| variable | question |
|---|---|
| name | employee name |
| q1 | Deadline Consistency: Average discrepancy between 'Target Date' vs. 'Actual Completion Date' for assigned tasks. |
| q2 | Scheduling: Frequency of updated timelines or revised milestones sent to the team. |
| q3 | Resource Allocation: How well have they allocated resources to ensure efficient project execution? |
| q4 | Risk Identification: Rate their proficiency in identifying and mitigating project risks. |
| q5 | Project Updating: Frequency of weekly status emails/announcements on the project. |
| q6 | Collaboration: Number of projects where they were a 'Collaborator' or 'Contributor' alongside others. |
| q7 | Teamwork: Rate how well they have actively listened to and considered the ideas and opinions of others. |
| q8 | Positivity: How effectively have they contributed to a positive team environment? |
| q9 | Assistance: Frequency of being tagged for help on others' assigned tasks. |
| q10 | Conflict: How well have they resolved conflicts and disagreements within the team? |
| q11 | Technical Proficiency: The number of tasks sent back for 'Correction' versus those approved on the first pass. |
| q12 | Technical Development: Number of completed internal or external training certifications. |
| q13 | Problem Resolution: The average time between a 'Help Ticket' or 'Bug' being assigned and closed. |
| q14 | Technical Communication: How well have they translated complex technical information into understandable terms for non-technical stakeholders? |
| q15 | Technical Initiative: How well have they leveraged technical expertise for problem-solving? |
Week 7 Exercises: PCA & EFA
New packages
We’re going to be needing some different packages this week (no more lme4!).
Make sure you have these packages installed:
- psych
- GPArotation
- car
Reducing the dimensionality of job performance
Data: jobperfbonus.csv
A company has asked line managers to fill out a questionnaire that asks them to capture ‘performance indicators’ for each of their employees. These 15 indicators are a mix of metrics from the companies work management software, and questions about manager’s perceptions of their employees’ work over the last year.
The company’s leadership team finds the 15-indicator report a bit confusing and overwhelming. They want to create a simplified “Performance Dashboard” that captures only the most important directions of variance in their employees.
It can be downloaded at https://uoepsy.github.io/data/jobperfbonus.csv
Question 1
Load the data!
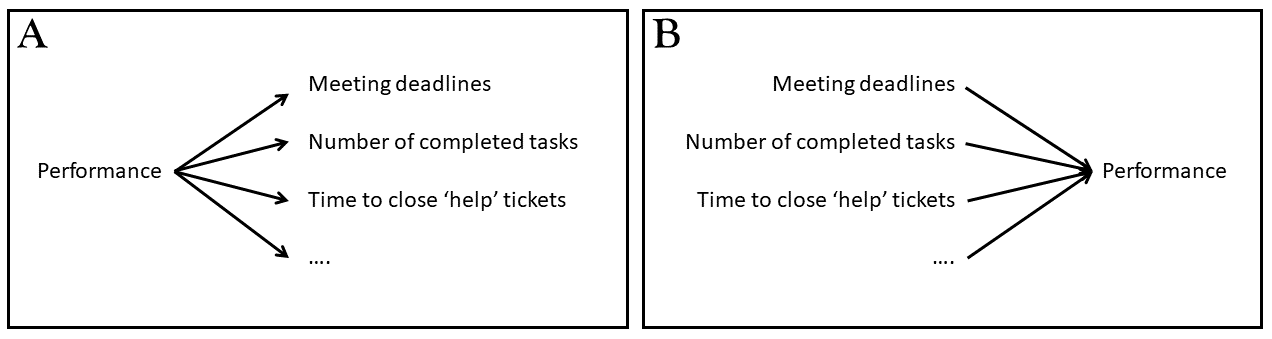
We’re going to want to reduce these 15 variables (or “items”) down into a smaller set. Should we use PCA or EFA?
Question 2
Explore the relationships between variables in the data.
You’re probably going to want to subset out just the relevant variables (q1 to q15).
