their value of \(\color{red}{y}\) =
some number (\(\color{blue}{b_0}\)) +
some amount (\(\color{blue}{b_1}\)) times their value of \(x\) +
their residual \(\varepsilon_j\)
their value of \(\color{red}{y}\) =
some number for group \(i\) (\(\color{blue}{b_{0i}}\)) +
some amount (\(\color{blue}{b_1}\)) times their value of \(x\) +
their residual \(\varepsilon_{ij}\)
their value of \(\color{red}{y}\) =
some number for group \(i\) (\(\color{blue}{b_{0i}}\)) +
some amount (\(\color{blue}{b_1}\)) times their value of \(x\) +
their residual \(\varepsilon_{ij}\)
group \(i\)’s intercept (\(\color{blue}{b_{0i}}\)) =
the intercept for the average of the population of groups (\(\gamma_{00}\)) +
the deviation of group \(i\) (\(\color{orange}{\zeta_{0i}}\)) from \(\gamma_{00}\)
their value of \(\color{red}{y}\) =
some number for group \(i\) (\(\color{blue}{b_{0i}}\)) +
some amount (\(\color{blue}{b_1}\)) times their value of \(x\) +
their residual \(\varepsilon_{ij}\)
group \(i\)’s intercept (\(\color{blue}{b_{0i}}\)) =
the intercept for the average of the population of groups (\(\gamma_{00}\)) +
the deviation of group \(i\) (\(\color{orange}{\zeta_{0i}}\)) from \(\gamma_{00}\)
We are now assuming \(\color{orange}{\zeta_0}\) and \(\varepsilon\) to be normally distributed with a mean of 0, and we denote their variances as \(\color{orange}{\sigma_0^2}\) and \(\sigma_\varepsilon^2\) respectively.
multi-level (mixed-effects) regression
