lm(score ~ hours + motivation, data = test_study2)Testing and Evaluating LM
Data Analysis for Psychology in R 2
Defining the Null
Conceptually:
- If \(x\) yields no information on \(y\), then \(\beta_1 = 0\)
Why would this be the case?
\(\beta\) gives the predicted change in \(y\) for a unit change in \(x\)
- If \(x\) and \(y\) are unrelated, then a change in \(x\) will not result in any change to the predicted value of \(y\)
- So for a unit change in \(x\), there is no (=0) change in \(y\)
We can state this formally as a null and alternative:
\[H_0: \beta_1 = 0\] \[H_1: \beta_1 \neq 0\]

Sampling Distribution for the Null
So what about \(p\)?
\(p\) refers to the likelihood of having results as extreme as ours, given \(H_0\) is true
To compute that likelihood, we need a sampling distribution for the null
For \(\beta\), this is a \(t\)-distribution
Remember, the shape of the \(t\)-distribution changes depending on the degrees of freedom

- For \(\beta\), we use a \(t\)-distribution with \(n-k-1\) degrees of freedom
- \(n\) = sample size
- \(k\) = number of predictors
- The additional - 1 represents the intercept
Visualise the Null

- \(t\)-distribution with 147 df (our null distribution)
Visualise the Null

\(t\)-distribution with 147 df (our null distribution)
Critical values \((t^*)\) establish a boundary for significance
- The probability that a \(t\)-value will fall within these extreme regions of the distribution given \(H_0\) is true is equal to \(\alpha\)
- Because we are performing a two-tailed test, \(\alpha\) is split between each tail:
- The probability that a \(t\)-value will fall within these extreme regions of the distribution given \(H_0\) is true is equal to \(\alpha\)
Visualise the Null

\(t\)-distribution with 147 df (our null distribution)
Critical values \((t^*)\) establish a boundary for significance
- The probability that a \(t\)-value will fall within these extreme regions of the distribution given \(H_0\) is true is equal to \(\alpha\)
- Because we are performing a two-tailed test, \(\alpha\) is split between each tail:
- The probability that a \(t\)-value will fall within these extreme regions of the distribution given \(H_0\) is true is equal to \(\alpha\)
(LowerCrit = round(qt(0.025, 147), 3))[1] -1.98(UpperCrit = round(qt(0.975, 147), 3))[1] 1.98Visualise the Null

\(t\)-distribution with 147 df (our null distribution)
Critical values \((t^*)\) establish a boundary for significance
- The probability that a \(t\)-value will fall within these extreme regions of the distribution given \(H_0\) is true is equal to \(\alpha\)
- Because we are performing a two-tailed test, \(\alpha\) is split between each tail:
- The probability that a \(t\)-value will fall within these extreme regions of the distribution given \(H_0\) is true is equal to \(\alpha\)
(LowerCrit = round(qt(0.025, 147), 3))[1] -1.98(UpperCrit = round(qt(0.975, 147), 3))[1] 1.98- \(t\) = 2.388, \(p\) = .018
Total Sum of Squares
- Each Sums of Squares measure quantifies different sources of variation
\[SS_{Total} = \sum_{i=1}^{n}(y_i - \bar{y})^2\]
Squared distance of each data point from the mean of \(y\)
Mean is our baseline

Residual Sum of Squares
- Each Sums of Squares measure quantifies different sources of variation
\[SS_{Residual} = \sum_{i=1}^{n}(y_i - \hat{y}_i)^2\]
This may look familiar
Squared distance of each point from the predicted value

Model Sums of Squares
- Each Sums of Squares measure quantifies different sources of variation
\[SS_{Model} = \sum_{i=1}^{n}(\hat{y}_i - \bar{y})^2\]
The deviance of the predicted scores from the mean of \(y\)
Easy to calculate if we know total sum of squares and residual sum of squares
\[SS_{Model} = SS_{Total} - SS_{Residual}\]

