library(tidyverse)
jsup <- read_csv("https://uoepsy.github.io/data/lmm_jsup.csv")
ggplot(jsup, aes(x = seniority, y = wp, col = role)) +
stat_summary(geom="pointrange")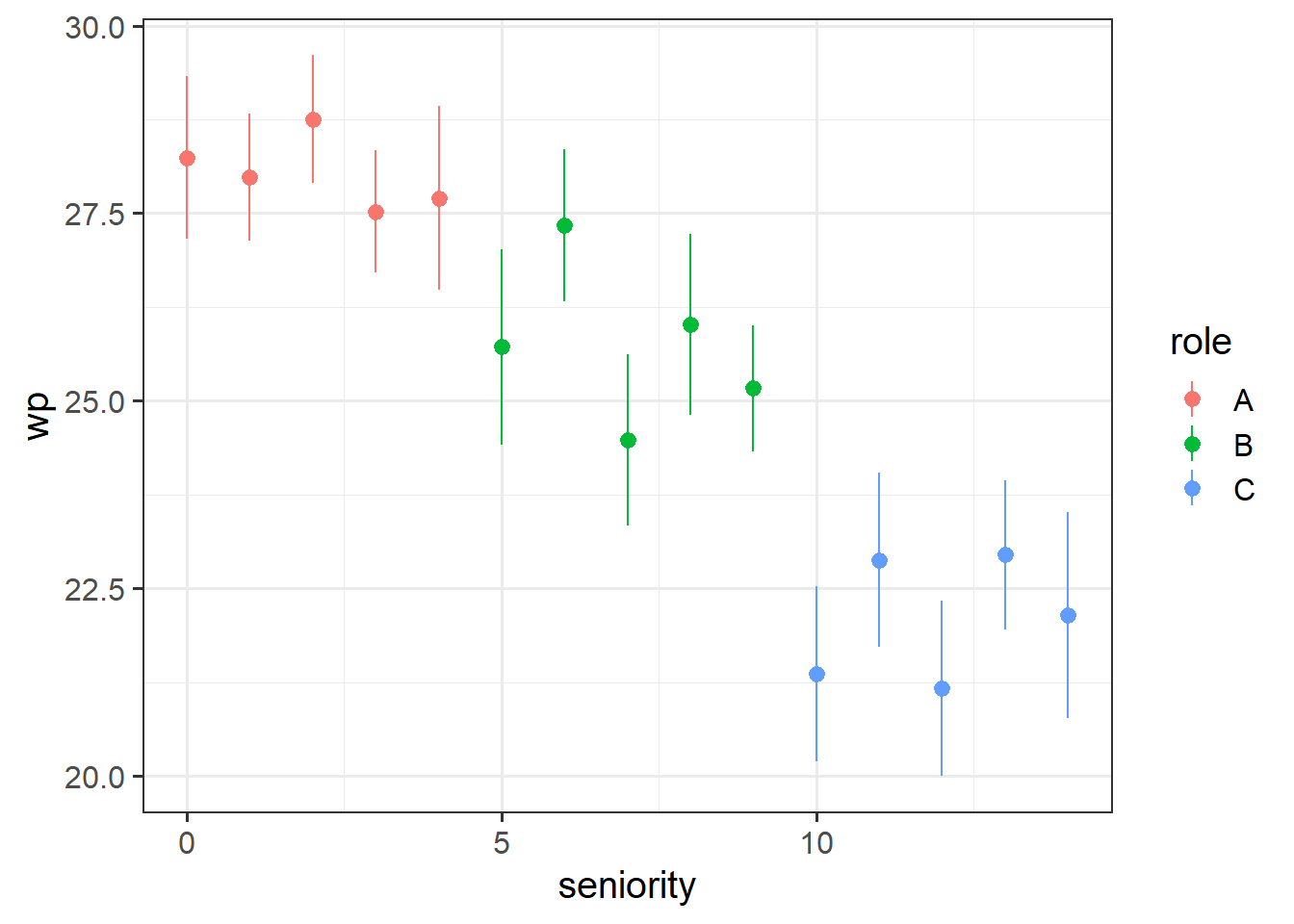
These first set of exercises are not “how to do analyses with multilevel models” - they are designed to get you thinking, and help with an understanding of how these models work.
Recall the data from last week’s exercises. Instead of looking at the roles A, B and C, we’ll look in more fine grained detail at the seniority. This is mainly so that we have a continuous variable to work with as it makes this illustration easier.
The chunk of code below shows a function for plotting that you might not be familiar with - stat_summary(). This takes the data in the plot and “summarises” the Y-axis variable into the mean at every unique value on the x-axis. So below, rather than having a lot of individual data points that represent every employee’s wp (workplace pride), we let stat_summary() compute the mean (the points) plus and minus the standard error (the vertical lines) of all the wp observations at each value of seniority:
library(tidyverse)
jsup <- read_csv("https://uoepsy.github.io/data/lmm_jsup.csv")
ggplot(jsup, aes(x = seniority, y = wp, col = role)) +
stat_summary(geom="pointrange")
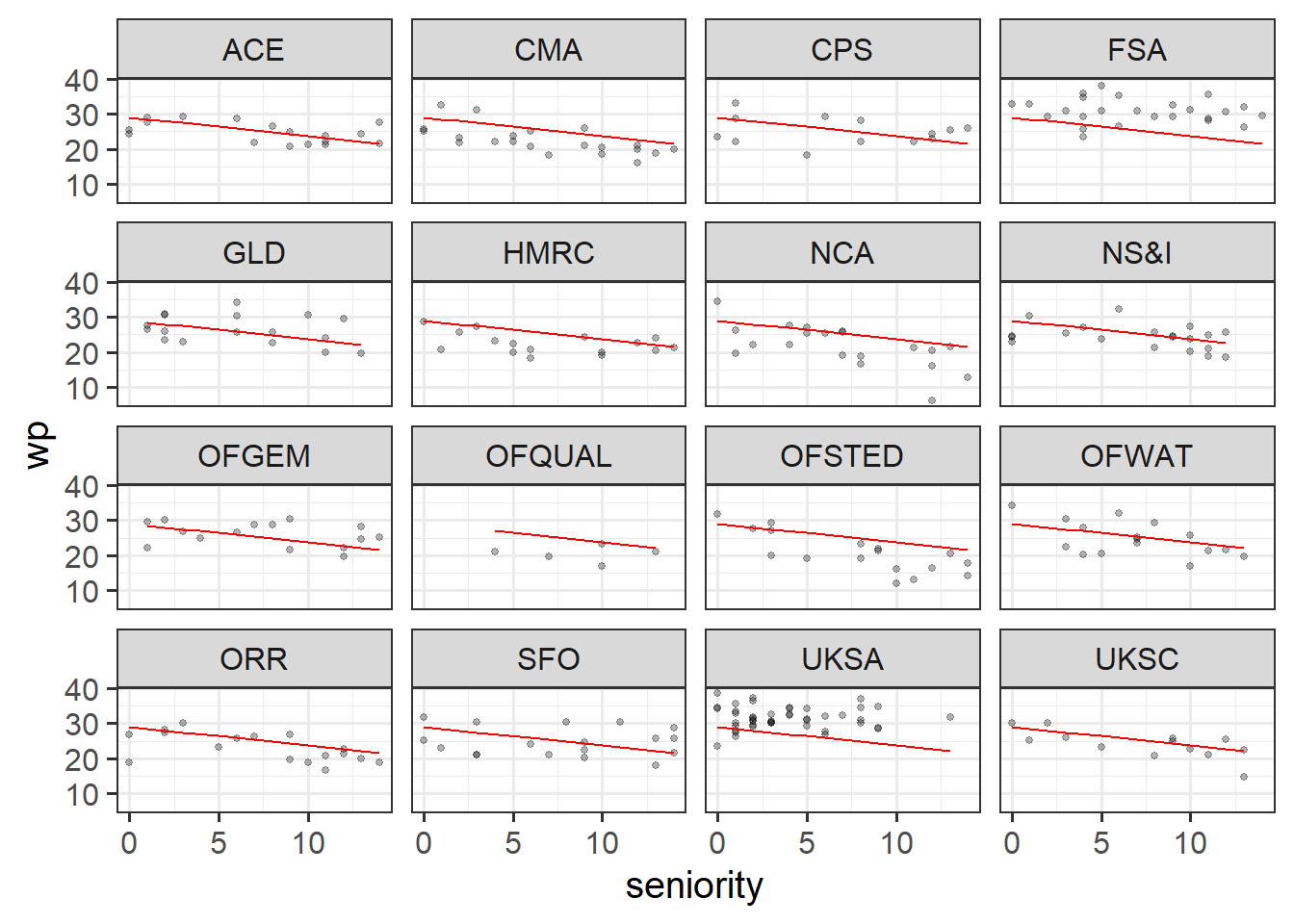
Below is some code that fits a model of the workplace-pride predicted by seniority level. Line 2 then gets the ‘fitted’ values from the model and adds them as a new column to the dataset, called pred_lm. The fitted values are what the model predicts the workplace pride to be for every value of seniority.
