class: center, middle, inverse, title-slide # <b>Week 11: Some Kind of End to the Course</b> ## Univariate Statistics and Methodology using R ### Martin Corley ### Department of Psychology<br/>The University of Edinburgh --- class: inverse, center, middle # Part 1 ## ANOVA and GLM --- # ANOVA and GLM > If you should say to a mathematical statistician that you have discovered that linear multiple regression and the analysis of variance (and covariance) are identical systems, he would mutter something like "Of course—general linear model," and you might have trouble maintaining his attention. If you should say this to a typical psychologist, you would be met with incredulity, or worse. Yet it is true, and in its truth lie possibilities for more relevant and therefore more powerful research data. .tr[ Cohen (1968) ] --- # History .pull-left[ .br3.pa2.bg-gray.white[ ### .white[Multiple Regression] - introduced c. 1900 in biological and behavioural sciences - aligned to "natural variation" in observations - tells us that means `\((\bar{y})\)` are related to groups `\((g_1,g_2,\ldots,g_n)\)` ]] .pull-right[ .br3.pa2.bg-gray.white[ ### .white[ANOVA] - introduced c. 1920 in agricultural research - aligned to experimentation and manipulation - tells us that groups `\((g_1,g_2,\ldots,g_n)\)` have different means `\((\bar{y})\)` ]] .pt2[ - both produce `\(F\)`-ratios, discussed in different language, but identical ] --- # Why Teach GLM/Regression? - GLM has less restrictive assumptions + especially true for unbalanced designs/missing data - GLM is far better at dealing with covariates + can arbitrarily mix continuous and discrete predictors - GLM is the gateway to other powerful tools + mixed models and factor analysis (→ MSMR) + structural equation models --- # ANOVA in R .pull-left.center[ <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #mgshirejte .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 2px; border-top-color: #A8A8A8; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #A8A8A8; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; } #mgshirejte .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #mgshirejte .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #mgshirejte .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 0; padding-bottom: 4px; border-top-color: #FFFFFF; border-top-width: 0; } #mgshirejte .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #mgshirejte .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #mgshirejte .gt_col_heading { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #mgshirejte .gt_column_spanner_outer { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #mgshirejte .gt_column_spanner_outer:first-child { padding-left: 0; } #mgshirejte .gt_column_spanner_outer:last-child { padding-right: 0; } #mgshirejte .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; overflow-x: hidden; display: inline-block; width: 100%; } #mgshirejte .gt_group_heading { padding: 8px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; } #mgshirejte .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: middle; } #mgshirejte .gt_from_md > :first-child { margin-top: 0; } #mgshirejte .gt_from_md > :last-child { margin-bottom: 0; } #mgshirejte .gt_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #mgshirejte .gt_stub { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #mgshirejte .gt_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #mgshirejte .gt_first_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #mgshirejte .