Exploratory Factor Analysis 1
Data Analysis for Psychology in R 3
Questions to ask before you start
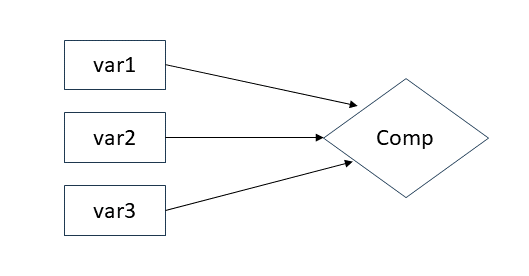
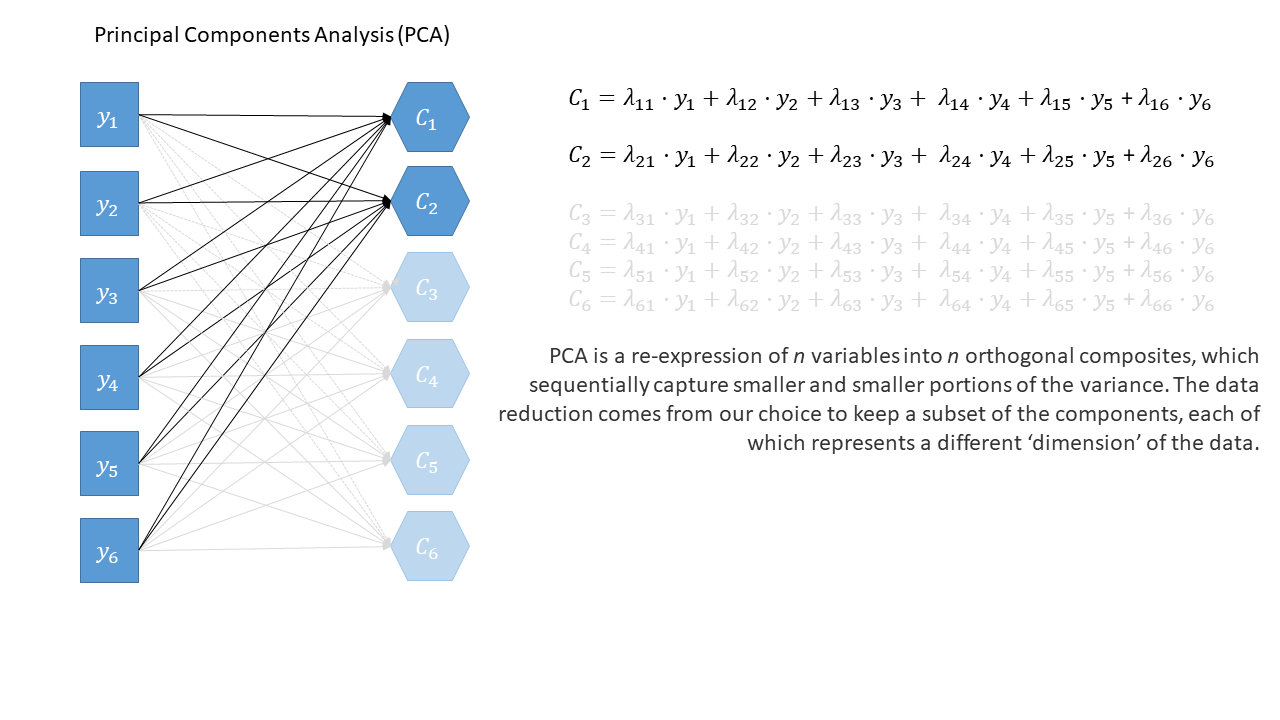
PCA
- Why are your variables correlated?
- Agnostic/don’t care
- What are your goals?
- Just reduce the number of variables
EFA
- Why are your variables correlated?
- Believe there are underlying “causes” of these correlations
- What are your goals?
