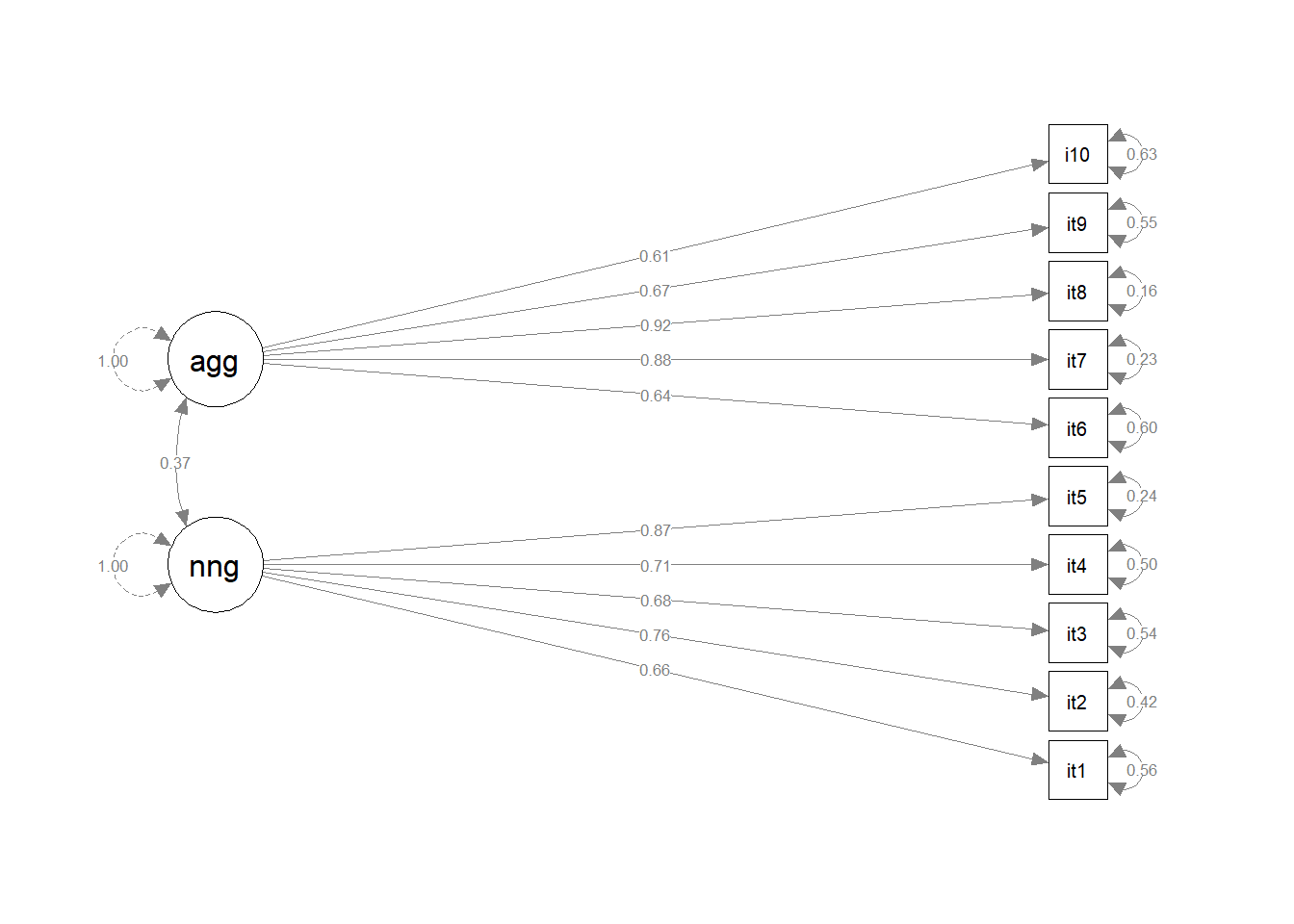
This week, we’ll conduct some confirmatory factor analyses (CFA) of the same inventory to assess the extent to which this 2-factor structure fits an independent sample. To do this, we have administered our measure to a new sample of n=600 adolescents.
We have re-ordered the questionnaire items to be grouped into the two types of behaviours:
Non-Aggressive Behaviours
| item | behaviour |
|---|---|
| item 1 | Stealing |
| item 2 | Lying |
| item 3 | Skipping school |
| item 4 | Vandalism |
| item 5 | Breaking curfew |
Aggressive Behaviours
| item | behaviour |
|---|---|
| item 6 | Threatening others |
| item 7 | Bullying |
| item 8 | Spreading malicious rumours |
| item 9 | Using a weapon |
| item 10 | Fighting |
The data are available as a .csv at https://uoepsy.github.io/data/conduct_problems_2.csv
Question 13
- Read in the data, and take a quick look around (e.g., cor matrix, quick pairs.panels plots etc).
- Fit the proposed 2 factor model
- Examine the fit of the 2-factor model of conduct problems to this new sample of 600 adolescents.
- Evaluate the fit, and make any model modifications if necessary (and only if you feel that there is substantive support for the modification given the items).
- Make a diagram of your model, using the standardised factor loadings as labels.
- Make a bullet point list of everything you have done so far, and the resulting conclusions. Then, if you feel like it, turn the bulleted list into written paragraphs, and you’ll have a write-up of your analyses!