Sometimes, you will see the levels collapsed into one equation, as it might make for more intuitive reading:
The intercept \(\color{blue}{b_{0i}}\) is a “mix” of two things:
the fixed number \(\gamma_{00}\)
group deviations \(\color{orange}{\zeta_{0i}}\)
NOTE
You do not have to write equations for the DAPR3 report or exam.
As models get more complex, it is much easier to explain your model structure in words rather than equations
“[outcome] was modelled using a linear multilevel model, with fixed effects of [predictors] and by-[grouping] random intercepts.”
We’re still going to go through them in lectures & readings because they provide a clear scaffolding for learning how the models work
Building up the idea
back to our example
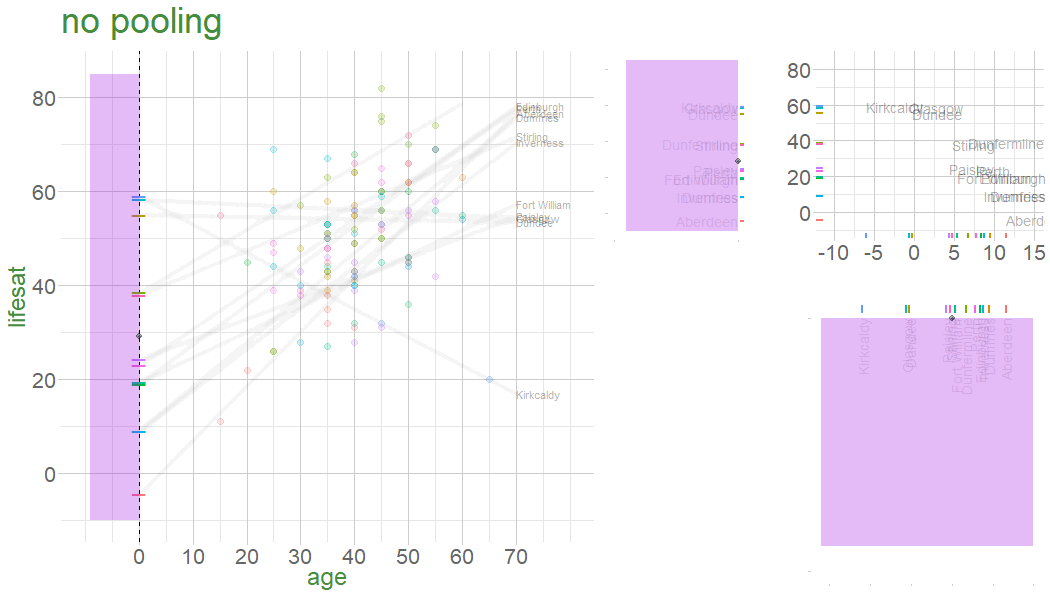
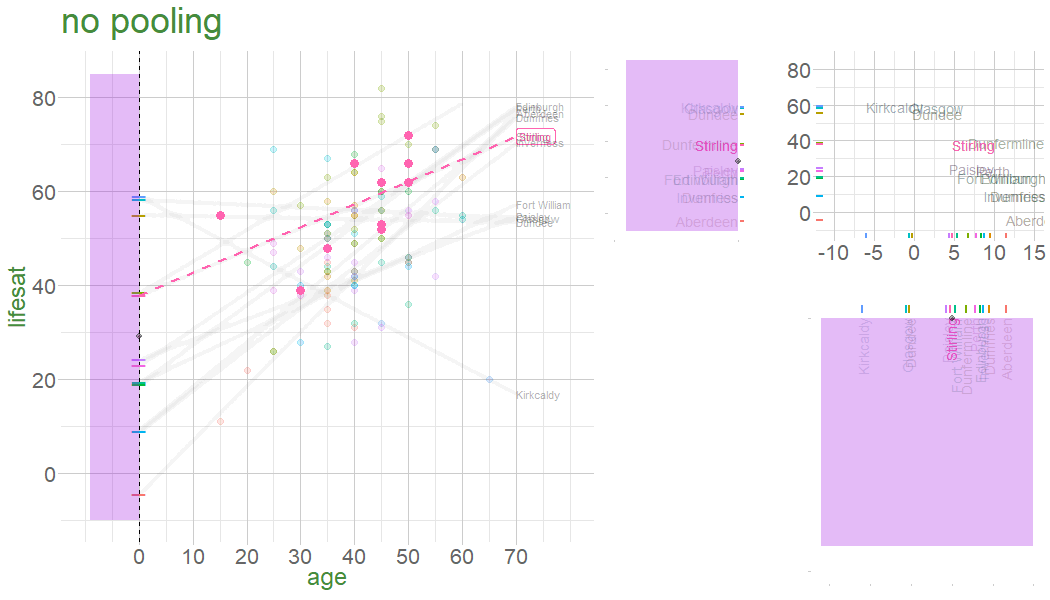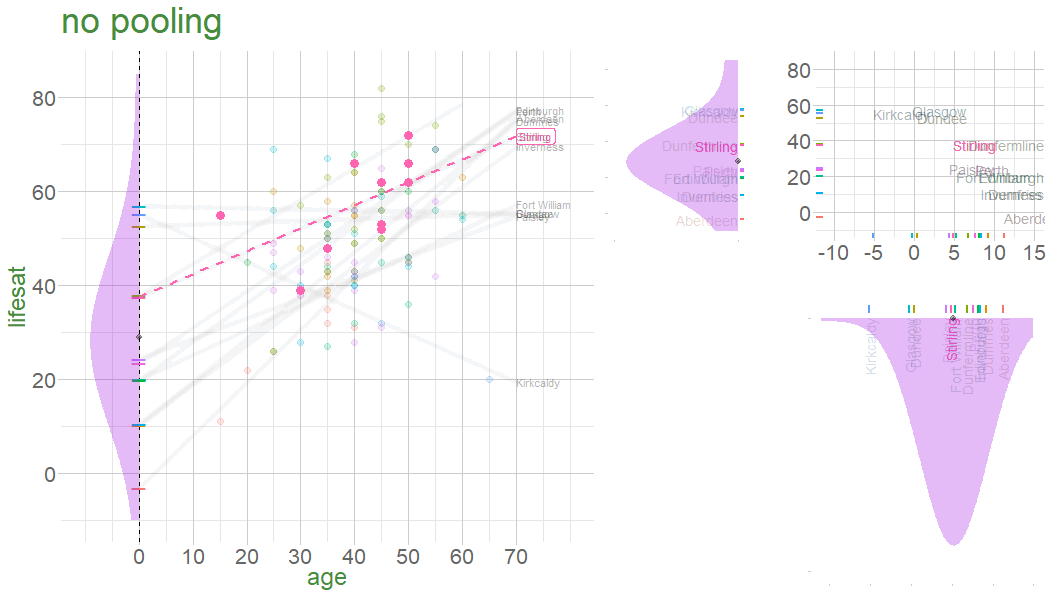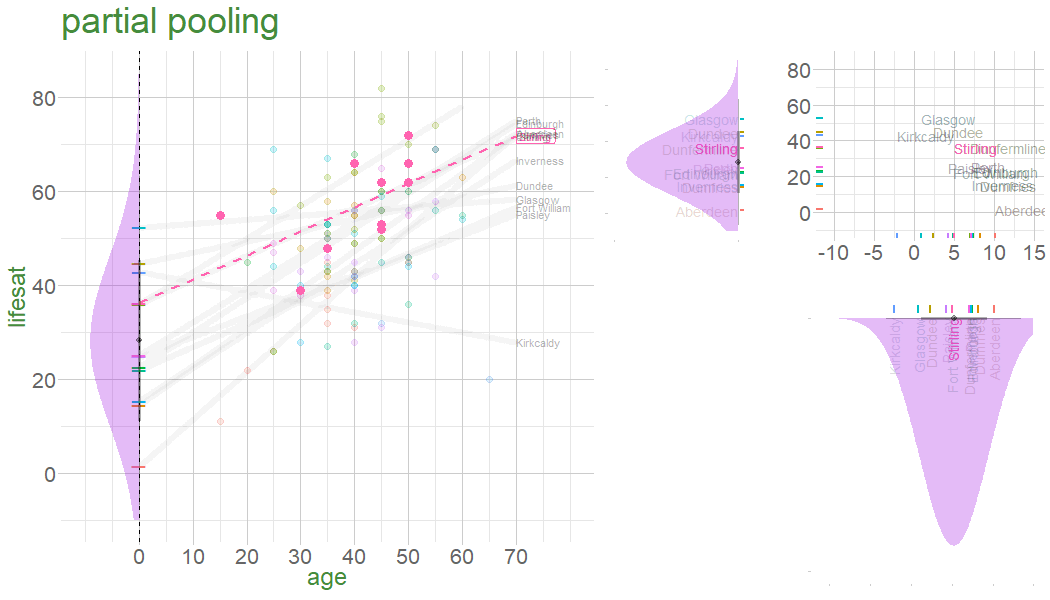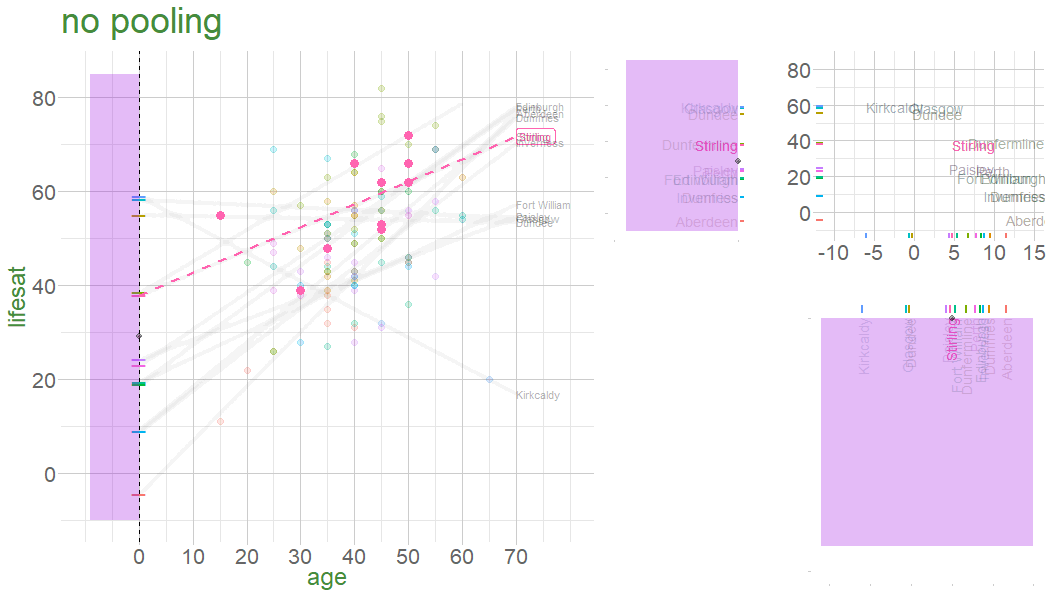
Are older people more satisfied with life? 112 people from 12 different dwellings (cities/towns) in Scotland. Information on their ages and some measure of life satisfaction.
The \(\color{orange}{\zeta}\) components also get termed the “random effects” part of the model, Hence names like “random effects model”, etc.
\(\color{orange}{\zeta_i}\) is “random” because considered a random sample from larger population such that \(\color{orange}{\zeta_{0i}} \sim N(0, \color{orange}{\sigma^2_0})\).
fixed and random
Should variable g be fixed or random?