- Reduce your variables and learn about/model their underlying (latent) causes
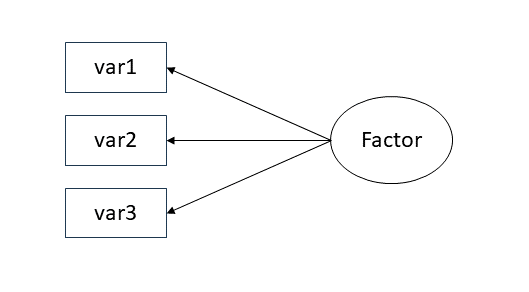
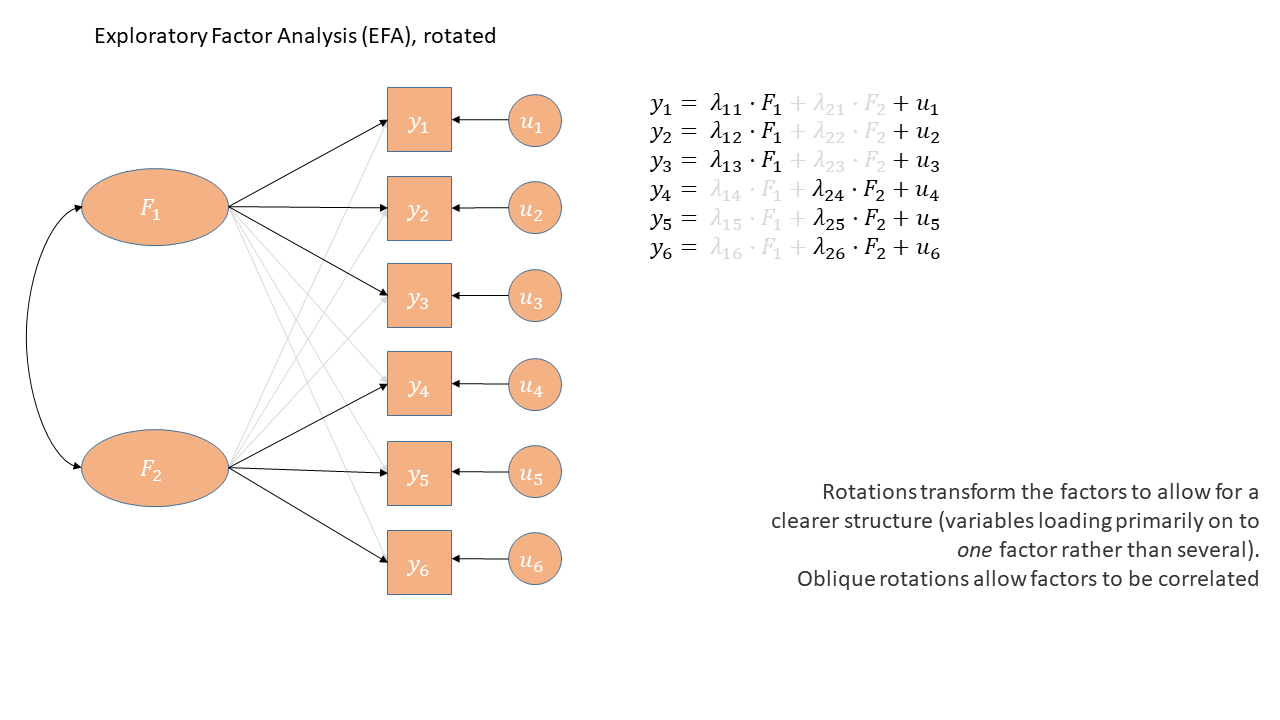
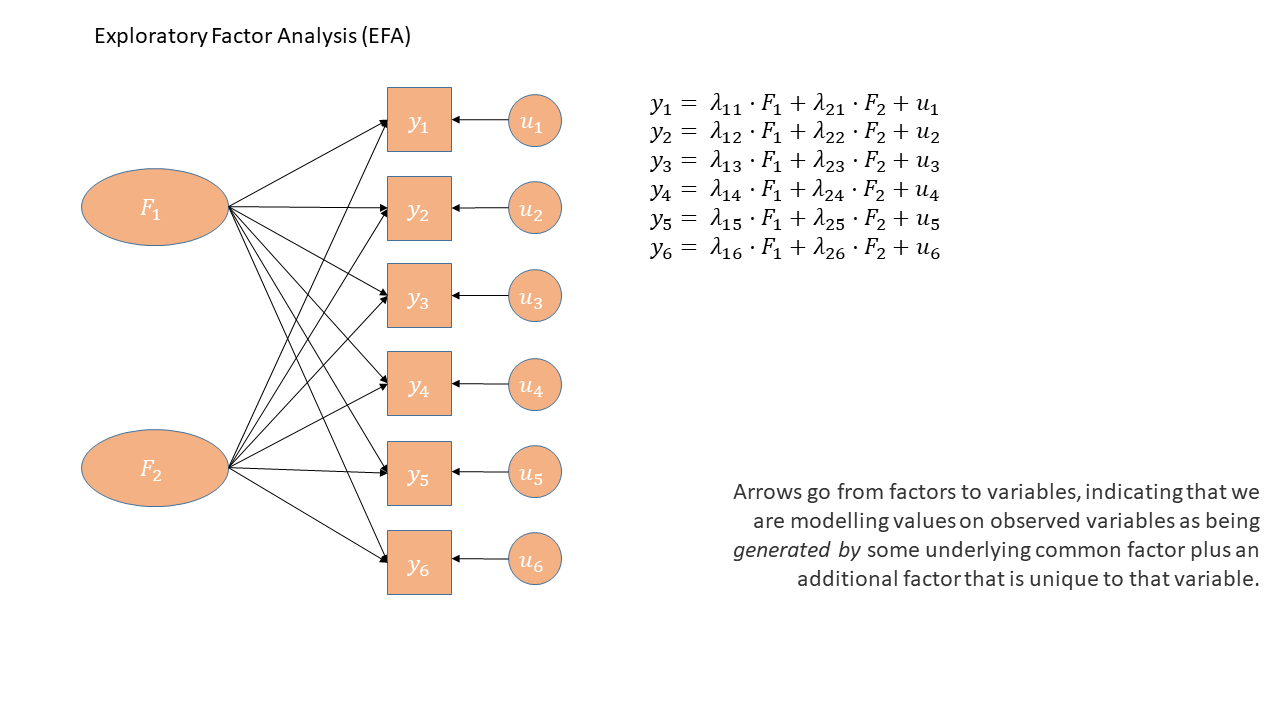
Latent variables
Theorized common cause (e.g., cognitive ability) of responses to a set of variables
- Explain correlations between measured variables
- Held to be real
- No direct test of this theory
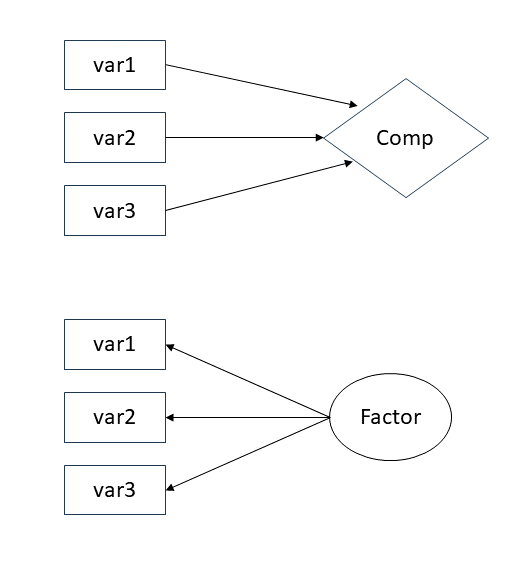