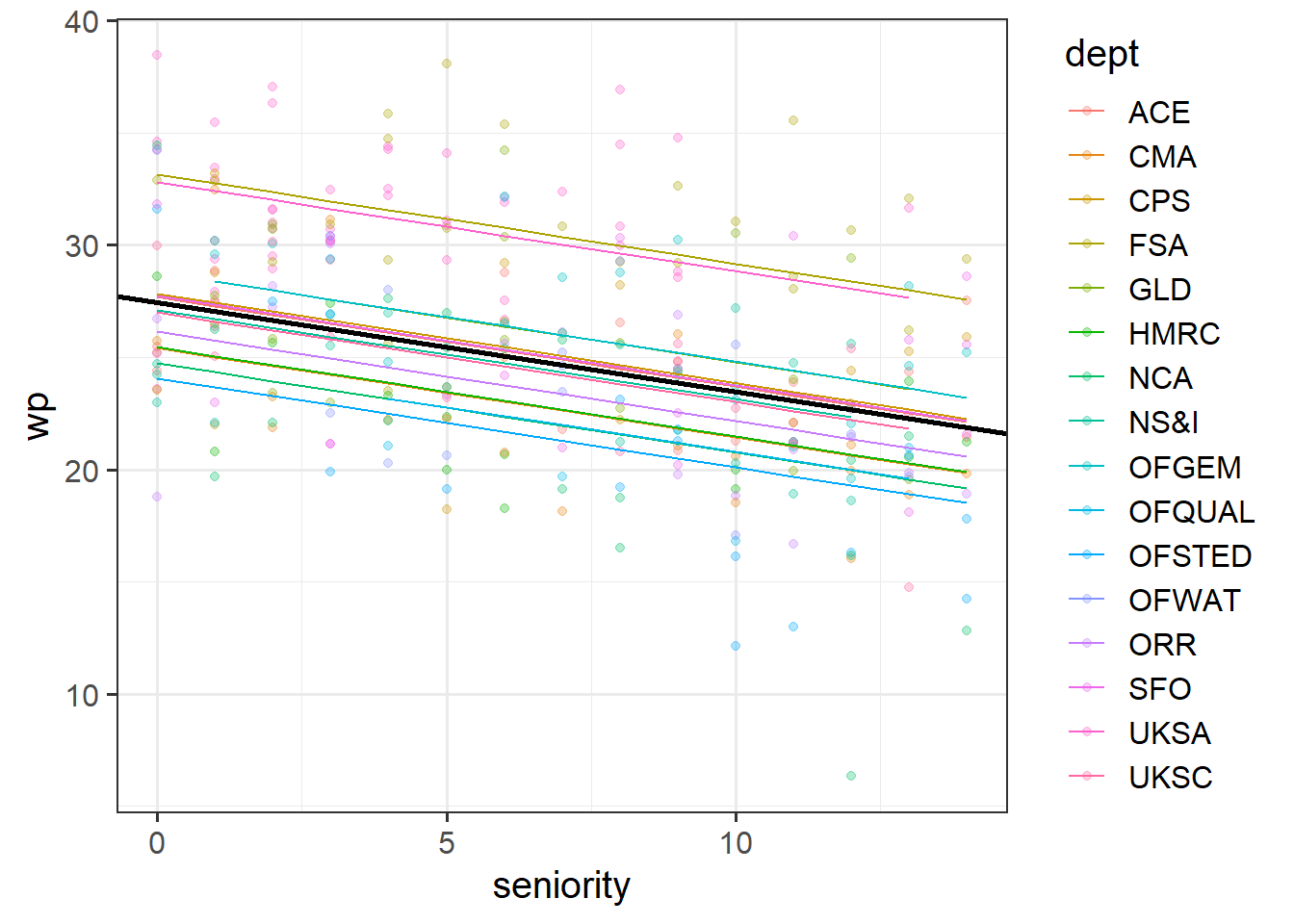
Lines 4-7 then plot the data, split up by each department, and adds lines showing the model fitted values.
Run the code and check that you get a plot. What do you notice about the lines?