Hints
There are lots of variables! There are various things we can do here. Try some of them to see what they do:
cor(data)heatmap(cor(data))pairs.panels(data)(from the psych package)
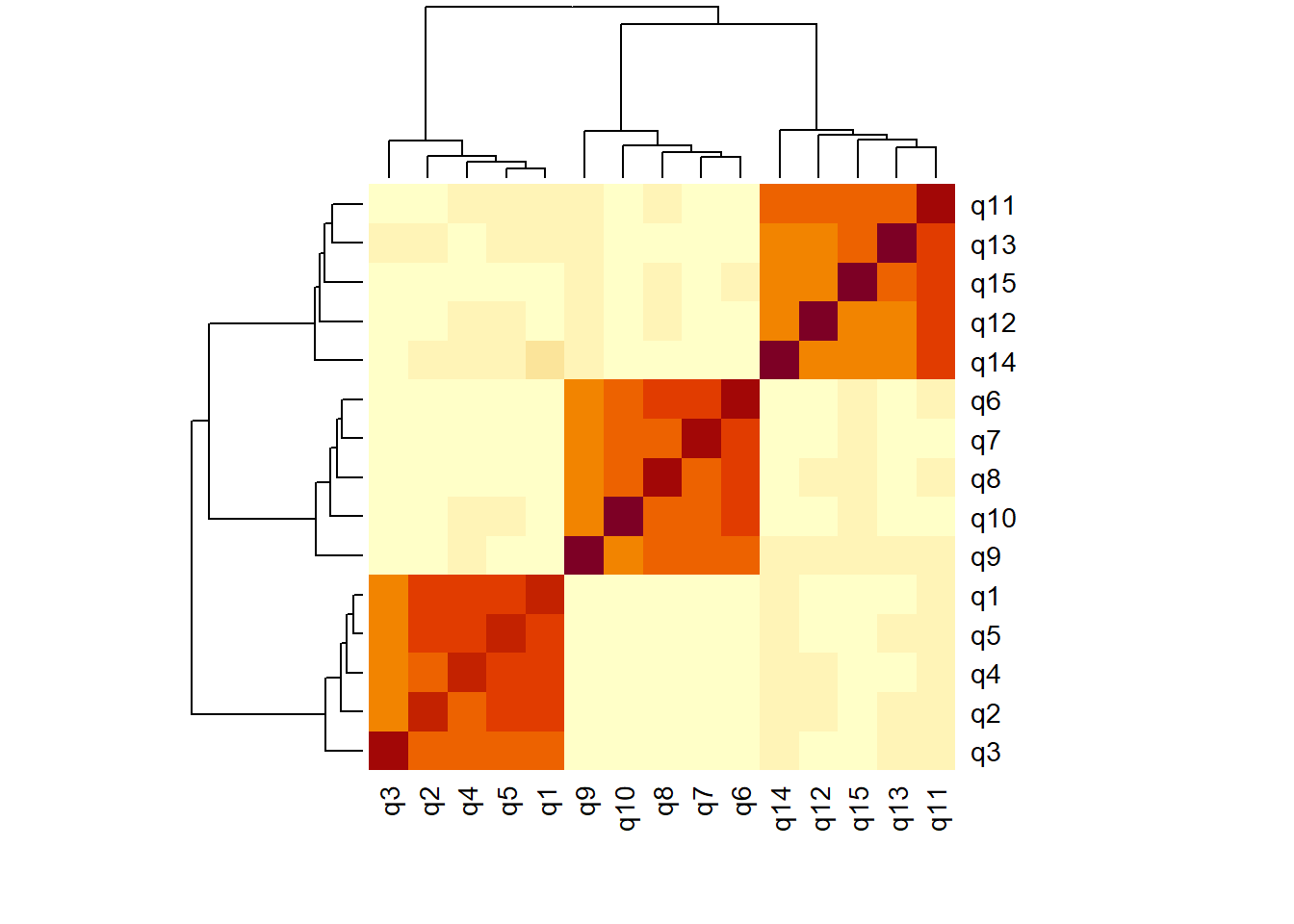

Question 3
How much variance in the set of performance indicators will be captured by 15 principal components?
Note: We can figure this out without having to do anything - it’s a theoretical question!
Question 4
Remember, the company is wanting us to simplify things down from having 15 indicators of ‘job performance’ to a smaller set, that captures the most important ways in which employees vary in their performance.
We’re going to use PCA.