As a diagram
As a diagram (PCA)

As a diagram (PCA)
Some data
| variable | wording |
|---|---|
| item1 | I worry that people will think I'm awkward or strange in social situations. |
| item2 | I often fear that others will criticize me after a social event. |
| item3 | I'm afraid that I will embarrass myself in front of others. |
| item4 | I feel self-conscious in social situations, worrying about how others perceive me. |
| item5 | I often avoid social situations because I’m afraid I will say something wrong or be judged. |
| item6 | I avoid social gatherings because I fear feeling uncomfortable. |
| item7 | I try to stay away from events where I don’t know many people. |
| item8 | I often cancel plans because I feel anxious about being around others. |
| item9 | I prefer to spend time alone rather than in social situations. |
cor(eg_data) |>
pheatmap::pheatmap()
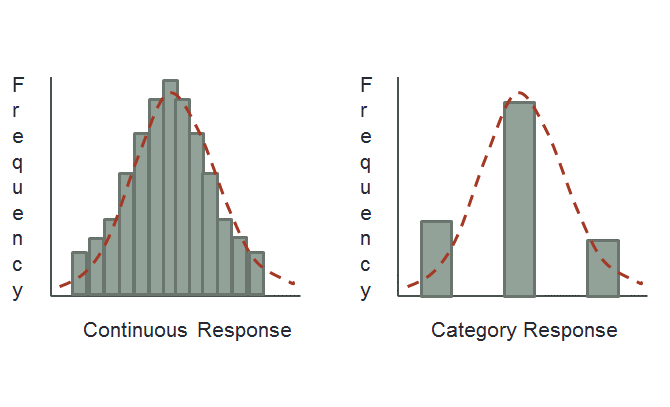
Non-continuous data
Sometimes (often) even when we assume a construct is continuous, we measure it with a discrete scale.
E.g., Likert!
Simulation studies tend to suggest \(\geq 5\) response categories can be treated as continuous
- provided that they have all been used!!

Non-continuous data
Polychoric Correlations
