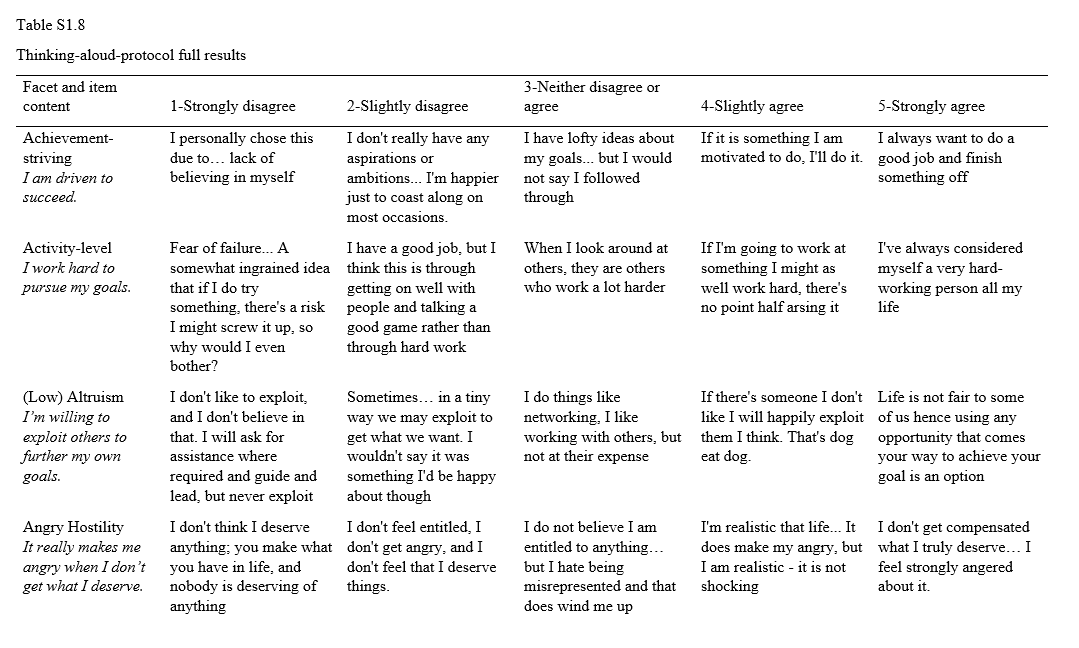
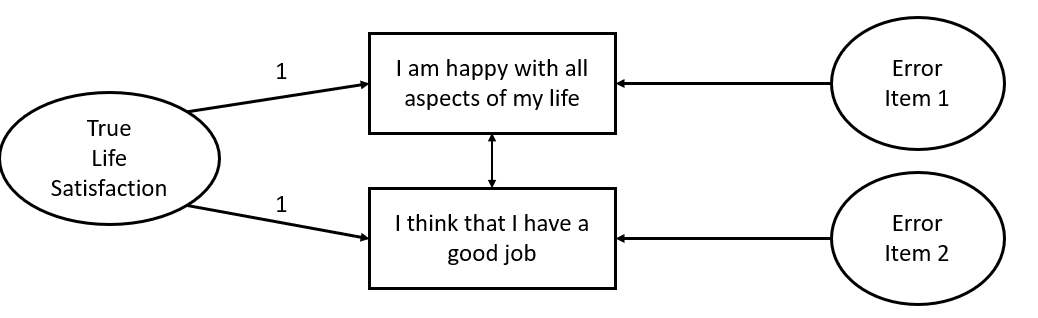
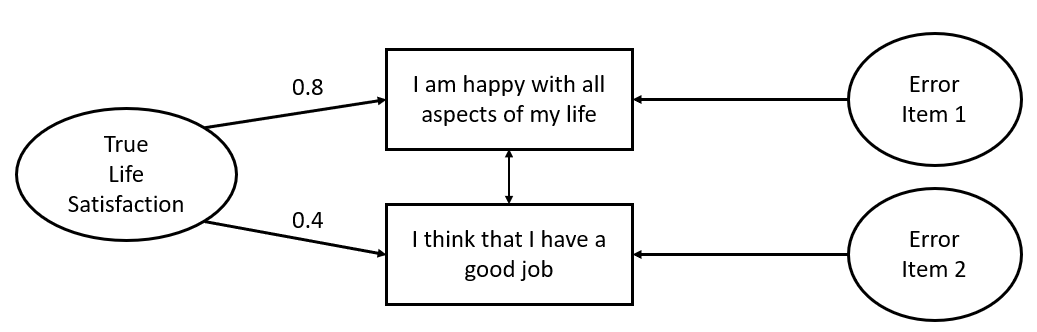
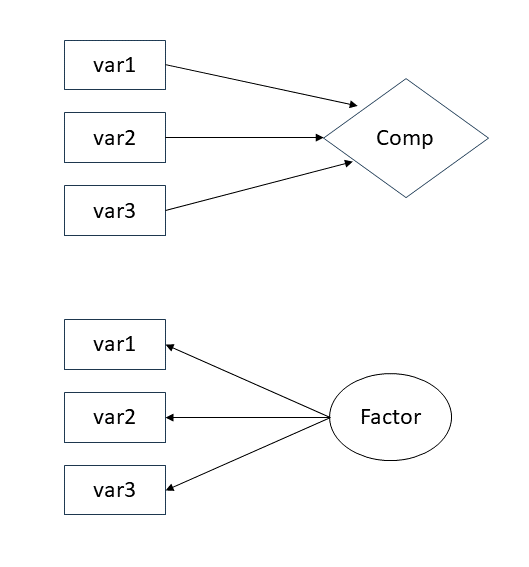
d3 <- read_csv("https://uoepsy.github.io/data/lmm_lifesatscot.csv")
head(d3)# A tibble: 6 × 4
age lifesat dwelling size
<dbl> <dbl> <chr> <chr>
1 40 31 Aberdeen >100k
2 45 56 Glasgow >100k
3 40 51 Glasgow >100k
4 40 55 Dundee >100k
5 40 41 Dundee >100k
6 55 69 Perth <100k