| age | outdoor_time | social_int | routine | wellbeing | location | steps_k |
|---|---|---|---|---|---|---|
| 28 | 12 | 13 | 1 | 36 | rural | 21.6 |
| 56 | 5 | 15 | 1 | 41 | rural | 12.3 |
| 25 | 19 | 11 | 1 | 35 | rural | 49.8 |
| 60 | 25 | 15 | 0 | 35 | rural | NA |
| 19 | 9 | 18 | 1 | 32 | rural | 48.1 |
| 34 | 18 | 13 | 1 | 34 | rural | 67.3 |
Multiple Linear Regression
Learning Objectives
At the end of this lab, you will:
- Extend the ideas of single linear regression to consider regression models with two or more predictors
- Understand and interpret the coefficients in multiple linear regression models
Requirements
Required R Packages
Remember to load all packages within a code chunk at the start of your RMarkdown file using library(). If you do not have a package and need to install, do so within the console using install.packages(" "). For further guidance on installing/updating packages, see Section C here.
For this lab, you will need to load the following package(s):
- tidyverse
- patchwork
- sjPlot
- kableExtra
Lab Data
You can download the data required for this lab here or read it in via this link https://uoepsy.github.io/data/wellbeing.csv.
Study Overview
Research Question
Is there an association between wellbeing and time spent outdoors after taking into account the association between wellbeing and social interactions?
Setup
Setup
- Create a new RMarkdown file
- Load the required package(s)
- Read the wellbeing dataset into R, assigning it to an object named
mwdata
Exercises
Study & Analysis Plan Overview
Question 1
Provide a brief overview of the study design and data, before detailing your analysis plan to address the research question.
Hint
- Give the reader some background on the context of the study (you might be able to re-use some of the content you wrote for Lab 1 here)
- State what type of analysis you will conduct in order to address the research question
- Specify the model to be fitted to address the research question
- Specify your chosen significance (\(\alpha\)) level
- State your hypotheses
Descriptive Statistics
Question 2
Alongside descriptive statistics, visualize the marginal distributions of the wellbeing, outdoor_time, and social_int variables.
Hint
Plot interpretation
- The shape, center and spread of the distribution - Whether the distribution is symmetric or skewed - Whether the distribution is unimodal or bimodal
Plotting tips
- Use \n to wrap text in your titles and or axis labels - The patchwork package allows us to arrange multiple plots in two ways - | arranges the plots adjacent to one another, and / arranges the plots on top of one another