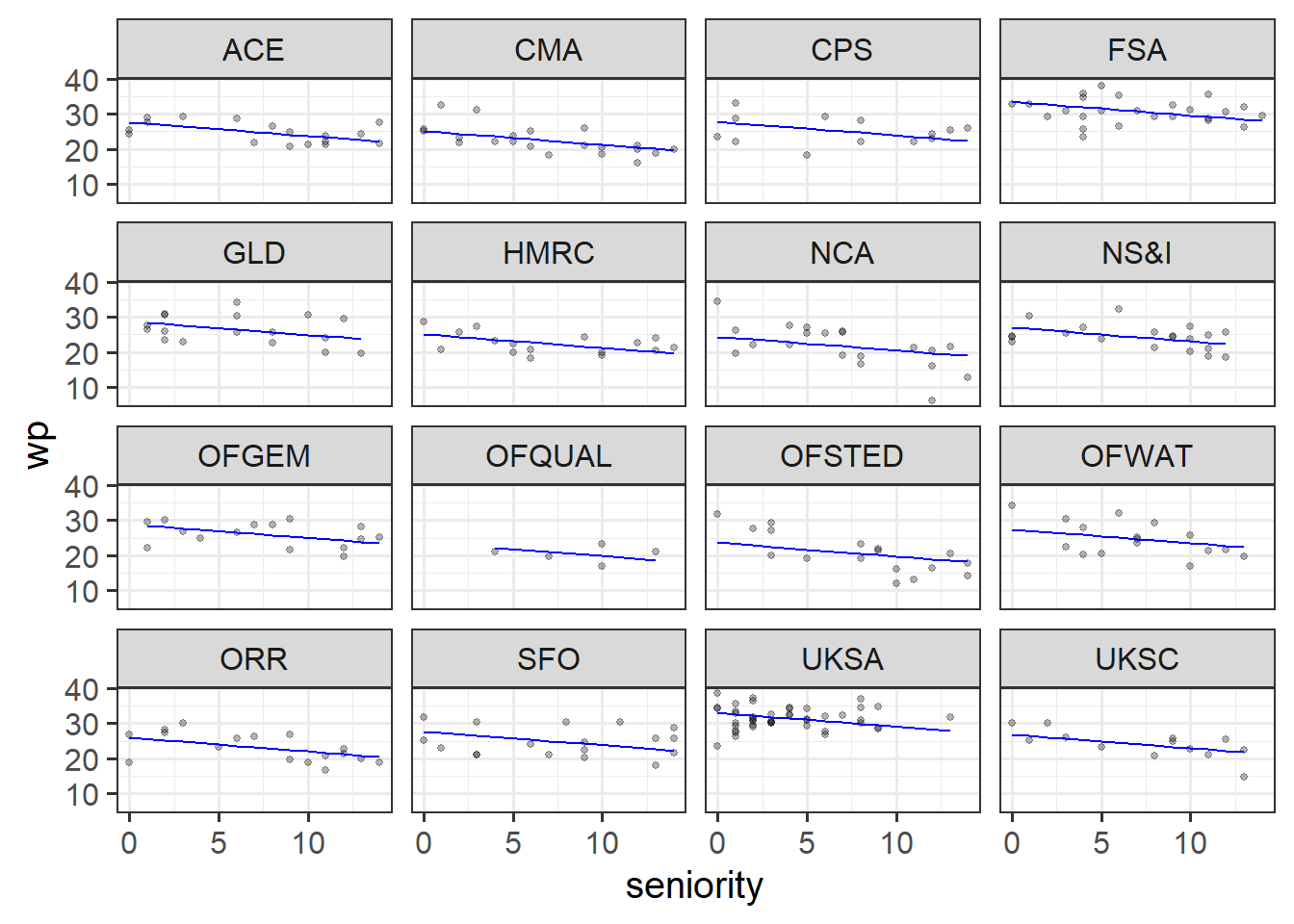
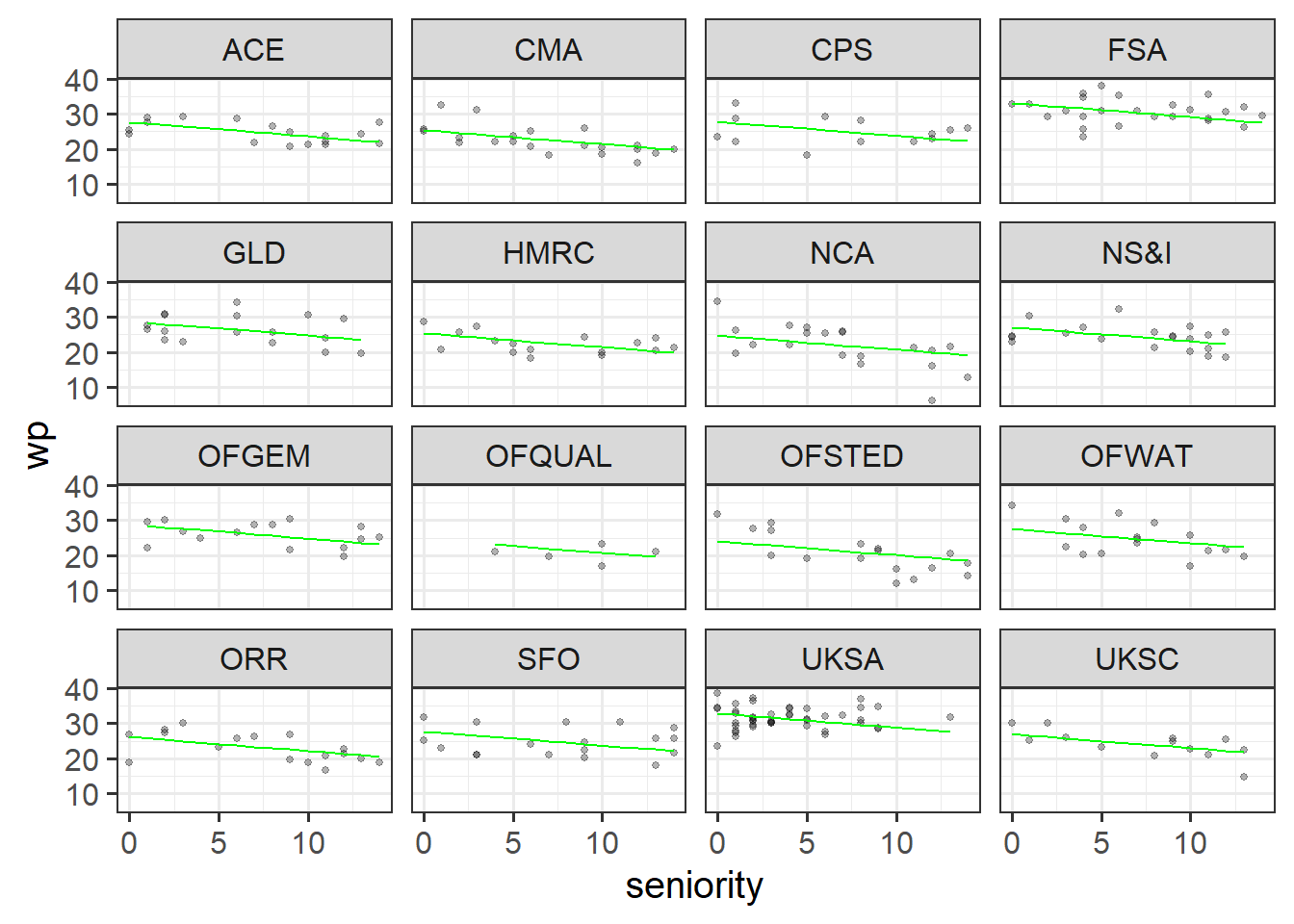
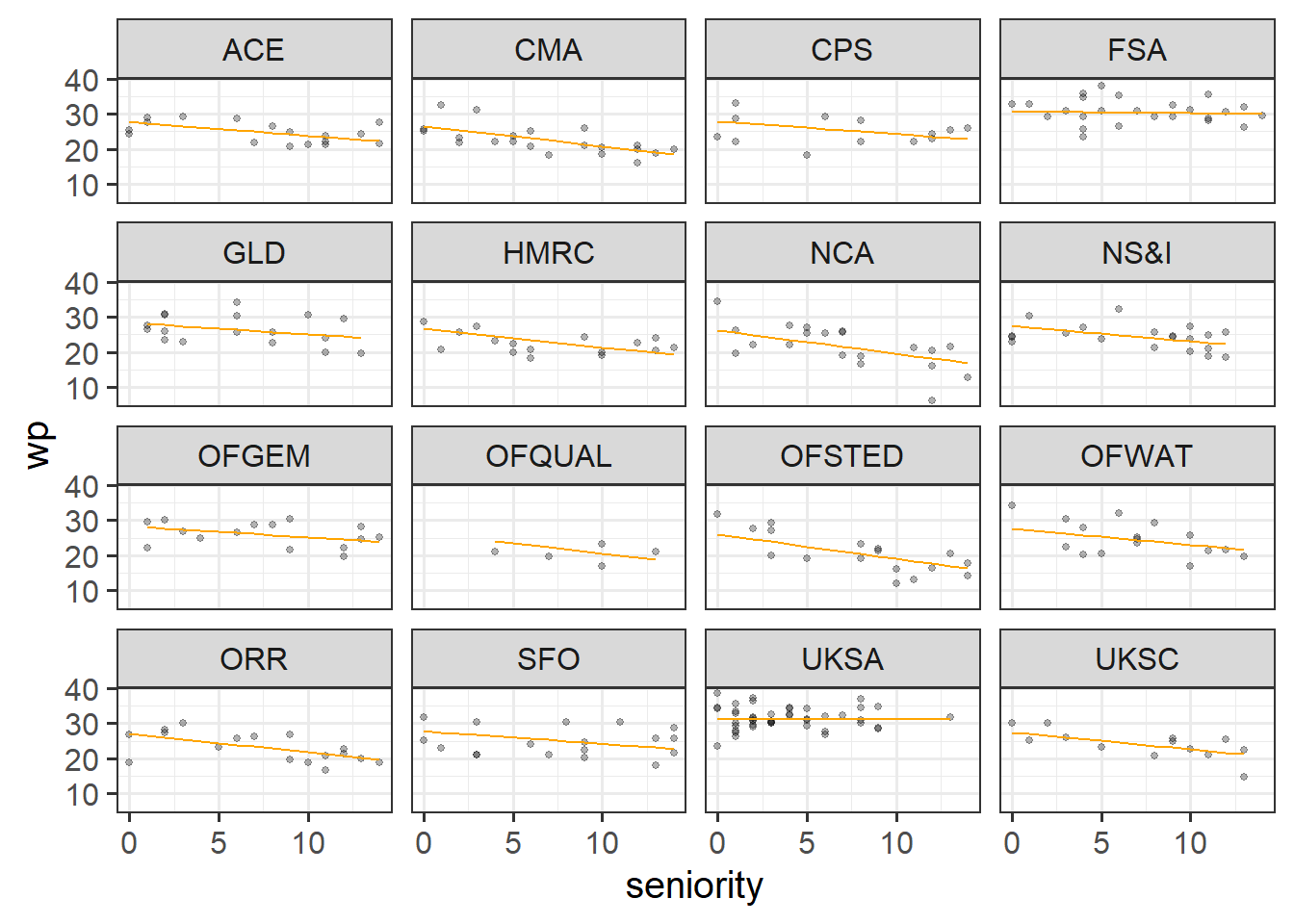
Below are 3 more code chunks that all 1) fit a model, then 2) add the fitted values of that model to the plot.
