Correlations
Univariate Statistics and Methodology using R
Blood Alcohol and Reaction Time
- data from 100 drivers
- are blood alcohol and RT (linearly) related?

A Simplified Case



- does \(y\) vary linearly with \(x\)?
- equivalent to asking “does \(y\) differ from its mean in the same way that \(x\) does?”
Covariance

- it’s likely the variables are related if observations differ proportionately from their means
Correlation Coefficient
measure of how related two variables are
\(-1 \le r \le 1\) (\(\pm 1\) = perfect fit; \(0\) = no fit)
\[ r=0.4648 \]

\[ r=-0.4648 \]
What Does the Value of r Mean?

Significance of a Correlation
\[ r = 0.4648 \]

Random Correlations
pick some pairs of numbers at random, return correlation
- repeat 1000 times
randomCor <- function(size) {
x <- runif(size, min = 0,
max = 100)
y <- runif(size, min = 0,
max = 100)
cor(x, y) # calculate r
}
# then we can use the
# usual trick:
rs <- replicate(1000, randomCor(5))
hist(rs)
Random Correlations


Calculating Probability


- distribution of random \(r\)s is \(t\) distribution, with \(n-2\) df
\[t= r\sqrt{\frac{n-2}{1-r^2}}\]
- makes it “easy” to calculate probability of getting \(\ge{}r\) for sample size \(n\) by chance
Calculating Probability
calculate \(t\)
r_to_t <- function (r,n) {
r * sqrt((n-2) / (1-r^2))
}
r_to_t(0.4648, 50)[1] 3.637calculate \(p\)
2 * pt(3.637, 48, lower.tail=F)[1] 0.0006727- note
2 * pt(...)as this is a two-tailed hypothesis
\[r=0.4648\]
or just be lazy
cor.test(dat$BloodAlc, dat$RT)
Pearson's product-moment correlation
data: dat$BloodAlc and dat$RT
t = 3.6, df = 48, p-value = 0.0007
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.2141 0.6580
sample estimates:
cor
0.4648 Back on the Road

\[r= 0.4648, p = 0.0007\]

reaction time is positively associated with blood alcohol
not a very complete picture
how much does alcohol affect RT?
The Only Equation You Will Ever Need
\[\color{red}{\textrm{outcome}_i} = (\textrm{model})_i + \textrm{error}_i\]

The Only Equation You Will Ever Need
\[\color{red}{\textrm{outcome}_i} = \color{blue}{(\textrm{model})_i} + \textrm{error}_i\]

The Only Equation You Will Ever Need
\[\color{red}{\textrm{outcome}_i} = \color{blue}{(\textrm{model})_i} + \textrm{error}_i\]

The Only Equation You Will Ever Need
\[\color{red}{\textrm{outcome}_i} = \color{blue}{(\textrm{model})_i} + \textrm{error}_i\]

The Aim of the Game
\[\color{red}{\textrm{outcome}_i} = \color{blue}{(\textrm{model})_i} + \textrm{error}_i\]

maximise the explanatory worth of the model
minimise the amount of unexplained error
explain more than one outcome!
We need to make assumptions
- model is linear
- errors are from a normal distribution