Repetition: If the experiment were repeated:
Desired inference: The conclusions refer to:
Fixed \(y\,\sim\,~\,...\, +\, g\)
Same groups would be used
The groups used
Random \(y\,\sim\,...\,+\,(\,... |\,g)\)
Different groups would be used
A population from which the groups used are just a (random) sample
their value of \(\color{red}{y}\) =
some number for group \(i\) (\(\color{blue}{b_{0i}}\)) +
some amount (\(\color{blue}{b_1}\)) times their value of \(x\) +
their residual \(\varepsilon_{ij}\)
group \(i\)’s intercept (\(\color{blue}{b_{0i}}\)) =
the intercept for the average of the population of groups (\(\gamma_{00}\)) +
the deviation of group \(i\) (\(\color{orange}{\zeta_{0i}}\)) from \(\gamma_{00}\)
their value of \(\color{red}{y}\) =
some number for group \(i\) (\(\color{blue}{b_{0i}}\)) +
some amount for group \(i\) (\(\color{blue}{b_{1i}}\)) times their value of \(x\) +
their residual \(\varepsilon_{ij}\)
group \(i\)’s intercept (\(\color{blue}{b_{0i}}\)) =
the intercept for the average of the population of groups (\(\gamma_{00}\)) +
the deviation of group \(i\) (\(\color{orange}{\zeta_{0i}}\)) from \(\gamma_{00}\)
group \(i\)’s slope (\(\color{blue}{b_{1i}}\)) =
the slope for the average of the population of groups (\(\gamma_{10}\)) +
the deviation of group \(i\) (\(\color{orange}{\zeta_{1i}}\)) from \(\gamma_{10}\)
their value of \(\color{red}{y}\) =
some number for group \(i\) (\(\color{blue}{b_{0i}}\)) +
some amount for group \(i\) (\(\color{blue}{b_{1i}}\)) times their value of \(x\) +
their residual \(\varepsilon_{ij}\)
group \(i\)’s intercept (\(\color{blue}{b_{0i}}\)) =
the intercept for the average of the population of groups (\(\gamma_{00}\)) +
the deviation of group \(i\) (\(\color{orange}{\zeta_{0i}}\)) from \(\gamma_{00}\)