The first model is a ‘no-pooling’ approach, similar to what we did in last week’s exercises - adding in dept as a predictor.
The second and third are multilevel models. The second fits random intercepts by-department, and the third fits random intercepts and slopes of seniority.
Copy each chunk and run through the code. Pay attention to how the lines differ.
fe_mod <- lm(wp ~ dept + seniority, data = jsup)
jsup$pred_fe <- predict(fe_mod)
ggplot(jsup, aes(x = seniority)) +
geom_point(aes(y = wp), size=1, alpha=.3) +
facet_wrap(~dept) +
geom_line(aes(y=pred_fe), col = "blue")library(lme4)
ri_mod <- lmer(wp ~ seniority + (1|dept), data = jsup)
jsup$pred_ri <- predict(ri_mod)
ggplot(jsup, aes(x = seniority)) +
geom_point(aes(y = wp), size=1, alpha=.3) +
facet_wrap(~dept) +
geom_line(aes(y=pred_ri), col = "green")rs_mod <- lmer(wp ~ seniority + (1 + seniority|dept), data = jsup)
jsup$pred_rs <- predict(rs_mod)
ggplot(jsup, aes(x = seniority)) +
geom_point(aes(y = wp), size=1, alpha=.3) +
facet_wrap(~dept) +
geom_line(aes(y=pred_rs), col = "orange")
From the previous questions you should have a model called ri_mod.
Below is a plot of the fitted values from that model. Rather than having a separate facet for each department as we did above, I have put them all on one plot. The thick black line is the average intercept and slope of the departments lines.
Identify the parts of the plot that correspond to A1-4 in the summary output of the model below

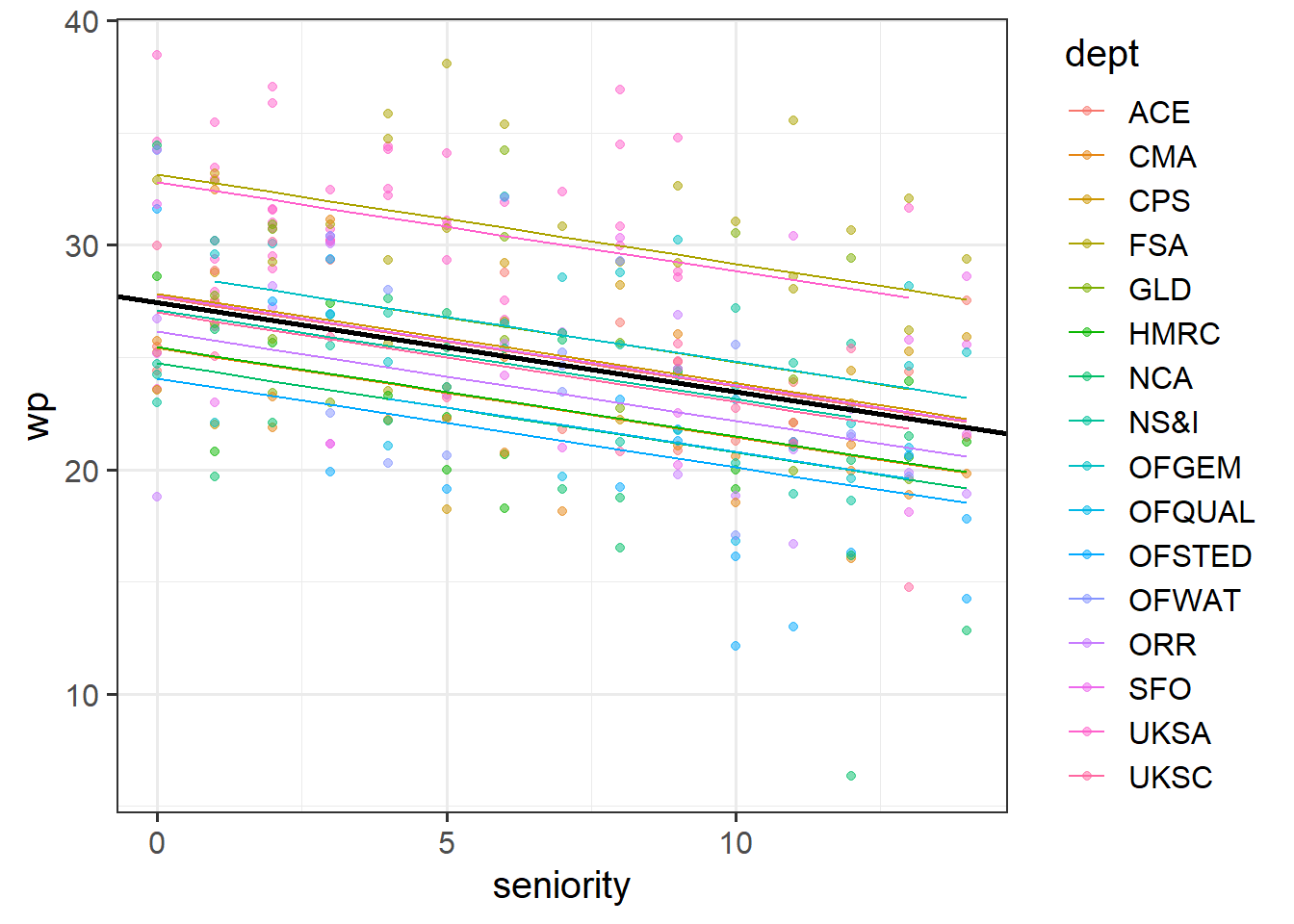
Choose from these options:
Below is the model equation for the ri_mod model.
Identify the part of the equation that represents each of A1-4.
\[\begin{align} \text{For Employee }j\text{ from Dept }i & \\ \text{Level 1 (Employee):}& \\ \text{wp}_{ij} &= b_{0i} + b_1 \cdot \text{seniority}_{ij} + \epsilon_{ij} \\ \text{Level 2 (Dept):}& \\ b_{0i} &= \gamma_{00} + \zeta_{0i} \\ \text{Where:}& \\ \zeta_{0i} &\sim N(0,\sigma_{0}) \\ \varepsilon &\sim N(0,\sigma_{e}) \\ \end{align}\]
Choose from:
This next set are a bit closer to conducting a real study. We have some data and a research question (below). The exercises will walk you through describing the data, then prompt you to think about how we might fit an appropriate model to address the research question, and finally task you with having a go at writing up what you’ve done.
