class: center, middle, inverse, title-slide # <b>Week 1: Introduction</b> ## Univariate Statistics and Methodology using R ### Martin Corley ### Department of Psychology<br/>The University of Edinburgh --- class: inverse, center, middle # Part 1 # Why R? --- # What is R? .flex.items-center[.w-20.pa2[ ] .w-80.pa2[ - **R** is a 'statistical programming language' - created mid-90s as a free version of **S** - widespread adoption since v2 (2004) ]] .flex.items-center[.w-80.pa2[ - **RStudio** is an 'integrated development environment' (IDE) - created 2011 'to improve **R** experience' - widespread adoption since 2012 ] .w-20.pa2[ ]] --- # R vs RStudio ### This is R ```r model <- lm(RT ~ (age+freq+handedness)^2, data=words) summary(model) ``` -- .flex[.w-50[ ### This is RStudio ] .w-50[]] --- # RMarkdown .flex.items-center[.w-20.pa2[ ] .w-80.pa2[ - **RMarkdown** is a 'text markup language' - created 2012 as a markup language for **R** - widespread adoption since 2015 ]] --- # RMarkdown .flex.w-100.bg-light-gray[ ``` ### About RMarkdown _This_ is some **RMarkdown**, which uses 'simple' codes to mark up text. - it can include R code like `r sqrt(2)` - it's simple to format things like bulleted lists + or even sublists ``` ] .pt4[ ### About RMarkdown _This_ is some **RMarkdown**, which uses 'simple' codes to mark up text. - it can include R code like 1.4142 - it's simple to format things like bulleted lists + or even sublists ] ---  - these lecture slides are created in **RStudio**, using **RMarkdown** and **R**  --- class: inverse, center, middle # What is R Good For? --- # Managing Datasets .center[ 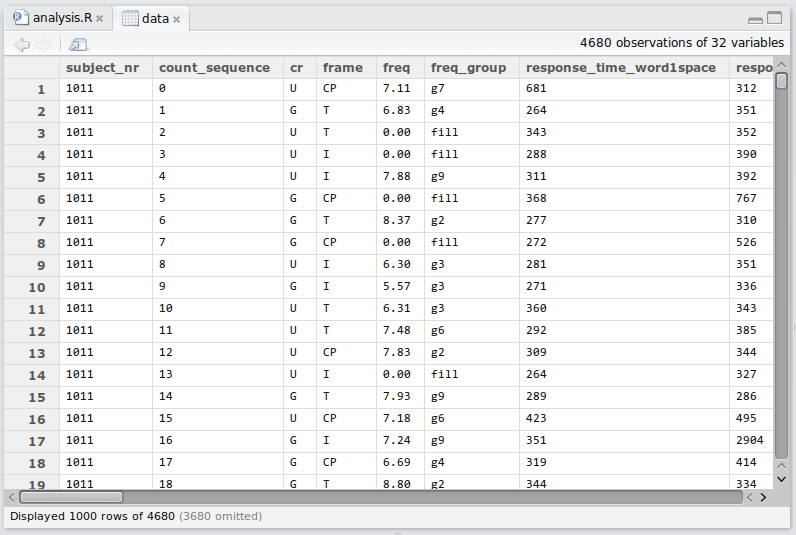 ] --- # Doing Statistics ``` Generalized linear mixed model fit by maximum likelihood (Laplace Approximation) [glmerMod] Family: binomial ( logit ) Formula: DV ~ sc(FvO) * sc(EvC) + (1 | Code) + (0 + (sc(FvO) * sc(EvC)) | Code) + (1 | Item) Data: feminine Control: glmerControl(optimizer = "bobyqa") AIC BIC logLik deviance df.resid 879.3 943.6 -427.7 855.3 1558 ... Fixed effects: Estimate Std. Error z value Pr(>|z|) (Intercept) -1.0566 1.1485 -0.92 0.35758 sc(FvO) 1.2453 0.3505 3.55 0.00038 *** sc(EvC) -0.0915 0.3080 -0.30 0.76638 sc(FvO):sc(EvC) 0.0221 0.6321 0.04 0.97207 --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ... ``` --- # Publication-Quality Graphics .center[  ] --- # Data Visualisation .center[  ] .tr[.f6[ https://www.facebook.com/notes/facebook-engineering/visualizing-friendships/469716398919/ ]] --- ### Online Interactive Visualisation <!-- <div style="text-align:center"> --> <iframe src="http://vac-lshtm.shinyapps.io/ncov_tracker/" width="100%" height="80%" align="center"></iframe> <!-- </div> --> --- # R for Anything to do with Data .pull-left.pt4[ ### Pride and Prejudice ```r require(tm) require(wordcloud) # load "Pride and Prejudice" pp <- Corpus(DirSource('R/PP/')) pp <- tm_map(pp,stripWhitespace) pp <- tm_map(pp,tolower) pp <- tm_map(pp,removeWords, stopwords('english')) pp <- tm_map(pp,stemDocument) pp <- tm_map(pp,removePunctuation) pp <- tm_map(pp, PlainTextDocument) wordcloud(pp, scale=c(5,0.5), max.words=150, random.order=FALSE, rot.per=0.35, colors=brewer.pal(12,'Dark2')) ``` ] .pull-right[  ] ??? R is a multipurpose programming language with an emphasis on statistics. It can do all of the things that any statistics package can do and much more: Here, we're using it to visualise the frequencies with which words are used in Jane Austen's _Pride and Prejudice_. --- # The R Community .left-column[  ] .right-column[ - _someone else_ has done all the hard work to create wordclouds - released as libraries or **packages** (like `lme4` and `tidyverse`) - all I supplied was a text version of _Pride and Prejudice_ .pt3[ - **R** allows you to do _anything_ with data - if it's useful, chances are someone has already done it - useful things include statistics! ]] --- # The R Community - if it serves no purpose, chances are that someone's already done it too ```r library(cowsay) say("hello USMR") ``` ``` ## ## -------------- ## hello USMR ## -------------- ## \ ## \ ## \ ## |\___/| ## ==) ^Y^ (== ## \ ^ / ## )=*=( ## / \ ## | | ## /| | | |\ ## \| | |_|/\ ## jgs //_// ___/ ## \_) ## ``` --- # Why Use R? .pt4[ - because it's a _language_, I can easily show you what I did and you can copy it - because it's a _language_, statisticians can use it to implement leading-edge stats - because it's _free_, anyone can use it---and anyone can access your research - because it's _open source_, anyone can fix or improve `R` ] --- <!-- HERE HERE HERE HERE HERE --> # Devilish stuff .pull-left[ ## doing stats  ] .pull-right[ ## coding   .tc.pt3[ **NB** all indices in `R` start at `1` ]] --- # Why use R?? .pull-left[  ] .pull-right[  .tr.f7[ https://r4stats.com/articles/popularity ]] --- class: inverse, center, middle, animated, heartBeat # End of Part 1 --- class: inverse, center, middle # Part 2 ## Getting to Grips with R --- # Data in R - you can type **data** directly in to R ```r # a number 1.2 ``` ``` ## [1] 1.2 ``` ```r # characters (a string) "fáilte" ``` ``` ## [1] "fáilte" ``` - and you can do **operations** on data ```r 1.2 + 7 * 2 ``` ``` ## [1] 15.2 ``` ??? by "data" we really mean anything that is measured *outside* R and provided to R directly --- # Variables .left-column[  ] .right-column[ - you can assign data to **variables** ```r bodyTemp <- 37.8 ``` - and use those variables ```r bodyTemp * (9/5) + 32 # to Fahrenheit ``` ``` ## [1] 100 ``` - **NB** spelling/capitalization matter ```r BodyTemp - 37 ``` ``` ## Error in eval(expr, envir, enclos): object 'BodyTemp' not found ``` ] --- # Statistics is about **groups** of things .flex.items-center[ .w-70.pa2[ ```r allTemps <- c(37.8, 0, 37.4) # vector maths allTemps * (9/5) + 32 ``` ``` ## [1] 100.04 32.00 99.32 ``` .pt2[ - note the **vectorization** of the calculation - R is designed from the bottom up to deal with groups ]] .w-30.pa2[  ]] --- # Not everything is a number .flex.items-center[ .w-70.pa2[ ```r allHair <- c("brown","white","black") allHair ``` ``` ## [1] "brown" "white" "black" ``` - these are called **character strings** + can be anything - **categories** (nominal data) are from a limited set + called **factors** in R ```r as.factor(allHair) ``` ``` ## [1] brown white black ## Levels: black brown white ``` ] .w-30.pa2[  ]] --- # Basic types of data (stats) .flex.items-center[ .w-70.pa2[ - **Nominal** ('names of things': e.g., hair colour) - **Ordinal** (order, no number: e.g., small-medium-large) - **Interval** (number without a true zero: e.g., body temp in ℃) - **Ratio** (number with a true zero: e.g., height) ] .w-30.pa2[  ]] --- # NOIR in R .flex.items-center[.w-40.pa1[ <style>html { font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Helvetica Neue', 'Fira Sans', 'Droid Sans', Arial, sans-serif; } #wpxjrazgde .gt_table { display: table; border-collapse: collapse; margin-left: auto; margin-right: auto; color: #333333; font-size: 16px; font-weight: normal; font-style: normal; background-color: #FFFFFF; width: auto; border-top-style: solid; border-top-width: 2px; border-top-color: #A8A8A8; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #A8A8A8; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; } #wpxjrazgde .gt_heading { background-color: #FFFFFF; text-align: center; border-bottom-color: #FFFFFF; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #wpxjrazgde .gt_title { color: #333333; font-size: 125%; font-weight: initial; padding-top: 4px; padding-bottom: 4px; border-bottom-color: #FFFFFF; border-bottom-width: 0; } #wpxjrazgde .gt_subtitle { color: #333333; font-size: 85%; font-weight: initial; padding-top: 0; padding-bottom: 4px; border-top-color: #FFFFFF; border-top-width: 0; } #wpxjrazgde .gt_bottom_border { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #wpxjrazgde .gt_col_headings { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; } #wpxjrazgde .gt_col_heading { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; padding-left: 5px; padding-right: 5px; overflow-x: hidden; } #wpxjrazgde .gt_column_spanner_outer { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: normal; text-transform: inherit; padding-top: 0; padding-bottom: 0; padding-left: 4px; padding-right: 4px; } #wpxjrazgde .gt_column_spanner_outer:first-child { padding-left: 0; } #wpxjrazgde .gt_column_spanner_outer:last-child { padding-right: 0; } #wpxjrazgde .gt_column_spanner { border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: bottom; padding-top: 5px; padding-bottom: 6px; overflow-x: hidden; display: inline-block; width: 100%; } #wpxjrazgde .gt_group_heading { padding: 8px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; } #wpxjrazgde .gt_empty_group_heading { padding: 0.5px; color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; vertical-align: middle; } #wpxjrazgde .gt_from_md > :first-child { margin-top: 0; } #wpxjrazgde .gt_from_md > :last-child { margin-bottom: 0; } #wpxjrazgde .gt_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; margin: 10px; border-top-style: solid; border-top-width: 1px; border-top-color: #D3D3D3; border-left-style: none; border-left-width: 1px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 1px; border-right-color: #D3D3D3; vertical-align: middle; overflow-x: hidden; } #wpxjrazgde .gt_stub { color: #333333; background-color: #FFFFFF; font-size: 100%; font-weight: initial; text-transform: inherit; border-right-style: solid; border-right-width: 2px; border-right-color: #D3D3D3; padding-left: 12px; } #wpxjrazgde .gt_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #wpxjrazgde .gt_first_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; } #wpxjrazgde .gt_grand_summary_row { color: #333333; background-color: #FFFFFF; text-transform: inherit; padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; } #wpxjrazgde .gt_first_grand_summary_row { padding-top: 8px; padding-bottom: 8px; padding-left: 5px; padding-right: 5px; border-top-style: double; border-top-width: 6px; border-top-color: #D3D3D3; } #wpxjrazgde .gt_striped { background-color: rgba(128, 128, 128, 0.05); } #wpxjrazgde .gt_table_body { border-top-style: solid; border-top-width: 2px; border-top-color: #D3D3D3; border-bottom-style: solid; border-bottom-width: 2px; border-bottom-color: #D3D3D3; } #wpxjrazgde .gt_footnotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #wpxjrazgde .gt_footnote { margin: 0px; font-size: 90%; padding: 4px; } #wpxjrazgde .gt_sourcenotes { color: #333333; background-color: #FFFFFF; border-bottom-style: none; border-bottom-width: 2px; border-bottom-color: #D3D3D3; border-left-style: none; border-left-width: 2px; border-left-color: #D3D3D3; border-right-style: none; border-right-width: 2px; border-right-color: #D3D3D3; } #wpxjrazgde .gt_sourcenote { font-size: 90%; padding: 4px; } #wpxjrazgde .gt_left { text-align: left; } #wpxjrazgde .gt_center { text-align: center; } #wpxjrazgde .gt_right { text-align: right; font-variant-numeric: tabular-nums; } #wpxjrazgde .gt_font_normal { font-weight: normal; } #wpxjrazgde .gt_font_bold { font-weight: bold; } #wpxjrazgde .gt_font_italic { font-style: italic; } #wpxjrazgde .gt_super { font-size: 65%; } #wpxjrazgde .gt_footnote_marks { font-style: italic; font-size: 65%; } </style> <div id="wpxjrazgde" style="overflow-x:auto;overflow-y:auto;width:auto;height:auto;"><table class="gt_table"> <thead class="gt_col_headings"> <tr> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="1" colspan="1">Type</th> <th class="gt_col_heading gt_columns_bottom_border gt_left" rowspan="1" colspan="1">R Variable Type</th> </tr> </thead> <tbody class="gt_table_body"> <tr> <td class="gt_row gt_left">Nominal</td> <td class="gt_row gt_left">character/factor</td> </tr> <tr> <td class="gt_row gt_left">Ordinal</td> <td class="gt_row gt_left">number</td> </tr> <tr> <td class="gt_row gt_left">Interval</td> <td class="gt_row gt_left">number</td> </tr> <tr> <td class="gt_row gt_left">Ratio</td> <td class="gt_row gt_left">number</td> </tr> </tbody> </table></div> ] .w-60.pa1[ - nominal ```r allHair <- as.factor(c("brown", "white", "black")) allHair ``` ``` ## [1] brown white black ## Levels: black brown white ``` - interval ```r allTemps <- c(37.8, 0, 37.4) allTemps ``` ``` ## [1] 37.8 0.0 37.4 ``` ]] -- .flex.items-center[ .w-5.pa1[  ] .w-95.pa1[ - ordinal data can also be represented as **ordered factors** (`as.ordered()`) ]] ??? this is the first time I've used this symbol, which means "dangerous bend in the road" I'm going to use it when there's something additional that you really don't need to know but I can't help myself telling you --- # Break it down ```r allHair <- c("brown","white","black") ``` .flex.items-center[ .w-30.f3[ `allHair` ] .w-70[ - **variable** (can be anything that isn't _reserved_) ]] .flex.items-center[ .w-30.f3[ `<-` ] .w-70[ - **assignment** ("goes in to") ]] .flex.items-center[ .w-30.f3[ `c()` ] .w-70[ - **function** (`c()` _combines_ its **arguments**) ]] .flex.items-center[ .w-30.f3[ `"brown"` ] .w-70[ - **character** (arbitrary sequence of symbols) ]] --- # Dataframes .flex.items-center[ .w-70.pa2[ - data can be grouped into a **dataframe** - each _line_ represents one set of observations - each _column_ represents one type of information + (a bit like a spreadsheet) ```r people <- data.frame(name=c('Johanna','Casper','Steve'), temp=allTemps, hair=as.factor(allHair), height=c(132,205,181)) people ``` ``` ## name temp hair height ## 1 Johanna 37.8 brown 132 ## 2 Casper 0.0 white 205 ## 3 Steve 37.4 black 181 ``` ] .w-30.pa2[  ]] ??? - note that I've made _hair_ a factor but left _names_ as character strings. - that's because, in my world, there is a finite set of hair colours, but a name can be anything: it's an arbitrary label. - you'll see the effect of this in the next slide. --- # Can you run an **function** on a **dataframe**? - youbetcha! ```r summary(people) ``` ``` ## name temp hair height ## Length:3 Min. : 0.0 black:1 Min. :132 ## Class :character 1st Qu.:18.7 brown:1 1st Qu.:156 ## Mode :character Median :37.4 white:1 Median :181 ## Mean :25.1 Mean :173 ## 3rd Qu.:37.6 3rd Qu.:193 ## Max. :37.8 Max. :205 ``` - or on a vector ```r mean(people$temp) # just the temp column from people ``` ``` ## [1] 25.07 ``` ??? note the difference between the name column ("there are some strings") and the hair column ("I know there are categories: this is how many of each you have") --- # We know a little about R - we've seen some R code - we know about basic data types - we know what variables are - we've seen vectors, and dataframes - we've seen a couple