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #mgshirejte .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #mgshirejte .gt_striped { background-color: rgba(128, 128, 128, 0.05); } #mgshirejte .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #mgshirejte .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #mgshirejte .gt_footnote { margin: 0px; font-size: 90%; padding: 4px; } #mgshirejte .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #mgshirejte .gt_sourcenote { font-size: 90%; padding: 4px; } #mgshirejte .gt_left { text-align: left; } #mgshirejte .gt_center { text-align: center; } #mgshirejte .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #mgshirejte .gt_font_normal { font-weight: normal; } #mgshirejte .gt_font_bold { font-weight: bold; } #mgshirejte .gt_font_italic { font-style: italic; } #mgshirejte .gt_super { font-size: 65%; } #mgshirejte .gt_footnote_marks { font-style: italic; font-size: 65%; } </style> <div id="mgshirejte" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"><table class="gt_table"> <thead class="gt_col_headings"> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_center" rowspan="1" colspan="1">type</th> <th class="gt_col_heading gt_columns_bottom_border gt_right" rowspan="1" colspan="1">UTILITY</th> </tr> </thead> <tbody class="gt_table_body"> <tr> <td class="gt_row gt_center">zing</td> <td class="gt_row gt_right">3.2</td> </tr> <tr> <td class="gt_row gt_center">playmo</td> <td class="gt_row gt_right">5.2</td> </tr> <tr> <td class="gt_row gt_center">lego</td> <td class="gt_row gt_right">3.7</td> </tr> <tr> <td class="gt_row gt_center">zing</td> <td class="gt_row gt_right">2.8</td> </tr> <tr> <td class="gt_row gt_center">playmo</td> <td class="gt_row gt_right">7.8</td> </tr> <tr> <td class="gt_row gt_center">lego</td> <td class="gt_row gt_right">3.1</td> </tr> <tr> <td class="gt_row gt_center">zing</td> <td class="gt_row gt_right">4.5</td> </tr> <tr> <td class="gt_row gt_center">playmo</td> <td class="gt_row gt_right">9.3</td> </tr> <tr> <td class="gt_row gt_center">lego</td> <td class="gt_row gt_right">1.7</td> </tr> <tr> <td class="gt_row gt_center">zing</td> <td class="gt_row gt_right">3.2</td> </tr> </tbody> </table></div> ] .pull-right[  ] --- # GLM vs ANOVA ```r l.mod <- lm(UTILITY~type, data=toys) *anova(l.mod) ``` ``` ## Analysis of Variance Table ## ## Response: UTILITY ## Df Sum Sq Mean Sq F value Pr(>F) ## type 2 40.5 20.24 7.38 0.0081 ** ## Residuals 12 32.9 2.74 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ``` ```r a.mod <- aov(UTILITY~type, data=toys) *summary(a.mod) ``` ``` ## Df Sum Sq Mean Sq F value Pr(>F) ## type 2 40.5 20.24 7.38 0.0081 ** ## Residuals 12 32.9 2.74 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ``` --- # GLM vs ANOVA ```r *summary(l.mod) ``` ``` ## ... ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 4.000 0.741 5.40 0.00016 *** ## typeplaymo 2.600 1.047 2.48 0.02884 * ## typelego -1.360 1.047 -1.30 0.21853 ## ... ``` ```r *model.tables(a.mod) ``` ``` ## Tables of effects ## ## type ## type ## zing playmo lego ## -0.4133 2.1867 -1.7733 ``` ??? - the (default) model table shows you the differences from the grand mean, which is 4.4133 - so in the linear model summary the mean value for playmos is 4 + 2.6 or 6.6 - in the anova summary the mean value for playmos is 4.4133 + 2.1867 or 6.6 - however in the model table (from ANOVA) we don't know what differences are statistically significant, and we don't have diagnostics such as `\(R^2\)` --- background-image: url(lecture_10_files/img/elephant.jpg) background-size: cover class: bottom, animated, fadeIn .f1.white.pa3.tc[ Repeated Measures ] --- # Repeated Measures - so far, _every_ model we've looked at has been "one observation per participant" - however, most experiments have a _structure_ - some observations are "more related" to each other than others - for example, because they come from the same person (repeated measures) ---  .f1[Mixed Models] .br3.bg-gray.white.pa2[ `$$y_{ij}=b_{0j}+b_{1j}x_{1ij}+\epsilon_{ij}$$` .pt3[ `$$b_{0j}=\gamma_{00}+\nu_{0j}$$` `$$b_{1j}=\gamma_{01}+\nu_{1j}$$` ]] - relatedness accounted for by more regression equations - all part of the linear model .right[NEXT TERM] --- # ANOVA reading - brief introduction: Navarro (pp. 523-534, v0.5) - Cohen, J. (1968). Multiple Regression as a General Data-Analytic System. _Psychological Bulletin, 70,_ 426-443. - Chapter 16 of Howell, D. C. (2002). _Statistical Methods for Psychology,_ 5th Edn. Duxbury, CA: Duxbury Thomson Learning. --- class: center, middle, inverse, animated, flipInY ## End of Part 1 # For Parts 2 and 3: # please read the example coursework --- class: center, middle, inverse # Part 2 ## Analysis and Reporting --- # Analytical Steps .pull-left[ 1. specify research questions and hypotheses 1. operationalize variables 1. clean and prepare data 1. describe and visualize data 1. select and run statistics 1. check and test data assumptions 1. report and interpret results ] .pull-right.center[  ] ??? - these are the typical steps you would take for an analysis --- # 1. Research Questions and Hypotheses .pt4[ > Does time of day and speed of driving predict the blood alcohol content over and above driver's age? - several variables "predicting" one variable - variables need to be operationalized ] --- # 2. Operationalize Variables .pull-left[ ### predictors (IVs) > Age of driver (in years) > Speed when stopped by police (mph) - continuous > Whether or not the incident occurred at night - binary ] .pull-right[ ### outcome (DV) > Blood Alcohol Content (%) as measured by breathalyser - continuous ] --- # 3. Clean and Prepare Data 1. are there any impossible values? - clean and recode them as something sensible, often `NA` 1. are there any outliers? - often can't be sure unless we've measured _influence_ 1. are categorical variables appropriately encoded? - does R recognise them as `factor`s? - how are the levels labelled? (which is the intercept level?) --- # 4. Describe and Visualize Data .pt4[ - descriptions depend on variable types - `age`, `speed`: continuous → mean, SD, histogram or density? - `nighttime`: binary → frequencies, mosaic plot? ] --- # 5. Statistics - **t-test**: mean difference - **correlation**: association - **regression**: "prediction" .pt2[ - choice depends on relational statement in question - calculation depends on DV type etc. ] -- .pt2[ - how does this method treat missing data? (`na.rm=T` ?) - what is the key output (from `summary()`, for example?) ] --- # 6. Checking Assumptions: Linear Models .pull-left[ ### required - linearity of relationship - for the _residuals_: + normality + homogeneity of variance + independence ] .pull-right[ ### desirable - uncorrelated predictors - no "bad" (overly influential) observations ] --- # 6. Checking Assumptions: Logit Models .pull-left[ ### required - linearity of relationship .red[between IVs and log-odds] - for the _residuals_: + .red[~~normality~~] + .red[~~homogeneity of variance~~] + independence ] .pull-right[ ### desirable - uncorrelated predictors - no "bad" (overly influential) observations - .red[large samples (due to maximum likelihood fitting)] ] --- # EXAM INFO .pt5[ - for the exam, we do not expect a full set of assumption checks for any `glm(..., family=binomial)` regressions you do - please provide a rationale for using these regressions based on the types of the variables you are analysing ] --- # 6. Interpretation .center[ 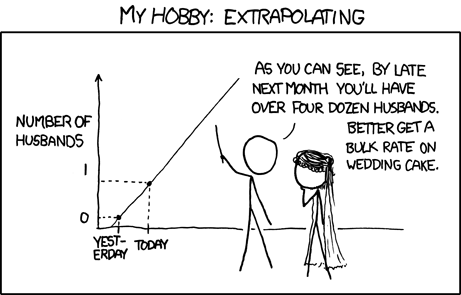 ] ??? - remember that statistics are no substitute for common sense --- # 6. Interpretation (see week 9) 1. is the intercept meaningful? - can I make it meaningful using scaling? 1. do the units of `\(x_n\)` and `\(y\)` aid interpretation? - can I help interpretability using standardisation? - often useful to report `\(b\)`s and `\(\beta\)`s 1. is the coding of nominal variables sensible? - right intercept? - .gray[could I use a better coding?] --- # 7. Reporting Results: General Formatting - primary source for psychology (and empirical linguistics) is the _American Psychology Association Publication Manual_, 7th Edn.<sup>1</sup> - plenty of material at http://www.apastyle.org/ - there are formal ways to present statistical results - plenty of good resources, e.g., http://my.ilstu.edu/~jhkahn/apastats.html .footnote[ <sup>1</sup> most people are still using the 6th Edn. ] --- # Reporting Results: Tables 1. if you have fewer than 2 rows/columns, you don't need a table 1. number tables sequentially and refer to them in the text + _table 1 contains descriptive statistics..._ 1. be consistent in your formatting + consistency is more important than exactly matching APA standards 1. include a brief informative title/caption above the table --- # Example Table .center[ .f4.tl[ Table X: Proportions of trials in which participants referred disfluently to disfluency images for experiments 1 and 2. Standard errors are given in parentheses. ] .pt2[ 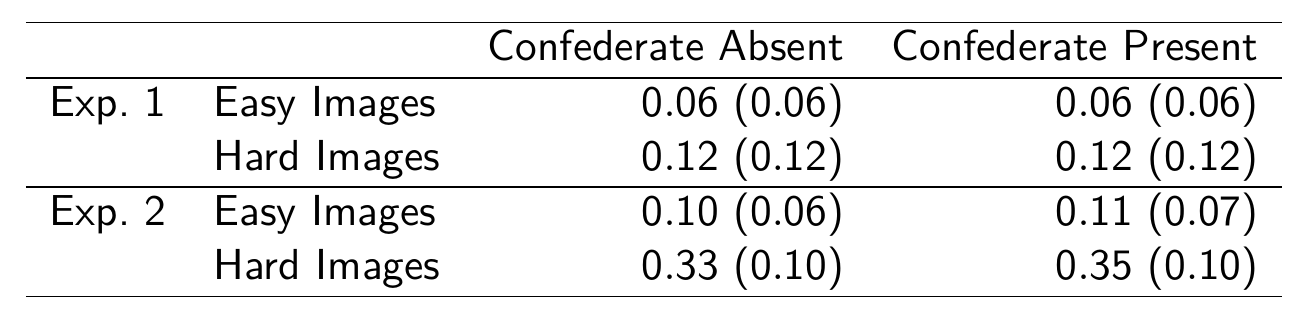 ] ] --- # Reporting Results: Figures .center.pt2[ 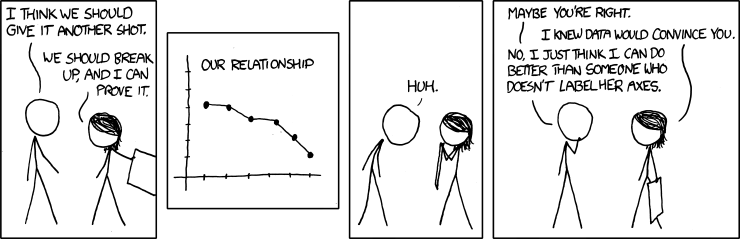 ] --- # Reporting Results: Figures 1. figures include all illustrations that aren't tables (chart, graph, photograph, drawing...) 1. number figures sequentially and refer to them in text + tables and figures have different numbering 1. for graphs, make sure + axes are labelled appropriately + legends are included where necessary 1. include a brief informative title/caption below the figure --- # Example Figure and Caption .center[ 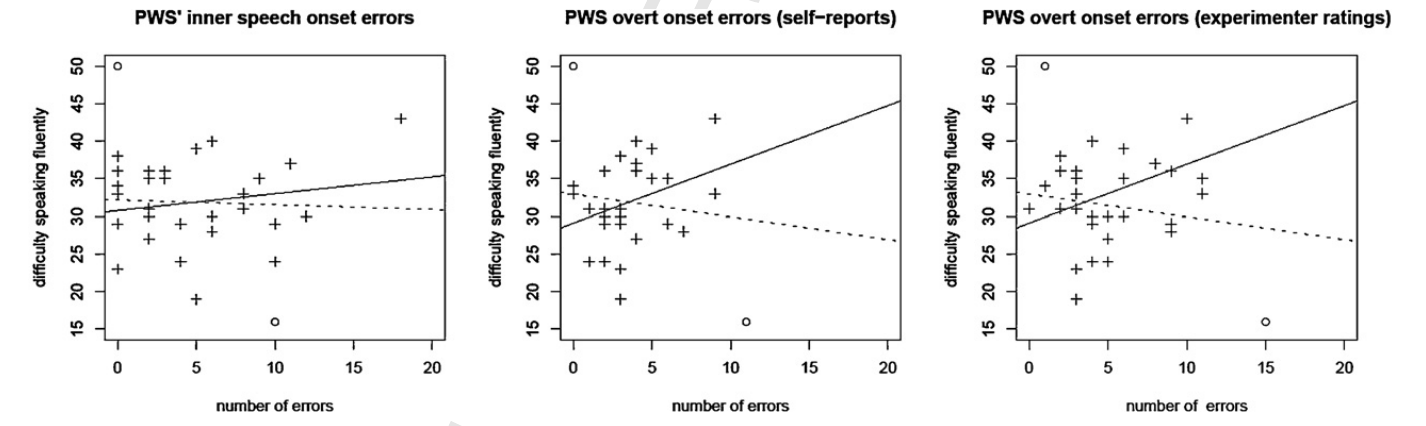 .f4.tl[Figure Y: Scatterplots showing, for each PWS, total number of onset errors (x axis) plotted against self ratings of difficulty speaking fluently in 10 commonly occurring speaking situation (y axis). From left to right, the three plots show raw numbers of onset errors in (1) inner speech; (2) overt speech (self-reports); and (3) overt speech (experimenter ratings). The unbroken regression line depicts the relationship between the two variables when two outliers (marked with `\(\circ\)`) are excluded.] ] --- # Reporting Results 1. don't repeat information 1. be concise 1. provide rationales for the decisions you make 1. be consistent 1. describe all your steps, but only include diagnostic information for key analyses --- class: inverse, center, middle, animated, flipInY # End of Part 2 --- class: inverse, center, middle # Part 3 ## Report Writing --- background-image: url(lecture_10_files/img/playmo_goodbye.jpg) background-size: contain # Goodbye!