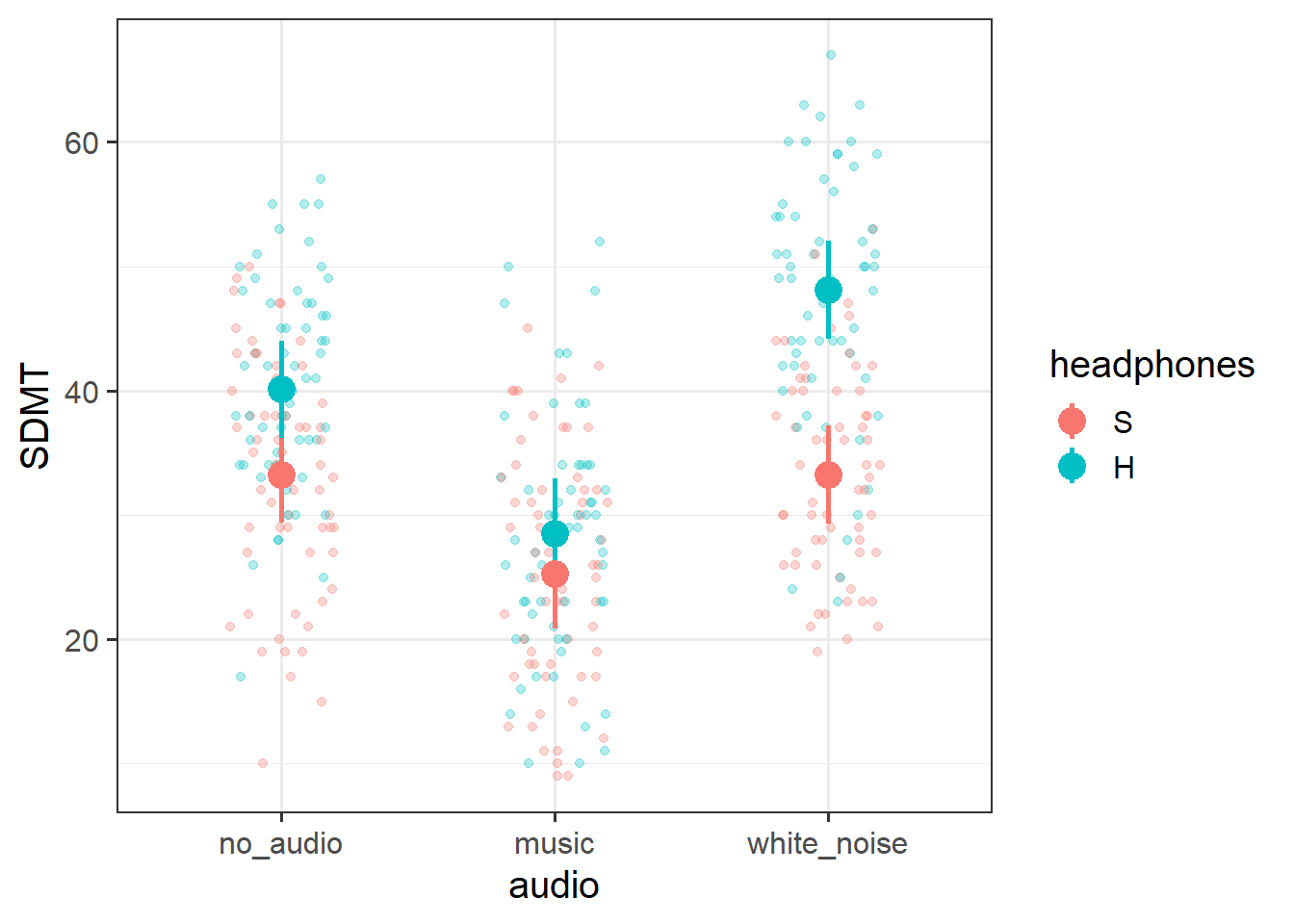
Data: Audio interference in executive functioning
This data is from a simulated study that aims to investigate the following research question:
How do different types of audio interfere with executive functioning, and does this interference differ depending upon whether or not noise-cancelling headphones are used?
30 healthy volunteers each completed the Symbol Digit Modalities Test (SDMT) - a commonly used test to assess processing speed and motor speed - a total of 15 times. During the tests, participants listened to either no audio (5 tests), white noise (5 tests) or classical music (5 tests). Half the participants listened via active-noise-cancelling headphones, and the other half listened via speakers in the room. Unfortunately, lots of the tests were not administered correctly, and so not every participant has the full 15 trials worth of data.
The data is available at https://uoepsy.github.io/data/lmm_ef_sdmt.csv.
| variable | description |
|---|---|
| PID | Participant ID |
| audio | Audio heard during the test ('no_audio', 'white_noise','music') |
| headphones | Whether the participant listened via speakers (S) in the room or via noise cancelling headphones (H) |
| SDMT | Symbol Digit Modalities Test (SDMT) score |
How many participants are there in the data?
How many have complete data (15 trials)?
What is the average number of trials that participants completed? What is the minimum?
Does every participant have some data for each type of audio?
Functions like table() and count() will likely be useful here.
How do different types of audio interfere with executive functioning, and does this interference differ depending upon whether or not noise-cancelling headphones are used?
Consider the following questions about the study:
A model that only has an intercept, i.e., y ~ 1, is called an “intercept-only model”. A multilevel model that only has an intercept but also has a grouping structure, i.e., y ~ 1 + (1|g) is called an “intercept-only model with random intercepts”. (Here g stands for an arbitrary group.)
Because there are no predictors in the fixed effects, the model only estimates one fixed parameter: the intercept. All of the variance in the outcome gets modelled in the random effects part, and is partitioned into either ‘variance between groups’ or ‘residual variance’. This means we can just use those estimates to calculate the ICC (the Intraclass Correlation Coefficient).
For our executive functioning study, fit an intercept-only model with random intercepts for the appropriate outcome variable and the appropriate grouping variable (check your responses to the last question to remind yourself what these variables are for this dataset). Use the output to calculate the ICC. Compare it to the answer you get from ICCbare() (it should be pretty close).
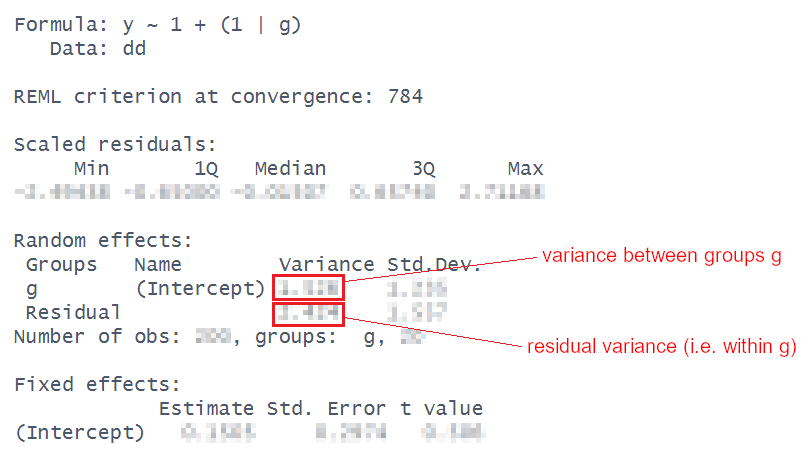
The formula for the ICC is:
\[
ICC = \frac{\sigma^2_{b}}{\sigma^2_{b} + \sigma^2_e} = \frac{\text{between-group variance}}{\text{between-group variance}+\text{within-group variance}}
\]
Make factors and set the reference levels of the audio and headphones variables to “no audio” (no_audio) and “speakers” (S) respectively.
Can’t remember about setting factors and reference levels? Check back to DAPR2!
Fit a multilevel model to address the aims of the study (copied below)
How do different types of audio interfere with executive functioning, and does this interference differ depending upon whether or not noise-cancelling headphones are used?
Specifying the model may feel like a lot, but try splitting it into three parts:
\[ \text{lmer(}\overbrace{\text{outcome }\sim\text{ fixed effects}}^1\, + \, (1 + \underbrace{\text{slopes}}_3\, |\, \overbrace{\text{grouping structure}}^2 ) \]
lm()s we have used in the past, think about what we want to test. This should provide the outcome and the structure of our fixed effects.Make sure to read about multilevel models and how to fit them in 2: MLM #multilevel-models-in-r.
We now have a model, but we don’t have any p-values or confidence intervals or anything - i.e. we have no inferential criteria on which to draw conclusions. There are a whole load of different methods available for drawing inferences from multilevel models, which means it can be a bit of a never-ending rabbit hole. For now, we’ll just use the ‘quick and easy’ approach provided by the lmerTest package seen in the lectures.
Using the lmerTest package, re-fit your model, and you should now get some p-values!
If you use library(lmerTest) to load the package, then every single model you fit will show p-values calculated with the Satterthwaite method.
Personally, I would rather this is not the case, so I often opt to fit specific models with these p-values without ever loading the package:
modp <- lmerTest::lmer(y ~ 1 + x + ....
If we want to go down the model comparison route, we just need to isolate the relevant part(s) of the model that we are interested in.
Remember, model comparison is sometimes a useful way of testing a set of coefficients. For instance, in this example the interaction involves estimating two terms: audiomusic:headphonesH and audiowhite_noise:headphonesH.
To test the interaction as a whole, we can create a model without the interaction, and then compare it. The SATmodcomp() function from the pbkrtest package provides a way of conducting an F test with the same Satterthwaite method of approximating the degrees of freedom:
sdmt_mod <- lmer(SDMT ~ audio * headphones +
(1 + audio | PID), data = efdat)
sdmt_res <- lmer(SDMT ~ audio + headphones +
(1 + audio | PID), data = efdat)
library(pbkrtest)
SATmodcomp(largeModel = sdmt_mod, smallModel = sdmt_res)large : SDMT ~ audio * headphones + (1 + audio | PID)
small : SDMT ~ audio + headphones + (1 + audio | PID)
statistic ndf ddf p.value
[1,] 11.1 2.0 26.9 0.00031 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
We’ve already seen in the example with the UK civil service employees (above and last week) that we can visualise the fitted values (model predictions). But these were plotting all the cluster-specific values, and what we are typically really interested in are the estimates of (and uncertainty around) our fixed effects (i.e. estimates for clusters on average). We say “typically” because if you study individual differences, for example, sometimes you might really care about estimating the variability within and between people! But for now, we’re going to focus on what most research questions target: the fixed effects.