A Linear Model
- defined by two properties
- height of the line (intercept)
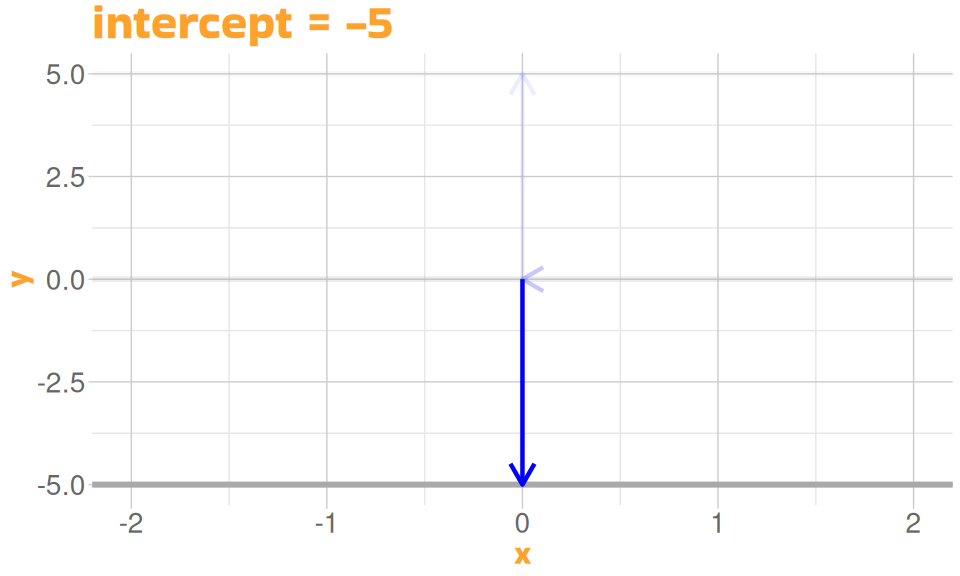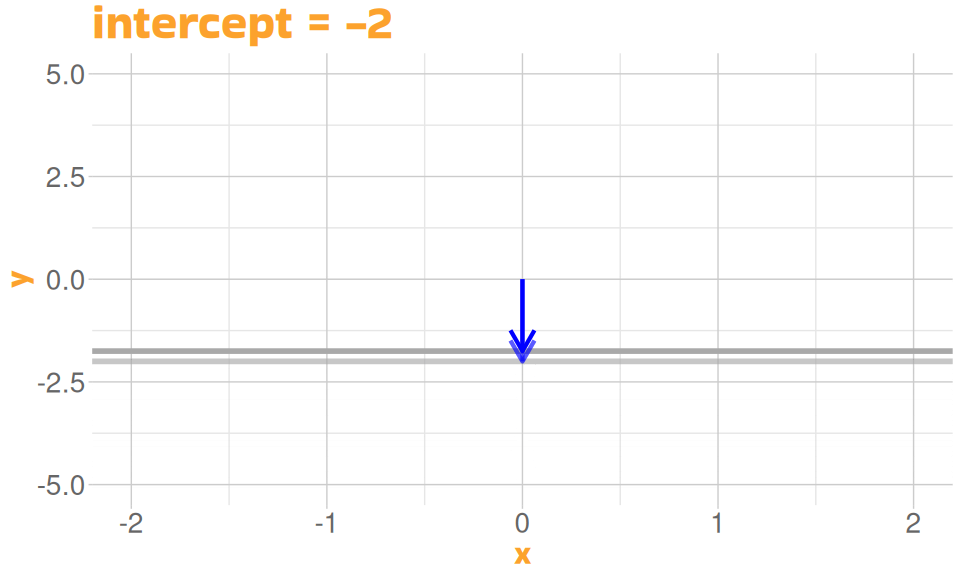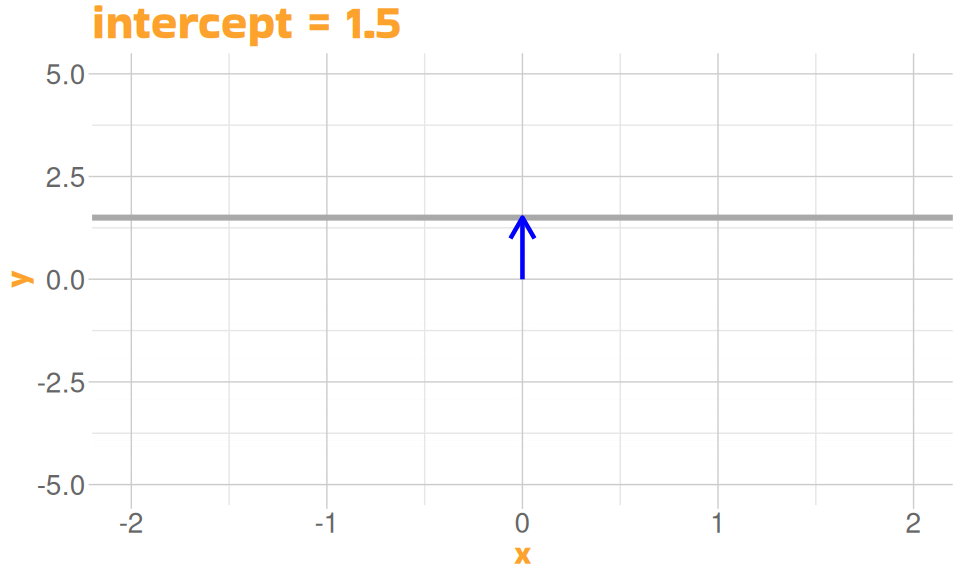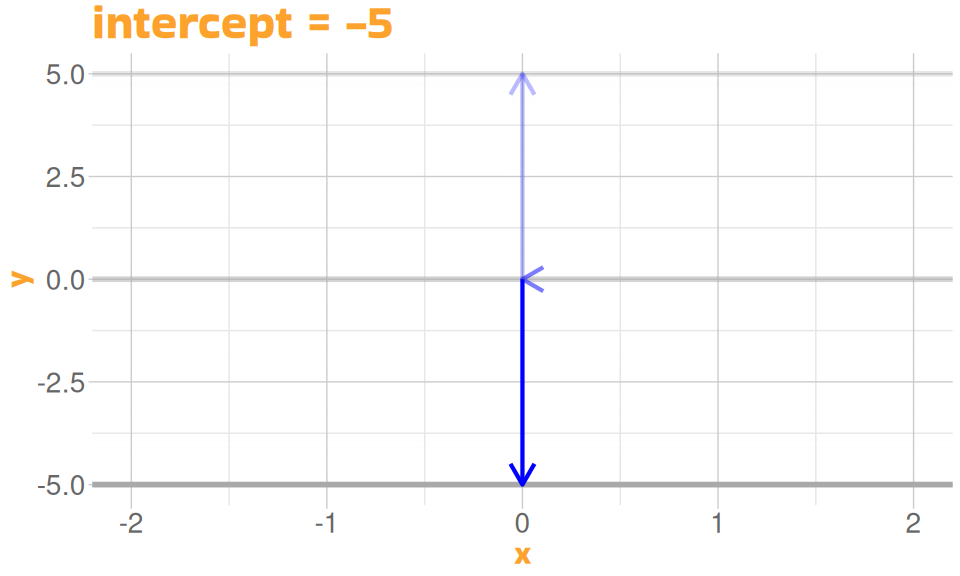
- slope of the line
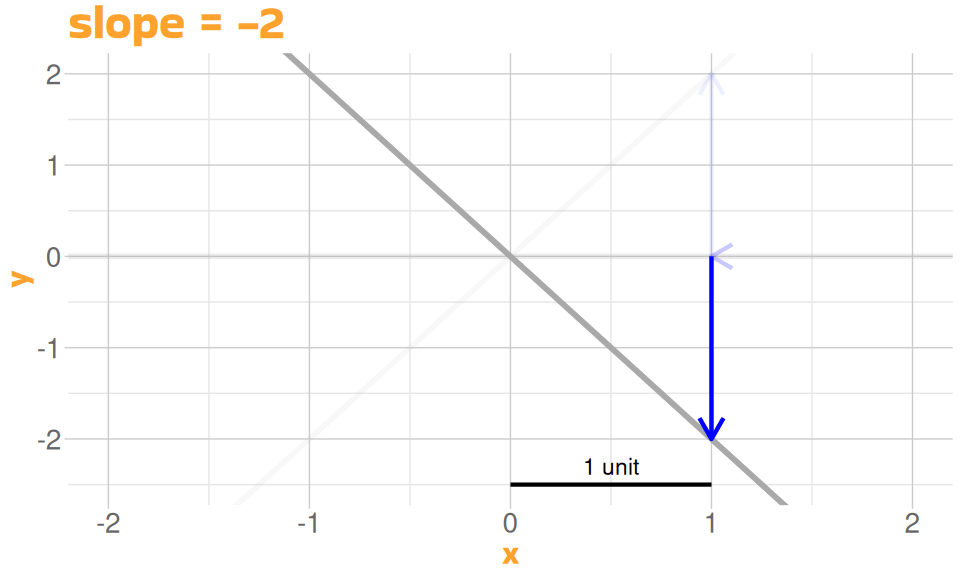