
Linear Model: Introduction
Data Analysis for Psychology in R 2
Predictions and Data

| Age | PredictedLength |
|---|---|
| 10.0 | 95 |
| 10.2 | 96 |
| 10.5 | 97 |
| 10.8 | 98 |
| 11.0 | 99 |
| 11.2 | 100 |
| 11.5 | 101 |
| 11.8 | 102 |
| 12.0 | 103 |
- Our predictions are points which fall on our line (representing the model, as a function)
- The arrows are showing how we can use the model to find a predicted value
Length & Age is Non-Linear

- Our red line is plotted based on the mean length for different ages real data
Deterministic vs Statistical Models
A deterministic model is a model for an exact relationship:
\[ y = \underbrace{3 + 2 x}_{f(x)} \]

A statistical model allows for case-by-case variability:
\[ y = \underbrace{3 + 2 x}_{f(x)} + \epsilon \]

Scatterplot of Data


- The line represents the best model
Definition of the Line
The line can be described by two values:
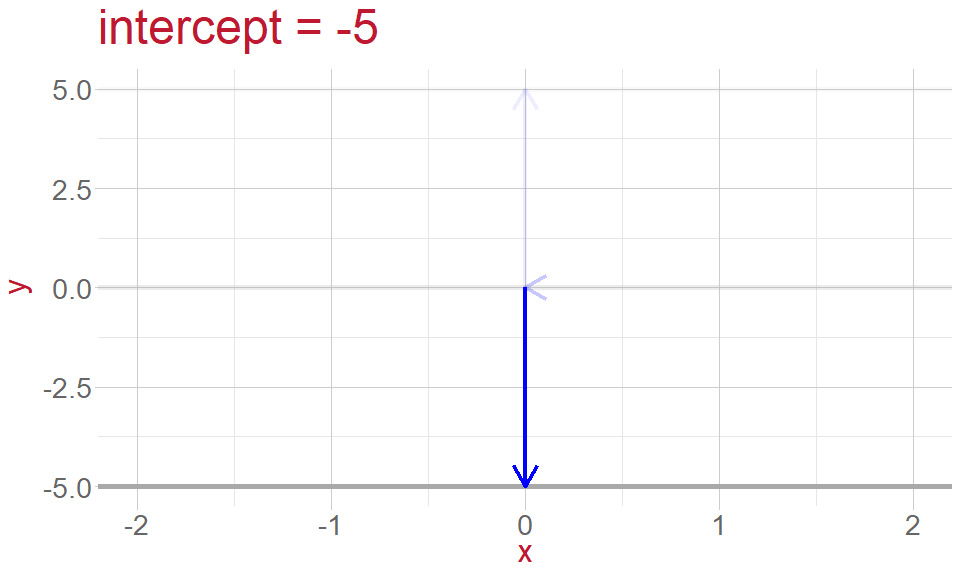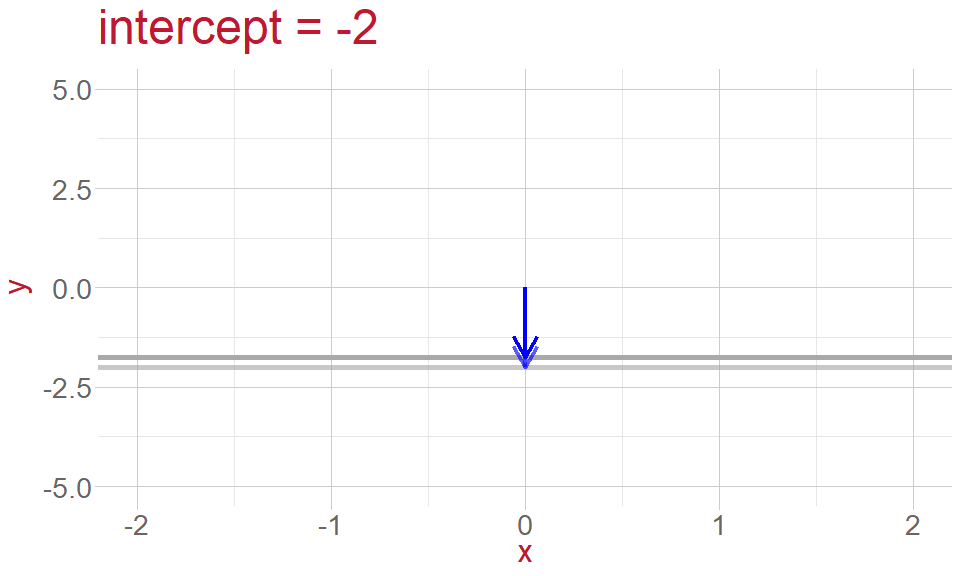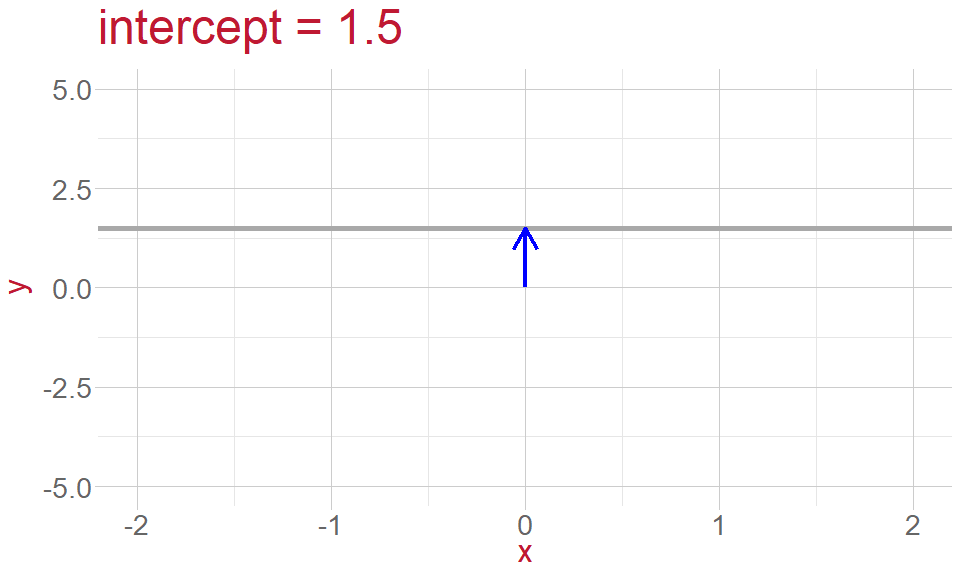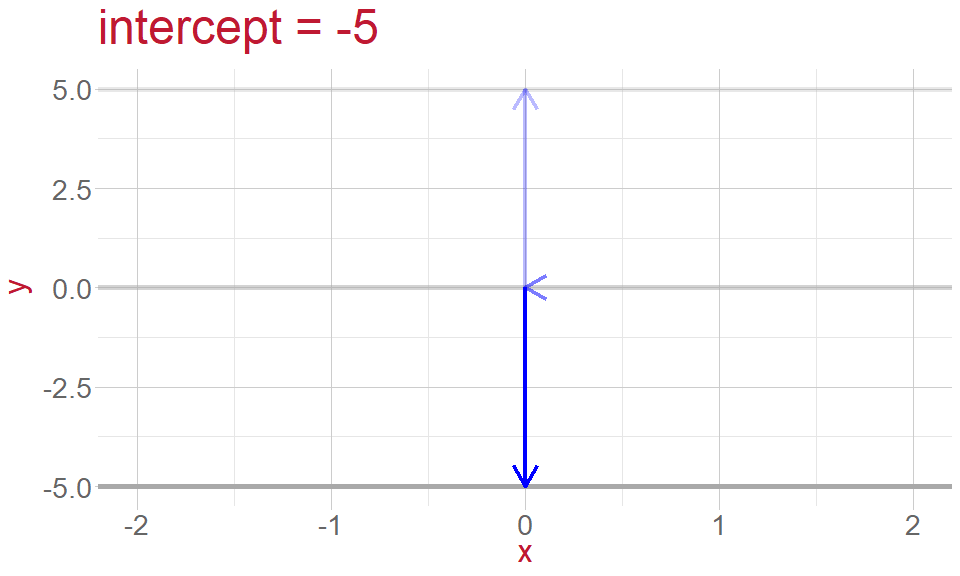
Intercept: the point where the line crosses the \(y\) -axis and \(x = 0\)
Slope: the gradient of the line, or rate of change