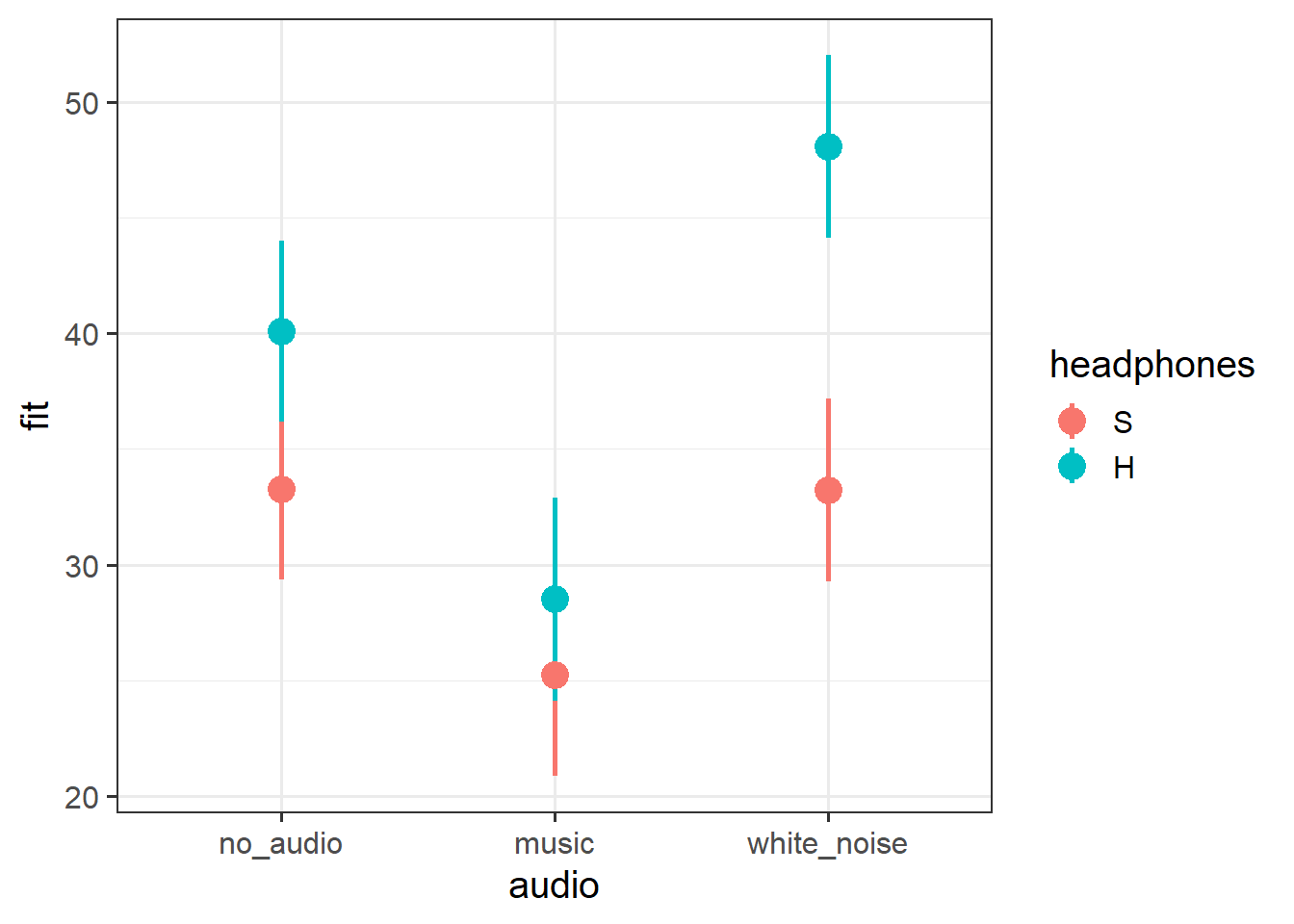
Using tools like the effects package can provide us with the values of the outcome across levels of a specific fixed predictor (holding other predictors at their mean).
Your task is to make a plot that visualises the model’s fixed effect estimates.
This should get you started:
library(effects)
effect(term = "audio*headphones", mod = sdmt_mod) |>
as.data.frame()You can see the effects package used for plotting in 2: MLM #visualising-models.
(You’ll have to use different geoms than this example does because the example involves a continuous and a categorical predictor, whereas this data set has two categorical ones.)
Now we have some p-values and a plot, try to create a short write-up of the analysis and results.
Think about the principles that have guided you during write-ups thus far.
The aim in writing a statistical report should be that a reader is able to more or less replicate your analyses without referring to your analysis code. Furthermore, it should be able for a reader to understand and replicate your work even if they use something other than R. This requires detailing all of the steps you took in conducting the analysis, but without simply referring to R code.
Here we have some extra exercises for you to practice with. There’s a bit more data cleaning involved, so we’ve made some of the solutions immediately available. Don’t worry if some of the functions are new to you - try play around with them to get a sense of how they work.
Data: lmm_apespecies.csv & lmm_apeage.csv
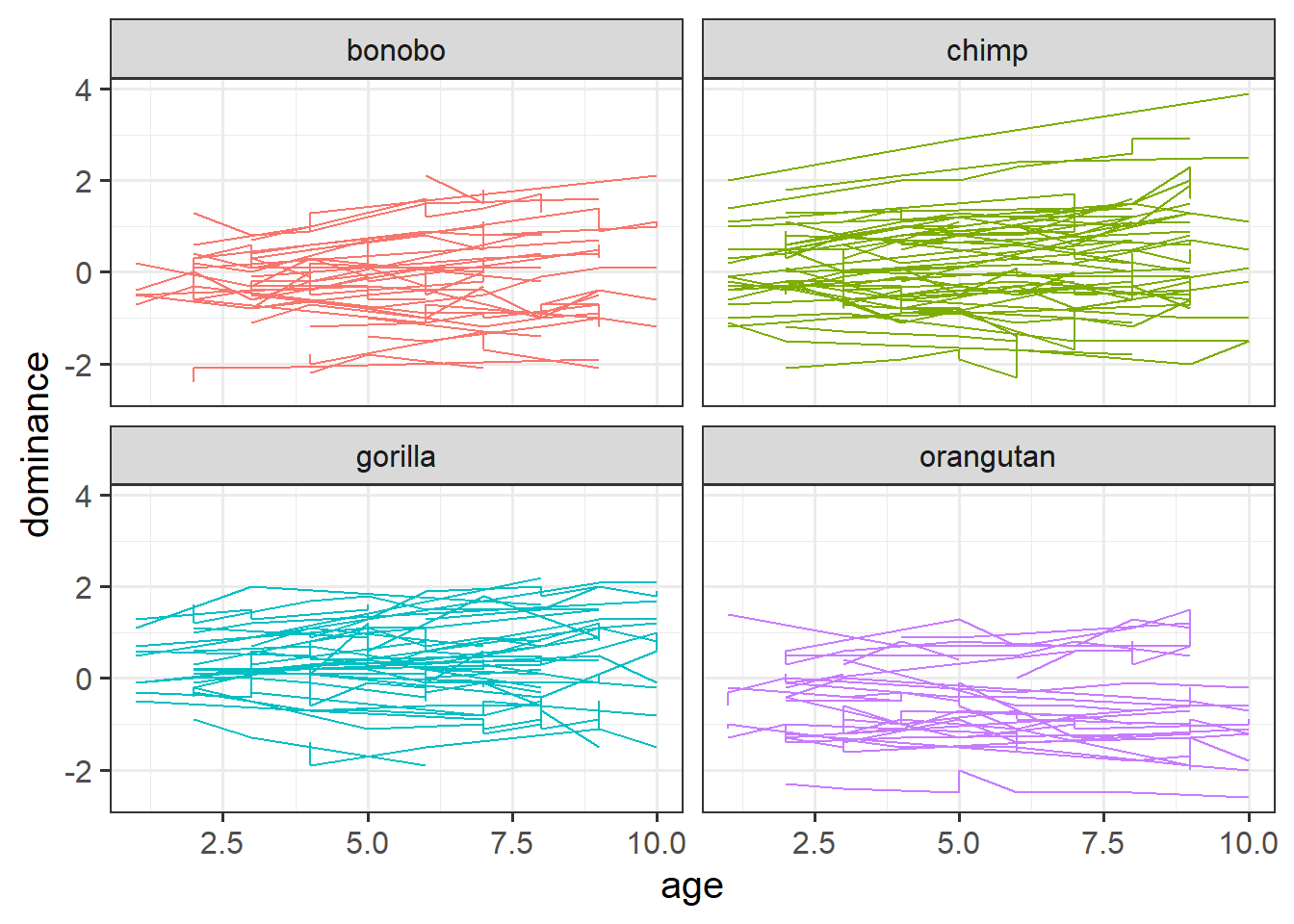
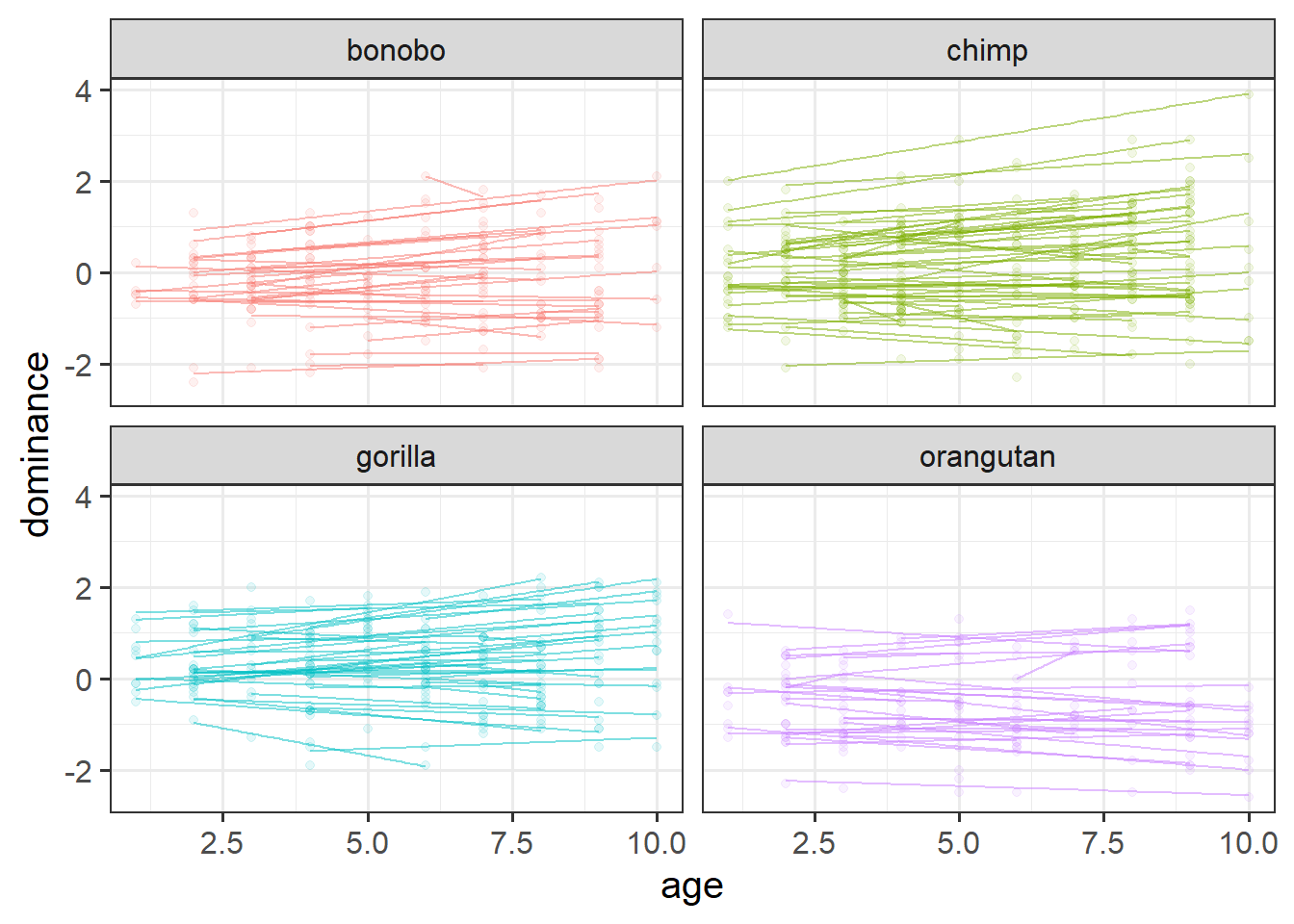
We have data from a large sample of great apes who have been studied between the ages of 1 to 10 years old (i.e. during adolescence). Our data includes 4 species of great apes: Chimpanzees, Bonobos, Gorillas and Orangutans. Each ape has been assessed on a primate dominance scale at various ages. Data collection was not very rigorous, so apes do not have consistent assessment schedules (i.e., one may have been assessed at ages 1, 3 and 6, whereas another at ages 2 and 8).
The researchers are interested in examining how the adolescent development of dominance in great apes differs between species.
Data on the dominance scores of the apes are available at https://uoepsy.github.io/data/lmm_apeage.csv and the information about which species each ape is are in https://uoepsy.github.io/data/lmm_apespecies.csv.