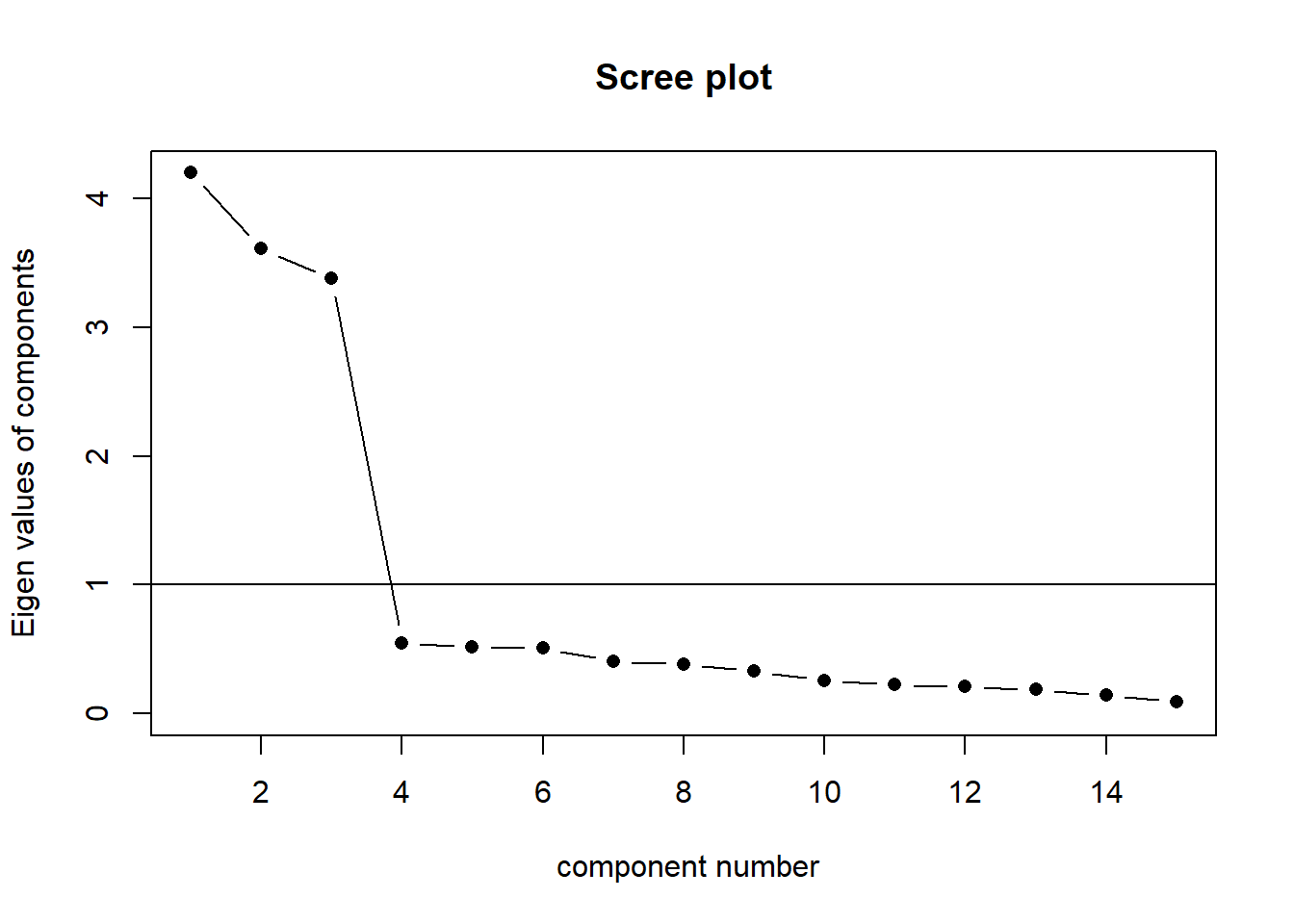
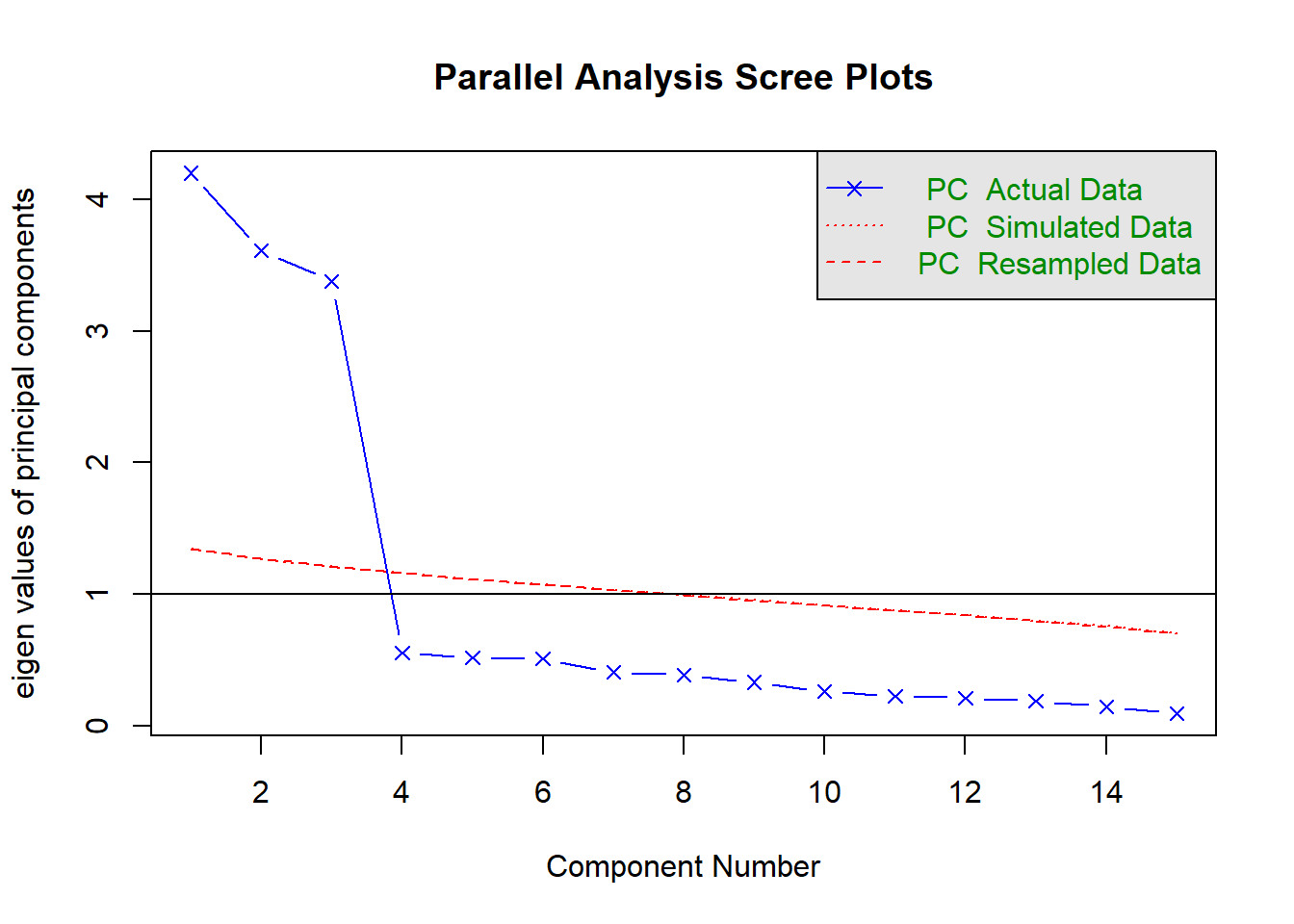
How many components should we keep?
Hints
See scree plots, parallel analysis, MAP - Chapter 2 - PCA walkthrough.
Question 5
Conduct a principal components analysis extracting the number of components you decided on from the previous question.
Be sure to set rotate = "none" (a conventional PCA does not use rotations - it is simply about data reduction. The line is a bit blurred here, but once we start introducing rotations, we are moving more towards a form of EFA).
Examine the loadings for the components. By thinking in relation to the questions that were asked (refer back to Table 1), what do you think each component is capturing?
Question 6
Extract the scores on the principal components.
The company wants to reward teamwork. Pick 10 people they should give a bonus to.
Hints
See Chapter 2#PCA-walkthrough - scores for how to extract scores (a score on each component for each row of our original dataset) using the $scores from the object fitted with principal().
This will contain as many sets of scores as there are components. One of these (given the previous question) might be of use here.
You’ll likely want to join them back to the column of names. So we can figure out who gets the bonus. cbind() or bind_cols() might help here.
Understanding Conduct Problems
Data: Conduct Problems
A researcher is developing a new brief measure of Conduct Problems. She has collected data from n=450 adolescents on 10 items, which cover the following behaviours:
- Breaking curfew
- Vandalism
- Skipping school
- Bullying
- Spreading malicious rumours
- Fighting
- Lying
- Using a weapon
- Stealing
- Threatening others
Our task is to use the dimension reduction techniques we learned about in the lecture to help inform how to organise the items she has developed into subscales.
The data can be found at https://uoepsy.github.io/data/conduct_probs_scale.csv
Question 7
Read in the dataset.
Create a correlation matrix for the items, and inspect the items to check their suitability for exploratory factor analysis (see Chapter 3#EFA-initial checks).