Table tips
- The kableExtra package allows us to produce well formatted tables for our descriptive statistics. To do so, you need to specify the kable() and kable_styling() arguments
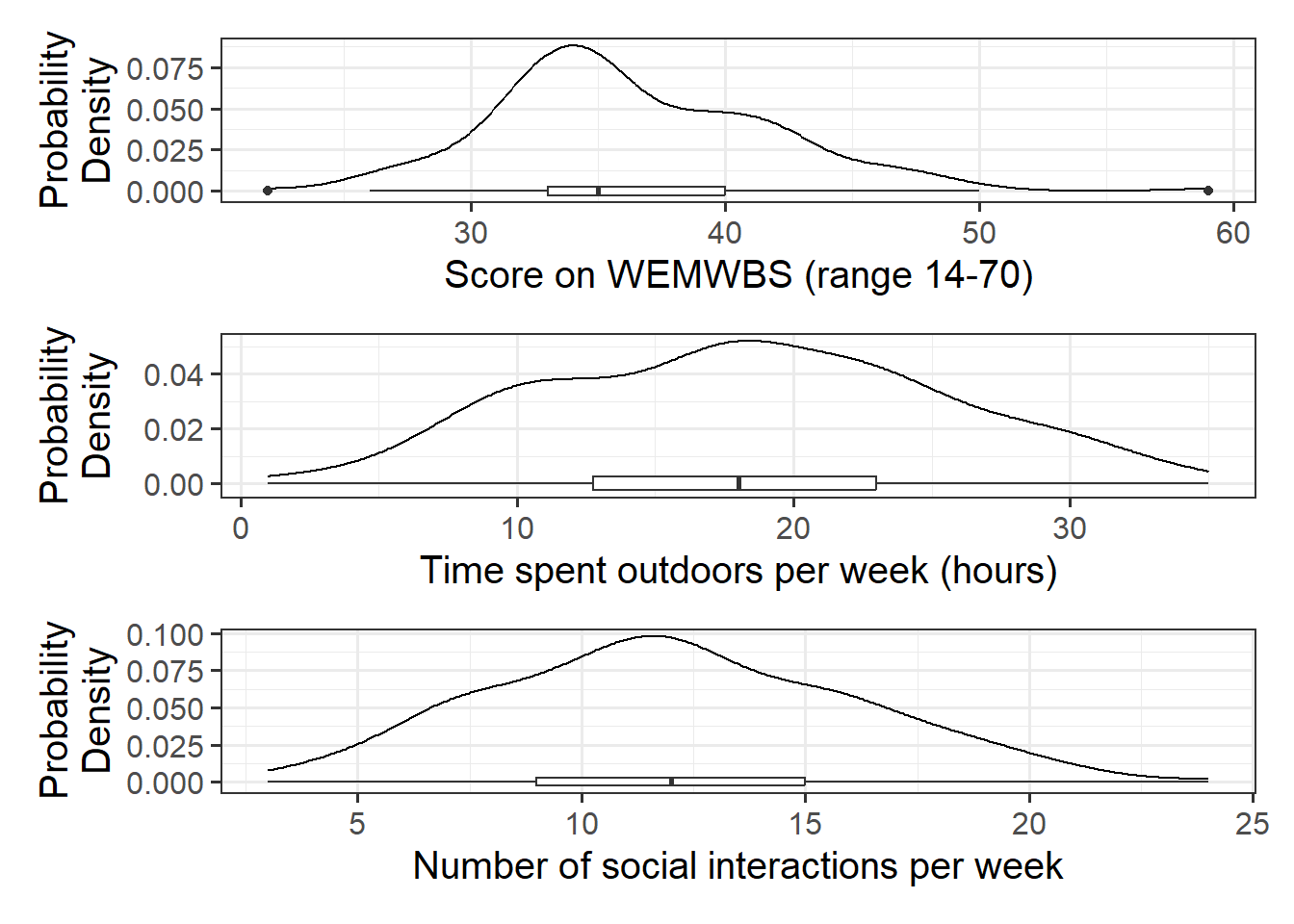
Question 3
Produce plots of the associations between the outcome variable (wellbeing) and each of the explanatory variables.
Hint
Plot interpretation
- Direction of association - Form of association (can it be summarised well with a straight line?)
- Strength of association (how closely do points fall to a recognizable pattern such as a line?) - Unusual observations that do not fit the pattern of the rest of the observations and which are worth examining in more detail
Plot tips
- use \n to wrap text in your titles and or axis labels - consider using geom_smooth() to superimpose the best-fitting line describing the association of interest

Question 4
Produce a correlation matrix of the variables which are to be used in the analysis, and write a short paragraph describing the associations.
Hint
Correlation Matrix
Review Q2 of your Week 1 lab for guidance on how to produce a correlation matrix.
APA Format
Make sure to round your numbers in-line with APA 7th edition guidelines. The round() function will come in handy here, as might this APA numbers and statistics guide!
Model Fitting & Interpretation
Question 5
Recall the model specified in Q1, and:
- State the parameters of the model. How do we denote parameter estimates?
- Fit the linear model in using
lm(), assigning the output to an object calledmdl1.
Hint
As we did for simple linear regression, we can fit our multiple regression model using the lm() function. We can add as many explanatory variables as we like, separating them with a +.
model_name <- lm(<response variable> ~ 1 + <explanatory variable 1> + <explanatory variable 2> + ... , data = <dataframe>)
Visual
Note that for simple linear regression we talked about our model as a line in 2 dimensions: the systematic part \(\beta_0 + \beta_1 x\) defined a line for \(\mu_y\) across the possible values of \(x\), with \(\epsilon\) as the random deviations from that line. But in multiple regression we have more than two variables making up our model.
In this particular case of three variables (one outcome + two explanatory), we can think of our model as a regression surface (see Figure 3). The systematic part of our model defines the surface across a range of possible values of both \(x_1\) and \(x_2\). Deviations from the surface are determined by the random error component, \(\hat \epsilon\).