| variable | description |
|---|---|
| ape | Ape Name |
| species | Species (Bonobo, Chimpanzee, Gorilla, Orangutan) |
| variable | description |
|---|---|
| ape | Ape Name |
| age | Age at assessment (years) |
| dominance | Dominance (Z-scored) |
Read in the data and check over it. Do any relevant cleaning/wrangling that might be necessary to put the datasets together into a single dataframe.
How is this data structure “hierarchical” (or “clustered”)? What are our level 1 units, and what are our level 2 units?
For how many apes do we have data? How many of each species?
How many datapoints does each ape have?
We’ve seen this last week too - counting the different levels in our data. There are lots of ways to do these things - functions like count(), summary(), n_distinct(), table(), mean(), min() etc. See 1: Group Structured Data #determining-sample-sizes
Make a plot to show how dominance changes as apes get older.
You might be tempted to use facet_wrap(~ape) here, but we have too many apes! The group aesthetic will probably help instead!
The youngest age that we have data for for any of our species is 1. But it’s often useful for the value 0 to be contained within the range of a predictor’s values, because that makes interpreting all the other estimates easier. (Why? Because the intercept, and all the group-level variability in intercepts, is estimated when the predictors = 0. And if 0 is outside of the range of predictors, then we’re estimating the intercept for values that don’t really exist in our data. Mathematically possible, but hard to interpret.)
For the current analysis, let’s subtract 1 from the age variable so that the minimum value of age becomes 0. In other words, let’s shift the age variable down by 1, so that the value 0 now represents the minimum age, 1. This way, the intercept (and the group-level variability in intercepts) will be estimated for the minimum age in our dataset.
Then fit a model that estimates the differences between primate species in how dominance changes over time.
Do primate species differ in the growth of dominance?
Perform an appropriate test/comparison.
This is asking about the age*species interaction, which in our model is represented by three parameters (the interaction terms between age and each of the three non-reference-level species). To assess the overall question, it might make more sense to do a model comparison.