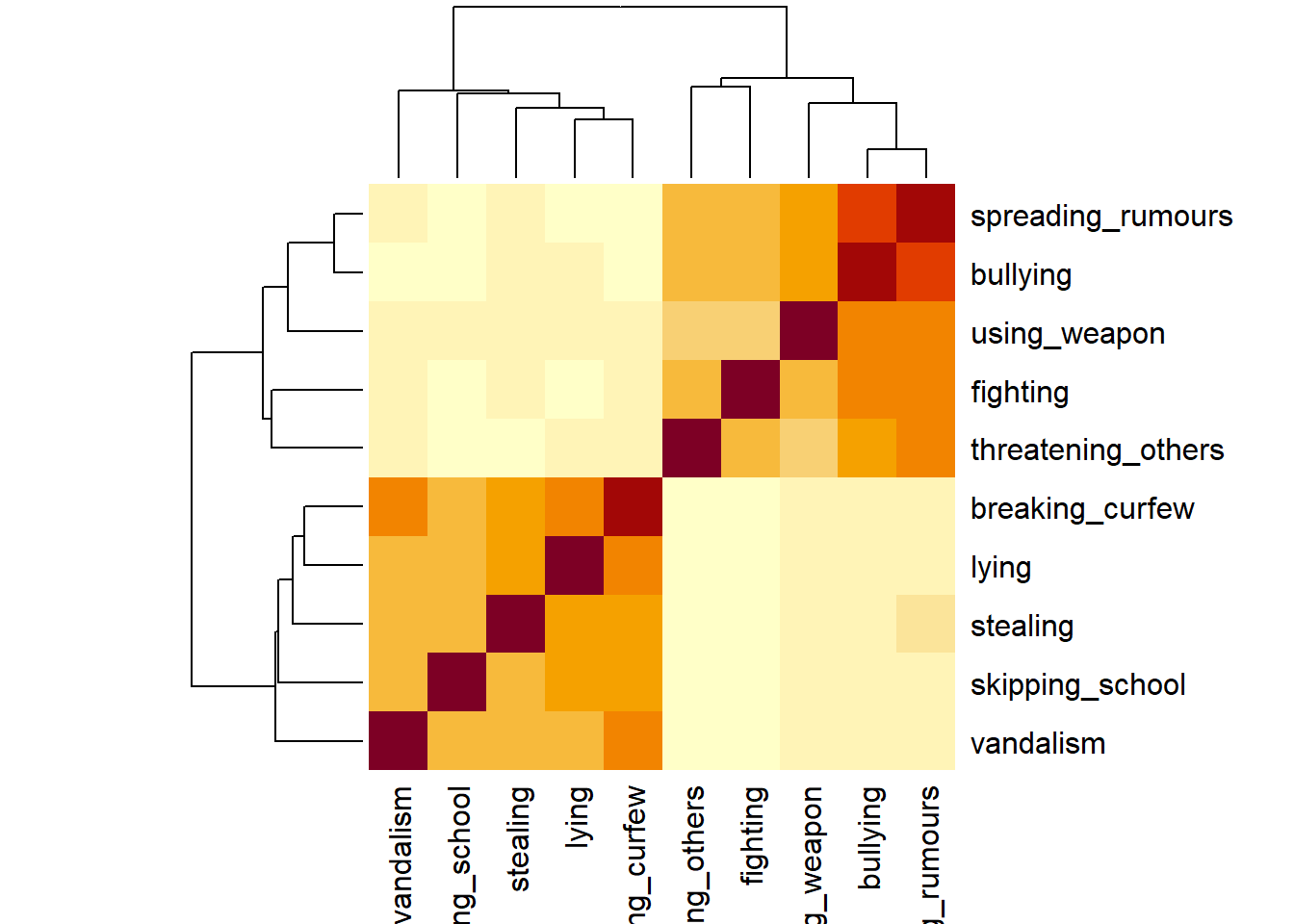
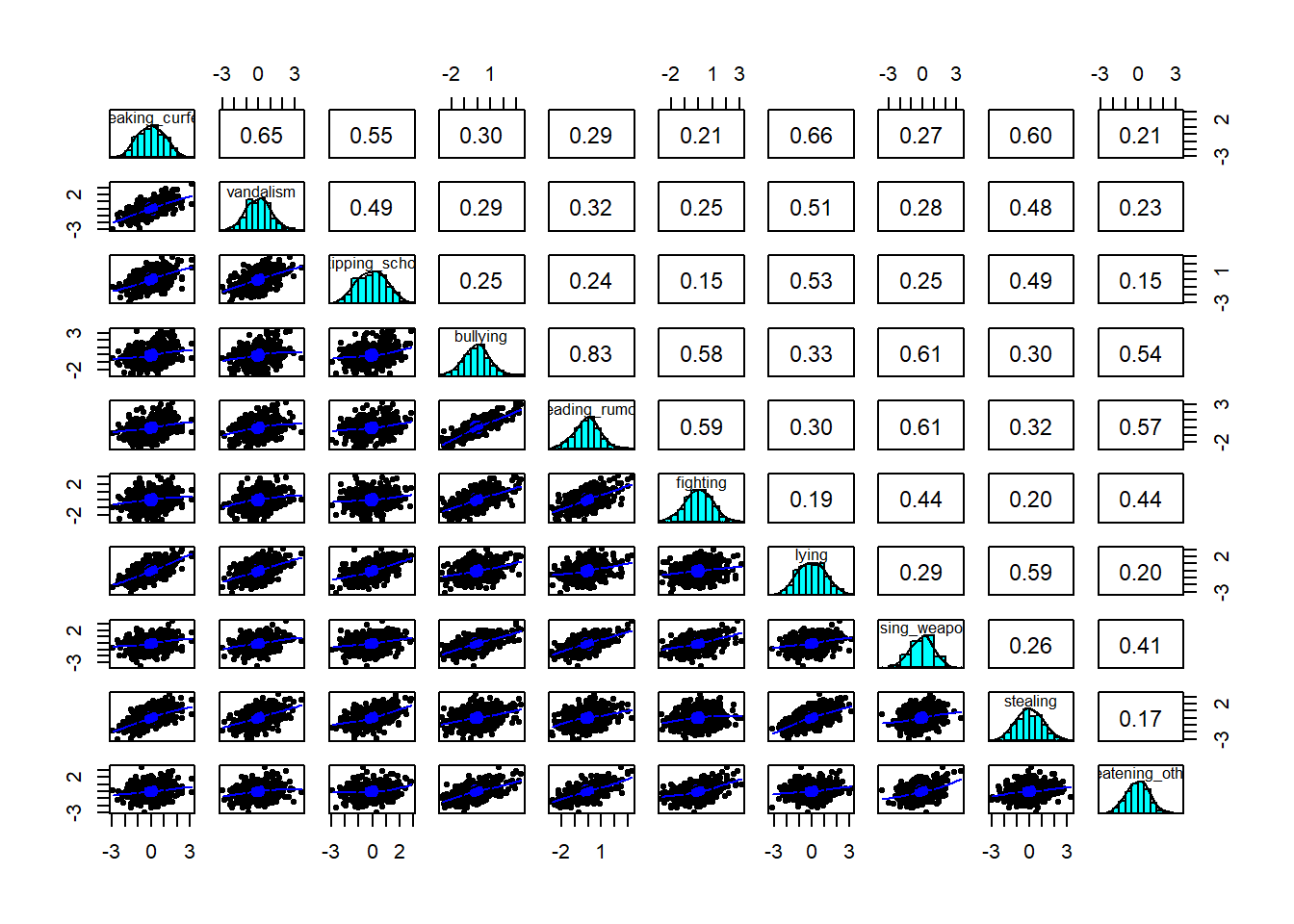
Question 8
How many dimensions should be retained?
This question can be answered in the same way as we did above for PCA - use a scree plot, parallel analysis, and MAP test to guide you.
You can use fa.parallel(data, fa = "both") to conduct both parallel analysis and view the scree plot!