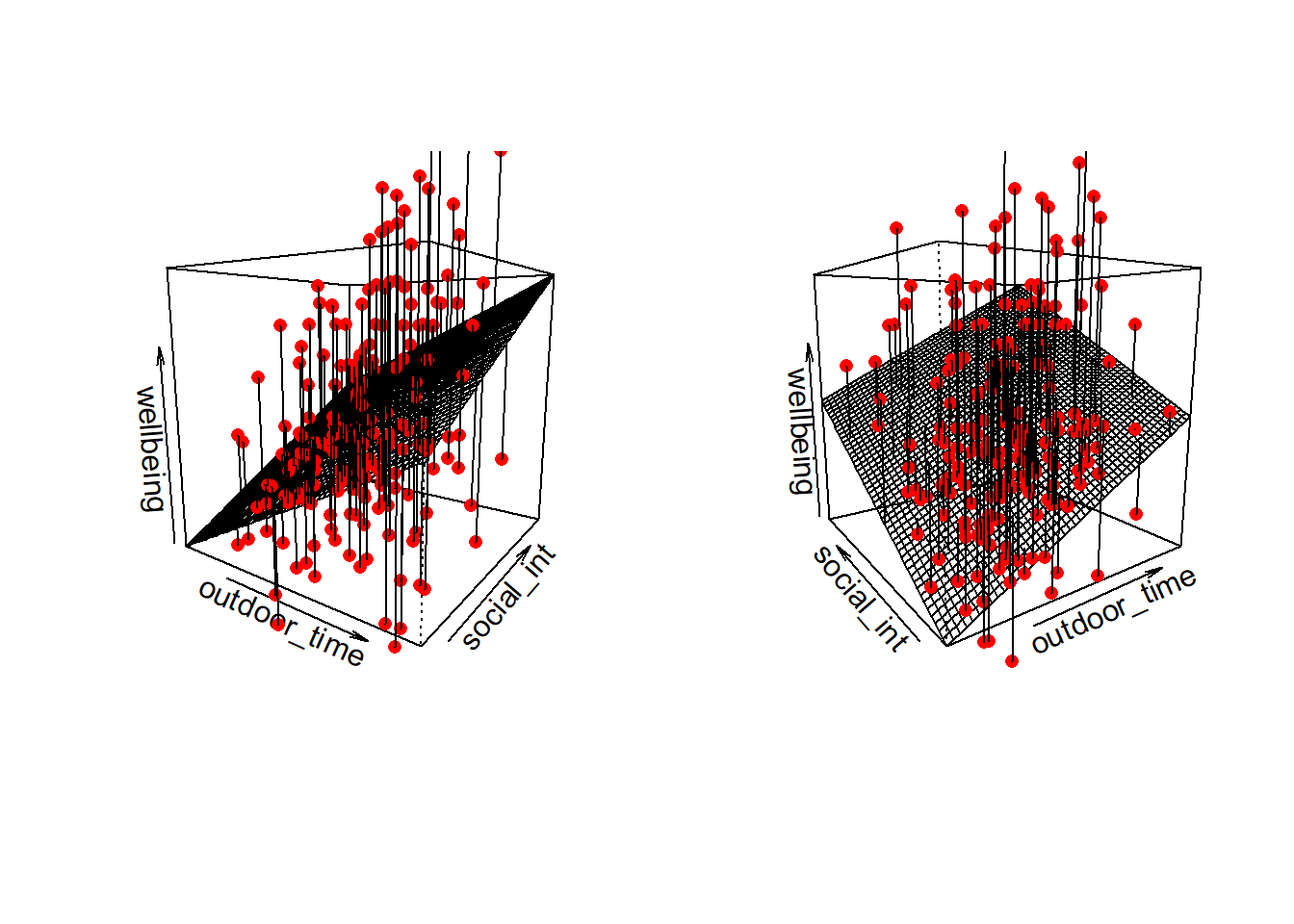
Don’t worry about trying to figure out how to visualise it if we had any more explanatory variables! We can only concieve of 3 spatial dimensions. One could imagine this surface changing over time, which would bring in a 4th dimension, but beyond that, it’s not worth trying!.
Question 6
Using any of:
mdl1mdl1$coefficientscoef(mdl1)coefficients(mdl1)summary(mdl1)
Write out the estimated parameter values of:
-
\(\hat \beta_0\), the estimated average wellbeing score associated with zero hours of outdoor time and zero social interactions per week.
-
\(\hat \beta_1\), the estimated increase in average wellbeing score associated with an additional social interaction per week (an increase of one), holding weekly outdoor time constant.
- \(\hat \beta_2\), the estimated increase in average wellbeing score associated with one hour increase in weekly outdoor time, holding the number of social interactions constant
Note
Q: What do we mean by hold constant / controlling for / partialling out / residualizing for?
A: When the remaining explanatory variables are held at the same value or are fixed.
Question 7
Within what distance from the model predicted values (the regression line) would we expect 95% of WEMWBS wellbeing scores to be?
Question 8
Based on the model, predict the wellbeing scores for the following individuals:
- Leah: Social Interactions = 25; Outdoor Time = 3
- Sean: Social Interactions = 19; Outdoor Time = 36
- Mike: Social Interactions = 15; Outdoor Time = 20
- Donna: Social Interactions = 7; Outdoor Time = 1
Who has the highest predicted wellbeing score, and who has the lowest?
Writing Up & Presenting Results
Question 9
Provide key model results in a formatted table.
Question 10
Interpret your results in the context of the research question.
Make reference to the your regression table.
Hint
Make sure to include a decision in relation to your null hypothesis - based on the evidence, should you reject or fail to reject the null?