- Estimates of the correlation between two theorized normally distributed continuous variables, based on their observed ordinal manifestations.

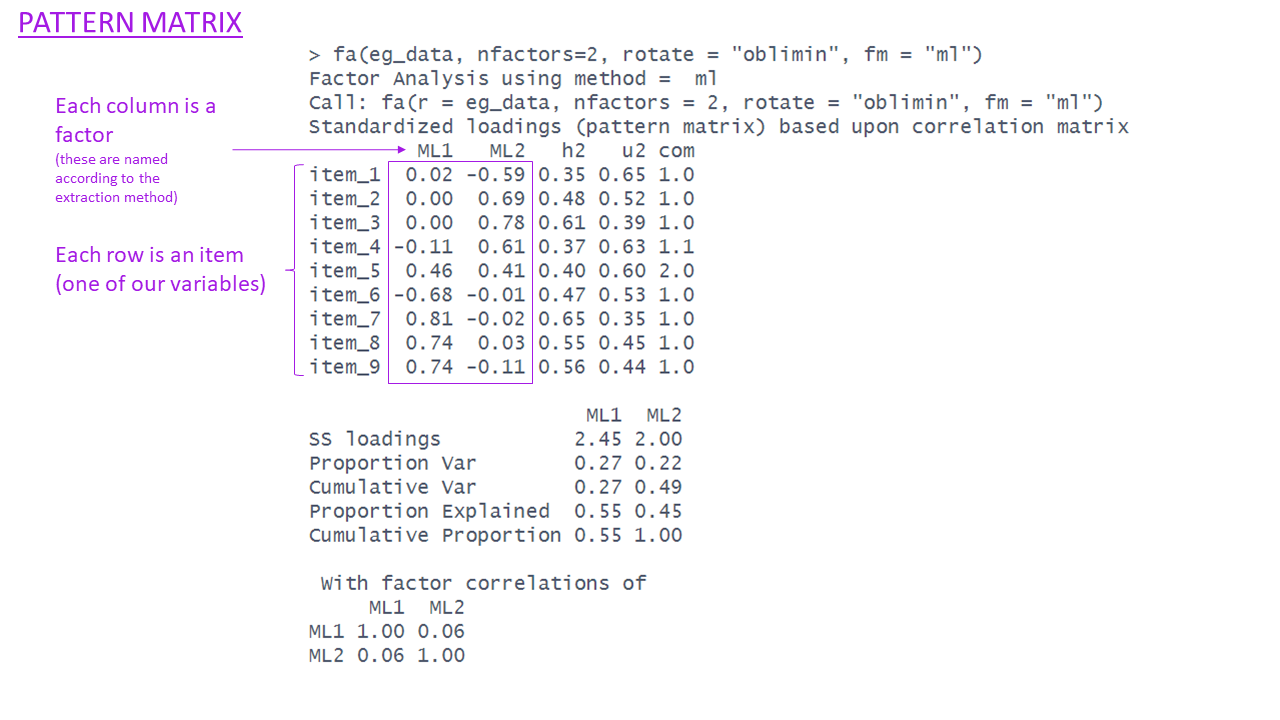
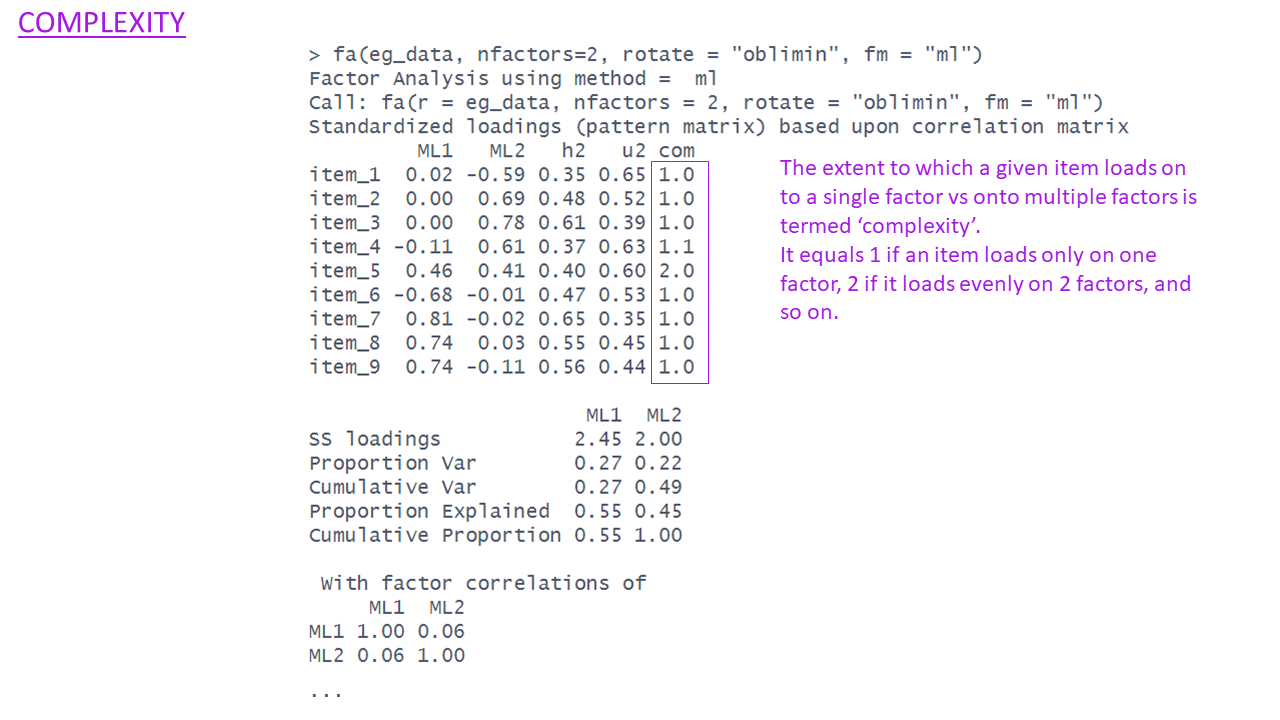
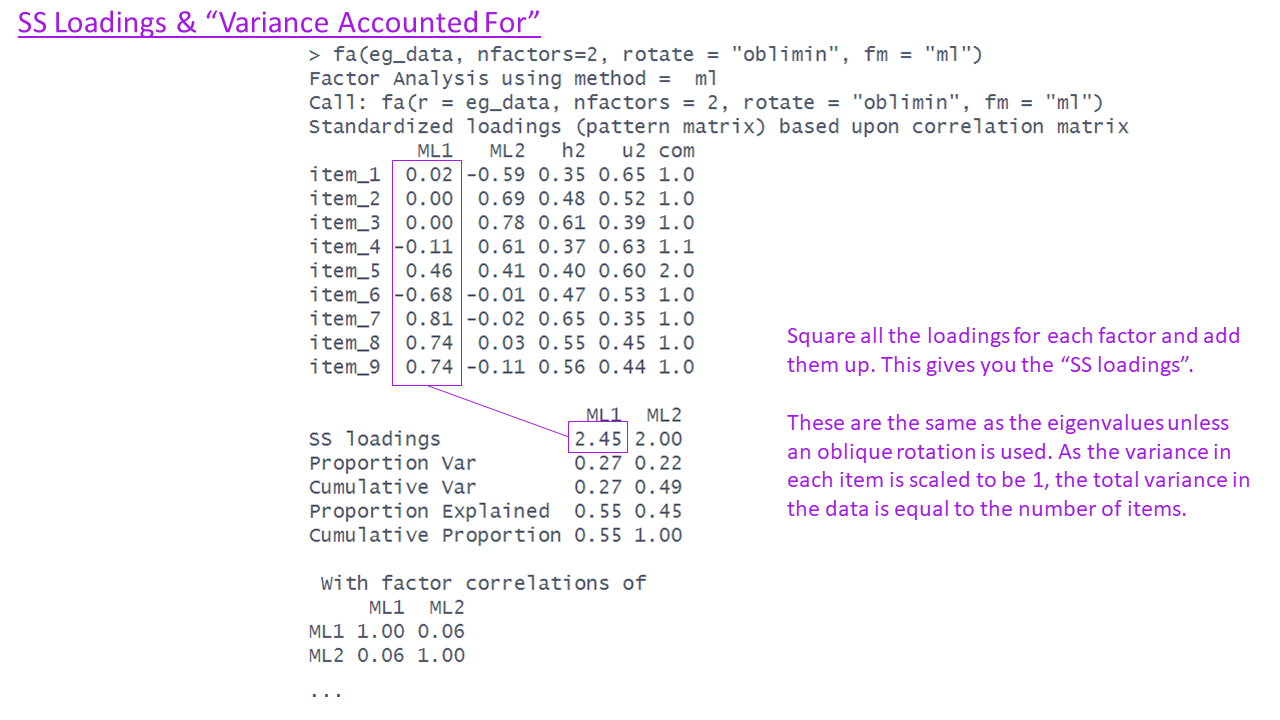
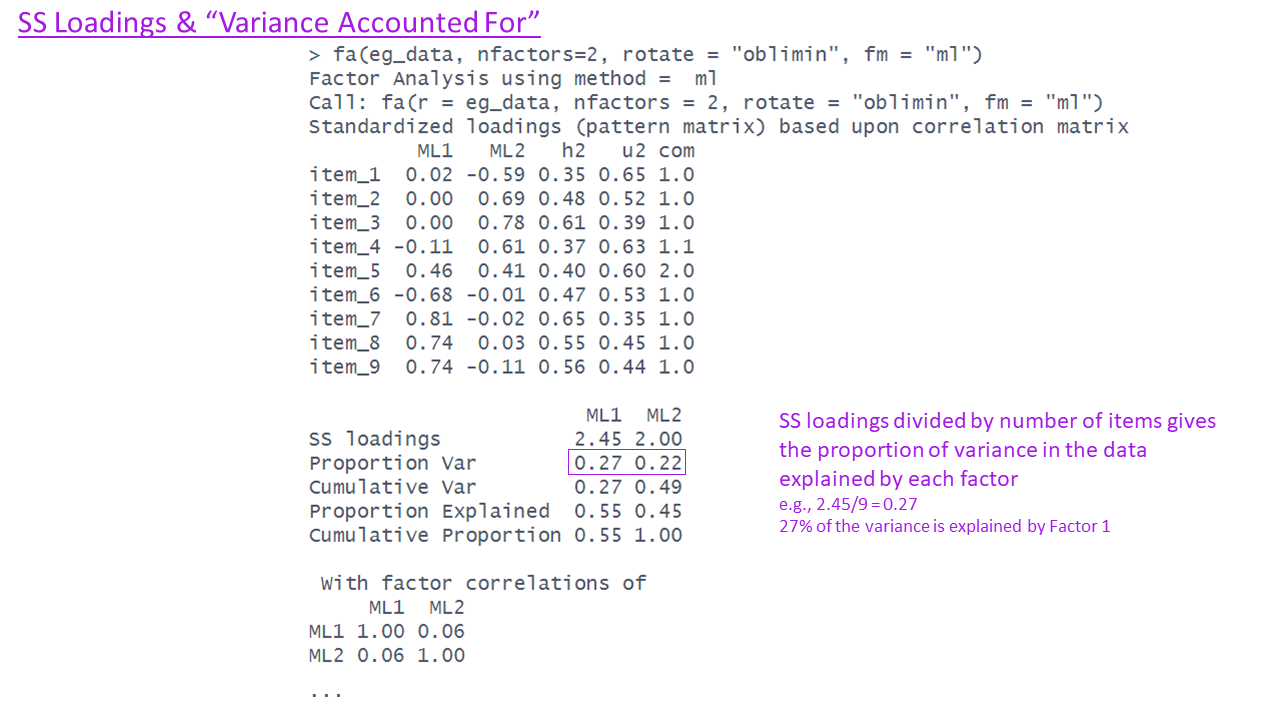
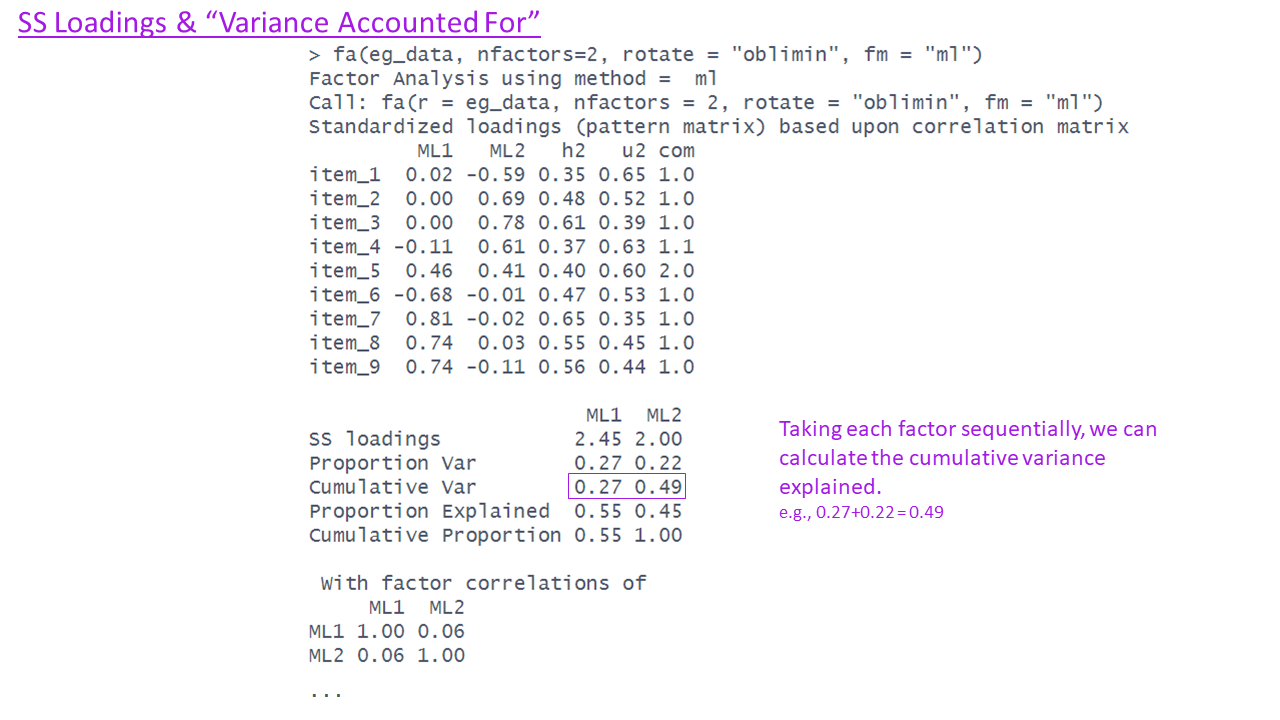
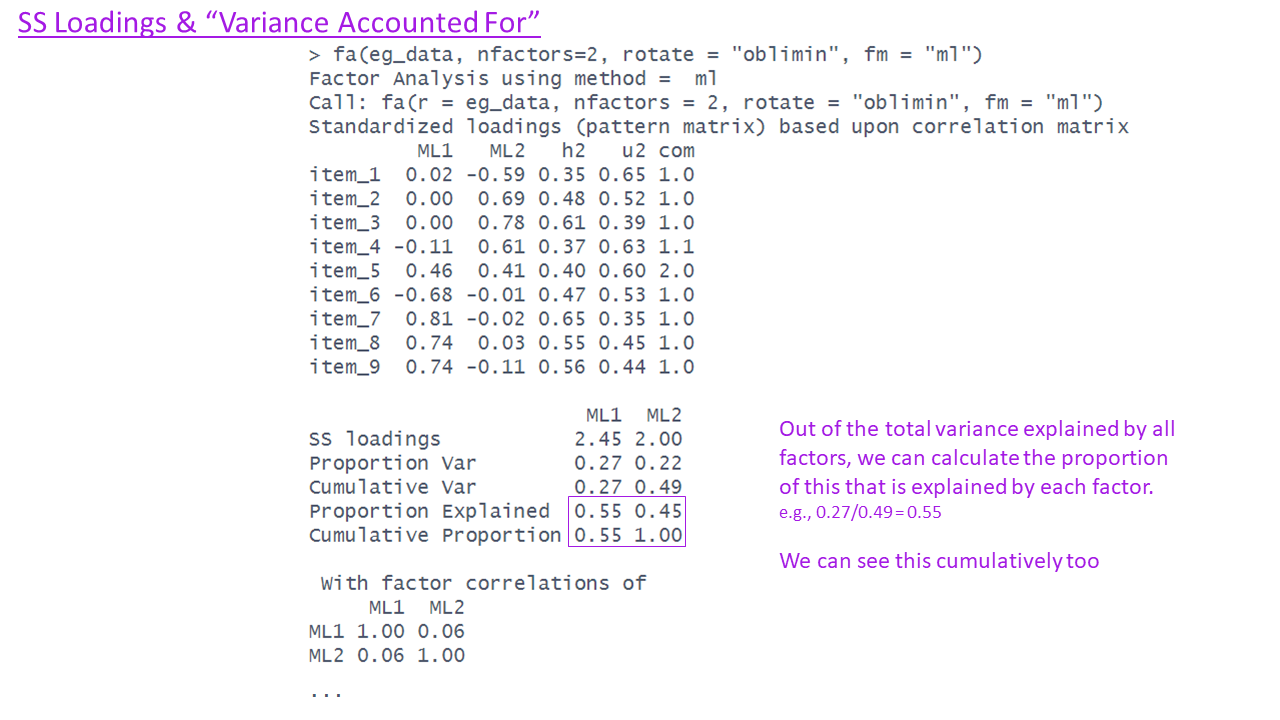
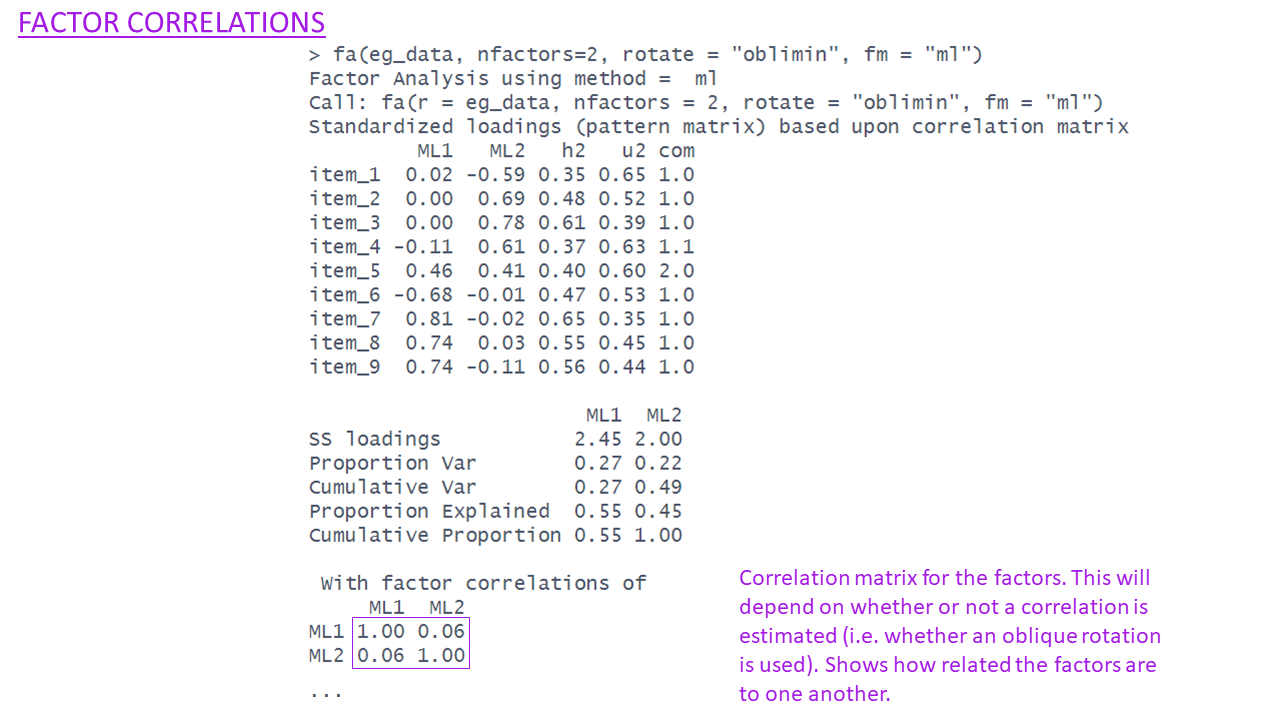
What is rotation?