group \(i\)’s slope (\(\color{blue}{b_{1i}}\)) =
the slope for the average of the population of groups (\(\gamma_{10}\)) +
the deviation of group \(i\) (\(\color{orange}{\zeta_{1i}}\)) from \(\gamma_{10}\)
group deviations for intercepts and slopes are normally distributed with mean of 0 and standard deviations of \(\color{orange}{\sigma_0}\) and \(\color{orange}{\sigma_1}\) respectively, and with a correlation of \(\color{orange}{\rho_{01}}\).
random intercepts, random slopes
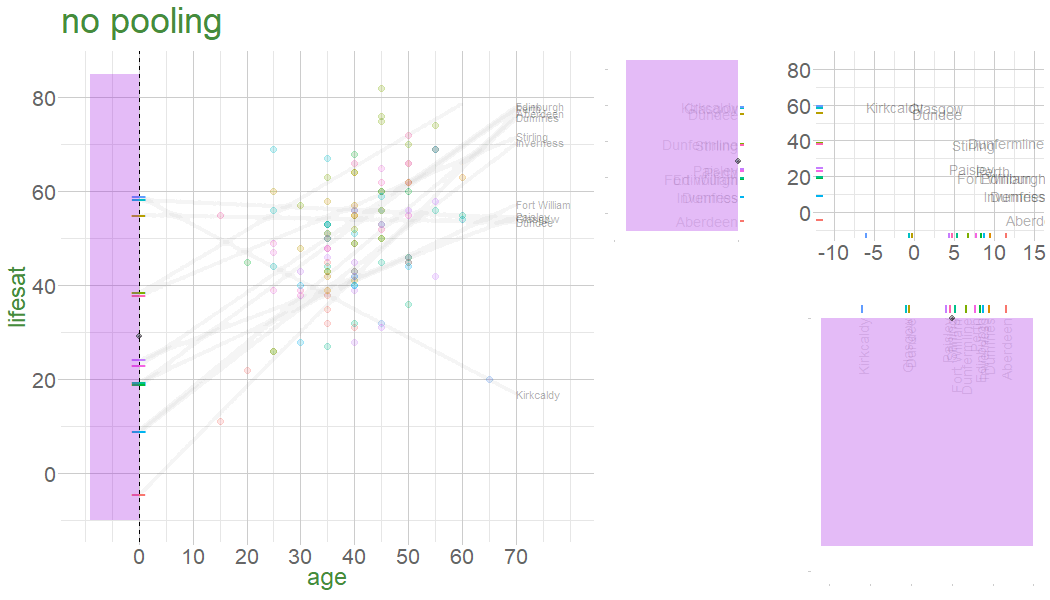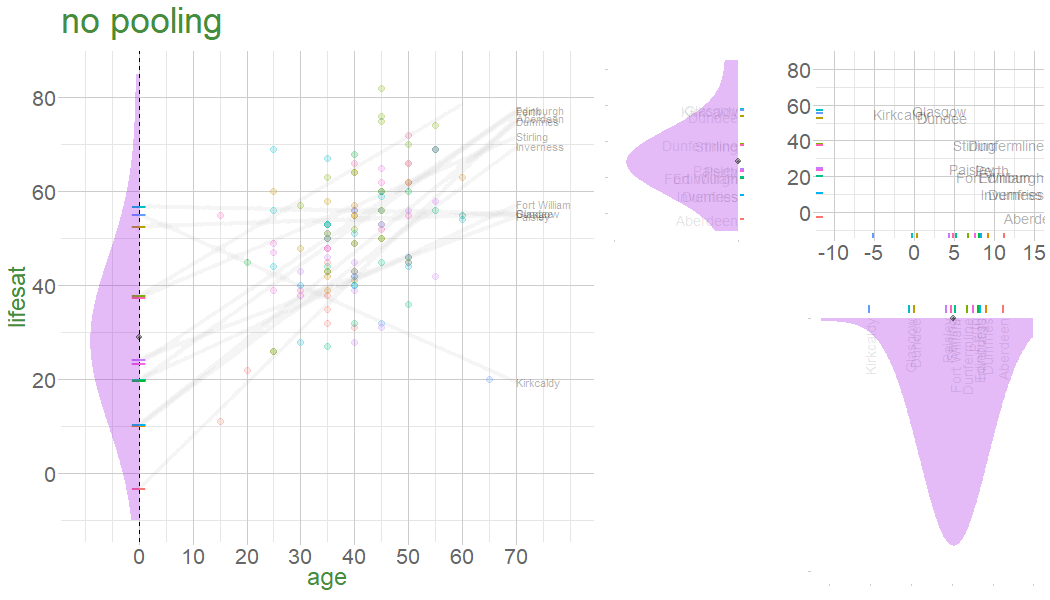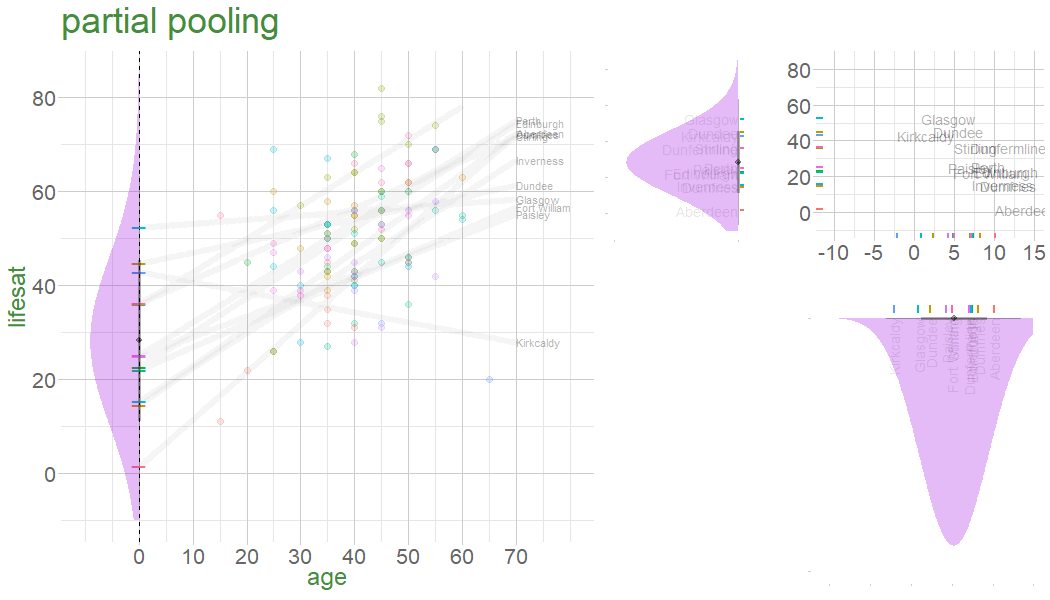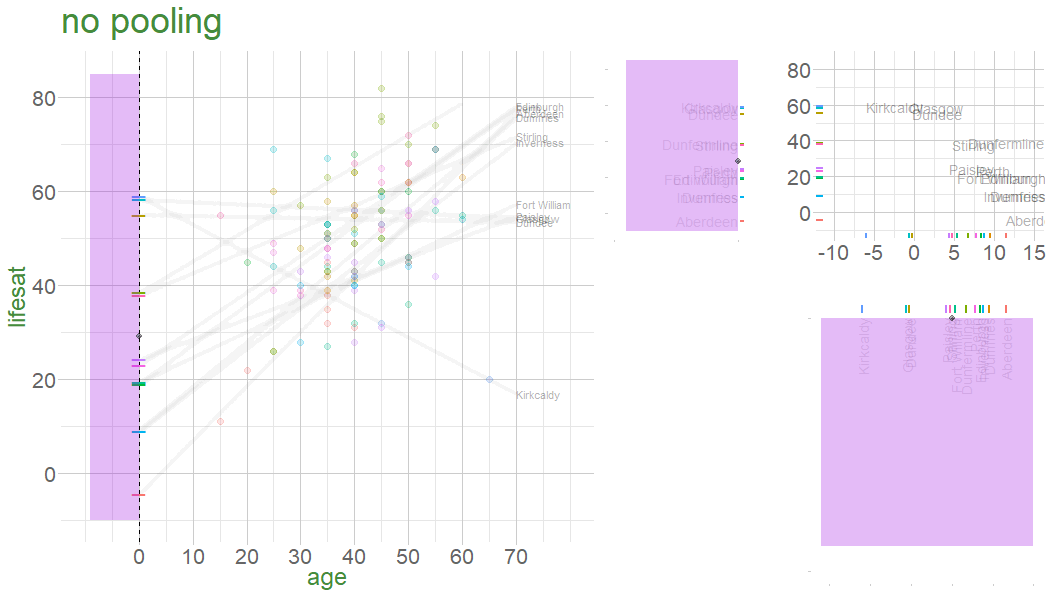
the multilevel model: partial pooling
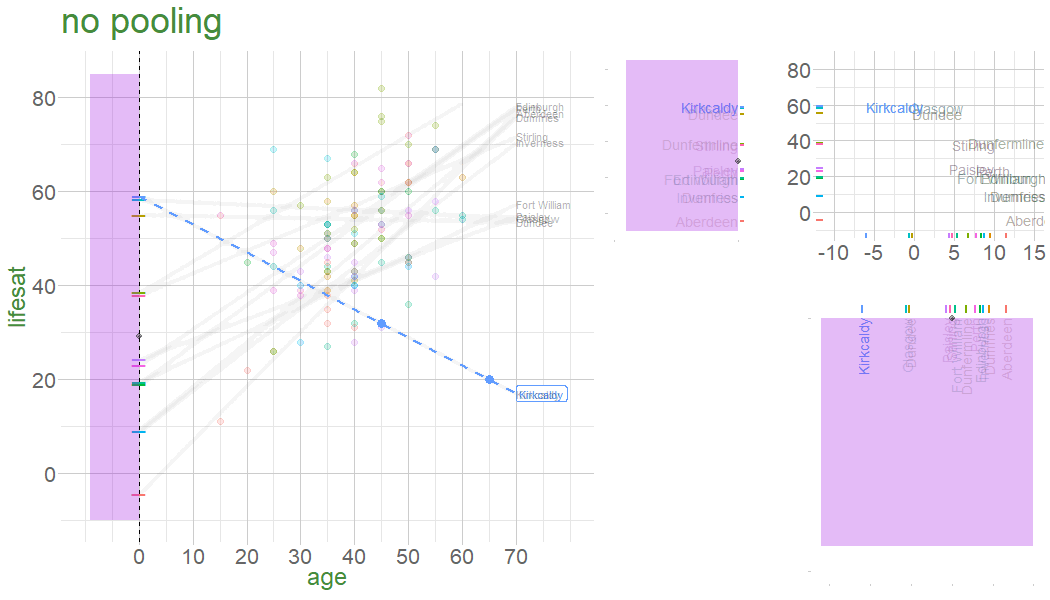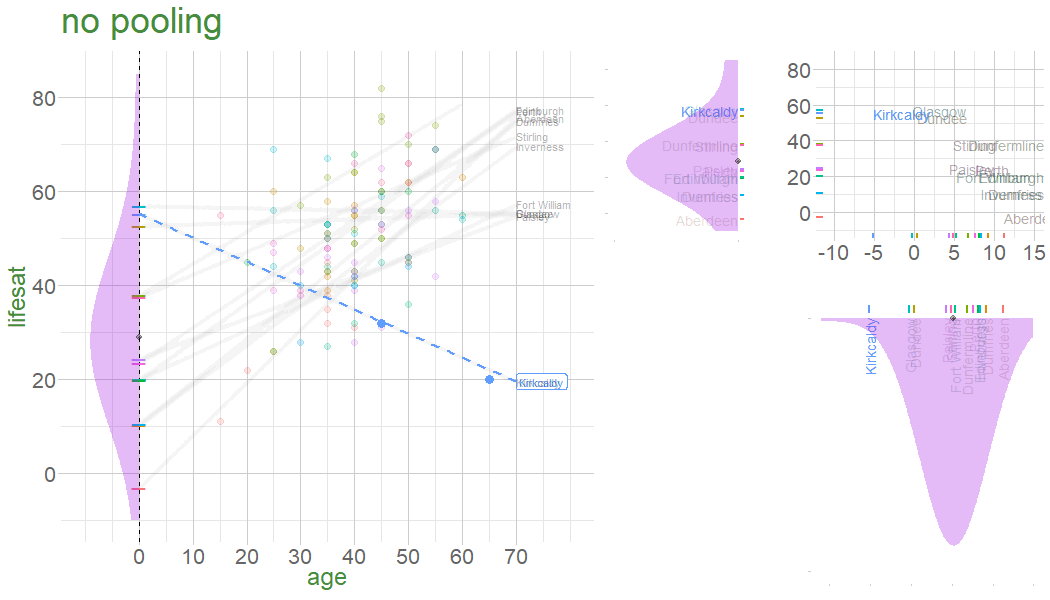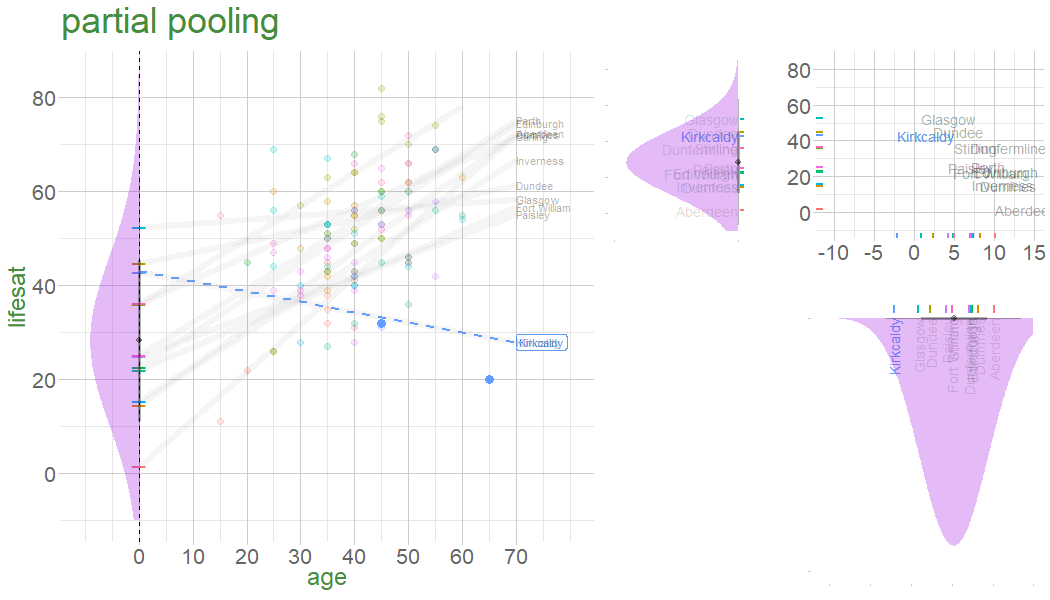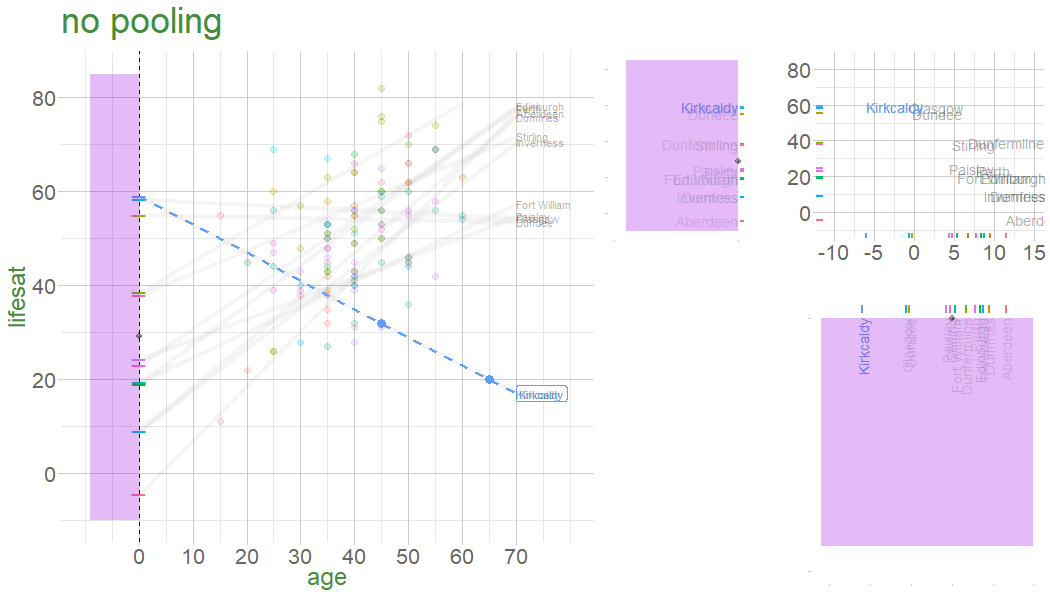
In a no-pooling approach, information is not combined in anyway (data from cluster \(i\) contributes to the slope for cluster \(i\), but nothing else.
Information from Glasgow, Edinburgh, Perth, Dundee etc doesn’t influence what we think about Stirling
In the multilevel model, we model group deviations as normally distributed with a variance of \(\color{orange}{\sigma^2_b}\).
clusters’ contributions to the model depend on:
\(\color{orange}{\sigma^2_b}\) relative to \(\sigma^2_\varepsilon\)
the amount of data in each cluster
the multilevel model: partial pooling
In a no-pooling approach, information is not combined in anyway (data from cluster \(i\) contributes to the slope for cluster \(i\), but nothing else.
Information from Glasgow, Edinburgh, Perth, Dundee etc doesn’t influence what we think about Stirling