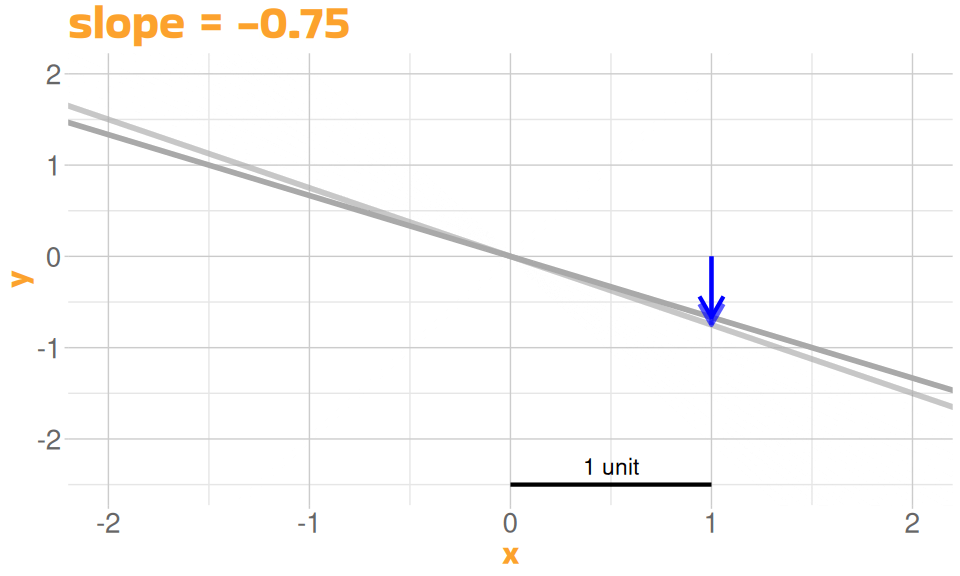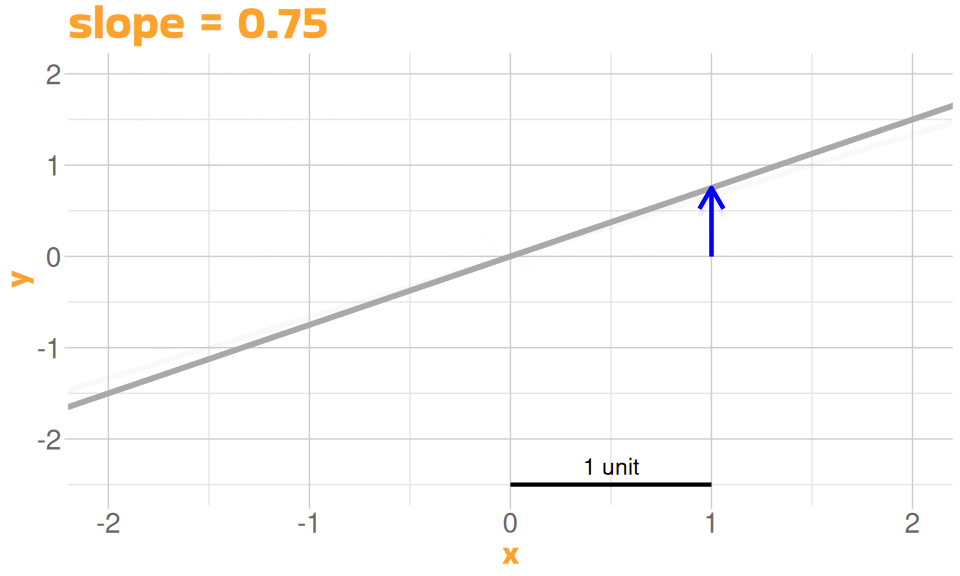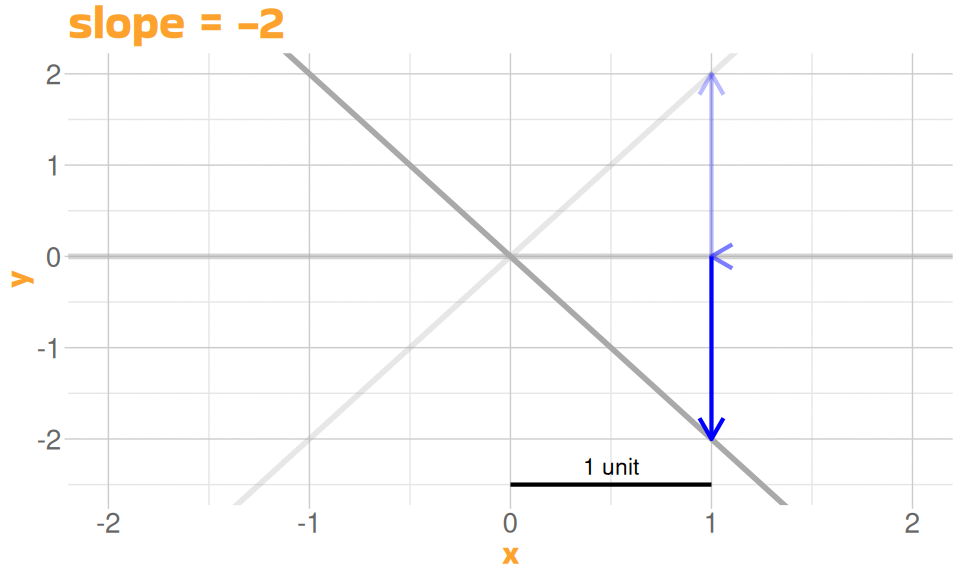
A Linear Model
\[\color{red}{\textrm{outcome}_i} = \color{blue}{(\textrm{model})_i} + \textrm{error}_i\] \[\color{red}{y_i} = \color{blue}{\textrm{intercept}\cdot{}1+\textrm{slope}\cdot{}x_i}+\epsilon_i\]
\[\color{red}{y_i} = \color{blue}{b_0 \cdot{} 1 + b_1 \cdot{} x_i} + \epsilon_i\] so the linear model itself is…
\[\hat{y}_i = \color{blue}{b_0 \cdot{} 1 + b_1 \cdot{} x_i}\]
\[\color{blue}{b_0=5}, \color{blue}{b_1=2}\] \[\color{orange}{x_i=1.2},\color{red}{y_i=9.9}\] \[\hat{y}_i=7.4\]