Factor solutions can sometimes be complex to interpret.
- the pattern of the factor loading’s is not clear.
- The difference between the primary and cross-loading’s is small


Types of rotation
# no rotation
fa(eg_data, nfactors = 2, rotate = "none", fm="ml")
# orthogonal rotations
fa(eg_data, nfactors = 2, rotate = "varimax", fm="ml")
fa(eg_data, nfactors = 2, rotate = "quartimax", fm="ml")
# oblique rotations
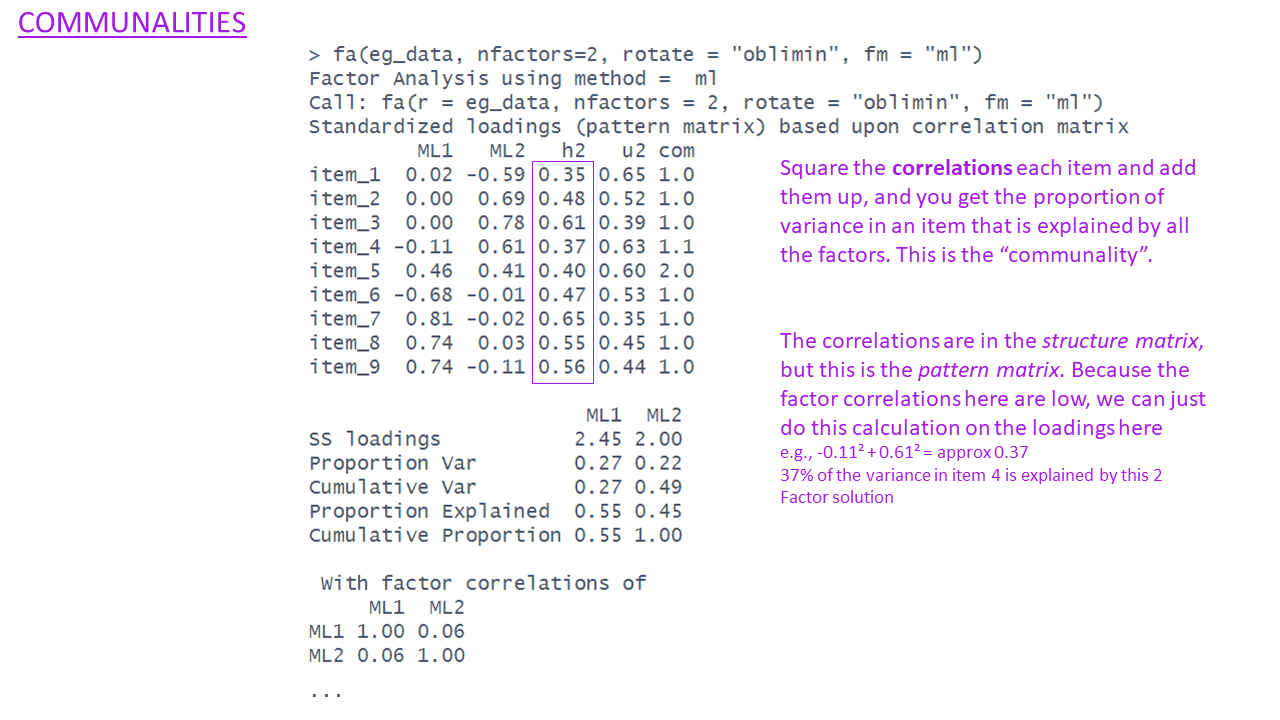