of examples of functions ??? time for a break! --- class: inverse, center, middle, animated, heartBeat # End of Part 2 --- class: inverse, center, middle # Part 3 .pt3[  ] ??? in part 3 we're going to look at probability, starting with a couple of dice --- ## How likely are you to throw 12 with two dice? .left-column[  ] .right-column[ - pretty easy to work out - one-in-six chance of throwing a six - one-in-six chance of throwing a second six + NB., these observations are _independent_ + (wouldn't matter if you threw one dice twice or two dice together) - `\(\frac{1}{36}\)` chance of throwing two sixes ] --- # Are my dice fair? - one way to find out: throw two dice many times and count the outcomes .center[ <!-- --> ] --- # What would fair dice look like? .pull-left[  ] .pull-right[ - we need a lot of throws - first rule of coding: be lazy - let the computer do the work ] --- # Using RStudio .center[  ] --- count: false # Using RStudio .center[  ] --- class: center, middle ## create some dice ??? - show creating a project - markdown; call project **dice** - first show `1:6` - then `sample(1:6, 1)` - then help for `sample()` - then `sample(1:6, 2, replace=T)` - then `sum(sample(1:6,2,replace=T))` - then make a `dice(num=1)` function which returns the sum, for default 1 --- # Now we can throw dice a _lot_ of times ```r dice <- function(num=1) { sum(sample(1:6, num, replace=TRUE)) } dice() ``` ``` ## [1] 4 ``` -- ```r dice(2) ``` ``` ## [1] 6 ``` --- # Throw two dice many times ```r replicate(250,dice(2)) ``` ``` ## [1] 7 10 8 3 2 11 2 4 9 9 8 8 7 2 10 6 6 11 4 11 5 10 10 5 7 ## [26] 10 12 8 2 3 6 4 11 7 12 2 5 7 12 6 7 5 9 10 8 7 5 11 11 8 ## [51] 7 6 2 8 9 8 6 7 12 3 6 10 10 2 3 11 5 8 10 6 8 7 9 9 3 ## [76] 6 7 5 5 10 10 9 5 11 8 6 10 11 6 7 3 7 9 6 8 7 9 6 4 9 ## [101] 5 7 7 9 5 5 7 3 7 8 9 5 6 12 8 2 9 11 7 5 8 5 5 6 6 ## [126] 6 6 9 9 4 7 6 6 11 8 9 7 10 4 6 4 9 3 10 6 7 5 6 5 8 ## [151] 10 10 8 3 9 5 5 11 8 9 5 3 5 7 9 6 5 8 9 9 8 7 9 3 2 ## [176] 9 7 3 10 9 5 4 4 5 5 6 8 6 10 5 3 12 4 11 9 7 3 5 7 9 ## [201] 8 11 2 8 11 4 9 10 9 12 12 6 6 7 4 8 2 4 7 6 10 2 6 6 5 ## [226] 11 5 2 6 6 10 8 7 3 5 10 6 6 5 6 4 9 7 8 5 6 6 7 6 7 ``` -- - ...and record the result ```r d <- replicate(250,dice(2)) ``` ??? - actually, `d` won't contain the same numbers as you see on the slide --- # Make a graph ```r table(d) ``` ``` ## d ## 2 3 4 5 6 7 8 9 10 11 12 ## 3 18 17 27 43 47 34 27 13 9 12 ``` --- count: false # Make a graph ```r barplot(table(d)) ``` <!-- --> --- # Many more throws ```r d <- replicate(10000,dice(2)) barplot(table(d)) ``` <!-- --> --- # 10,000 dice throws .flex.items-top[ .w-20.pa2[  ] .w-80.pa2[ - we can work out the proportion of throws that summed to 12 ```r sum(d == 12) / 10000 ``` ``` ## [1] 0.0302 ``` - and we know what that proportion should be if the dice are fair ```r 1/36 ``` ``` ## [1] 0.02778 ``` ]] --- # Some more (fake) dice throws .center[ <!-- --> ] .br3.center.pa2.bg-green.white.f4[ are the patterns from the dice _different enough_ from what we would expect from fair dice for us to conclude that they're unfair? ] --- # Statistical questions - so the million-dollar question is a _negative_ question .br3.center.pa2.pt4.bg-green.white.f4[ are we dissatisfied with the suggestion that the pattern of results we have observed should be attributed to chance? ] .pt2[ - if we are, then maybe we can persuade you of a different explanation - but note that the different explanation is not _proven_, it's _suggested_ ] --- class: inverse, center, middle, animated, heartBeat # End --- # Acknowledgements - icons by Diego Lavecchia from the [Noun Project](https://thenounproject.com/)