Intercept and Slope
- height of the line (intercept)
- gradient of the line (slope)
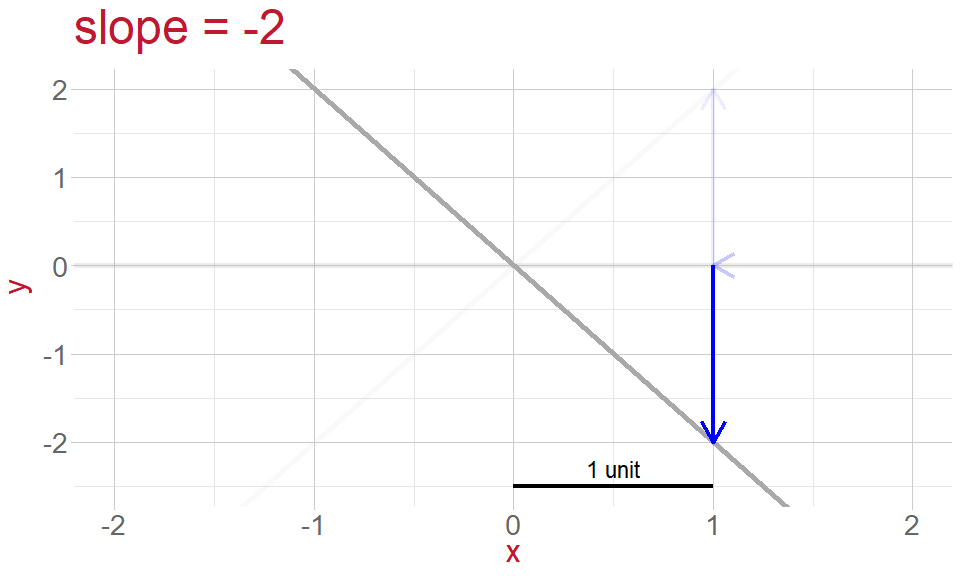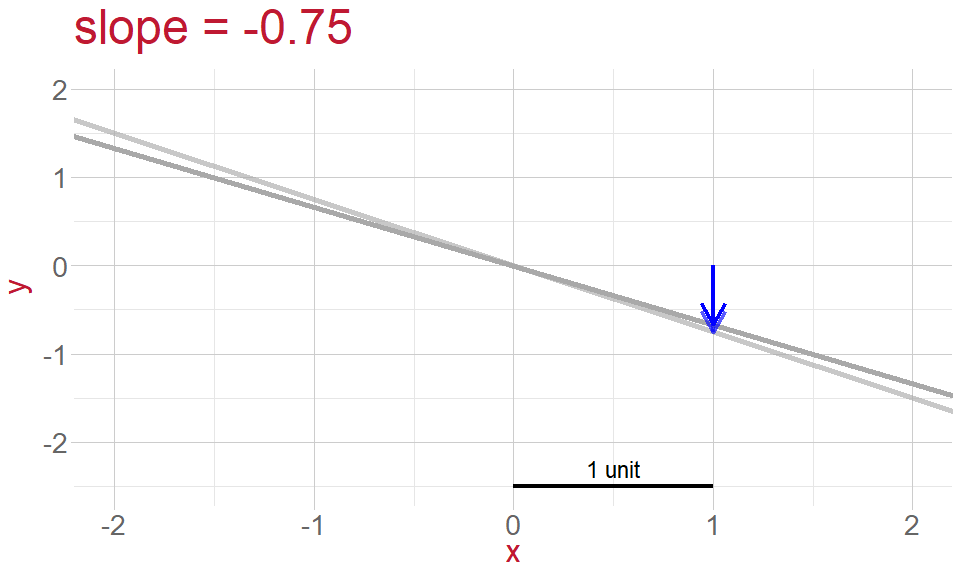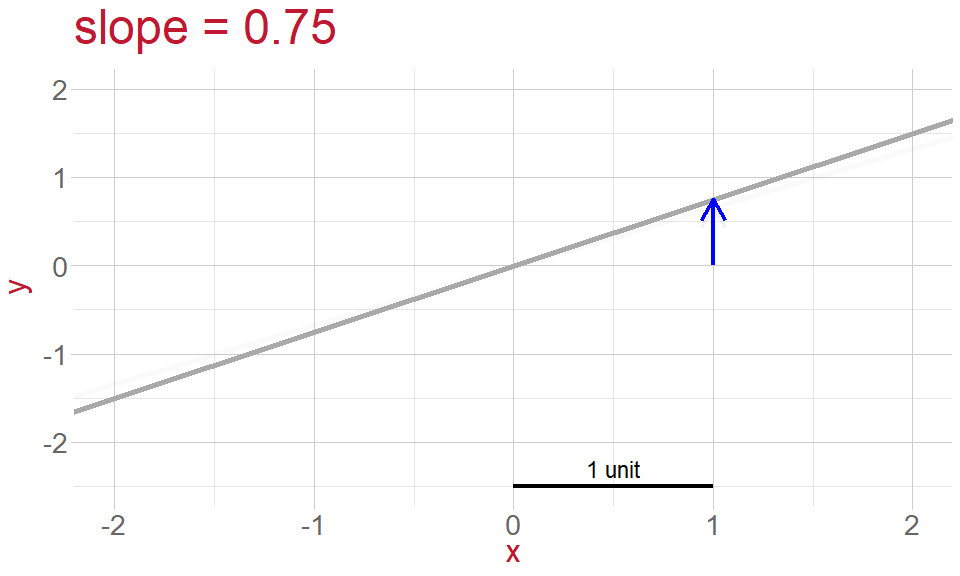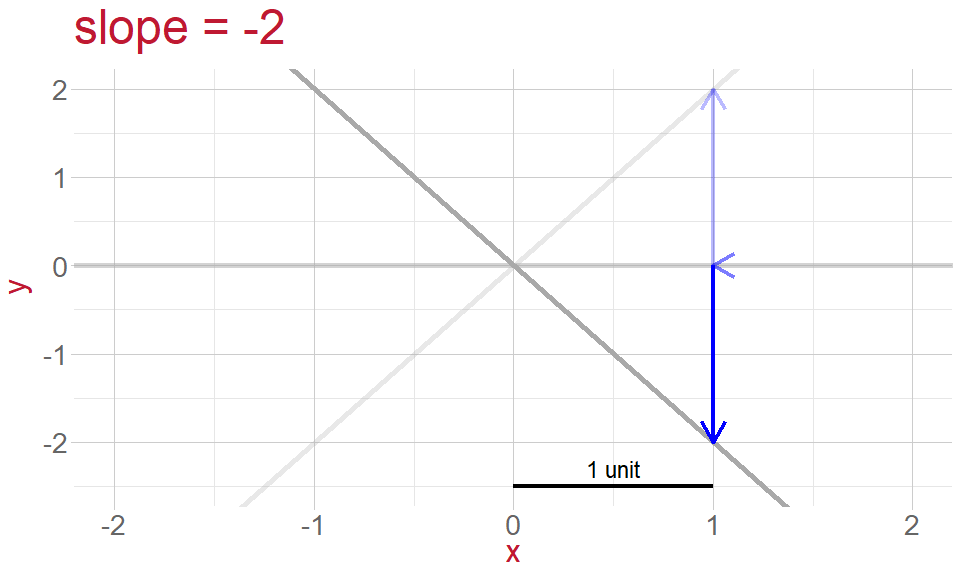
What is \(\epsilon_i\)?
\(\epsilon_i\), or the residual, is a measure of how well the model fits each data point.
It is the distance between the model line (on \(y\)-axis) and a data point.
\(\epsilon_i\) is positive if the point is above the line (red in plot)
\(\epsilon_i\) is negative if the point is below the line (blue in plot)