In our Example
summary(performance)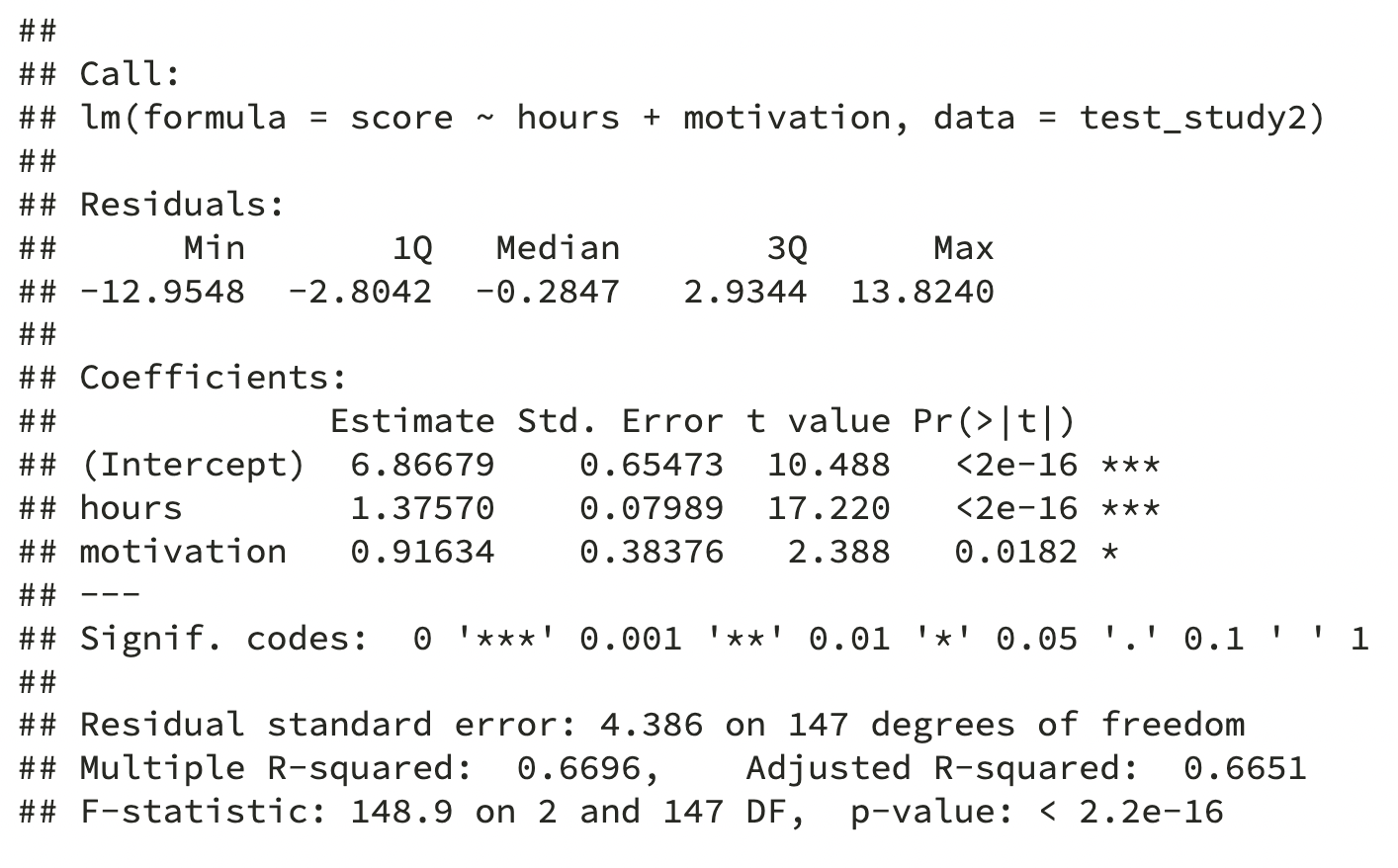
Based on adjusted R-squared, hours studying and student motivation explain 66.5% of the variance in test scores
As the sample size is large and the number of predictors small, unadjusted (0.67) and adjusted R-squared (0.665) are similar
This Week
Tasks

Attend your lab and work together on the exercises

Complete the weekly quiz
Support

Help each other on the Piazza forum

Attend office hours (see Learn page for details)