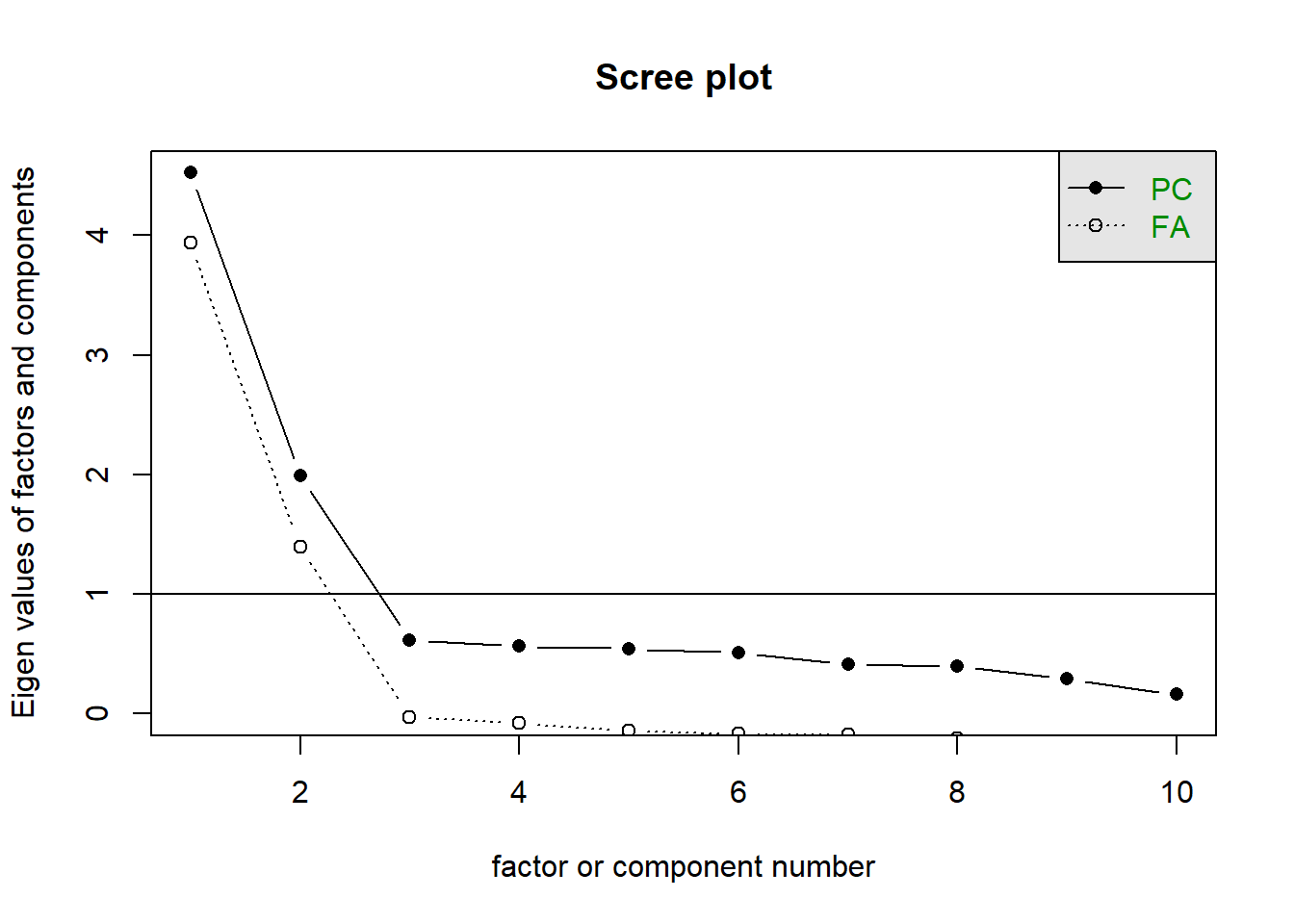
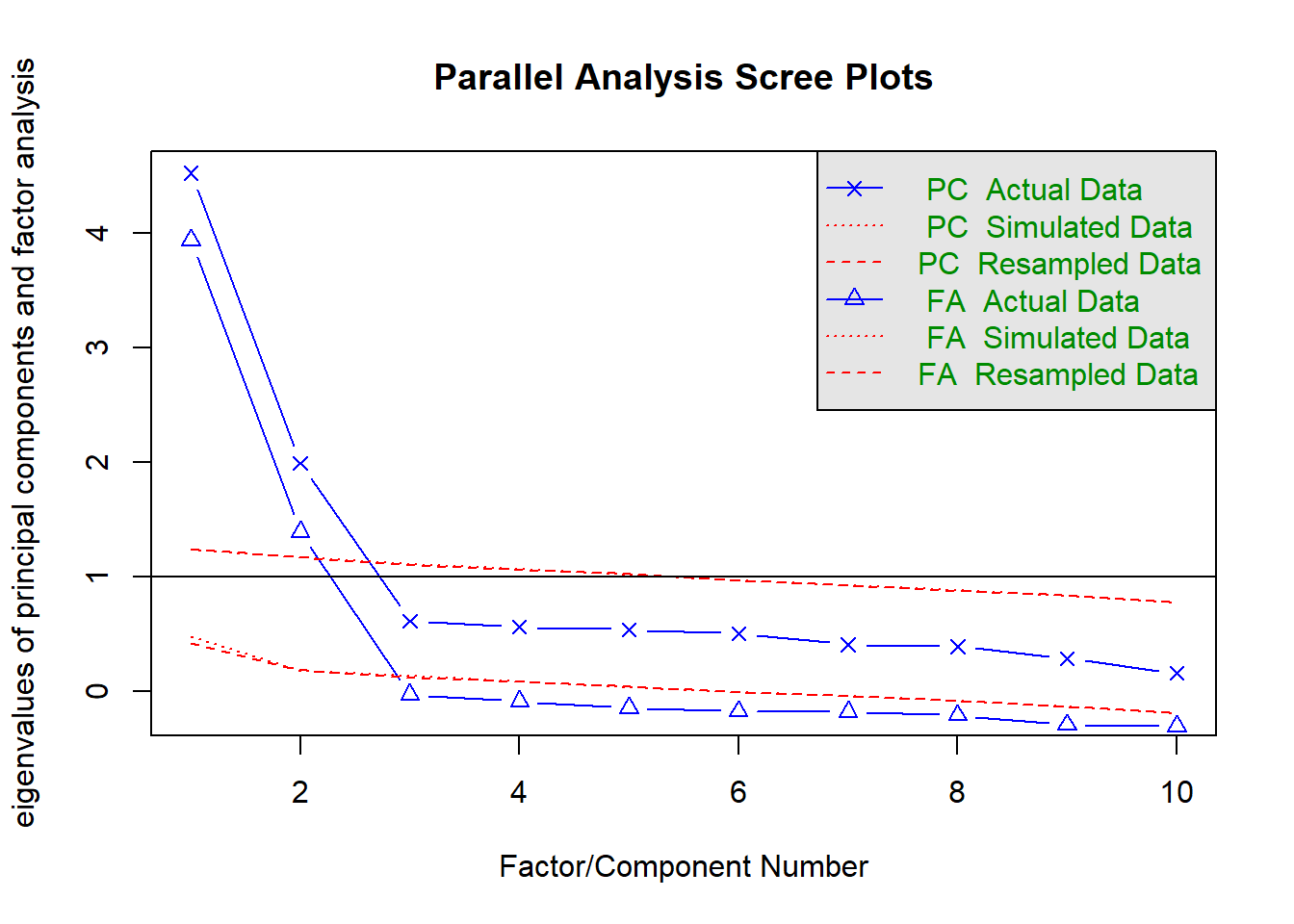
Question 9
Use the function fa() from the psych package to conduct and EFA to extract 2 factors (this is what we suggest based on the various tests above, but you might feel differently - the ideal number of factors is subjective!). Use a suitable rotation (rotate = ?) and extraction method (fm = ?).
myfa <- fa(data, nfactors = ?, rotate = ?, fm = ?)
Hints
Would you expect factors to be correlated? If so, you’ll want an oblique rotation.
If there are two+ underlying factors of ‘conduct problems’, if someone is higher on one of them, would we expect them to therefore be high/low on the other? If so, then we the two factors are correlated!
Question 10
Inspect your solution. Make sure to look at and think about the loadings, the variance accounted for, and the factor correlations (if estimated).
What we’re doing here is essentially evaluating whether our solution looks theoretically coherent. A big part of this is a subjective decision about the groupings of items, but we would also like the numerical parts of our model to meet certain criteria (see Chapter 3: EFA#what-makes-a-good-factor-solution).
Hints
Just printing an fa object:
myfa <- fa(data, ..... )
myfaWill give you lots and lots of information.
You can extract individual parts using:
myfa$loadingsfor the loadingsmyfa$Vaccountedfor the variance accounted for by each factormyfa$Phifor the factor correlation matrix
You can find a quick guide to reading the fa output here: efa_output.pdf.
Question 11
Look back to the description of the items, and suggest a name for your factors based on the patterns of loadings.
Hints
To sort the loadings, you can use
print(myfa$loadings, sort = TRUE)
Question 12
Compare your three different solutions:
- your current solution from the previous questions
- one where you fit 1 more factor
- one where you fit 1 fewer factors
Which one looks best?
Hints
We’re looking here to assess:
- how much variance is accounted for by each solution
- do all factors load on 3+ items at a salient level?
- do all items have at least one loading at a salient level?
- are there any “Heywood cases” (communalities or standardised loadings that are >1)?
- should we perhaps remove some of the more complex items?
- is the factor structure (items that load on to each factor) coherent, and does it make theoretical sense?
Question 13
Drawing on your previous answers and conducting any additional analyses you believe would be necessary to identify an optimal factor structure for the 10 conduct problems, write some bullet points to summarise your methods and the results of your chosen optimal model.
Remember, the main principles governing the reporting of statistical methods are transparency and reproducibility (i.e., someone should be able to reproduce your analysis based on your description).
Footnotes
You should provide the table of factor loadings. It is conventional to omit factor loadings \(<|0.3|\); however, be sure to ensure that you mention this in a table note.↩︎