In this lesson we will work with some of the data from the Gapminder project. This data are available via an R package, which you will need to install in R.
First, install the gapminder package. Then load the gapminder package and the tidyverse package as we will need its functionality to work with data.
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.2 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.5.0.9000 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
✔ purrr 1.0.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
The gapminder package provides you with a data table having the same name as the package (unfortunately).
Let’s inspect the contents of the data using the glimpse function from tidyverse:
The output tells us that the Gapminder data contain 1704 rows and 6 columns.
An alternative to glimpse() is the str() function, showing the structure of the data
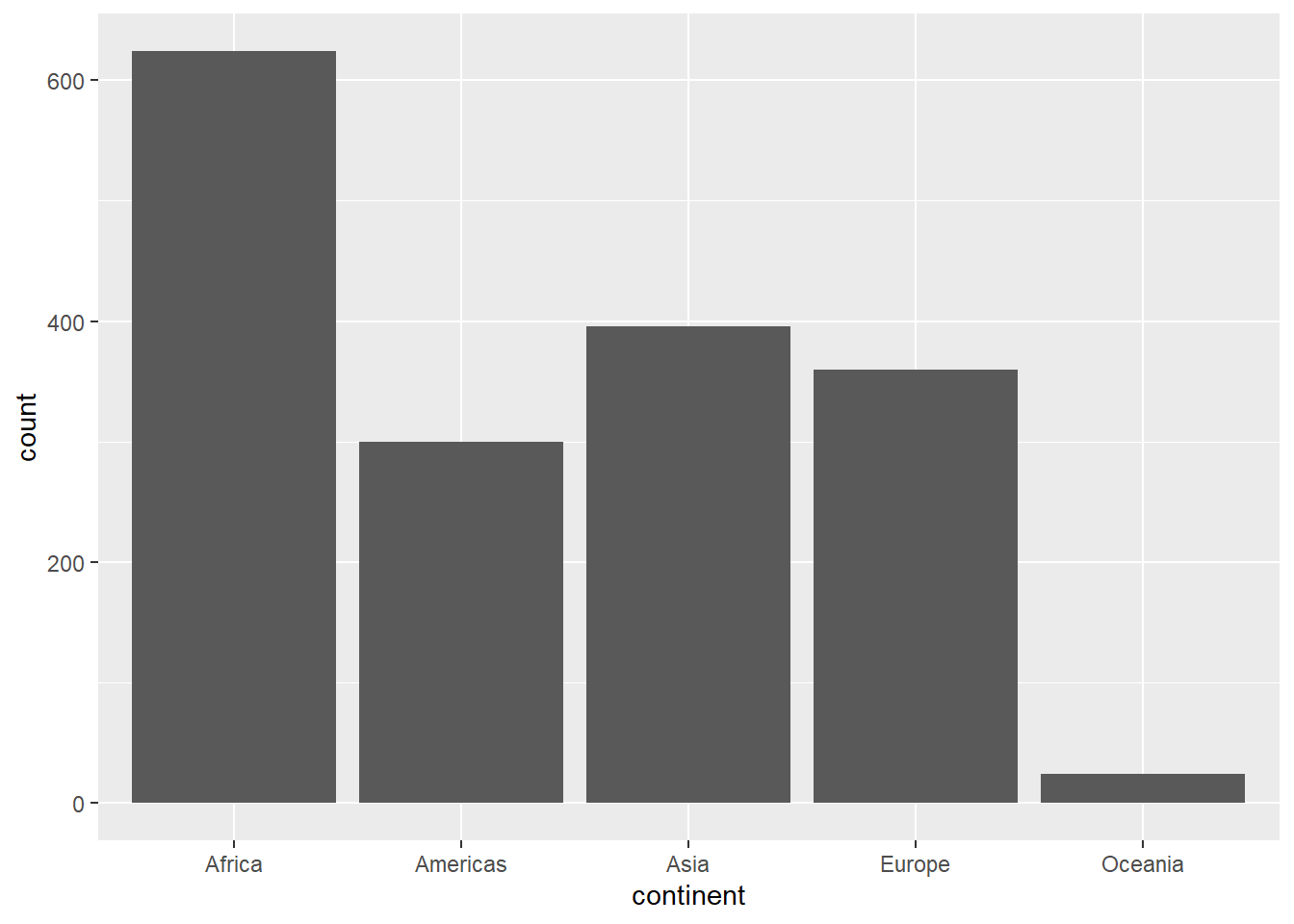
country continent year lifeExp
Afghanistan: 12 Africa :624 Min. :1952 Min. :23.60
Albania : 12 Americas:300 1st Qu.:1966 1st Qu.:48.20
Algeria : 12 Asia :396 Median :1980 Median :60.71
Angola : 12 Europe :360 Mean :1980 Mean :59.47
Argentina : 12 Oceania : 24 3rd Qu.:1993 3rd Qu.:70.85
Australia : 12 Max. :2007 Max. :82.60
(Other) :1632
pop gdpPercap
Min. :6.001e+04 Min. : 241.2
1st Qu.:2.794e+06 1st Qu.: 1202.1
Median :7.024e+06 Median : 3531.8
Mean :2.960e+07 Mean : 7215.3
3rd Qu.:1.959e+07 3rd Qu.: 9325.5
Max. :1.319e+09 Max. :113523.1
Look at some variables individually
Let’s start by looking at the year variable. Clearly, we are not running the following code otherwise we will get 1704 values printed out and it will be impossible to make any sense of that!