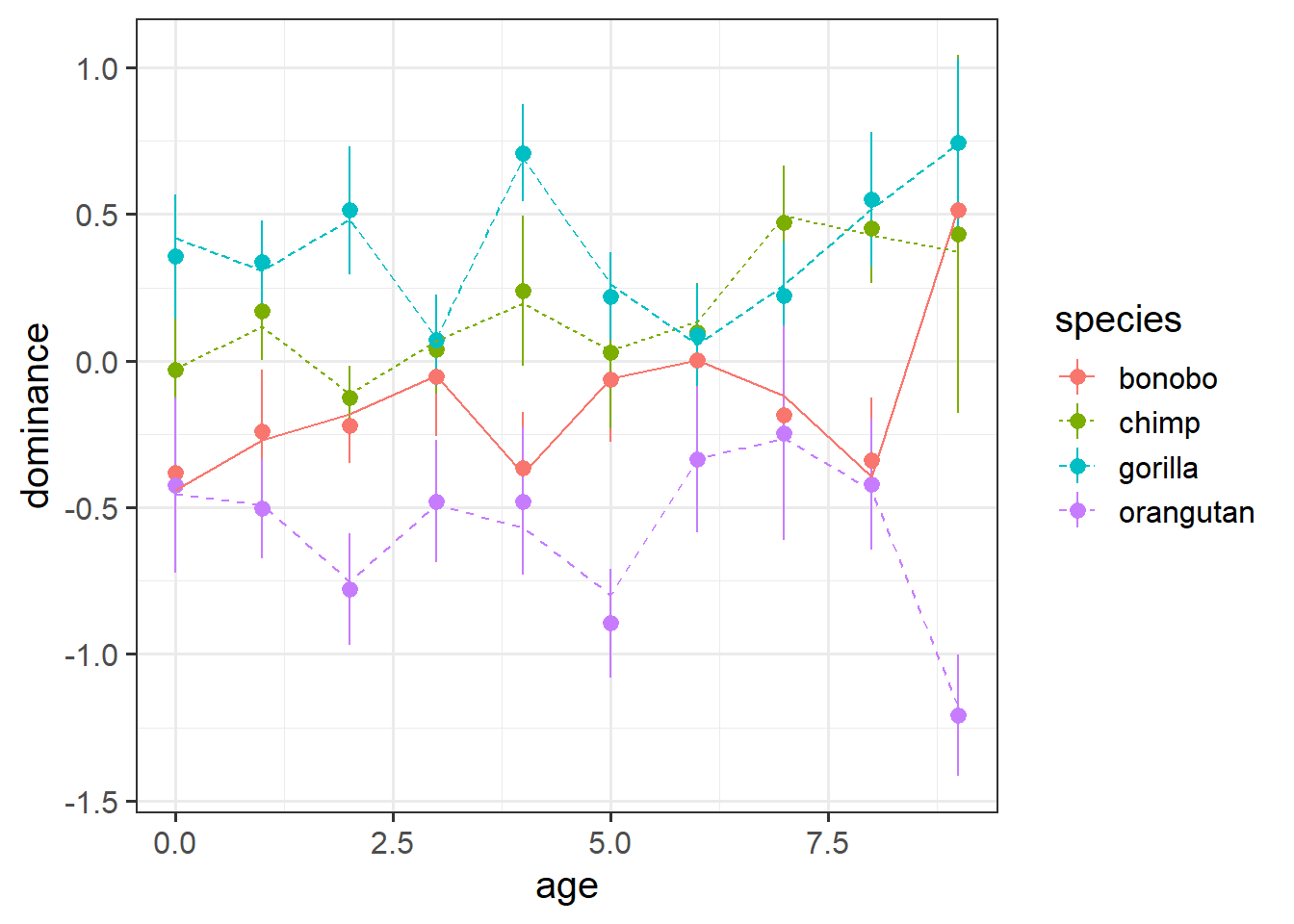
Below is code that creates a plot of the average model predicted values for each age.1
Before you run the code - do you expect to see straight lines? (remember, not every ape is measured at age 2, or age 3, etc).
library(broom.mixed)
augment(m.full) |>
ggplot(aes(age,dominance, color=species)) +
# the point ranges are our observations
stat_summary(fun.data=mean_se, geom="pointrange") +
# the lines are the average of our predictions
stat_summary(aes(y=.fitted, linetype=species), fun=mean, geom="line")
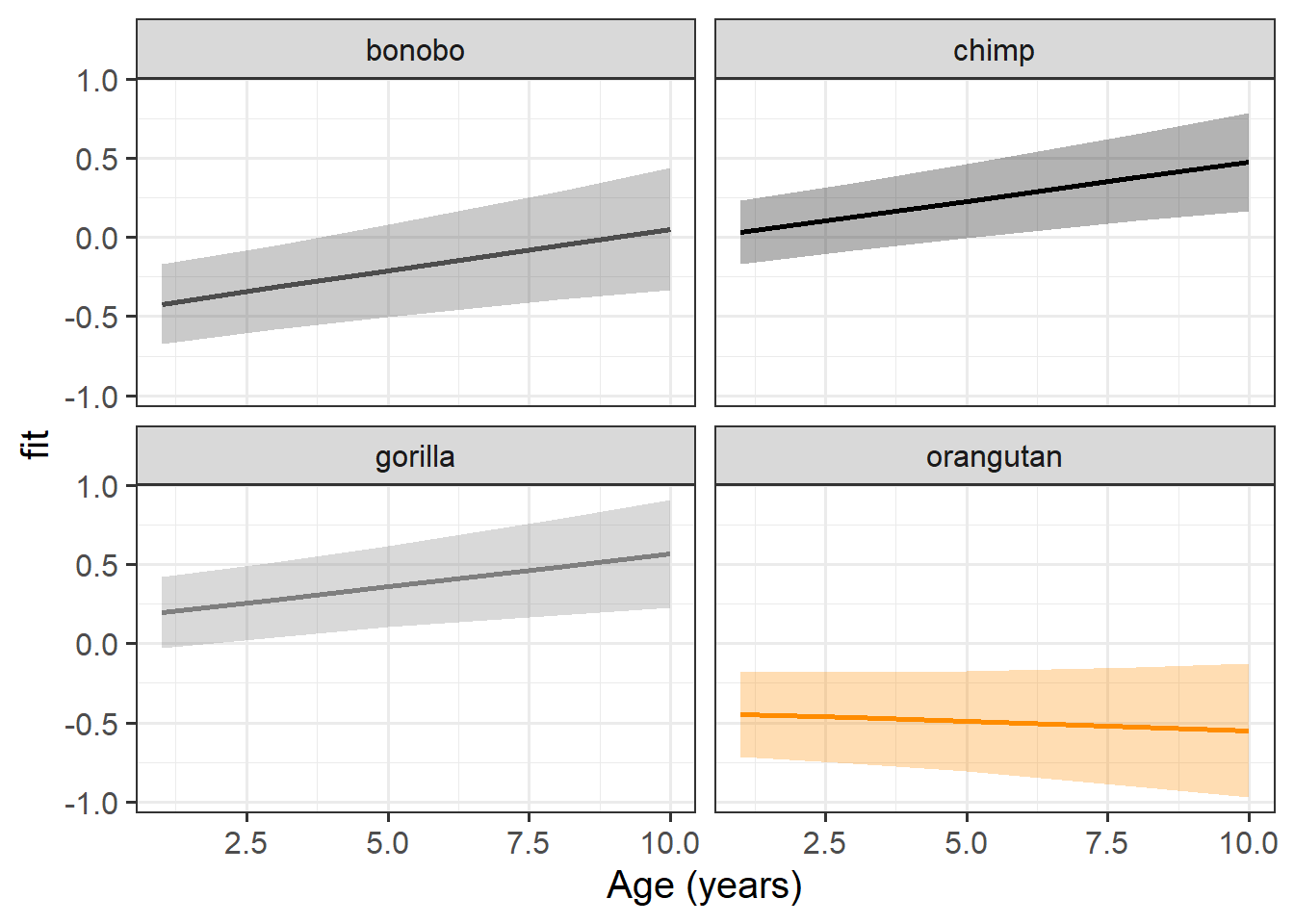
Plot the model based fixed effects.
This should get you started:
library(effects)
effect(term = "age*species", mod = m.full) |>
as.data.frame() |>
ggplot(
...
...
Interpret each of the fixed effects from the model (you might also want to get some p-values or confidence intervals).
Each of the estimates should correspond to part of our plot from the previous question.
You can either use the lmerTest::lmer() to get p-values, or why not try using confint(model) to get some confidence intervals.
This is like taking predict() from the model, and then then grouping by age, and calculating the mean of those predictions. However, we can do this more easily using augment() and then some fancy stat_summary() in ggplot↩︎
provided that the confidence intervals and p-values are constructed using the same methods↩︎