In the multilevel model, we model group deviations as normally distributed with a variance of \(\color{orange}{\sigma^2_b}\).
clusters’ contributions to the model depend on:
how distinct the clustering is
how big a cluster is
cluster specific predictions are shrunk towards the average depending on:
Multi-level models can be used to answer multi-level questions!
Do phenomena at Level X influence effects at Level Y?
example: \(n\) children’s grades are recorded every year throughout school
Q: Does being mono/bi-lingual influence childrens’ grades over the duration of their schooling?
Multi-level models can be used to answer multi-level questions!
Do phenomena at Level X influence effects at Level Y?
example: \(n\) children’s grades are recorded every year throughout school
Q: Does being mono/bi-lingual influence childrens’ grades over the duration of their schooling?
Multi-level models can be used to answer multi-level questions!
Do random variances covary?
example: \(n\) participants’ cognitive ability is measured across time.
Q: Do people who have higher cognitive scores at start of study show less decline over the study period than those who have lower scores?
lme4 package (many others are available, but lme4 is most popular).
The lmer() function. syntax is similar to lm(), in that we specify:
[outcome variable] ~ [explanatory variables], data = [name of dataframe]
in lmer(), we have to also specify the random effect structure in parentheses:
[outcome variable] ~ [explanatory variables] + ([vary this] | [by this grouping variable]), data = [name of dataframe], REML = [TRUE/FALSE]
A new example
In a study examining how cognition changes over time, a sample of 20 participants took the Addenbrooke’s Cognitive Examination (ACE) every 2 years from age 60 to age 78.