# Don't run this, or you will get 1704 values printed!gapminder$year
Instead we will use head() to see the first few values:
Min. 1st Qu. Median Mean 3rd Qu. Max.
1952 1966 1980 1980 1993 2007
Next, we can compute how many times each year appears in the data. This is also called a frequency table, as it shows the absolute frequency (or count) of how many times each year is present in the data:
`summarise()` has grouped output by 'continent'. You can override using the
`.groups` argument.
gapminder_cont
# A tibble: 60 × 3
# Groups: continent [5]
continent year mean_life_exp
<fct> <int> <dbl>
1 Africa 1952 39.1
2 Africa 1957 41.3
3 Africa 1962 43.3
4 Africa 1967 45.3
5 Africa 1972 47.5
6 Africa 1977 49.6
7 Africa 1982 51.6
8 Africa 1987 53.3
9 Africa 1992 53.6
10 Africa 1997 53.6
# ℹ 50 more rows
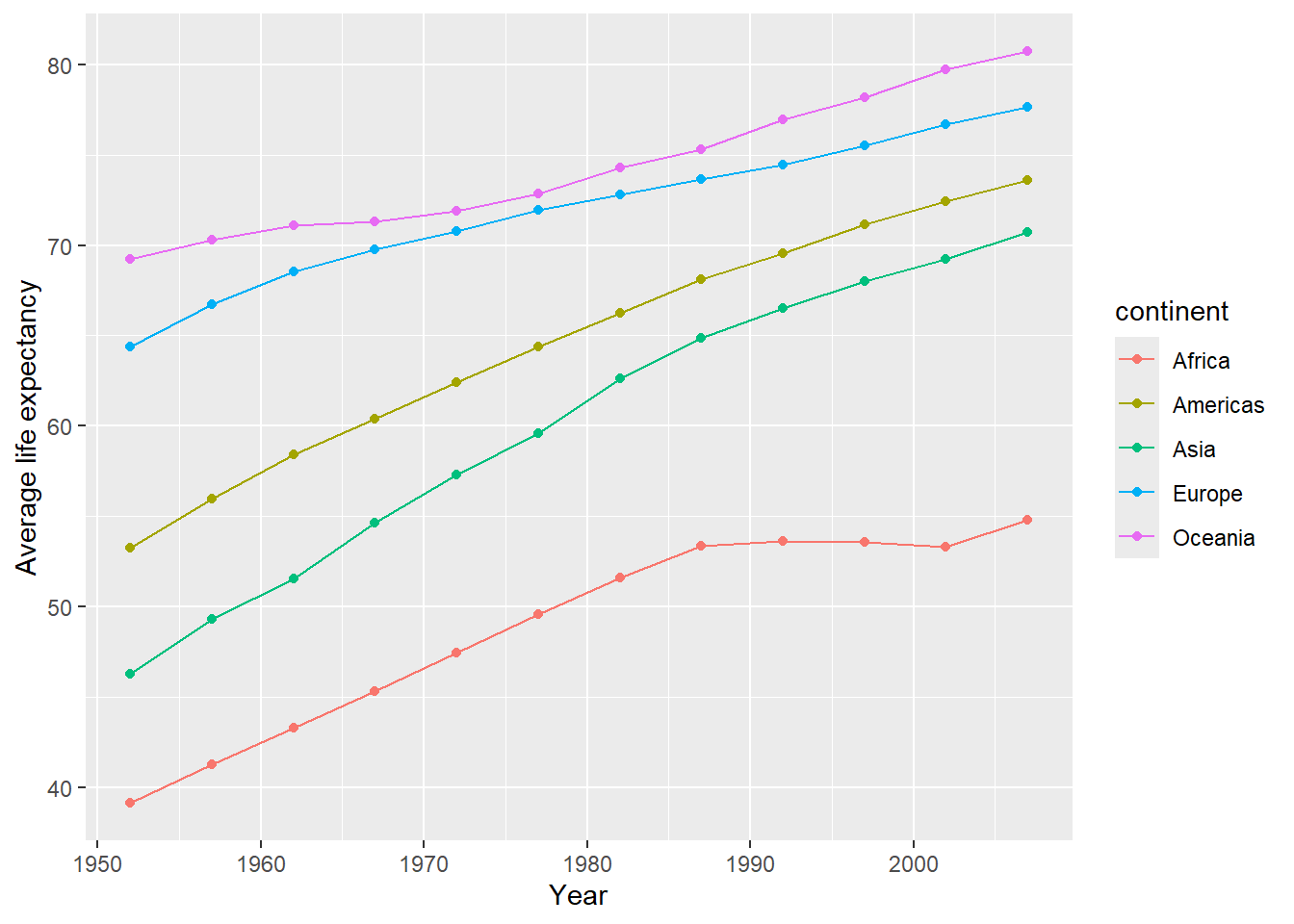
ggplot(data =gapminder_cont, aes(x =year, y =mean_life_exp, color =continent))+geom_point()+geom_line()+labs(x ='Year', y ='Average life expectancy')