How to Find the Line?
The line represents a model of our data.
- In our example, the model that best characterises the relationship between hours of study and test score
In the scatterplot, the data are represented by points
So a good line is a line that is “close” to all points
The method that we use to identify the best-fitting line is the Principle of Least Squares

Principle of Least Squares
The values \(\beta_0\) and \(\beta_1\) are typically unknown and need to be estimated from our data.
- We denote the “best” estimated values as \(\hat \beta_0\) and \(\hat \beta_1\)
We find the values of \(\hat \beta_0\) and \(\hat \beta_1\) (and thus our best line) using least squares
Least squares:
minimises the distances between the actual values of \(y\) and the model-predicted values of \(\hat y\)
that is, it minimises the residuals for each data point (the line is “close”)

Principle of Least Squares
- Formally, least squares minimises the residual sum of squares
Essentially:
- Fit a line

Principle of Least Squares
- Formally, least squares minimises the residual sum of squares
Essentially:
- Fit a line
- Calculate the residuals

Principle of Least Squares
- Formally, least squares minimises the residual sum of squares
Essentially:
- Fit a line
- Calculate the residuals
- Square them

Principle of Least Squares
- Formally, least squares minimises the residual sum of squares
Essentially:
- Fit a line
- Calculate the residuals
- Square them
- Sum up the squares

Principle of Least Squares
- Formally, least squares minimises the residual sum of squares
Essentially:
- Fit a line
- Calculate the residuals
- Square them
- Sum up the squares
Why do you think we square the deviations?

This Week
Tasks

Attend your lab and work together on the exercises

Complete the weekly quiz
Support

Help each other on the Piazza forum

Attend office hours (see Learn page for details)