# A tibble: 6 × 7
sitename ppt condition visit age ACE imp
<chr> <chr> <chr> <dbl> <dbl> <dbl> <chr>
1 Sncbk PPT_1 control 1 60 84.5 unimp
2 Sncbk PPT_1 control 2 62 85.6 imp
3 Sncbk PPT_1 control 3 64 84.5 imp
4 Sncbk PPT_1 control 4 66 83.1 imp
5 Sncbk PPT_1 control 5 68 82.3 imp
6 Sncbk PPT_1 control 6 70 83.3 imp
pptplots <-ggplot(d3, aes(x = visit, y = ACE, col = ppt)) +geom_point() +facet_wrap(~ppt) +guides(col ="none") +labs(x ="visit", y ="cognition")
pptplots
Fitting an lm
lm_mod <-lm(ACE ~1+ visit, data = d3)summary(lm_mod)
Call:
lm(formula = ACE ~ 1 + visit, data = d3)
Residuals:
Min 1Q Median 3Q Max
-4.868 -1.054 -0.183 1.146 6.632
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 85.6259 0.3022 283.3 < 2e-16 ***
visit -0.3857 0.0488 -7.9 2.9e-13 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.88 on 175 degrees of freedom
Multiple R-squared: 0.263, Adjusted R-squared: 0.259
F-statistic: 62.5 on 1 and 175 DF, p-value: 2.9e-13
pptplots +geom_line(aes(y=fitted(lm_mod)), col ="blue", lwd=1)
random intercept
vary the intercept by participant.
library(lme4)ri_mod <-lmer(ACE ~1+ visit + (1| ppt), data = d3)summary(ri_mod)
Linear mixed model fit by REML ['lmerMod']
Formula: ACE ~ 1 + visit + (1 | ppt)
Data: d3
REML criterion at convergence: 595
Scaled residuals:
Min 1Q Median 3Q Max
-2.8830 -0.5445 -0.0232 0.6491 3.0494
Random effects:
Groups Name Variance Std.Dev.
ppt (Intercept) 2.25 1.5
Residual 1.21 1.1
Number of obs: 177, groups: ppt, 20
Fixed effects:
Estimate Std. Error t value
(Intercept) 85.6497 0.3800 225.4
visit -0.3794 0.0287 -13.2
Correlation of Fixed Effects:
(Intr)
visit -0.411
pptplots +geom_line(aes(y=fitted(ri_mod)), col ="red", lwd=1)
Linear mixed model fit by REML ['lmerMod']
Formula: ACE ~ 1 + visit * condition + (1 + visit | ppt)
Data: d3
REML criterion at convergence: 362
Scaled residuals:
Min 1Q Median 3Q Max
-2.296 -0.686 -0.041 0.686 2.420
Random effects:
Groups Name Variance Std.Dev. Corr
ppt (Intercept) 0.1467 0.383
visit 0.0769 0.277 -0.49
Residual 0.2445 0.495
Number of obs: 177, groups: ppt, 20
Fixed effects:
Estimate Std. Error t value
(Intercept) 85.7353 0.1688 507.79
visit -0.5319 0.0897 -5.93
conditionmindfulness -0.2979 0.2362 -1.26
visit:conditionmindfulness 0.3459 0.1269 2.73
Correlation of Fixed Effects:
(Intr) visit cndtnm
visit -0.471
cndtnmndfln -0.715 0.337
vst:cndtnmn 0.333 -0.707 -0.473
lmer output
summary(model)
Linear mixed model fit by REML ['lmerMod']
Formula: y ~ x + (1 + x | group)
Data: my_data
REML criterion at convergence: 335
Scaled residuals:
Min 1Q Median 3Q Max
-2.1279 -0.7009 0.0414 0.6645 2.1010
Random effects:
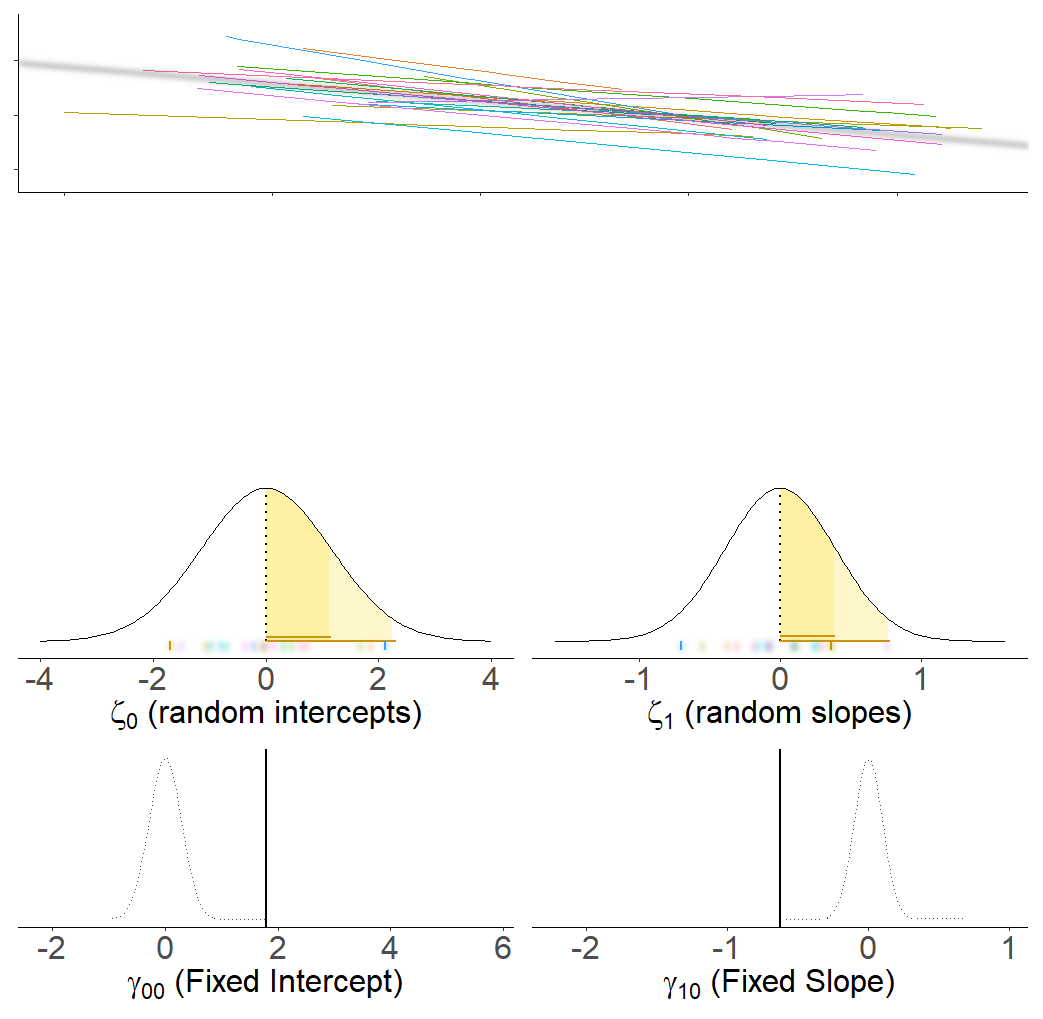
Groups Name Variance Std.Dev. Corr
group (Intercept) 1.326 1.152
x 0.152 0.390 -0.88
Residual 0.262 0.512
Number of obs: 170, groups: group, 20
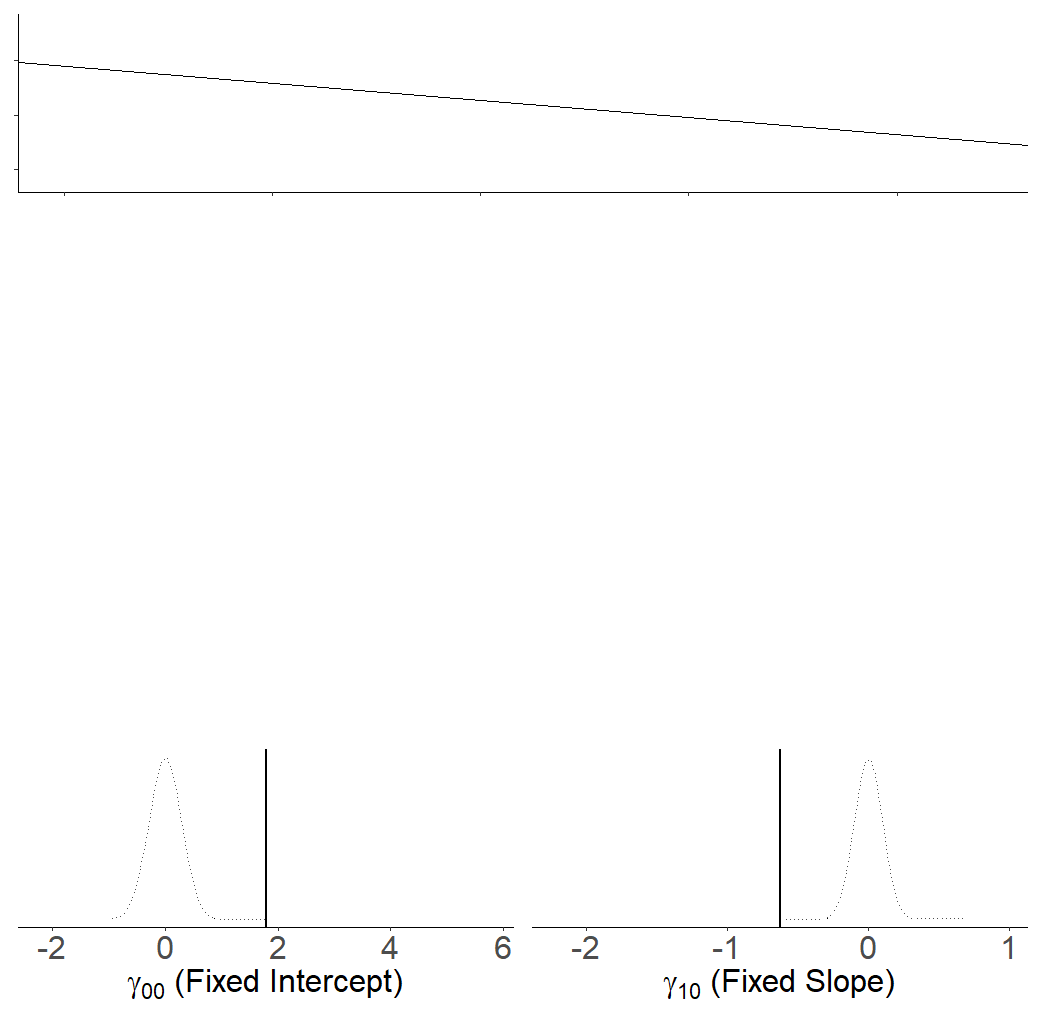
Fixed effects:
Estimate Std. Error t value
(Intercept) 1.7890 0.2858 6.26
x -0.6250 0.0996 -6.27
lmer output
summary(model)
Linear mixed model fit by REML ['lmerMod']
Formula: y ~ x + (1 + x | group)
Data: my_data
REML criterion at convergence: 335
Scaled residuals:
Min 1Q Median 3Q Max
-2.1279 -0.7009 0.0414 0.6645 2.1010
Random effects:
Groups Name Variance Std.Dev. Corr
group (Intercept) 1.326 1.152
x 0.152 0.390 -0.88
Residual 0.262 0.512
Number of obs: 170, groups: group, 20
Fixed effects:
Estimate Std. Error t value
(Intercept) 1.7890 0.2858 6.26
x -0.6250 0.0996 -6.27
lmer output
summary(model)
Linear mixed model fit by REML ['lmerMod']
Formula: y ~ x + (1 + x | group)
Data: my_data
REML criterion at convergence: 335
Scaled residuals:
Min 1Q Median 3Q Max
-2.1279 -0.7009 0.0414 0.6645 2.1010
Random effects:
Groups Name Variance Std.Dev. Corr
group (Intercept) 1.326 1.152
x 0.152 0.390 -0.88
Residual 0.262 0.512
Number of obs: 170, groups: group, 20
Fixed effects:
Estimate Std. Error t value
(Intercept) 1.7890 0.2858 6.26
x -0.6250 0.0996 -6.27
lmer output
summary(model)
Linear mixed model fit by REML ['lmerMod']
Formula: y ~ x + (1 + x | group)
Data: my_data
REML criterion at convergence: 335
Scaled residuals:
Min 1Q Median 3Q Max
-2.1279 -0.7009 0.0414 0.6645 2.1010
Random effects:
Groups Name Variance Std.Dev. Corr
group (Intercept) 1.326 1.152
x 0.152 0.390 -0.88
Residual 0.262 0.512
Number of obs: 170, groups: group, 20
Fixed effects:
Estimate Std. Error t value
(Intercept) 1.7890 0.2858 6.26
x -0.6250 0.0996 -6.27
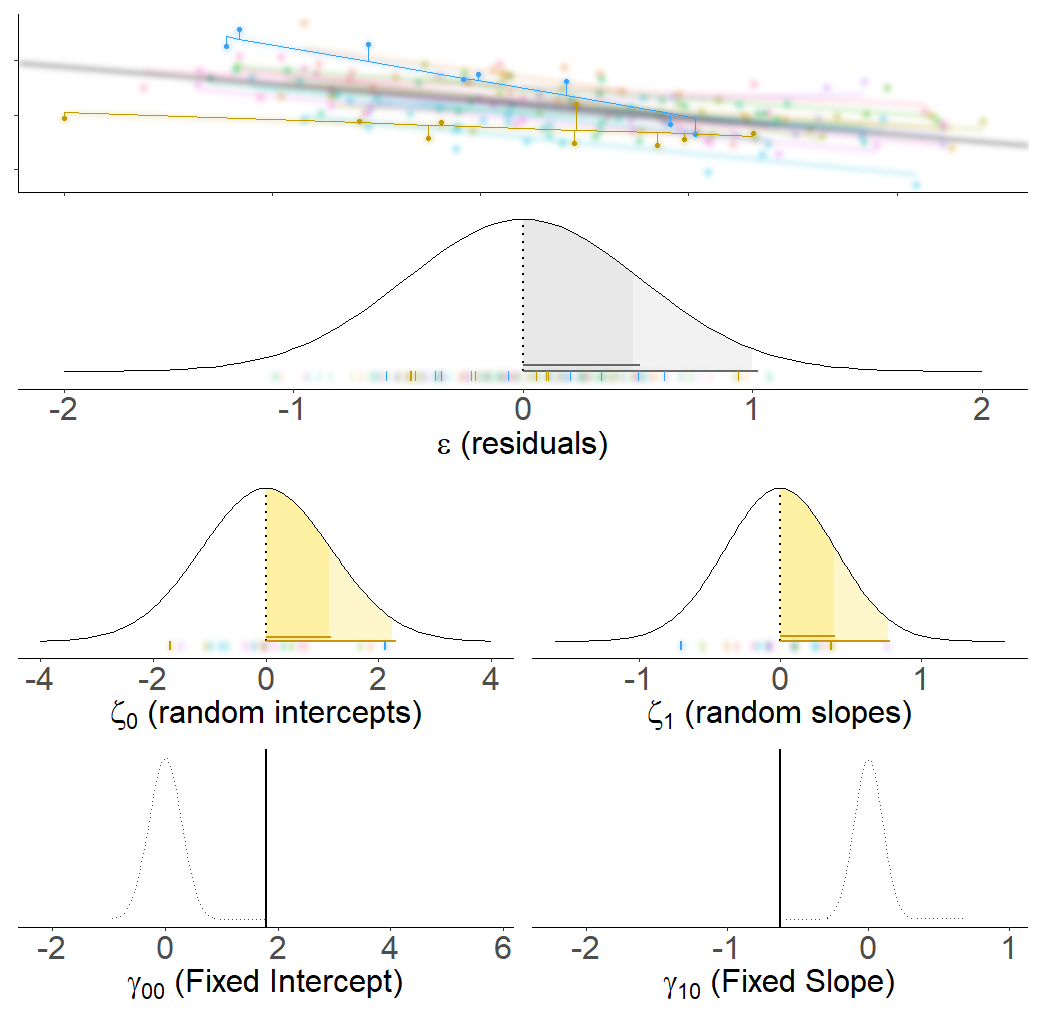
Model Parameters
summary(model)
Linear mixed model fit by REML ['lmerMod']
Formula: y ~ x + (1 + x | group)
Data: my_data
REML criterion at convergence: 335
Scaled residuals:
Min 1Q Median 3Q Max
-2.1279 -0.7009 0.0414 0.6645 2.1010
Random effects:
Groups Name Variance Std.Dev. Corr
group (Intercept) 1.326 1.152
x 0.152 0.390 -0.88
Residual 0.262 0.512
Number of obs: 170, groups: group, 20
Fixed effects:
Estimate Std. Error t value
(Intercept) 1.7890 0.2858 6.26
x -0.6250 0.0996 -6.27
Fixed effects:
fixef(model)
(Intercept) x
1.789 -0.625
Variance components:
VarCorr(model)
Groups Name Std.Dev. Corr
group (Intercept) 1.152
x 0.390 -0.88
Residual 0.512
Model Predictions: ranef, coef
summary(model)
Linear mixed model fit by REML ['lmerMod']
Formula: y ~ x + (1 + x | group)
Data: my_data
REML criterion at convergence: 335