Wow! this plot is definitely much more informative than all that huge table of numbers you get from View(gapminder).
From the plot we can see the increasing trend over time of average life expectancy in each continent, and we see that Oceania consistently had the highest average life expectancy than any other country, while Africa had the lowest.
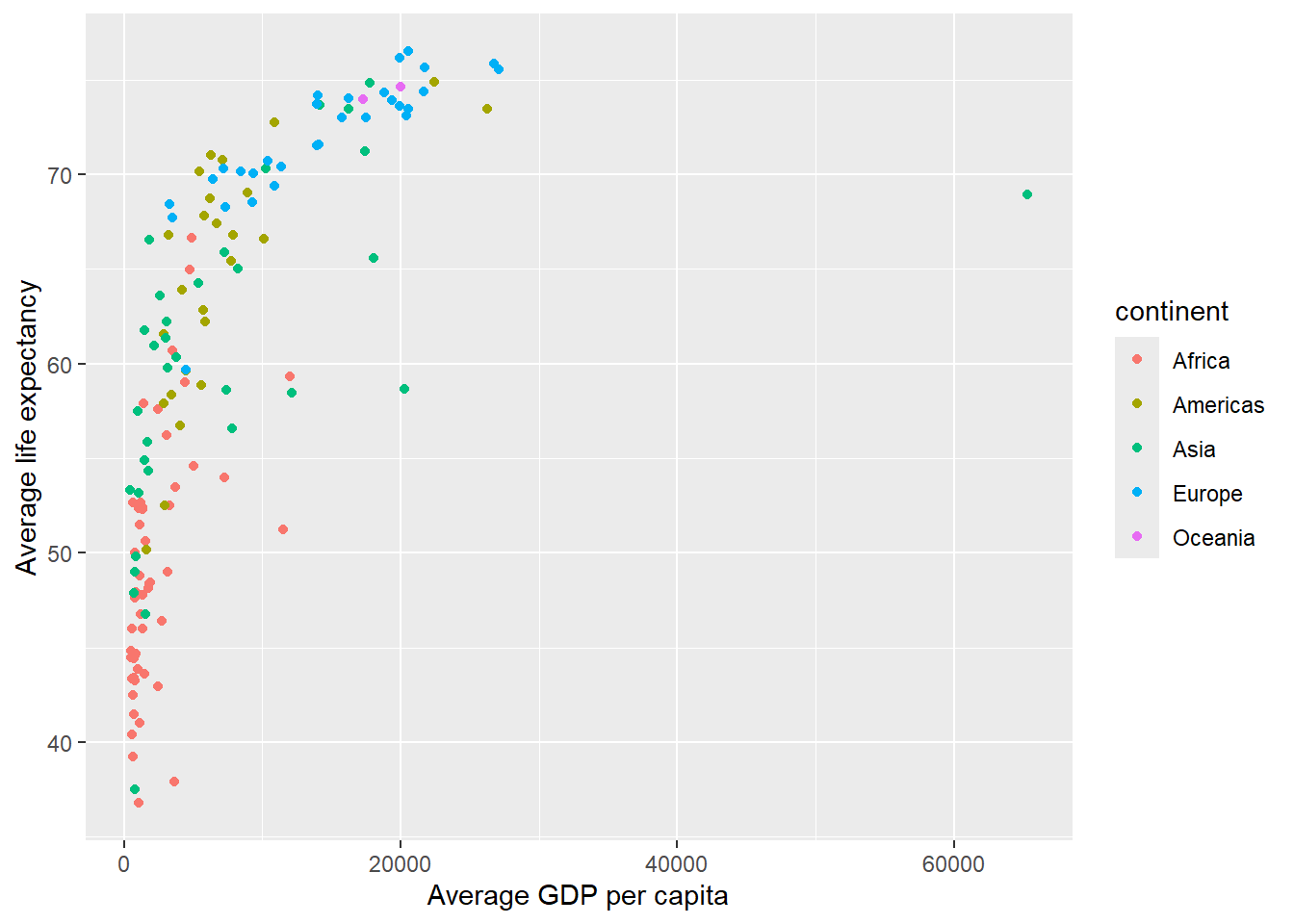
Group the Gapminder data by continent and country, and compute for each the average (over the different years) life expectancy and average GDP per capita.
Create a plot where each country is shown as a point, the x-axis has the average GDP per capita, the y-axis the average life expectancy, and the points are coloured by continent.
`summarise()` has grouped output by 'continent'. You can override using the
`.groups` argument.