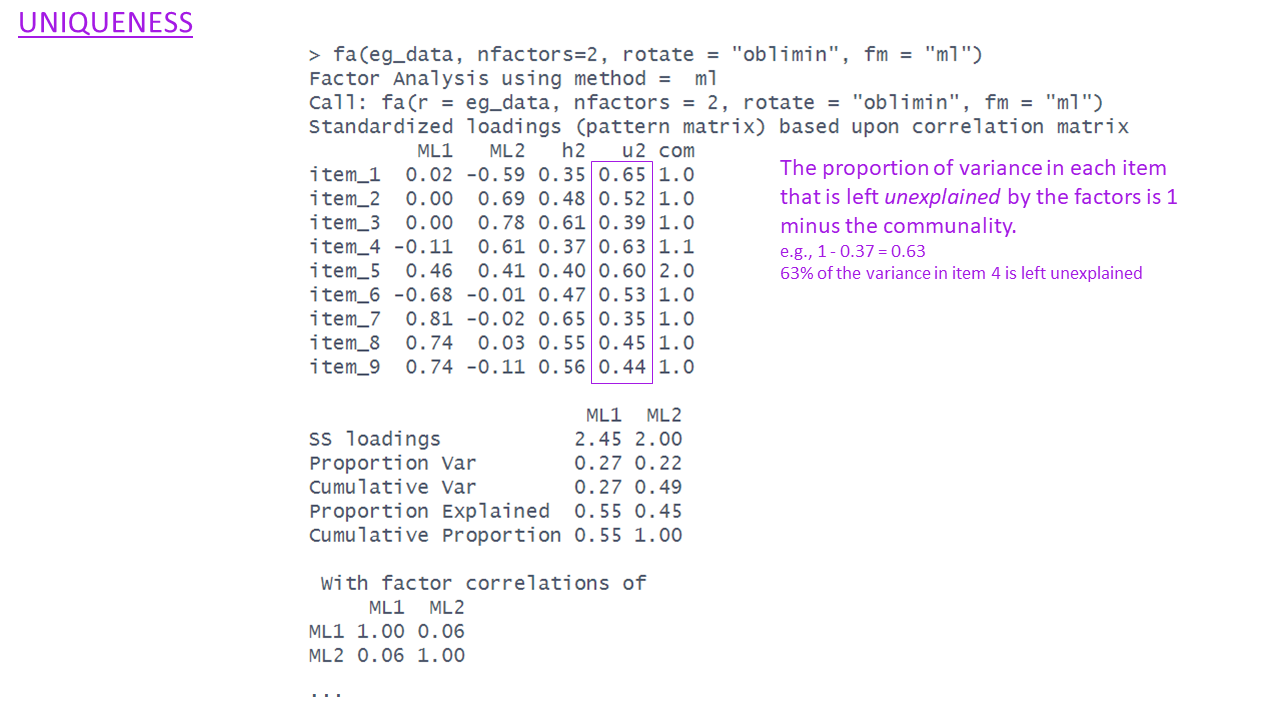
fa(eg_data, nfactors = 2, rotate = "oblimin", fm="ml")
fa(eg_data, nfactors = 2, rotate = "promax", fm="ml")Orthogonal

Oblique

Why rotate?
Factor rotation is an approach to clarifying the relationships between items and factors.
- Rotation aims to maximize the relationship of a measured item with a factor.
- That is, make the primary loading big and cross-loading’s small.