Scaled residuals:
Min 1Q Median 3Q Max
-2.1279 -0.7009 0.0414 0.6645 2.1010
Random effects:
Groups Name Variance Std.Dev. Corr
group (Intercept) 1.326 1.152
x 0.152 0.390 -0.88
Residual 0.262 0.512
Number of obs: 170, groups: group, 20
Fixed effects:
Estimate Std. Error t value
(Intercept) 1.7890 0.2858 6.26
x -0.6250 0.0996 -6.27
Degrees of freedom for multilevel models is not clear
Lots and lots of different methods
library(lmerTest) # overwrites the lmer() functionmodel <-lmer(y ~ x + (1+ x | group), my_data)summary(model)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: y ~ x + (1 + x | group)
Data: my_data
REML criterion at convergence: 335
Scaled residuals:
Min 1Q Median 3Q Max
-2.1279 -0.7009 0.0414 0.6645 2.1010
Random effects:
Groups Name Variance Std.Dev. Corr
group (Intercept) 1.326 1.152
x 0.152 0.390 -0.88
Residual 0.262 0.512
Number of obs: 170, groups: group, 20
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 1.7890 0.2858 16.4478 6.26 0.000010 ***
x -0.6250 0.0996 15.4780 -6.27 0.000013 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr)
x -0.894
Inference
Degrees of freedom for multilevel models is not clear
Lots and lots of different methods
restricted_model <-lmer(y ~1+ (1+ x | group), my_data)model <-lmer(y ~1+ x + (1+ x | group), my_data)anova(restricted_model, model) # likelihood ratio test
We can extend our linear model equation to model certain parameters as random cluster-level adjustments around a fixed center.
\(\color{red}{y_i} = \color{blue}{b_0 \cdot{} 1 \; + \; b_1 \cdot{} x_{i} } + \varepsilon_i\)
if we allow the intercept to vary by cluster, becomes: \(\color{red}{y_{ij}} = \color{blue}{b_{0i} \cdot 1 + b_{1} \cdot x_{ij}} + \varepsilon_{ij}\) \(\color{blue}{b_{0i}} = \gamma_{00} + \color{orange}{\zeta_{0i}}\)
We can express this as one equation if we prefer: \(\color{red}{y_{ij}} = \underbrace{(\gamma_{00} + \color{orange}{\zeta_{0i}})}_{\color{blue}{b_{0i}}} \cdot 1 + \color{blue}{b_{1} \cdot x_{ij}} + \varepsilon_{ij}\)
We can allow slopes to vary by-cluster too.
This allows us to model cluster-level variation around the intercept (“random intercepts”) and around slopes (“random slopes”).
We can fit this using the lme4 package in R
This week
Tasks
Complete readings
Attend your lab and work together on the exercises























 Complete readings
Complete readings Attend your lab and work together on the exercises
Attend your lab and work together on the exercises Complete the weekly quiz
Complete the weekly quiz Piazza forum!
Piazza forum! Office hours (see Learn page for details)
Office hours (see Learn page for details)