gapminder_le_gdp
# A tibble: 142 × 4
# Groups: continent [5]
continent country mean_le mean_gdp
<fct> <fct> <dbl> <dbl>
1 Africa Algeria 59.0 4426.
2 Africa Angola 37.9 3607.
3 Africa Benin 48.8 1155.
4 Africa Botswana 54.6 5032.
5 Africa Burkina Faso 44.7 844.
6 Africa Burundi 44.8 472.
7 Africa Cameroon 48.1 1775.
8 Africa Central African Republic 43.9 959.
9 Africa Chad 46.8 1165.
10 Africa Comoros 52.4 1314.
# ℹ 132 more rows
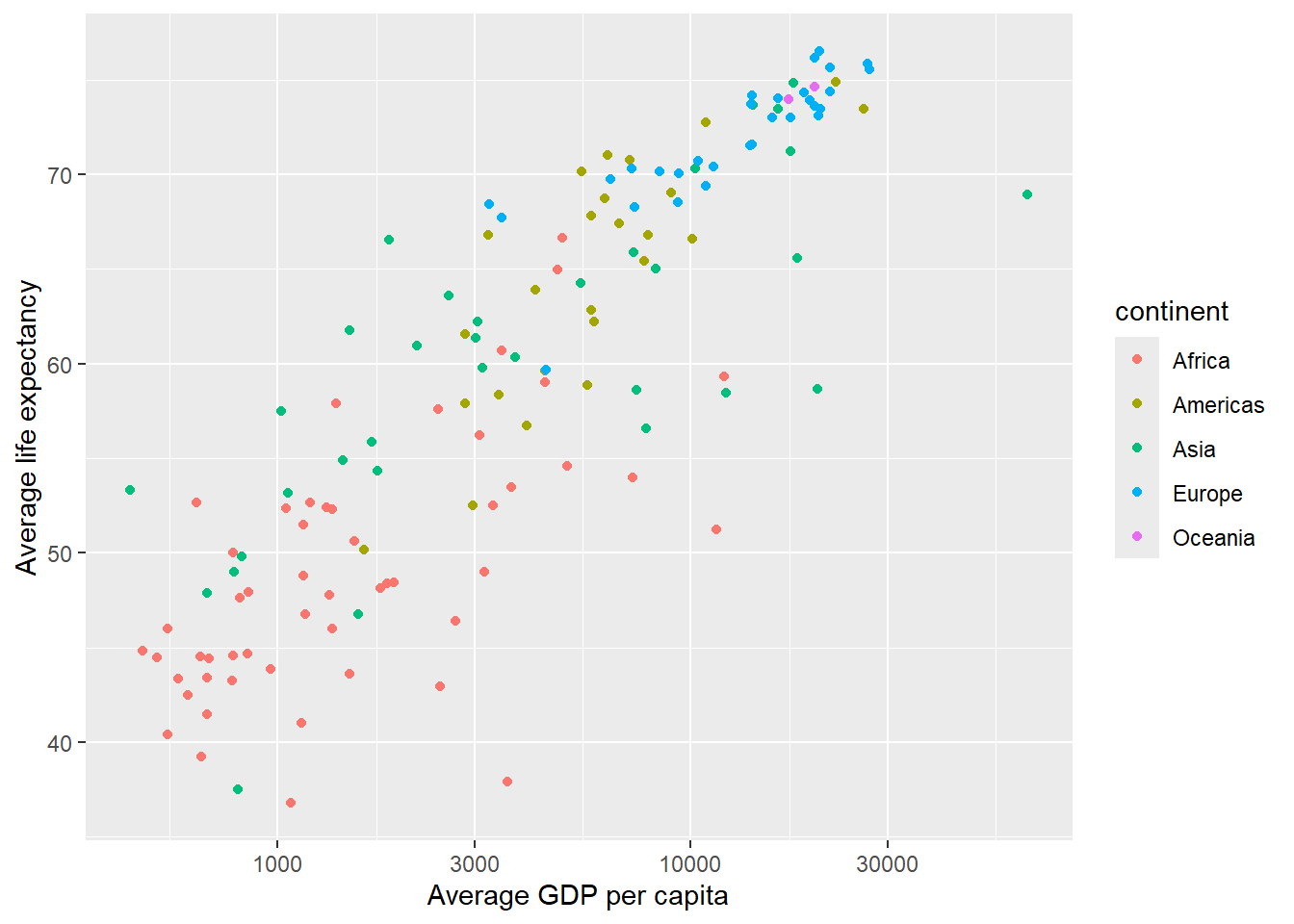
ggplot(data =gapminder_le_gdp,aes(x =mean_gdp, y =mean_le, color =continent))+geom_point()+labs(x ='Average GDP per capita', y ='Average life expectancy')
To make it easier to read, we can change the x-axis to increase in powers of 10.
ggplot(data =gapminder_le_gdp,aes(x =mean_gdp, y =mean_le, color =continent))+geom_point()+scale_x_log10()+labs(x ='Average GDP per capita', y ='Average life expectancy')