A Linear Model
\[\hat{y}_i = \color{blue}{b_0 \cdot{}}\color{orange}{1} \color{blue}{+b_1 \cdot{}} \color{orange}{x_i}\]
values of the linear model (coefficients)
values we provide (inputs)
- maps directly to R “formula” notation

A Linear Model
\[\color{red}{\textrm{outcome}_i} = \color{blue}{(\textrm{model})_i} + \textrm{error}_i\] \[\color{red}{y_i} = \color{blue}{\textrm{intercept}}\cdot{}\color{orange}{1}+\color{blue}{\textrm{slope}}\cdot{}\color{orange}{x_i}+\epsilon_i\] \[\color{red}{y_i} = \color{blue}{b_0} \cdot{} \color{orange}{1} + \color{blue}{b_1} \cdot{} \color{orange}{x_i} + \epsilon_i\] so the linear model itself is…
\[\hat{y}_i = \color{blue}{b_0} \cdot{} \color{orange}{1} + \color{blue}{b_1} \cdot{} \color{orange}{x_i}\]
\[\hat{y}_i = \color{blue}{b_0} + \color{blue}{b_1} \cdot{} \color{orange}{x_i}\] 

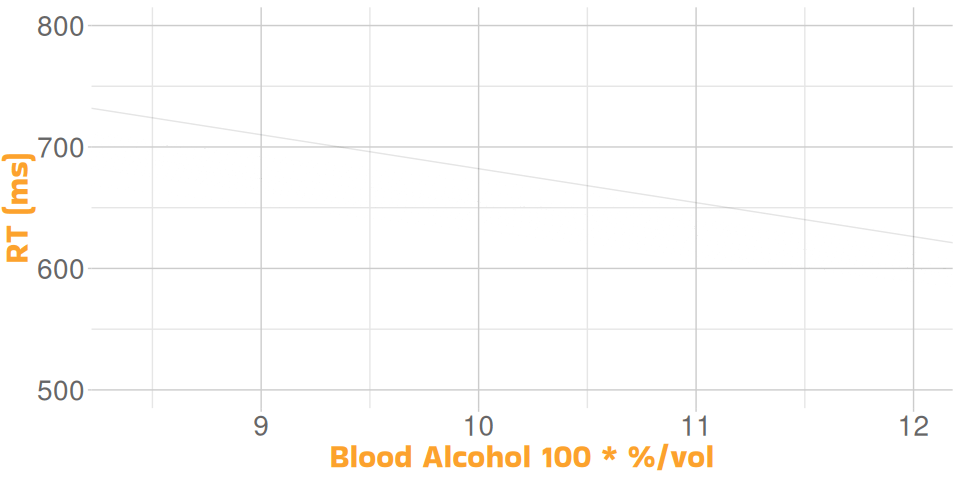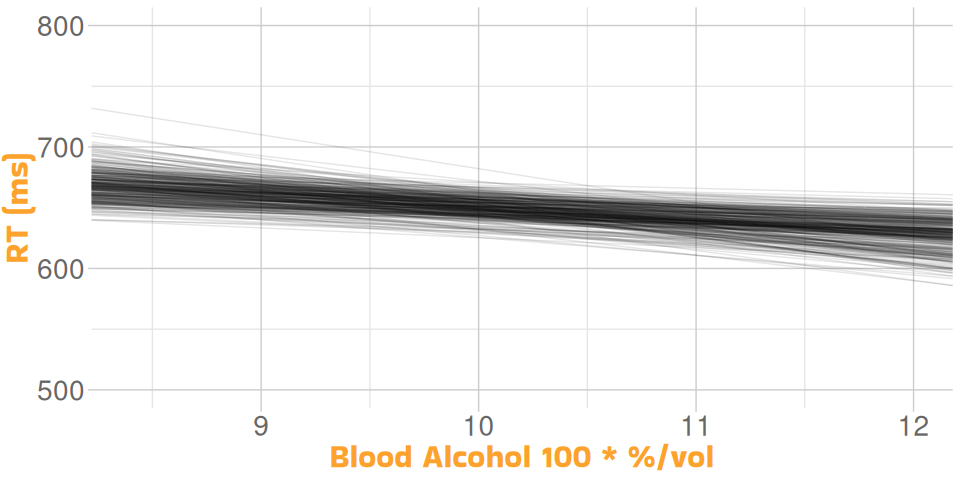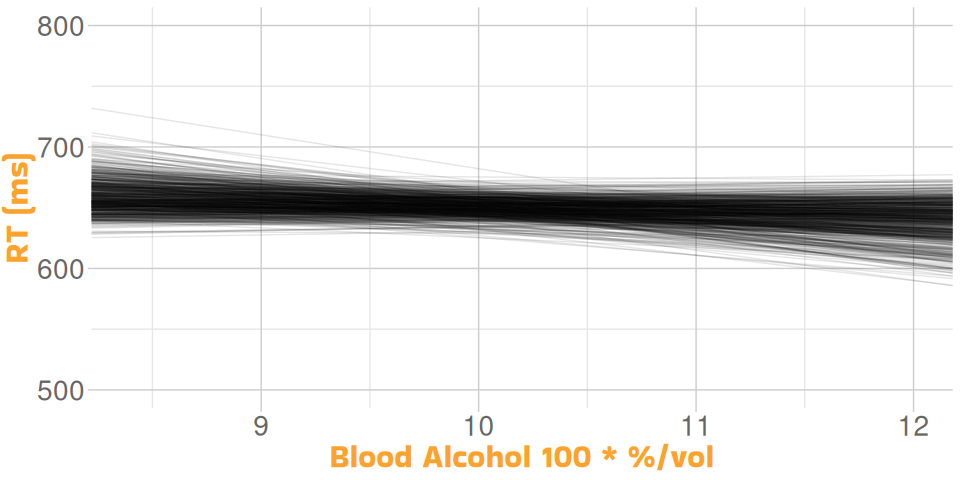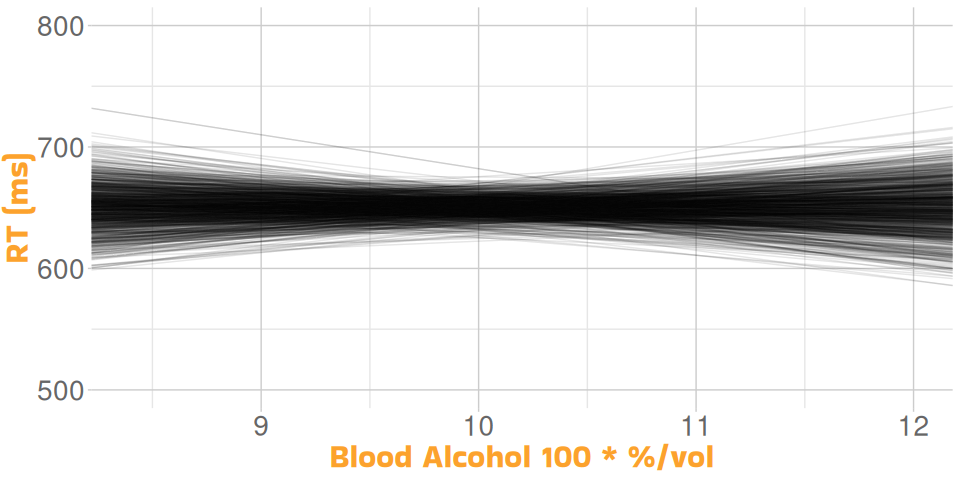
Back on the Road 2
- simplify the data to make interpretation easier
ourDat <- dat |>
mutate(BloodAlc = BloodAlc * 100)

mod <- lm(RT ~ BloodAlc, data = ourDat)Possibly Back on the Road

for every extra 0.01% blood alcohol, reaction time slows down by around 32 ms
- remember that one unit is 0.01%, because we multiplied by 100
Let’s Simulate!

Many Regressions


Degrees of Freedom

Degrees of Freedom

Pirates and Global Warming